

Redis を永続化するいくつかの方法

Redis はメモリ上で読み書きを行うため、パフォーマンスは高いですが、サーバーの再起動によりメモリ上のデータが失われます。データを失わないようにするために、データを移動する必要があります。 Redis の再起動時に元のデータをディスクから復元できるように、データはディスクに保存されます。このプロセス全体を Redis 永続化と呼びます。
Redis の永続性は、Redis と Memcached の主な違いの 1 つです。永続化機能はありません。
1. いくつかの永続化メソッド
Redis の永続化には次の 3 つのメソッドがあります:
スナップショット メソッド (RDB、Redis Database) は、メモリ データを特定の瞬間がバイナリ形式でディスクに書き込まれます。
ファイル追加モード (AOF、ファイル追加のみ) は、すべての操作コマンドを記録し、テキスト形式でファイルに追加します。
Redis 4.0以降に追加された新しい方式であるハイブリッド永続化方式 RDBとAOFの利点を組み合わせたハイブリッド永続化方式 書き込み時、まず現在のデータをRDB形式でファイルの先頭に書き込み、その後の操作コマンドをファイルの先頭に格納しますファイルは AOF 形式で保存されるため、Redis の再起動速度が確保されるだけでなく、データ損失のリスクも軽減されます。
各永続性ソリューションには特定の使用シナリオがあるため、RDB 永続性から始めましょう。
2. RDB の概要
RDB (Redis Database) は、特定の瞬間のメモリ スナップショット (Snapshot) をバイナリ形式でディスクに書き込むプロセスです。
3. 永続化トリガー
RDB の永続化トリガー方法には、手動トリガーと自動トリガーの 2 種類があります。
1) 手動トリガー
永続化を手動でトリガーするには、save と bgsave の 2 つの操作があります。これらの主な違いは、Redis メイン スレッドの実行をブロックするかどうかです。
① save コマンド
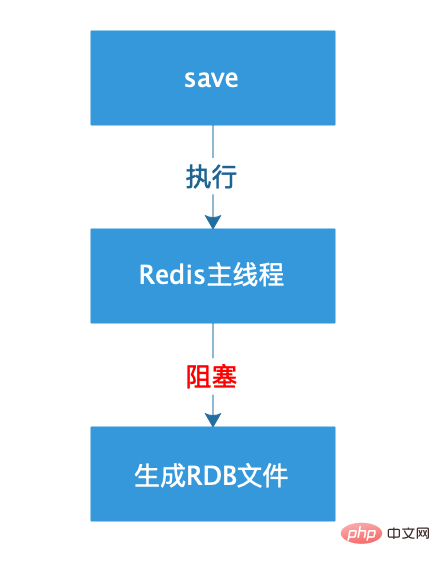
クライアントで save コマンドを実行すると、Redis の永続化がトリガーされますが、同時に Redis がブロック状態になります。 RDB が永続化されるまでは、他のクライアントから送信されたコマンドに応答しないため、運用環境では注意して使用する必要があります。
save コマンドは次のように使用されます。
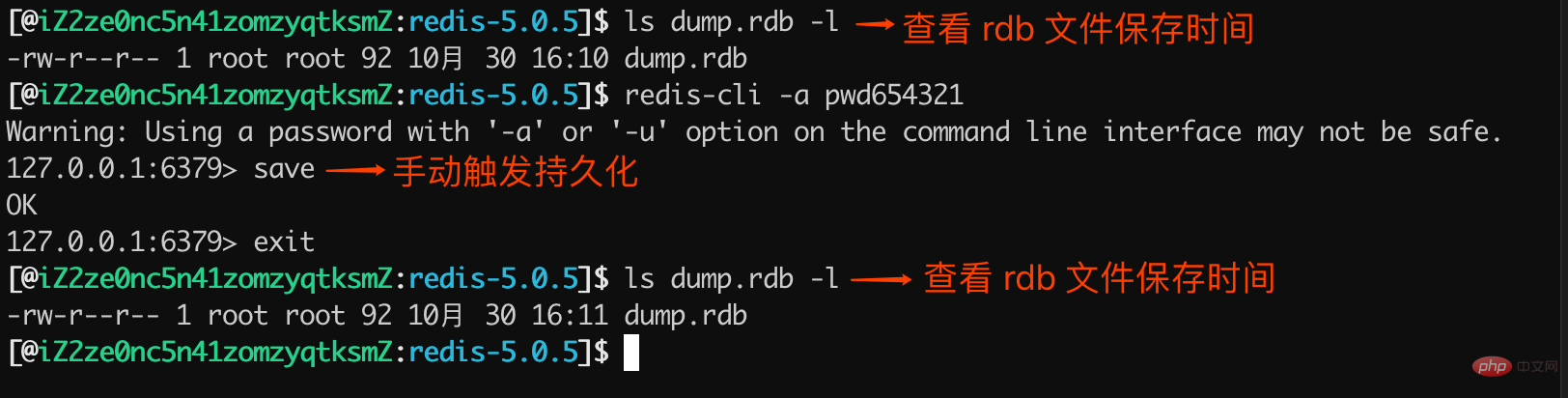
図からわかるように、save コマンドが実行されると、永続ファイルが作成されます。 dump. rdb の変更時刻が変更されました。これは、save が RDB 永続化を正常にトリガーしたことを意味します。
save コマンドの実行プロセスは次の図のようになります。
② bgsave コマンド
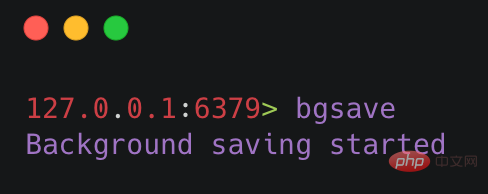
bgsave (バックグラウンド保存)両方の背景 保存の意味、保存コマンドとの最大の違いは、bgsave が子プロセスを fork() して永続化を実行することです。プロセス全体の間、子プロセスを fork() するときにブロックされるのは短いだけです。子プロセスが作成され、Redis メインプロセスが他のクライアントからのリクエストに応答できるようになり、プロセス全体をブロックする save コマンドと比較すると、bgsave コマンドの方が明らかに適しています。
bgsave コマンドは次の図のように使用されます。
bgsave の実行プロセスは次の図のようになります。

2) 自動トリガー
##RDB の手動トリガー方法について説明した後、RDB 永続性を自動的にトリガーする方法を見てみましょう。RDB の自動永続化は主に次の状況で発生します。
① save m n
save m n は、n 個のキーが m 秒以内に変更された場合、永続化が自動的にトリガーされることを意味します。パラメーター m および n は、Redis 構成ファイルにあります。たとえば、save 60 1 は、60 秒以内に少なくとも 1 つのキーが変更された場合に、RDB 永続化がトリガーされることを示します。
永続性を自動的にトリガーする: 本質的には、設定されたトリガー条件が満たされた場合に、Redis が bgsave コマンドを自動的に実行するということです。
save 60 10save 600 1
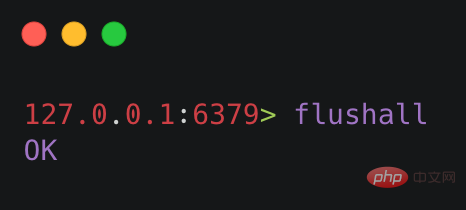
②フラッシュオール
flushall 命令用于清空 Redis 数据库,在生产环境下一定慎用,当 Redis 执行了 flushall 命令之后,则会触发自动持久化,把 RDB 文件清空。
执行结果如下图所示:
③ 主从同步触发
在 Redis 主从复制中,当从节点执行全量复制操作时,主节点会执行 bgsave 命令,并将 RDB 文件发送给从节点,该过程会自动触发 Redis 持久化。
4.配置说明
合理的设置 RDB 的配置,可以保障 Redis 高效且稳定的运行,下面一起来看 RDB 的配置项都有哪些?
RDB 配置参数可以在 Redis 的配置文件中找见,具体内容如下:
# RDB 保存的条件 save 900 1 save 300 10 save 60 10000 # bgsave 失败之后,是否停止持久化数据到磁盘,yes 表示停止持久化,no 表示忽略错误继续写文件。 stop-writes-on-bgsave-error yes # RDB 文件压缩 rdbcompression yes # 写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。 rdbchecksum yes # RDB 文件名 dbfilename dump.rdb # RDB 文件目录 dir ./
其中比较重要的参数如下列表:
① save 参数
它是用来配置触发 RDB 持久化条件的参数,满足保存条件时将会把数据持久化到硬盘。
默认配置说明如下:
save 900 1:表示 900 秒内如果至少有 1 个 key 值变化,则把数据持久化到硬盘;save 300 10:表示 300 秒内如果至少有 10 个 key 值变化,则把数据持久化到硬盘;save 60 10000:表示 60 秒内如果至少有 10000 个 key 值变化,则把数据持久化到硬盘。
② rdbcompression 参数
它的默认值是 yes 表示开启 RDB 文件压缩,Redis 会采用 LZF 算法进行压缩。如果不想消耗 CPU 性能来进行文件压缩的话,可以设置为关闭此功能,这样的缺点是需要更多的磁盘空间来保存文件。
③ rdbchecksum 参数
它的默认值为 yes 表示写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
5.配置查询
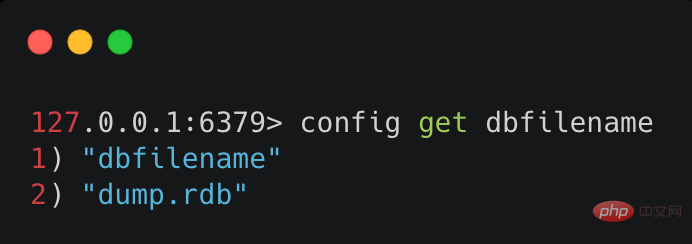
Redis 中可以使用命令查询当前配置参数。查询命令的格式为:config get xxx ,例如,想要获取 RDB 文件的存储名称设置,可以使用 config get dbfilename ,执行效果如下图所示:
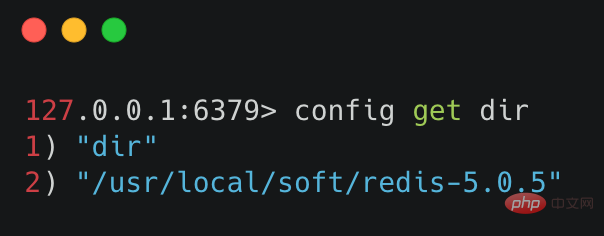
查询 RDB 的文件目录,可使用命令 config get dir ,执行效果如下图所示:
6.配置设置
设置 RDB 的配置,可以通过以下两种方式:
● 手动修改 Redis 配置文件;
● 使用命令行设置,例如,使用 config set dir "/usr/data" 就是用于修改 RDB 的存储目录。
注意:手动修改 Redis 配置文件的方式是全局生效的,即重启 Redis 服务器设置参数也不会丢失,而使用命令修改的方式,在 Redis 重启之后就会丢失。但手动修改 Redis 配置文件,想要立即生效需要重启 Redis 服务器,而命令的方式则不需要重启 Redis 服务器。
小贴士:Redis 的配置文件位于 Redis 安装目录的根路径下,默认名称为 redis.conf。
7.RDB 文件恢复
当 Redis 服务器启动时,如果 Redis 根目录存在 RDB 文件 dump.rdb,Redis 就会自动加载 RDB 文件恢复持久化数据。
如果根目录没有 dump.rdb 文件,请先将 dump.rdb 文件移动到 Redis 的根目录。
验证 RDB 文件是否被加载
Redis 在启动时有日志信息,会显示是否加载了 RDB 文件,我们执行 Redis 启动命令:src/redis-server redis.conf ,如下图所示:
从日志上可以看出, Redis 服务在启动时已经正常加载了 RDB 文件。
小贴士:Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
8.RDB 优缺点
1)RDB 优点
● RDB 的内容为二进制的数据,占用内存更小,更紧凑,更适合做为备份文件;
# RDB は災害復旧に非常に役立ちます。コンパクトなファイルなので、Redis サービスの復旧のためにリモート サーバーに高速に転送できます。
# RDB は、Redis の実行速度を大幅に向上させることができます。 Redis メイン プロセスは、データをディスクに永続化するたびに子プロセスを fork() するため、Redis メイン プロセスはディスク I/O、
#●、AOF などの操作を実行しません。フォーマットファイルに比べて、RDB ファイルはより速く再起動できます。 2) RDB のデメリット# RDB は一定期間のデータしか保存できないため、Redis サービスが誤って途中で終了すると、一定期間分の Redis データが失われます;#RDB では、子プロセスを使用してディスク上に永続化するために頻繁に fork() を必要とします。データ セットが大きい場合、Fork() は時間がかかる可能性があり、データ セットが大きく CPU パフォーマンスが低い場合には、Redis が数ミリ秒、さらには 1 秒間クライアントへのサービスを停止する可能性があります。9. 永続性の無効化
永続性を無効にすると、Redis の実行効率が向上します。データ損失に敏感でない場合は、クライアントに接続し、 # を実行できます。次の図に示すように、##config set save ""<span style="background-color: rgb(253, 234, 218); color: rgb(255, 0, 0);"></span># コマンドを使用して Redis 永続性を無効にします。 10. まとめ
この記事から、RDB の永続化には手動トリガーと自動トリガーの 2 つの方法があり、ストレージ ファイルが小さく Redis が起動するという利点があることがわかります。データの復元は高速ですが、データ損失のリスクがあるという欠点があります。 RDBファイルのリストアも非常に簡単で、RDBファイルをRedisのルートディレクトリに置くだけで、Redis起動時に自動的にデータが読み込まれてリストアされます。 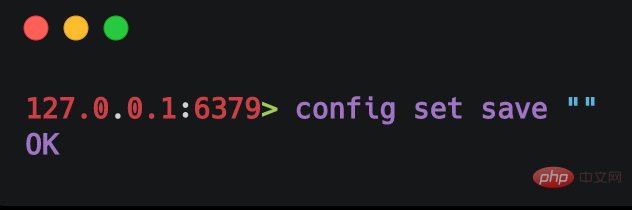
Redis 使用法チュートリアル 列をご覧ください。
以上がRedis を永続化するいくつかの方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7522
7522
 15
1378
52
81
11
21
71
15
1378
52
81
11
21
71

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
