


1. 概要
コレクション シリーズの最初の章では、Map の実装クラスがHashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、プロパティなどがあります。
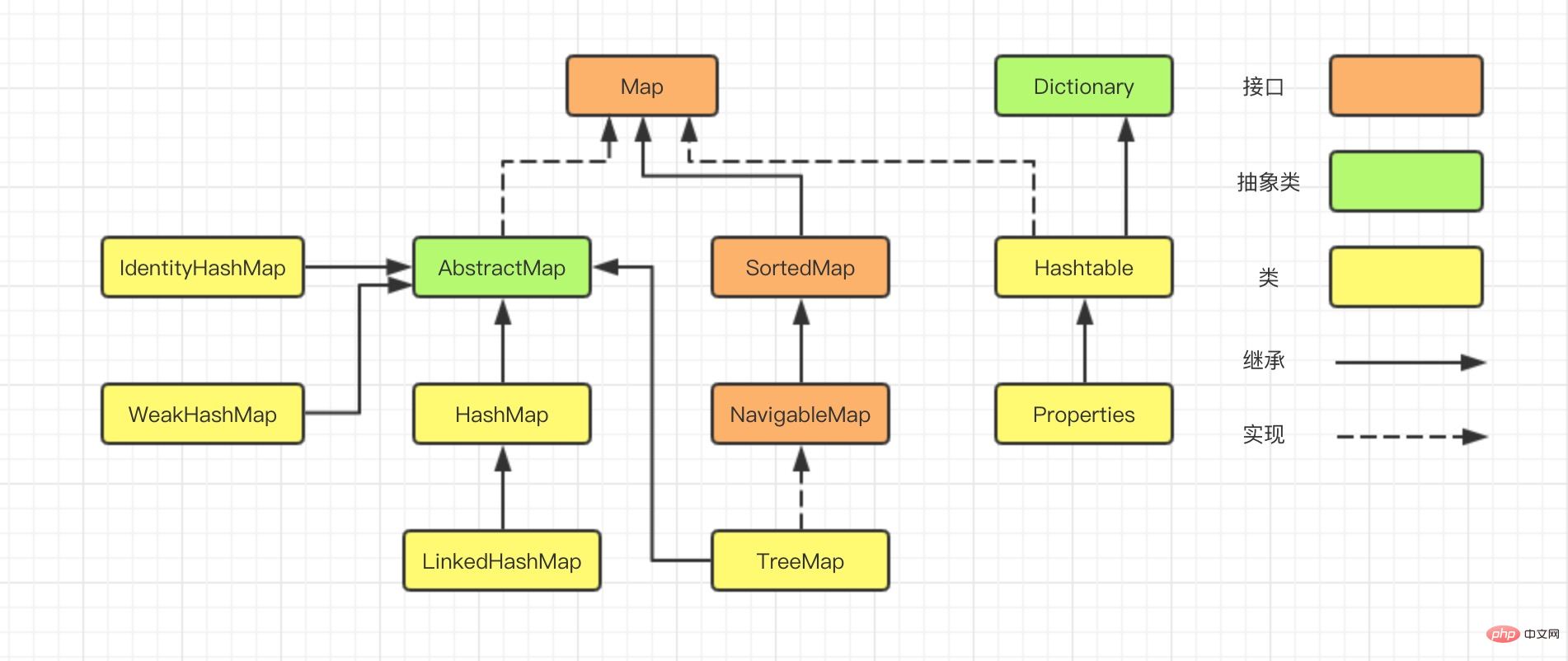
#この記事では主に LinkedHashMap の実装についてデータ構造とアルゴリズム レベルから説明します。
(推奨学習: Java ビデオ チュートリアル)
2. はじめに
LinkedHashMap は HashMap LinkedList と考えることができます。HashMap を使用してデータ構造を操作するだけでなく、LinkedList を使用して挿入された要素の順序を維持します。内部的には、二重にリンク リスト (二重リンク リスト) からすべての要素 (エントリ) が接続されます。
LinkedHashMap は HashMap を継承しており、null キーを持つ要素を挿入したり、null 値を持つ要素を挿入したりできます。名前からわかるように、このコンテナは LinkedList と HashMap を組み合わせたものであり、HashMap と LinkedList の両方の特性を満たしていることを意味しており、LinkedHashMap は HashMap を Linked list で強化したものとみなすことができます。
LinkedHashMap ソース コードを開くと、3 つの主要なコア属性が表示されます。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>{
/**双向链表的头节点*/
transient LinkedHashMap.Entry<K,V> head;
/**双向链表的尾节点*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 1、如果accessOrder为true的话,则会把访问过的元素放在链表后面,放置顺序是访问的顺序
* 2、如果accessOrder为false的话,则按插入顺序来遍历
*/
final boolean accessOrder;
}LinkedHashMap 初期化フェーズでは、デフォルトでは挿入オーダーでトラバースします
public LinkedHashMap() {
super();
accessOrder = false;
}LinkedHashMap で使用されるハッシュ アルゴリズム。HashMap と同じですが、配列に保存された要素エントリを再定義する点が異なります。現在のオブジェクトの参照を保存することに加えて、エントリは以前の要素の参照も保存します。基本的には、双方向のリンクされたリストが形成されます。
ソースコードは次のとおりです。
static class Entry<K,V> extends HashMap.Node<K,V> {
//before指的是链表前驱节点,after指的是链表后驱节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}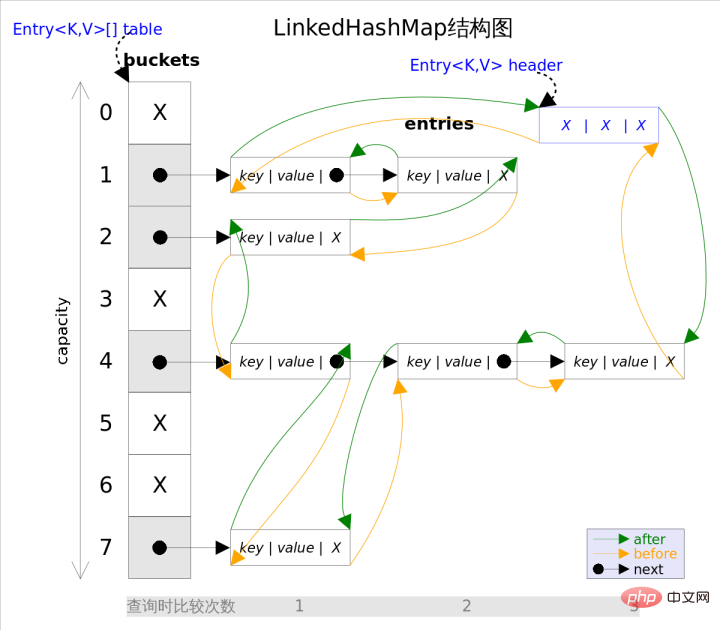
二重リンクリストの先頭に挿入されたデータが、次のエントリであることが直感的にわかります。リンク リストであり、反復子のトラバース方向はリンク リストからのもので、リンク リストの先頭から開始し、リンク リストの末尾で終了します。
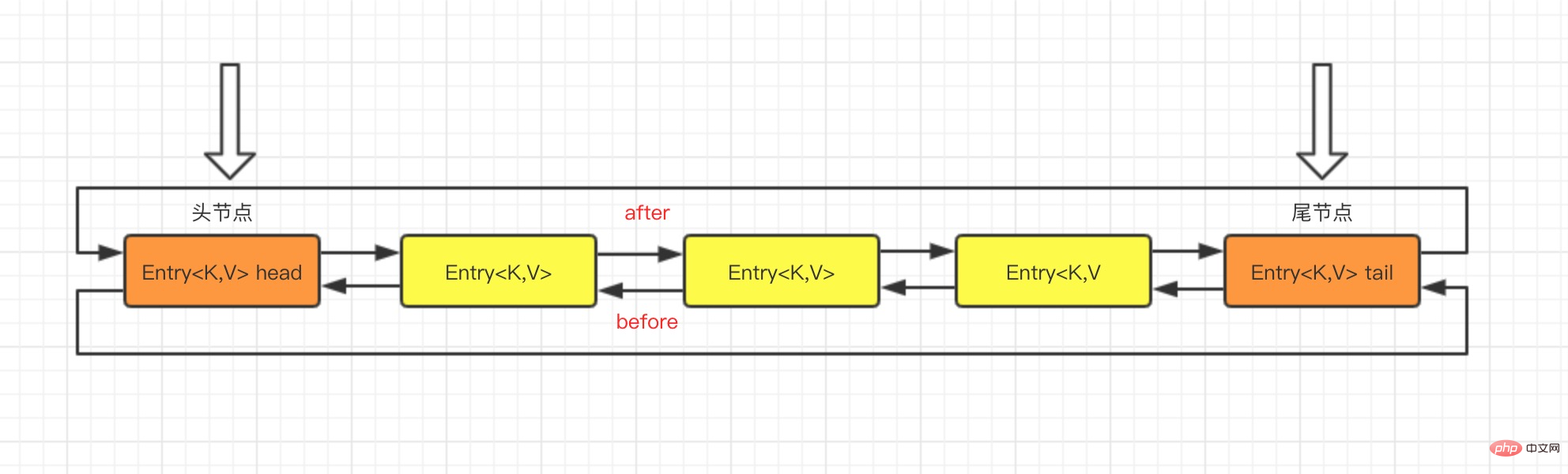
この構造には、反復順序の保持に加えて、別の利点もあります。LinkedHashMap を反復するときに、HashMap のようにテーブル全体を走査する必要はなく、必要なのは、つまり、LinkedHashMap の反復時間はエントリの数にのみ関係し、テーブルのサイズには関係ありません。
3. 一般的なメソッドの紹介
3.1. Get メソッド
get メソッドは、指定されたキー値。このメソッドのプロセスは HashMap.get() メソッドとほぼ同じで、デフォルトでは挿入順に処理されます。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}accessOrder が true の場合、訪問した要素はリンク リストの最後に配置され、配置順序はアクセス順になります。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}テスト ケース:
public static void main(String[] args) {
//accessOrder默认为false
Map<String, String> accessOrderFalse = new LinkedHashMap<>();
accessOrderFalse.put("1","1");
accessOrderFalse.put("2","2");
accessOrderFalse.put("3","3");
accessOrderFalse.put("4","4");
System.out.println("acessOrderFalse:"+accessOrderFalse.toString());
//accessOrder设置为true
Map<String, String> accessOrderTrue = new LinkedHashMap<>(16, 0.75f, true);
accessOrderTrue.put("1","1");
accessOrderTrue.put("2","2");
accessOrderTrue.put("3","3");
accessOrderTrue.put("4","4");
accessOrderTrue.get("2");//获取键2
accessOrderTrue.get("3");//获取键3
System.out.println("accessOrderTrue:"+accessOrderTrue.toString());
}出力結果:
acessOrderFalse:{1=1, 2=2, 3=3, 4=4}
accessOrderTrue:{1=1, 4=4, 2=2, 3=3}3.2. Put メソッド
put(K key, V value) メソッドは、指定されたキーと値のペアをマップに追加します。このメソッドは、まず HashMap の挿入メソッドを呼び出し、マップを検索して要素が含まれているかどうかを確認します。含まれている場合は、直接戻ります。検索プロセスは get() メソッドと似ており、見つからない場合は、要素がコレクションに挿入されます。
/**HashMap 中实现*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
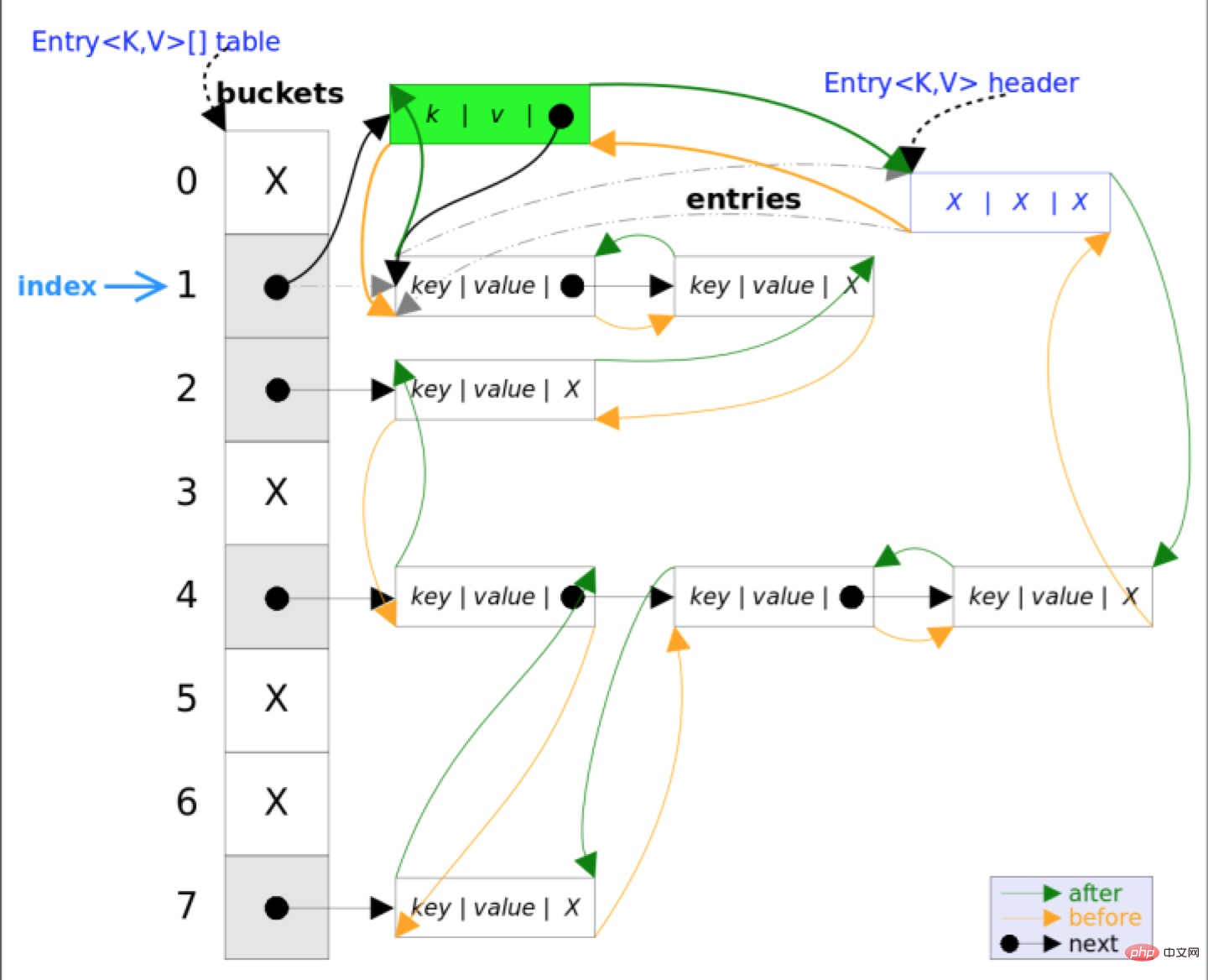
}LinkedHashMap でオーバーライドされたメソッド
// LinkedHashMap 中覆写
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将 Entry 接在双向链表的尾部
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// last 为 null,表明链表还未建立
if (last == null)
head = p;
else {
// 将新节点 p 接在链表尾部
p.before = last;
last.after = p;
}
}
3.3、removeメソッド
remove(Object key) 関数キー値に対応するエントリを削除することです。このメソッドの実装ロジックは主に HashMap に基づいており、まずキー値に対応するエントリを見つけてから、エントリを削除します (リンク リストの対応する参照を変更します)。検索プロセスは get() メソッドと似ており、最後に LinkedHashMap でオーバーライドされたメソッドが呼び出され、削除されます。
/**HashMap 中实现*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode) {...}
else {
// 遍历单链表,寻找要删除的节点,并赋值给 node 变量
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode) {...}
// 将要删除的节点从单链表中移除
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node); // 调用删除回调方法进行后续操作
return node;
}
}
return null;
}LinkedHashMap でオーバーライドされた afterNodeRemoval メソッド
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}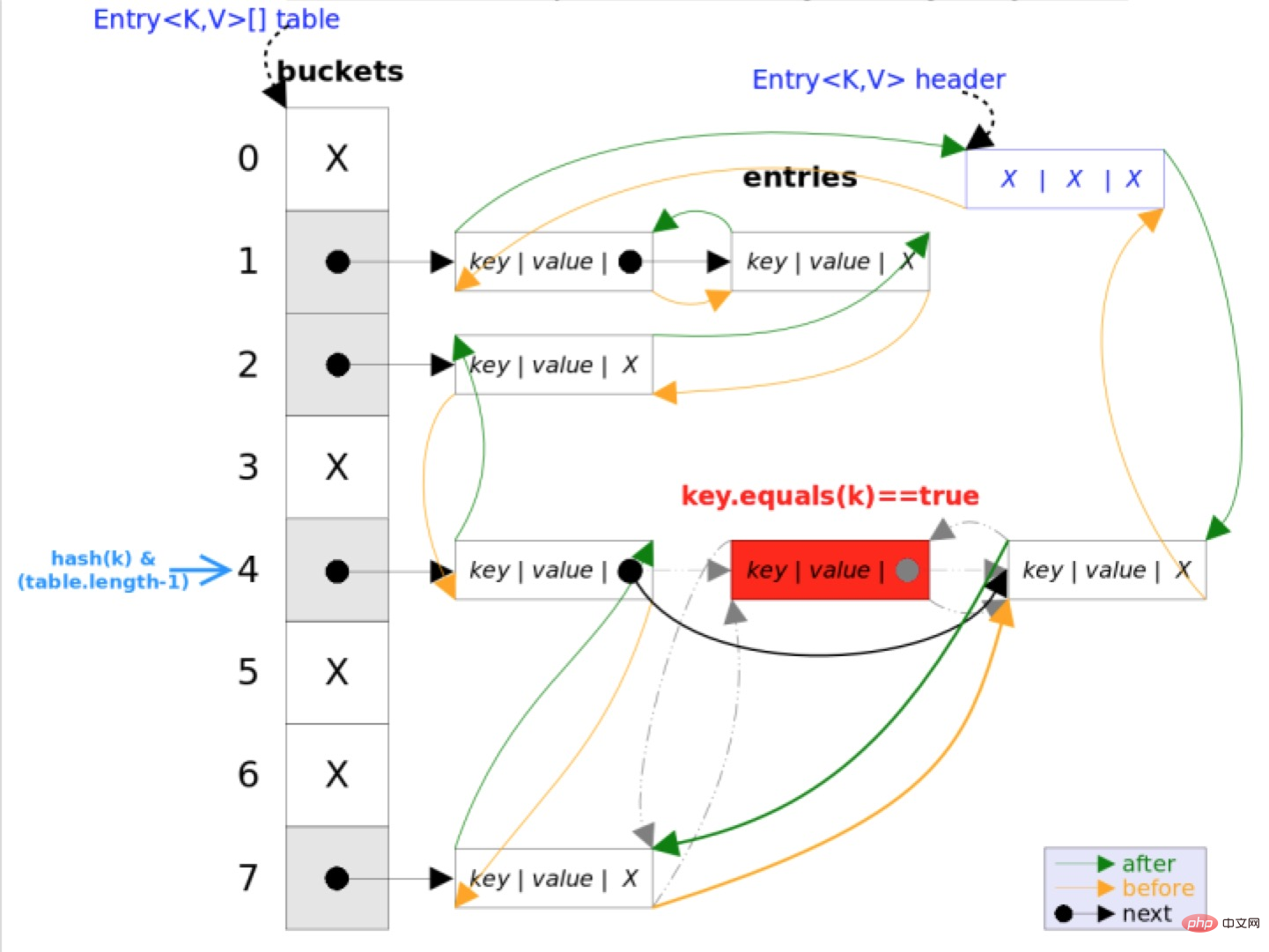
##4. 概要
LinkedHashMap は HashMap から継承します。機能的な特徴は基本的に同じです。この 2 つの唯一の違いは、LinkedHashMap が二重リンク リストを使用して HashMap に基づいてすべてのエントリを接続することです。これは、要素の反復順序が挿入順序と同じであることを保証するためです。 主要部分は HashMap とまったく同じですが、二重リンク リストの先頭を指す header と、二重リンク リストの末尾を指す tail が追加されています。リンクされたリストはエントリの挿入順序です。本文來自php中文網,java教學欄目,歡迎學習!
以上がLinkedHashMapを分かりやすく分析(写真とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



