

プログラマは、業界で有名な MD5、SHA、CRC などのハッシュ アルゴリズムに精通している必要があります。 , など; 日常の開発では、Map を使用して (キー、値) 構造を持つデータをロードしたり、ハッシュ アルゴリズム O(1) の時間計算量を使用してプログラムの処理効率を向上させたりすることがよくあります。ハッシュ アルゴリズムの他の応用シナリオをご存知ですか?
ハッシュ アルゴリズムのアプリケーション シナリオを理解する前に、まず ハッシュ (ハッシュ) の概念を見てみましょう. ハッシュとは、任意の長さの入力を固定長の出力に変換することです。入力は Key と呼ばれ、出力はハッシュ値、つまりハッシュ値 hash(key) で、ハッシュ アルゴリズムは hash() 関数です (ハッシュとハッシュはハッシュ の異なる翻訳です)。 ; 実際には、これらのハッシュ値は、ハッシュ テーブルと呼ばれる配列に格納されます。ハッシュ テーブルは、配列の機能を使用して、添え字に従ってデータへのランダム アクセスをサポートします。データ値と配列の添え字は、ハッシュ関数。1 対 1 のマッピングにより、時間計算量 O(1) のクエリを実現します。
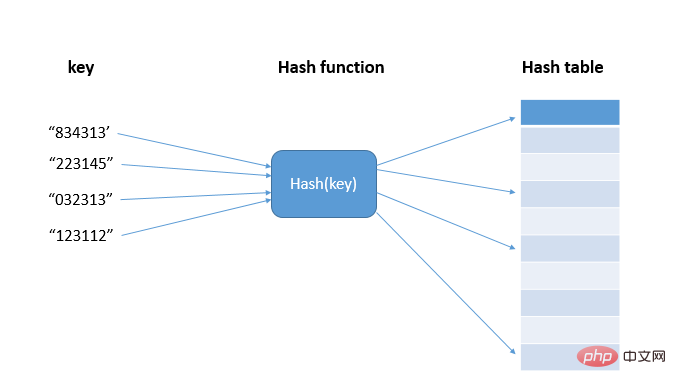
現在のハッシュ アルゴリズム MD5、SHA、CRC などは、異なるキーに対応する異なるハッシュ値を持つハッシュ関数を実現できません。つまり、異なるキーが同じ値にマッピングされる状況を避けることは不可能です。 ハッシュの競合、アレイのストレージ容量は限られているため、ハッシュの競合が発生する可能性も高くなります。ハッシュの衝突を解決するにはどうすればよいですか?私たちが一般的に使用するハッシュ競合解決方法には、オープン アドレッシングとチェーンという 2 種類があります。
線形検出によりハッシュテーブル内の空き位置を見つけ、ハッシュ値を書き込みます:
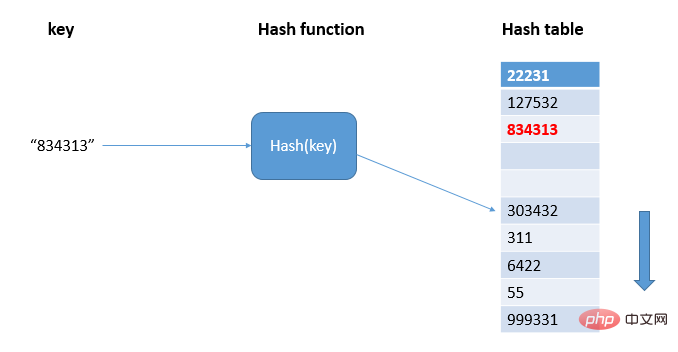
は空きスロットの数を表し、計算式は次のとおりです: ハッシュ テーブルのロード係数 = テーブルに埋められた要素の数 / ハッシュ テーブルの長さ。負荷率が大きいほど、空き場所が少なくなり、競合が多くなり、ハッシュ テーブルのパフォーマンスが低下します。 データ量が比較的少なく、負荷率が小さい場合には、オープン アドレッシング方式を使用するのが適しているため、Java の ThreadLocalMap では、オープン アドレッシング方式を使用してハッシュの競合を解決します。
1.1.2 リンク リスト方式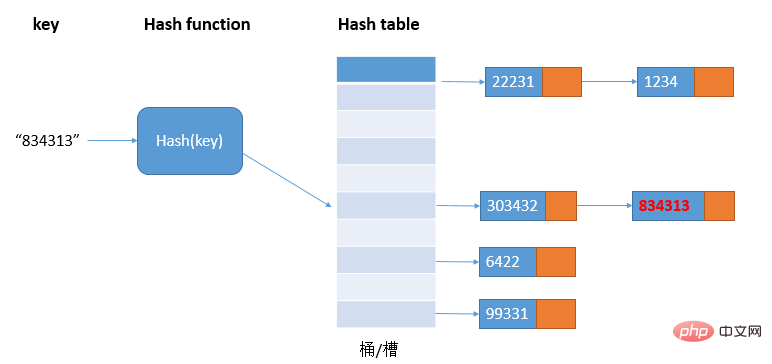 ハッシュ テーブルでは、各バケット/スロットがリンク リストに対応し、同じハッシュ値を持つすべての要素が対応するリンク リストに配置されます。中; ハッシュの競合が多い場合、リンク リストの長さも長くなり、ハッシュ値のクエリにはリンク リストを走査する必要があり、クエリ効率が O(1) から O に低下します。 (n)。
ハッシュ テーブルでは、各バケット/スロットがリンク リストに対応し、同じハッシュ値を持つすべての要素が対応するリンク リストに配置されます。中; ハッシュの競合が多い場合、リンク リストの長さも長くなり、ハッシュ値のクエリにはリンク リストを走査する必要があり、クエリ効率が O(1) から O に低下します。 (n)。
ハッシュ競合を解決するこの方法は、大きなオブジェクトと大量のデータを含むハッシュ テーブルにより適しており、リンク リストの代わりに赤黒ツリーを使用するなど、より多くの最適化戦略をサポートしています。jdk1.8 は設計されています。 HashMap をサポートするために、さらに最適化するために、赤黒ツリーが導入されます。リンク リストの長さが長すぎる場合 (デフォルトは 8 を超える場合)、リンク リストは赤黒ツリーに変換されます。このとき、赤-black ツリーを使用すると、HashMap のパフォーマンスを向上させるために、迅速に追加、削除、確認、および変更を行うことができます。赤黒ツリー ノードの数が 8 未満の場合、赤黒ツリーはリンク リストに変換されます。データ量が比較的少ない場合、赤黒ツリーはバランスを保つ必要があるため、リンク リストと比較してパフォーマンス上の利点は明らかではありません。
2. ハッシュ アルゴリズムの適用シナリオMD5 を例にとると、ハッシュ値は固定の 128 ビット バイナリ文字列であり、最大 2^128 データを表すことができます。このデータはすでに天文学的な数であり、ハッシュの競合の可能性は低くなります。この MD5 と同じデータを網羅的に検索しようとすると、天文学的な時間がかかるため、限られた時間内にハッシュ アルゴリズムを解読するのは依然として困難です。暗号化効果が得られることを示します。
2.2 データ検証 機能を使用すると、ネットワーク送信中のデータが正しいかどうかを検証できます。 、悪意のある改ざんを防ぐため。 ハッシュ関数の相対的 一様分布特性を利用して、ハッシュ値はデータ ストレージの位置値として使用されます。データはコンテナ内に均等に分散されます。 ハッシュ アルゴリズムを使用して、クライアント ID アドレスまたはセッション ID のハッシュ値を計算し、取得したハッシュ値をサーバー リスト モジュロ演算を行った後の最終値は、ルーティング先のサーバー番号になります。 ユーザーの検索キーワードを記録する 1T ログ ファイルがある場合、各キーワードの回数をすばやくカウントしたいと考えます。キーワード が検索されました。どうすればよいですか?データの量が比較的多く、1 台のマシンのメモリに置くのは困難です。1 台のマシンに置いたとしても、処理時間は非常に長くなります。この問題を解決するには、まずデータを断片化して、次に、複数のマシンを使用して処理する方法を使用して、処理速度を向上させます。 具体的なアイデアは次のとおりです。処理速度を向上させるために、n 台のマシンを使用して並列処理します。検索記録のログ ファイルから、各検索キーワードを順番に分析し、ハッシュ関数を使用して n を法として計算したハッシュ値が、割り当てられるべきマシン番号になります。ハッシュ値 同じ値を持つ検索キーワードは同じマシンに割り当てられ、各マシンはキーワードの出現数を個別にカウントし、最終的にそれらを結合して最終結果を取得します。実はここの処理プロセスはMapReduceの基本的な設計思想でもあります。 大量のデータをキャッシュする必要がある状況では、1 台のキャッシュ マシンでは明らかに不十分であるため、データを 1 台の複数のキャッシュ マシンに分散する必要があります。機械。
このとき、以前のシャーディングのアイデアを使用できます。つまり、ハッシュ アルゴリズムを使用してデータのハッシュ値を取得し、マシン数の剰余を取得して、保存する必要があるキャッシュ マシン番号を取得します。 しかし、データが増加すると、元の10台のマシンでは耐えられなくなり、拡張する必要が生じます。このとき、すべてのデータのハッシュ値を再計算して正しいマシンに移動すると、キャッシュされたデータはすべて一度に無効になるため、キャッシュを突き抜けてソースに戻り、雪崩現象を引き起こしてデータベースを圧倒する可能性があります。すべてのデータを移動せずに新しいキャッシュ マシンを追加するには、 Consistent Hash Algorithm がより良い選択です。主なアイデアは次のとおりです: kge マシンがあると仮定すると、データのハッシュ値の範囲は [0] , Max] で、範囲全体を m 個の小さな間隔に分割します (m は k よりもはるかに大きいです)。各マシンは m/k 個の小さな間隔を担当します。新しいマシンが参加すると、元のマシンから特定の小さな間隔のデータを分割します。この方法では、すべてのデータを再ハッシュして移動する必要がなく、各マシン上のデータ量のバランスが維持されます。 実際、ハッシュ アルゴリズムには、git commit id など、他にも多くのアプリケーションがあります。理解と拡張は、基本的なデータ構造とアルゴリズムの価値を体現するものでもあり、仕事の中でゆっくりと理解して経験する必要があります。 推奨チュートリアル: 「Java チュートリアル 」2.3 ハッシュ関数
2.4 負荷分散
2.5 データの断片化
2.6 分散ストレージ
3. 最後に書かれています
以上が一般的に使用されるアルゴリズム: ハッシュ アルゴリズムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



