
文字列または文字列は、数字、文字、およびアンダースコアで構成される文字列です。 - プログラミング言語でテキストを表すデータ型です。プログラミングにおいて、文字列とは、記号文字列 (文字列) やバイナリ数字文字列 (2 進数字の文字列) など、記号または値の連続したシーケンスです。
通常、文字列内の部分文字列の検索、部分文字列の取得、文字列内の特定の位置への部分文字列の挿入、部分文字列の削除など、文字列全体が操作オブジェクトとして使用されます。 WeChat アプレットでは、string 文字列を '' または "" で宣言でき、長さは length 属性で取得できます。一般的に使用される方法は、検索、傍受、変換に分類できます。
charAt(index): 指定された位置の文字を取得します (添字インデックスは 0 から始まります);
charCodeAt(index): 指定された位置の文字の Unicode エンコーディングを取得します (添字インデックスは 0 から始まります);
indexOf(searchvalue,start): 部分文字列を先頭から逆方向に検索します。文字列が見つかりませんでした。一致した場合は、-1 が返されます。searchvalue は取得する文字列値、start は開始位置、デフォルトは 0 です。
lastIndexOf(searchvalue,start): 文字列の末尾から順に部分文字列を検索します。一致するものが見つからない場合は、-1 が返されます。searchvalue は取得する文字列値、start は開始位置、デフォルトは末尾の 1 文字です。
localeCompare(target): ローカル固有の順序で 2 つの文字列を比較します;
match(regexp): 一致する結果を保存する配列;
search(searchvalue) : 開始値を指定します検索文字列の位置。searchvalue は検索文字列または正規表現です。
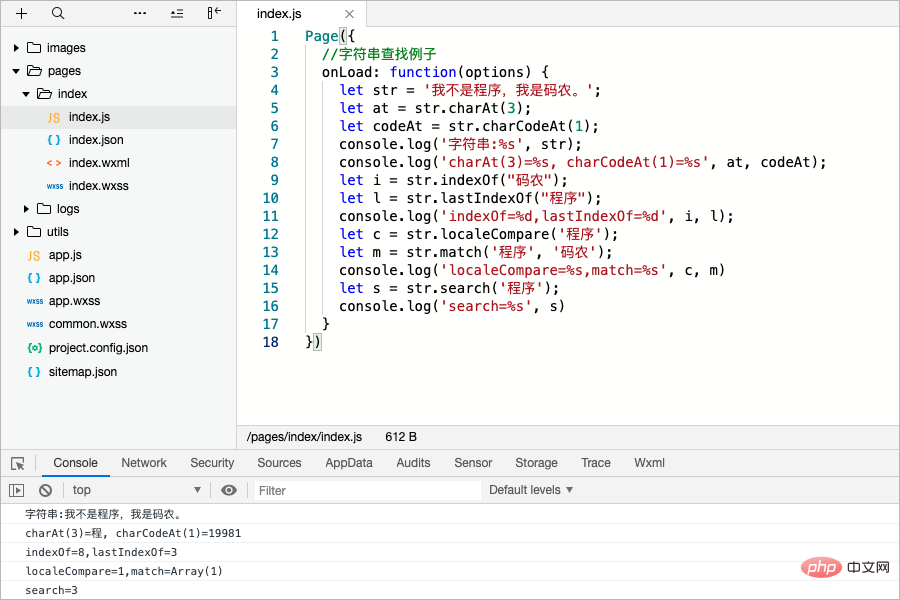
Page({ //字符串查找方法例子
onLoad: function(options) {
let str = '我不是程序,我是码农。';
let at = str.charAt(3);
let codeAt = str.charCodeAt(1);
console.log('字符串:%s', str);
console.log('charAt(3)=%s, charCodeAt(1)=%s', at, codeAt);
let i = str.indexOf("码农");
let l = str.lastIndexOf("程序");
console.log('indexOf=%d,lastIndexOf=%d', i, l);
let c = str.localeCompare('程序');
let m = str.match('程序', '码农');
console.log('localeCompare=%s,match=%s', c, m)
let s = str.search('程序');
console.log('search=%s', s)
}
})
slice(start,end): 文字列の特定の部分を抽出しますを実行し、抽出された部分を新しい文字列として返します。 Start は必須フィールドで、抽出されるフラグメントの開始インデックスであり、最初の文字位置は 0 です。 end はオプションで、その後に抽出するセグメントの終わりの添え字が続きます。
split(separator,limit): 区切り文字列または正規表現、オプション。制限はオプションであり、デフォルトは配列の最大長です。
substring(from,to): from は必須です。正の整数で、文字列内で抽出される部分文字列の最初の文字の位置を指定します。 to はオプションです。正の整数。デフォルトでは、返される部分文字列は文字列の末尾に移動します。
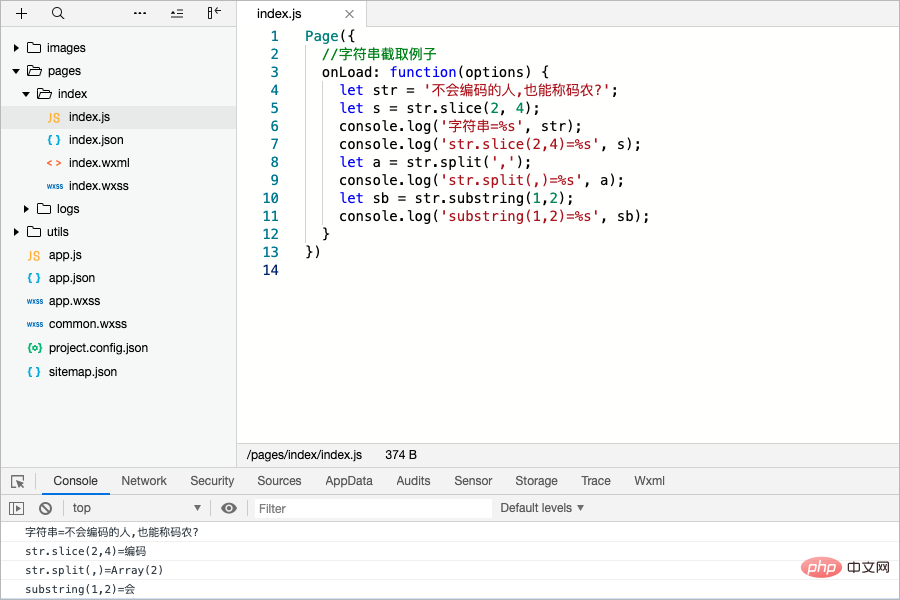
Page({ //字符串截取例子
onLoad: function(options) {
let str = '不会编码的人,也能称码农?';
let s = str.slice(2, 4);
console.log('字符串=%s', str);
console.log('str.slice(2,4)=%s', s);
let a = str.split(',');
console.log('str.split(,)=%s', a);
let sb = str.substring(1,2);
console.log('substring(1,2)=%s', sb);
}
})
toString() メソッド; 数値、文字列、オブジェクト、ブール値;すべてに toString メソッドが必要です。このメソッドでできることは、対応する文字列を返すことだけです。null と unknown には toString() メソッドがありません。
String() は強制変換であり、null 変換の結果です。 null; 未定義の変換 結果は未定義; 残りについては、toString() メソッドがある場合、そのメソッドが呼び出され、対応する結果が返されます;
valueOf: String オブジェクトの元の値を返します、暗黙的に呼び出されます;
String .fromCharCode(n1, n2, ..., nX): Unicode エンコーディングを文字に変換します;
toLowerCase: 文字列を小文字に変換するために使用されます;
toLocaleLowerCase: と toLowerCase( ) 違いは、 toLocaleLowerCase() メソッドがローカル メソッドに従って文字列を小文字に変換することです。少数の言語 (トルコ語など) のみがローカルな大文字と小文字のマッピングを持っているため、このメソッドの戻り値は通常 toLowerCase() と同じになります。
toUpperCase: 文字列を大文字に変換します。
toLocaleUpperCase: toUpperCase() とは異なり、toLocaleUpperCase() メソッドはローカル メソッドに従って文字列を大文字に変換します。少数の言語 (トルコ語など) のみがローカルな大文字と小文字のマッピングを持っているため、このメソッドの戻り値は通常 toUpperCase() と同じになります。
Page({ //字符串转换例子
onLoad: function(options) {
let str = "i love Programming.";
let v = str.valueOf();
console.log('字符串=%s', str);
console.log('valueOf=%s', v);
let l = str.toLowerCase();
let u = str.toUpperCase();
console.log('toLowerCase=%s,toUpperCase=%s', l, u);
let f = String.fromCharCode('30721', '20892');
console.log('fromCharCode=%s', f);
}
})
string1, ..., stringX): 2 つ以上の文字列を接続し、新しい文字列を返します;
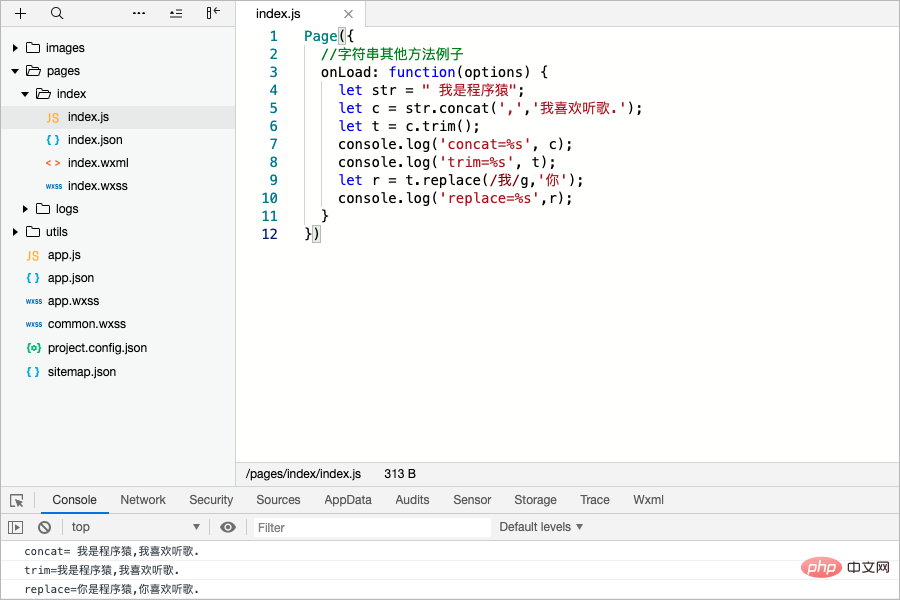
trim: 文字列の両側の空白を削除します; replace(searchvalue, newvalue):文字列内で一致する部分文字列を検索し、正規表現に一致する部分文字列を置き換えます。Page({ //字符串其他方法例子
onLoad: function(options) {
let str = " 我是程序猿";
let c = str.concat(',','我喜欢听歌.');
let t = c.trim();
console.log('concat=%s', c);
console.log('trim=%s', t);
let r = t.replace(/我/g,'你');
console.log('replace=%s',r);
}
})
WeChat ミニ プログラム」
以上が小さなプログラムでの文字列の使用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



