


#SQL の問題を判断する
Prometheus、Grafana

#SQL ステートメントの表現
 実行時間が長すぎます
実行時間が長すぎます
、行が非常に大きい (9950400) ため、基本的には「風味豊かな」 SQL であると判断できます。
 問題 SQL の取得
問題 SQL の取得
データベースが異なれば、それを取得する方法も異なります。以下は、現在の主流データベース向けのスロー クエリ SQL 取得ツールです。
MySQL スロークエリログ
テストツールloadrunner
インデックスが少ないとクエリが遅くなり、インデックスが多すぎると多くのスペースが占有されるため、インデックスを動的に維持する必要があります。追加、削除、変更を実行するとき、パフォーマンスに影響を与える
高い選択率 (重複値が少ない) そして、B ツリー インデックスを確立する必要がある場所によって頻繁に参照される、一般的な結合列にインデックスを付ける必要がある、複雑なドキュメント タイプのクエリフルテキスト インデックスを使用するとより効率的です。インデックスの確立では、クエリと DML のパフォーマンスのバランスをとる必要があります。複合インデックスを作成するときは、次の点に注意する必要があります。非先頭列クエリの場合は、• UNION の代わりに UNION ALL を使用してください
• select * メソッドの記述を避けるUNION ALL は UNION よりも実行効率が高くなります。UNION は実行時に重複排除する必要があります。UNION はソートする必要があります。
SQL を実行するとき、オプティマイザは * を特定の列に変換する必要があります。各クエリはテーブルに返される必要があり、上書きすることはできません。• JOIN フィールドのインデックスを作成することをお勧めします
一般に、JOIN フィールドには事前にインデックスが付けられます• 複雑な SQL を避けるステートメント
読みやすさを向上、クエリが遅くなる可能性を回避、複数の短いクエリに変換してビジネスエンドで処理可能#• 1=1 の記述を避ける
• データ列が複数回スキャンされる原因となる
SQL の最適化 実行計画RAND() と同様の記述による rand() による順序付けを避ける
SQL の最適化を完了する前に必ず実行計画を読んでください。実行計画には、効率が低い箇所と最適化が必要な箇所が示されます。 MYSQL を例として、実行計画がどのようなものかを見てみましょう。 (各データベースの実行計画は異なるため、自分で理解する必要があります)
| 説明 | |
|---|---|
| それぞれが独立して実行されます。 identifier はオブジェクトを操作する順序を識別します。id の値が大きいほど最初に実行されます。同じ場合、実行順序は上から下です。 | |
| クエリ内 各 select 句のタイプ | |
| 操作対象のオブジェクトの名前。通常はテーブル名ですが、他の形式 | #partitions |
| ##type | 結合操作の種類 |
| possible_keys | 使用される可能性のあるインデックス |
| key | インデックス実際にオプティマイザによって使用されます ( |
| 、 | eq_reg、ref、range## です) #、index および ALL。 ALL が表示される場合は、現在の SQL に「悪臭」があることを意味します。 key_len によって選択されたインデックス キーの長さ。オプティマイザの場合、単位は次のとおりです。バイト
|
| は、この行の操作対象オブジェクトの参照オブジェクトを表します。参照オブジェクトは NULL | # ではありません。 |
| クエリ実行によってスキャンされたタプルの数 (innodb の場合、この値は推定値です) | |
| 条件テーブルのデータがフィルタリングされる タプル数の割合 | |
| この列が表示される場合の実行計画の重要な補足情報 | ファイルソートの使用, | 一時的な使用# 単語を使用するときは注意してください ##、SQL ステートメントを最適化する必要がある可能性が非常に高いです
次に、実践的な最適化のケースでは、SQL 最適化プロセスと最適化手法を説明します。 |
CREATE TABLE `a` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_id` bigint(20) DEFAULT NULL, `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `b` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_name` varchar(100) DEFAULT NULL, `user_id` varchar(50) DEFAULT NULL, `user_name` varchar(100) DEFAULT NULL, `sales` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `c` ( `id` int(11) NOT NULLAUTO_INCREMENT, `user_id` varchar(50) DEFAULT NULL, `order_id` varchar(100) DEFAULT NULL, `state` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) );
3 つのテーブルの関連付け, 現在時刻から 10 時間前後の現在のユーザーの注文ステータスをクエリし、注文作成時刻に従って昇順に並べ替えます。具体的な SQL は次のとおりです。
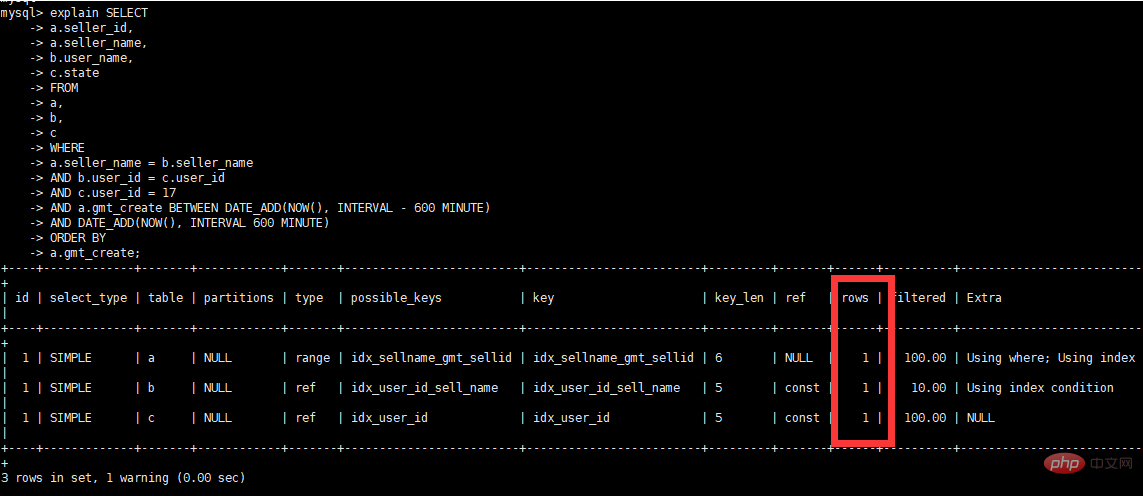
select a.seller_id, a.seller_name, b.user_name, c.state from a, b, c where a.seller_name = b.seller_name and b.user_id = c.user_id and c.user_id = 17 and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE) AND DATE_ADD(NOW(), INTERVAL 600 MINUTE) order by a.gmt_create
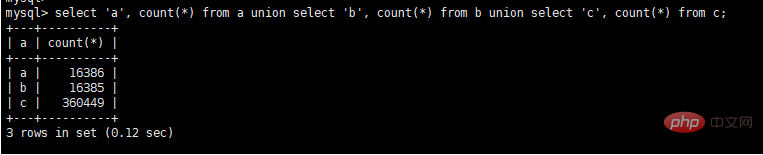 元の実行計画
元の実行計画
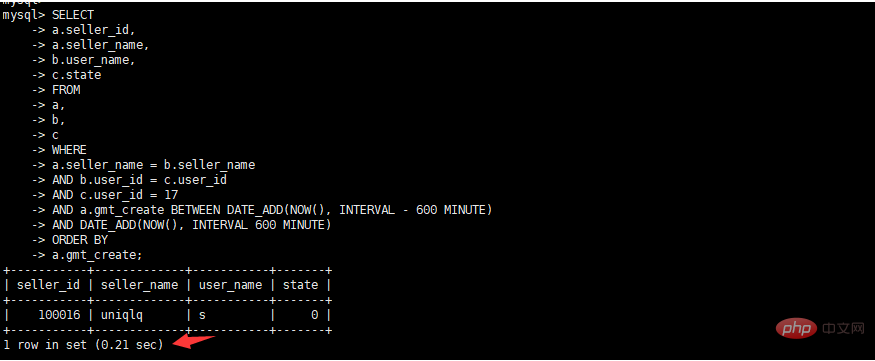 初期の最適化アイデア
初期の最適化アイデア
Where 条件フィールドのタイプSQL の はテーブル構造と一致している必要があります。
user_id は varchar(50) 型です。SQL で使用される実際の int 型は暗黙的な変換があり、インデックスは追加されません。テーブル b とテーブル c の 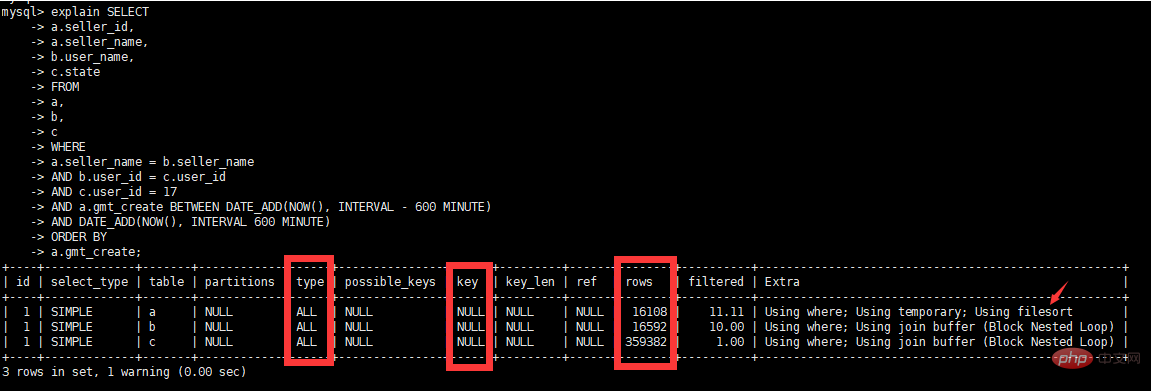 user_id
user_id
#テーブル b とテーブル c の間にリレーションシップがあるため、テーブル b とテーブル c にインデックスを作成します。
user_id #リレーションシップがあるため、テーブルは b テーブルに関連付けられており、a テーブルと b テーブルの seller_name フィールドにインデックスが付けられています。
複合インデックスを使用します。一時テーブルとソートを排除するため
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
警告情報の表示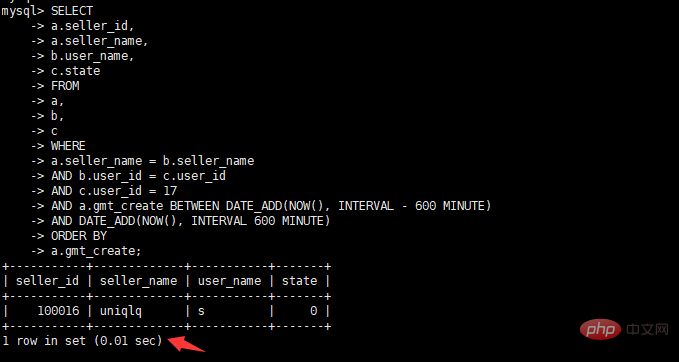
最適化の継続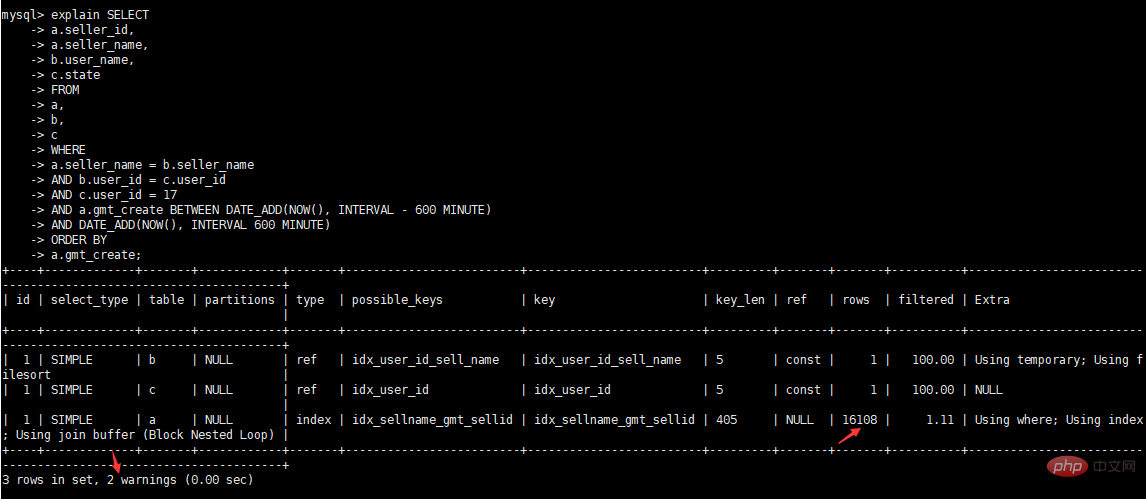
alter table a modify "gmt_create" datetime DEFAULT NULL
#実行時間の表示
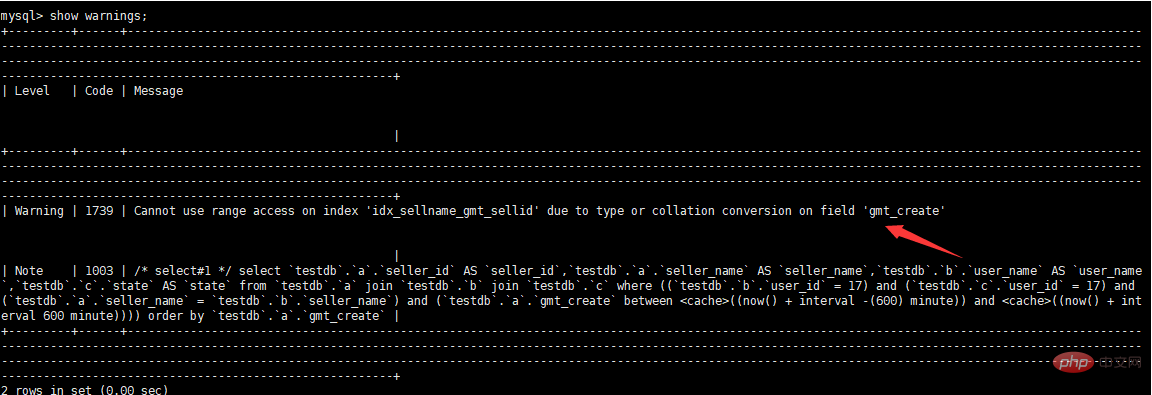
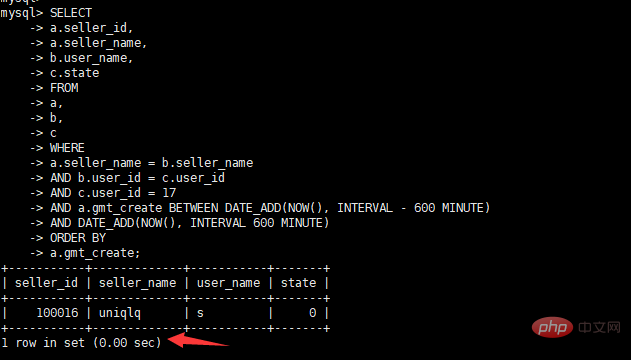
 最適化ポイントに応じてテーブル構造の変更、インデックス追加、SQLリライトなどを実行
最適化ポイントに応じてテーブル構造の変更、インデックス追加、SQLリライトなどを実行
最適化された実行時間と実行計画を表示します
最適化の効果が明らかでない場合は、4 番目のステップを繰り返します以上がMySQL データベース SQL ステートメントの最適化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



