
1. インターフェイスの基本的な使用法
golang のインターフェイス自体も型であり、コレクションを表しますメソッドの。いずれかの型がインターフェイスで宣言されたすべてのメソッドを実装している限り、クラスはインターフェイスを実装します。他の言語とは異なり、golang は型がインターフェイスを実装することを明示的に宣言する必要はありませんが、コンパイラーとランタイムによってチェックされます。
宣言
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | type 接口名 interface{
方法1
方法2
...
方法n
}
type 接口名 interface {
已声明接口名1
...
已声明接口名n
}
type iface interface{
tab *itab
data unsafe.Pointer
}
|
ログイン後にコピー
インターフェース自体も構造型ですが、コンパイラーはそれに多くの制限を課します:
#● フィールドを持つことはできません
● 独自のメソッドを定義することはできません
#● メソッドを宣言することのみが可能であり、メソッドを実装することはできません
##● 他のインターフェイス タイプを埋め込むことができます
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | package main
import (
"fmt"
)
type People interface {
ReturnName() string
}
type Student struct {
Name string
}
func (s Student) ReturnName() string {
return s.Name
}
func main() {
cbs := Student{Name:"小明"}
var a People
a = cbs
name := a.ReturnName()
fmt.Println(name)
}
|
ログイン後にコピー
If anインターフェイスにメソッドが含まれていない場合、それは空のインターフェイス (空のインターフェイス) です。すべての型は空のインターフェイスの定義に準拠しているため、任意の型を空のインターフェイスに変換できます。
簡単に言えば、インターフェイスの値は、型とデータの 2 つの部分で構成されます。2 つのインターフェイスが等しいかどうかは、その 2 つの部分が等しいかどうかによって決まります。また、型が等しい場合にのみ判断されます。およびデータは nil インターフェイスを nil として表します。
1 2 3 | var a interface{}
var b interface{} = (*int)(nil)
fmt.Println(a == nil, b == nil)
|
ログイン後にコピー
2. インターフェイスのネスト
匿名フィールドなどの他のインターフェイスを埋め込みます。ターゲット タイプのメソッド セットには、インターフェイスを実現するための組み込みインターフェイス メソッドを含むすべてのメソッドが含まれている必要があります。他のインターフェイス型を埋め込むことは、宣言されたメソッドを一元的にインポートすることと同じです。これには、同じ名前のメソッドをそれ自体に埋め込んだり、循環的に埋め込んだりできないことが必要です。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | type stringer interfaceP{
string() string
}
type tester interface {
stringer
test()
}
type data struct{}
func (*data) test() {}
func (data) string () string {
return ""
}
func main() {
var d data
var t tester = &d
t.test()
println(t.string())
}
|
ログイン後にコピー
スーパーセット インターフェイス変数は暗黙的にサブセットに変換できますが、その逆はできません。
3. インターフェースの実装
Golang のインターフェース検出には、静的な部分と動的な部分の両方があります。
# 静的部分
#具象型 (カスタム型を含む) -> インターフェイスの場合、コンパイラは対応する itab を生成し、ELF の .rodata セクションに置きます。の場合は、.rodata が存在する関連するオフセット アドレスをポインタで直接指すだけです。具体的な実装については、golang の送信ログ CL 20901 および CL 20902 を参照してください。
インターフェイス -> 具象型 (カスタム型を含む具象型) の場合、コンパイラは比較のために関連するフィールドを抽出し、値を生成します
● 動的部分
は実行時に処理されます対応する型 -> インターフェイス型変換の itab を記録するグローバル ハッシュ テーブルがあります。変換するときは、まずハッシュ テーブルを確認します。存在する場合は成功を返します。存在しない場合は、2 つの型が変換できるかどうかを確認しますハッシュ テーブルに挿入できた場合は成功を返し、挿入できなかった場合は失敗を返します。ここでのハッシュ テーブルは go のマップではなく、配列を使用した最も原始的なハッシュ テーブルであり、競合を解決するためにオープン アドレス方式を使用していることに注意してください。主にインターフェース <-> インターフェース (インターフェースに割り当てられたインターフェース、別のインターフェースに変換されたインターフェース) は、itab を動的に生成するために使用されます。
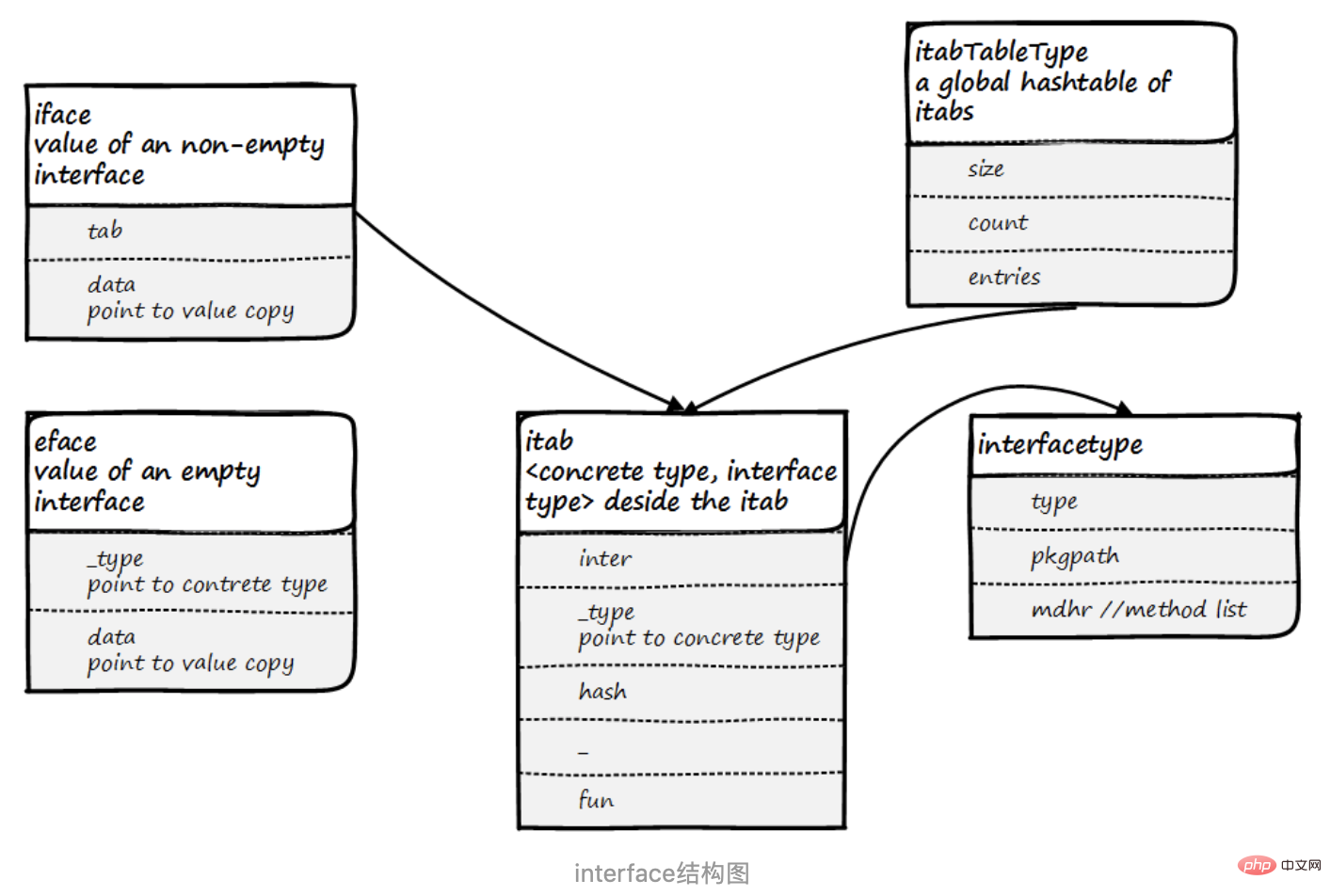
インターフェースの構造は次のとおりです。
インターフェース型の構造interfacetype
1 2 3 4 5 6 7 8 9 10 | type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
type imethod struct {
name nameOff
typ typeOff
}
|
ログイン後にコピー
nameOff 型と typeOff 型は int32、これら 2 つの値は次のとおりです。 リンカーは、実行可能ファイルのメタ情報に関連するオフセットを埋め込む役割を果たします。メタ情報は実行時に runtime.moduledata 構造にロードされます。
4. インターフェイス値 iface と eface の構造
パフォーマンスのために、golang は eface と iface の 2 種類のインターフェイスに分かれています。eface は空のインターフェイスです。 iface はメソッド インターフェイスです。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | type iface struct {
tab *itab
data unsafe.Pointer
}
type eface struct {
_type *_type
data unsafe.Pointer
}
type itab struct {
inter *interfacetype
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr
}
|
ログイン後にコピー
iface 構造体のデータは実際のデータの保存に使用されます。ランタイムは新しいメモリを適用し、そこでデータをテストし、データはこの新しいメモリを指します。
itab のハッシュ メソッドは _type.hash からコピーされます; fun はサイズ 1 の uintptr 配列です. fun[0] が 0 の場合、_type がインターフェイスを実装していないことを意味します。実装インターフェイス この時点で、 fun は最初のインターフェイス メソッドのアドレスを保存し、他のメソッドは一度に 1 つずつ保存されます。ここでは単にスペースと時間を交換するだけです。実際、メソッドは _type フィールドにあります。実際にはここに記録されており、呼び出されるたびに動的検索を行う必要はありません。
4.1 グローバル itab テーブル
iface.go:
1 2 3 4 5 6 7 8 | const itabInitSize = 512
type itabTableType struct {
size uintptr
count uintptr
entries [itabInitSize]*itab
}
|
ログイン後にコピー
このグローバル itabTable は配列に格納されており、size は配列のサイズを記録していることがわかります。これは常に 2 のべき乗です。 count は、配列のどれだけが使用されたかを記録します。エントリは、初期サイズが 512 の *itab 配列です。
5. インターフェイスの型変換
インターフェイスに特定の値を割り当てると、conv シリーズの関数が呼び出されます。たとえば、空のインターフェイスは convT2E シリーズを呼び出します。空のインターフェイスは convT2I シリーズを呼び出します。パフォーマンス上の理由から、convT2I64 や convT2Estring などの多くの特殊なケースでは、typedmemmove の呼び出しが回避されます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | func convT2E(t *_type, elem unsafe.Pointer) (e eface) {
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2E))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
e._type = t
e.data = x
return
}
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
func convT2I16(tab *itab, val uint16) (i iface) {
t := tab._type
var x unsafe.Pointer
if val == 0 {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(2, t, false)
*(*uint16)(x) = val
}
i.tab = tab
i.data = x
return
}
func convI2I(inter *interfacetype, i iface) (r iface) {
tab := i.tab
if tab == nil {
return
}
if tab.inter == inter {
r.tab = tab
r.data = i.data
return
}
r.tab = getitab(inter, tab._type, false)
r.data = i.data
return
}
|
ログイン後にコピー
次のことがわかります:
# 特定の型は空のインターフェイスに変換され、_type フィールドはソース型を直接コピーします。mallocgc は新しいメモリを作成し、値とデータをコピーします。この記憶を指します。
● 具体类型转非空接口,入参tab是编译器生成的填进去的,接口指向同一个入参tab指向的itab;mallocgc一个新内存,把值复制过去,data再指向这块内存。
● 对于接口转接口,itab是调用getitab函数去获取的,而不是编译器传入的。
对于那些特定类型的值,如果是零值,那么不会mallocgc一块新内存,data会指向zeroVal[0]。
5.1 接口转接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | func assertI2I2(inter *interfacetype, i iface) (r iface, b bool) {
tab := i.tab
if tab == nil {
return
}
if tab.inter != inter {
tab = getitab(inter, tab._type, true)
if tab == nil {
return
}
}
r.tab = tab
r.data = i.data
b = true
return
}
func assertE2I(inter *interfacetype, e eface) (r iface) {
t := e._type
if t == nil {
panic(&TypeAssertionError{nil, nil, &inter.typ, ""})
}
r.tab = getitab(inter, t, false)
r.data = e.data
return
}
func assertE2I2(inter *interfacetype, e eface) (r iface, b bool) {
t := e._type
if t == nil {
return
}
tab := getitab(inter, t, true)
if tab == nil {
return
}
r.tab = tab
r.data = e.data
b = true
return
}
|
ログイン後にコピー
我们看到有两种用法:
● 返回值是一个时,不能转换就panic。
● 返回值是两个时,第二个返回值标记能否转换成功
此外,data复制的是指针,不会完整拷贝值。每次都malloc一块内存,那么性能会很差,因此,对于一些类型,golang的编译器做了优化。
5.2 接口转具体类型
接口判断是否转换成具体类型,是编译器生成好的代码去做的。我们看个empty interface转换成具体类型的例子:
1 2 3 4 5 6 7 8 9 10 11 12 | var EFace interface{}
var j int
func F4(i int) int{
EFace = I
j = EFace.(int)
return j
}
func main() {
F4(10)
}
|
ログイン後にコピー
反汇编:
1 2 | go build -gcflags '-N -l' -o tmp build.go
go tool objdump -s "main.F4" tmp
|
ログイン後にコピー
可以看汇编代码:
可以看到empty interface转具体类型,是编译器生成好对比代码,比较具体类型和空接口是不是同一个type,而不是调用某个函数在运行时动态对比。
5.3 非空接口类型转换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | var tf Tester
var t testStruct
func F4() int{
t := tf.(testStruct)
return t.i
}
func main() {
F4()
}
MOVQ main.tf(SB), CX
LEAQ go.itab.main.testStruct,main.Tester(SB), DX
CMPQ DX, CX
|
ログイン後にコピー
可以看到,非空接口转具体类型,也是编译器生成的代码,比较是不是同一个itab,而不是调用某个函数在运行时动态对比。
6. 获取itab的流程
golang interface的核心逻辑就在这,在get的时候,不仅仅会从itabTalbe中查找,还可能会创建插入,itabTable使用容量超过75%还会扩容。看下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | func getitab(inter *interfacetype, typ *_type, canfail bool) *itab {
if len(inter.mhdr) == 0 {
throw("internal error - misuse of itab")
}
if typ.tflag&tflagUncommon == 0 {
if canfail {
return nil
}
name := inter.typ.nameOff(inter.mhdr[0].name)
panic(&TypeAssertionError{nil, typ, &inter.typ, name.name()})
}
var m *itab
t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable)))
if m = t.find(inter, typ); m != nil {
goto finish
}
lock(&itabLock)
if m = itabTable.find(inter, typ); m != nil {
unlock(&itabLock)
goto finish
}
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize, 0, &memstats.other_sys))
m.inter = inter
m._type = typ
m.init()
itabAdd(m)
unlock(&itabLock)
finish:
if m.fun[0] != 0 {
return m
}
if canfail {
return nil
}
panic(&TypeAssertionError{concrete: typ, asserted: &inter.typ, missingMethod: m.init()})
}
|
ログイン後にコピー
流程如下:
● 先用t保存全局itabTable的地址,然后使用t.find去查找,这样是为了防止查找过程中,itabTable被替换导致查找错误。
● 如果没找到,那么就会上锁,然后使用itabTable.find去查找,这样是因为在第一步查找的同时,另外一个协程写入,可能导致实际存在却查找不到,这时上锁避免itabTable被替换,然后直接在itaTable中查找。
● 再没找到,说明确实没有,那么就根据接口类型、数据类型,去生成一个新的itab,然后插入到itabTable中,这里可能会导致hash表扩容,如果数据类型并没有实现接口,那么根据调用方式,该报错报错,该panic panic。
这里我们可以看到申请新的itab空间时,内存空间的大小是unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize,参照前面接受的结构,len(inter.mhdr)就是接口定义的方法数量,因为字段fun是一个大小为1的数组,所以len(inter.mhdr)-1,在fun字段下面其实隐藏了其他方法接口地址。
6.1 在itabTable中查找itab find
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
return uintptr(inter.typ.hash ^ typ.hash)
}
func (t *itabTableType) find(inter *interfacetype, typ *_type) *itab {
mask := t.size - 1
h := itabHashFunc(inter, typ) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize))
m := (*itab)(atomic.Loadp(unsafe.Pointer(p)))
if m == nil {
return nil
}
if m.inter == inter && m._type == typ {
return m
}
h += I
h &= mask
}
}
|
ログイン後にコピー
从注释可以看到,golang使用的开放地址探测法,用的是公式h(i) = h0 + i*(i+1)/2 mod 2^k,h0是根据接口类型和数据类型的hash字段算出来的。以前的版本是额外使用一个link字段去连到下一个slot,那样会有额外的存储,性能也会差写,在1.11中我们看到有了改进。
6.2 检查并生成itab init
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | func (m *itab) init() string {
inter := m.inter
typ := m._type
x := typ.uncommon()
ni := len(inter.mhdr)
nt := int(x.mcount)
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
j := 0
imethods:
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
ipkg := name.pkgPath()
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
if tname.isExported() || pkgPath == ipkg {
if m != nil {
ifn := typ.textOff(t.ifn)
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn
}
continue imethods
}
}
}
m.fun[0] = 0
return iname
}
m.hash = typ.hash
return ""
}
|
ログイン後にコピー
这个方法会检查interface和type的方法是否匹配,即type有没有实现interface。假如interface有n中方法,type有m中方法,那么匹配的时间复杂度是O(n x m),由于interface、type的方法都按字典序排,所以O(n+m)的时间复杂度可以匹配完。在检测的过程中,匹配上了,依次往fun字段写入type中对应方法的地址。如果有一个方法没有匹配上,那么就设置fun[0]为0,在外层调用会检查fun[0]==0,即type并没有实现interface。
这里我们还可以看到golang中continue的特殊用法,要直接continue到外层的循环中,那么就在那一层的循环上加个标签,然后continue 标签。
6.3 把itab插入到itabTable中 itabAdd
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | func itabAdd(m *itab) {
if getg().m.mallocing != 0 {
throw("malloc deadlock")
}
t := itabTable
if t.count >= 3*(t.size/4) {
t2 := (*itabTableType)(mallocgc((2+2*t.size)*sys.PtrSize, nil, true))
t2.size = t.size * 2
if t2.count != t.count {
throw("mismatched count during itab table copy")
}
atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2))
t = itabTable
}
t.add(m)
}
func (t *itabTableType) add(m *itab) {
mask := t.size - 1
h := itabHashFunc(m.inter, m._type) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize))
m2 := *p
if m2 == m {
return
}
if m2 == nil {
atomic.StorepNoWB(unsafe.Pointer(p), unsafe.Pointer(m))
t.count++
return
}
h += I
h &= mask
}
}
|
ログイン後にコピー
可以看到,当hash表使用达到75%或以上时,就会进行扩容,容量是原来的2倍,申请完空间,就会把老表中的数据插入到新的hash表中。然后使itabTable指向新的表,最后把新的itab插入到新表中。
推荐:go语言教程
以上がgoのデータ構造 - インターフェース(詳細説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



