

Linux のキャッシュ メモリについて Cache Memory (詳細な図とテキストの説明)
今日のトピック探索はキャッシュです。いくつかの質問を中心に考えていきます。なぜキャッシュが必要なのでしょうか?キャッシュ内のデータがヒットしたかどうかを判断するにはどうすればよいですか?キャッシュの種類と違いは何ですか?
キャッシュとは何かを考える前に、まず最初の質問について考えてみましょう。プログラムはどのように実行されるのでしょうか?プログラムは RAM で実行され、RAM は通常 DDR (DDR3、DDR4 など) と呼ばれるものであることを知っておく必要があります。これをメイン メモリと呼びますが、プロセスを実行する必要がある場合、まず実行可能プログラムをフラッシュ デバイス (eMMC、UFS など) からメイン メモリにロードしてから、実行を開始します。 CPU内部には汎用レジスタ(レジスタ)が多数存在します。 CPU が変数に 1 を加算する必要がある場合 (アドレスが A であると仮定)、一般に次の 3 つのステップに分かれます。
CPU はアドレス A のデータを読み取ります。メインメモリから内部汎用レジスタ x0 (ARM64 アーキテクチャの汎用レジスタの 1 つ) へ。
# 汎用レジスタ x0 に 1 を加算します。
CPU は汎用レジスタ x0 の値をメインメモリに書き込みます。
このプロセスは次のように表現できます。
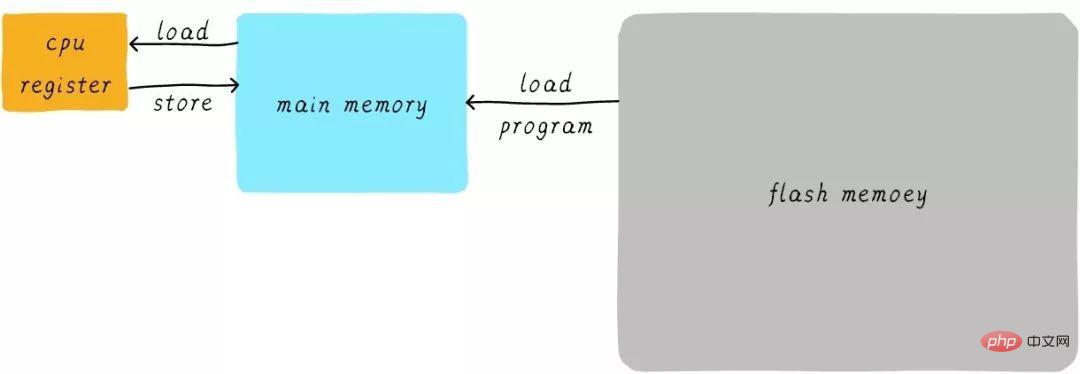
実際には、CPU の速度は一般的にレジスタとメインメモリ それらの間には大きな違いがあります。両者の速度関係はおおよそ次のとおりです。
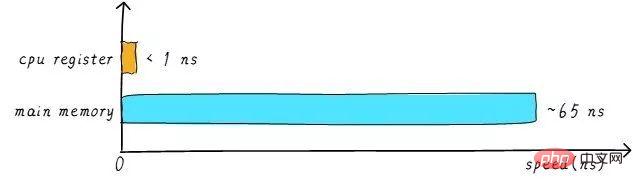
CPU レジスタの速度は通常 1ns 未満で、メイン メモリの速度は通常約 65ns です。速度の差は100倍近くあります。したがって、上記の例の 3 つのステップのうち、ステップ 1 と 3 は実際には非常に遅いです。 CPU がメイン メモリから操作をロード/ストアしようとすると、メイン メモリの速度制限により、CPU はこの長い 65ns 待機する必要があります。メインメモリの速度を上げることができれば、システムのパフォーマンスは大幅に向上します。
今日の DDR ストレージ デバイスは、簡単に数 GB の大容量を搭載できます。より高速な材料を使用してより高速なメインメモリを作成し、容量がほぼ同じだとします。そのコストは大幅に上昇します。私たちは、コストが非常に低いことを期待しながら、メインメモリの速度と容量を増加しようとしていますが、これは少し恥ずかしいことです。したがって、非常に高速だが容量が非常に小さいストレージデバイスを作成するという妥協の方法があります。そうすれば費用もそれほど高くはなりません。このストレージデバイスをキャッシュメモリと呼びます。
ハードウェア的には、メインメモリのデータのキャッシュとしてCPUとメインメモリの間にキャッシュを配置します。 CPU がメイン メモリからデータをロード/ストアしようとすると、CPU はまずキャッシュからチェックして、対応するアドレスのデータがキャッシュにキャッシュされているかどうかを確認します。データがキャッシュにキャッシュされている場合、データはキャッシュから直接取得され、CPU に返されます。キャッシュがある場合、上記のプログラム実行例の処理は次のようになります。
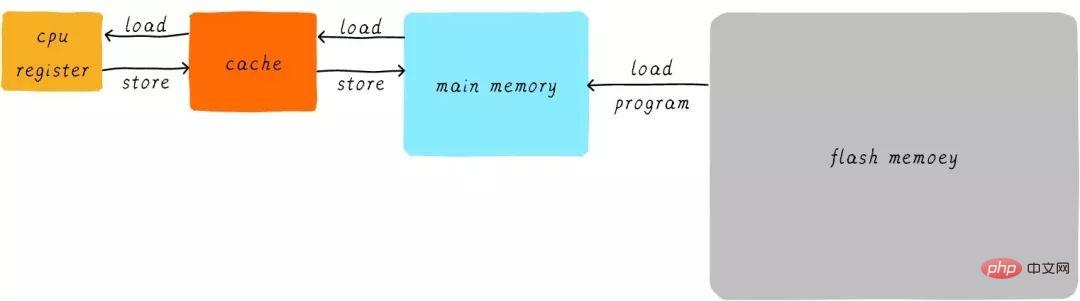
CPUとメインメモリ間の直接データ転送方式が変わります。 CPUとメインメモリ間で直接データ転送を行う方式へ キャッシュ間で直接データ転送を行う方式へキャッシュはメインメモリとメインメモリ間のデータ転送を担当します。
キャッシュの速度もシステムのパフォーマンスにある程度影響します。
一般に、キャッシュ速度は 1ns に達する可能性があり、これは CPU レジスタ速度とほぼ同等です。しかし、これで人々のパフォーマンスの追求は満たされるのでしょうか?全くない。必要なデータがキャッシュにキャッシュされていない場合でも、メインメモリからデータをロードするために長時間待つ必要があります。パフォーマンスをさらに向上させるために、マルチレベル キャッシュが導入されています。
先ほどのキャッシュはL1キャッシュ(一次キャッシュ)と呼ばれます。 L1 キャッシュの後ろに L2 キャッシュを接続し、L2 キャッシュとメイン メモリの間に L3 キャッシュを接続します。レベルが高くなるほど、速度は遅くなり、容量は大きくなります。しかし、メインメモリと比較すると、それでも速度は非常に高速です。さまざまなレベルのキャッシュ速度の関係は次のとおりです。
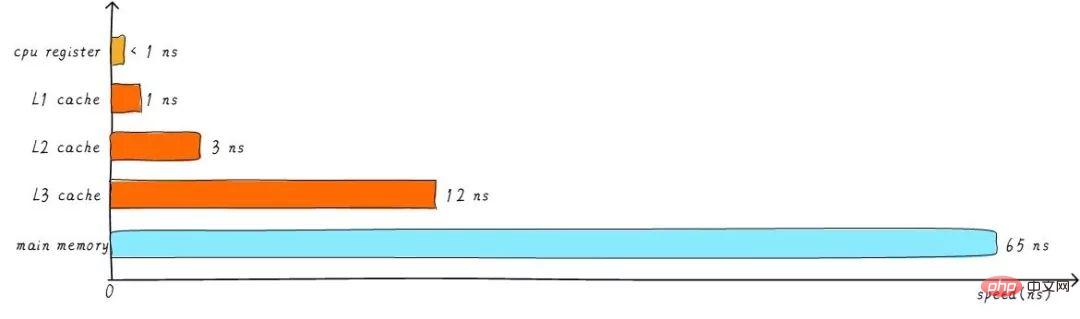
レベル 3 キャッシュのバッファリングの後、キャッシュとメイン メモリの各レベルの速度差も段階的に減少します。ステップ。実際のシステムでは、ハードウェアはすべてのレベルのキャッシュ間でどのように関係しているのでしょうか?次のように、Cortex-A53 アーキテクチャ上のすべてのレベルのキャッシュ間のハードウェア抽象ブロック図を見てみましょう。
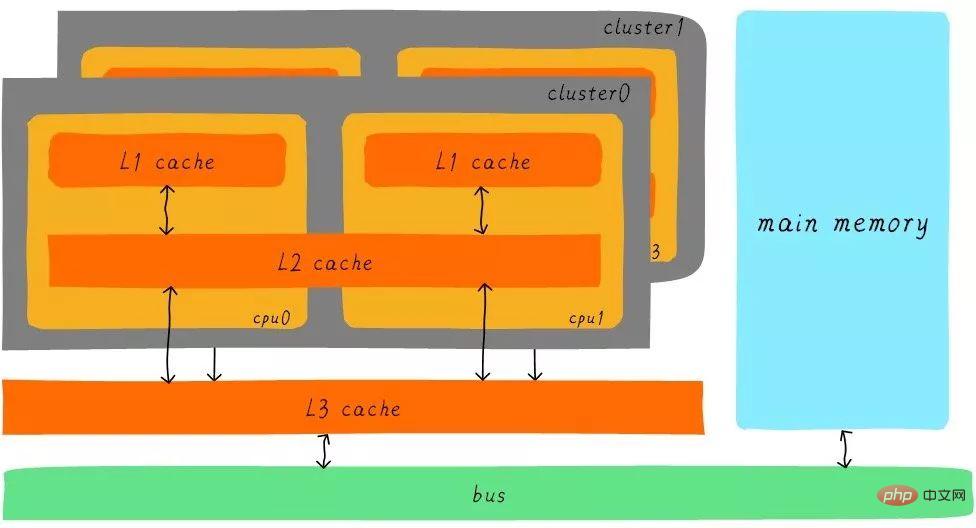
Cortex-A53 アーキテクチャでは、L1 キャッシュは個別の命令キャッシュ (ICache) とデータ キャッシュ (DCache) に分割されます。 L1 キャッシュは CPU 専用であり、各 CPU に L1 キャッシュがあります。クラスタ内のすべての CPU は L2 キャッシュを共有します。L2 キャッシュは命令とデータを区別せず、両方をキャッシュできます。 L3 キャッシュはすべてのクラスター間で共有されます。 L3 キャッシュはバスを介してメイン メモリに接続されます。
最初に、ヒットとミスという 2 つの名詞の概念を紹介します。 CPU がアクセスしたいデータがキャッシュにキャッシュされることを「ヒット」といい、その逆を「ミス」といいます。マルチレベルキャッシュはどのように連携するのでしょうか?検討中のシステムには 2 レベルのキャッシュしかないと仮定します。
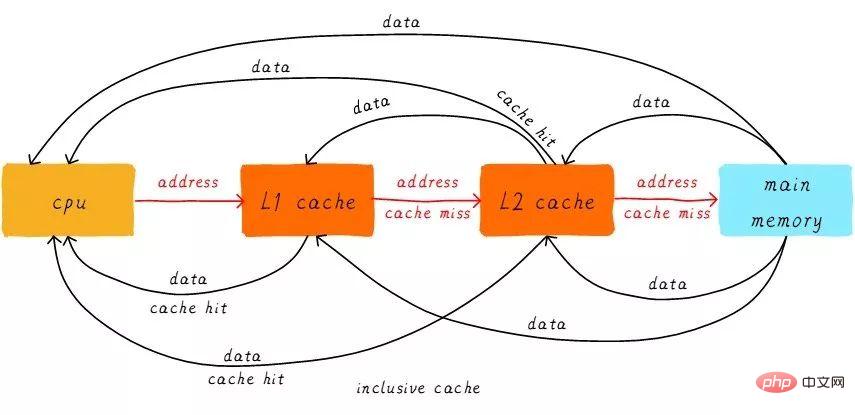
CPU がアドレスからデータをロードしようとすると、まず L1 キャッシュからヒットがあるかどうかを確認し、ヒットした場合はデータが CPU に返されます。 。 L1 キャッシュが見つからない場合は、L2 キャッシュから検索を続けます。 L2 キャッシュがヒットすると、データは L1 キャッシュと CPU に返されます。残念ながら L2 キャッシュも欠落している場合は、メイン メモリからデータをロードして、そのデータを L2 キャッシュ、L1 キャッシュ、CPU に返す必要があります。このマルチレベルキャッシュの動作方法は包括的キャッシュと呼ばれます。
特定のアドレスのデータは、マルチレベル キャッシュに存在する可能性があります。包含キャッシュに対応するのは排他キャッシュです。これにより、特定のアドレスのデータ キャッシュがマルチレベル キャッシュの 1 つのレベルにのみ存在することが保証されます。つまり、どのアドレスのデータも L1 キャッシュと L2 キャッシュに同時にキャッシュすることはできません。
キャッシュ関連の用語をいくつか紹介していきます。キャッシュのサイズはキャッシュ サイズと呼ばれ、キャッシュがキャッシュできる最大データのサイズを表します。キャッシュを多数の等しいブロックに分割し、各ブロックのサイズをキャッシュ ラインと呼び、そのサイズがキャッシュ ライン サイズです。
たとえば、64 バイト サイズのキャッシュ。 64 バイトを 64 ブロックに均等に分割すると、キャッシュ ラインは 1 バイトとなり、合計で 64 キャッシュ ラインになります。 64 バイトを 8 ブロックに均等に分割すると、キャッシュ ラインは 8 バイトとなり、合計 8 つのキャッシュ ラインが存在します。現在のハードウェア設計では、一般的なキャッシュ ライン サイズは 4 ~ 128 バイトです。なぜ1バイトもないのでしょうか?理由については後ほど説明します。
ここで注意すべき点は、キャッシュ ラインがキャッシュとメイン メモリ間のデータ転送の最小単位であるということです。それはどういう意味ですか? CPU が 1 バイトのデータをロードしようとしたときに、キャッシュが見つからない場合、キャッシュ コントローラーはキャッシュ ライン サイズのデータをメイン メモリからキャッシュに一度にロードします。たとえば、キャッシュ ラインのサイズは 8 バイトです。 CPU が 1 バイトを読み取る場合でも、キャッシュが失われた後、キャッシュはメイン メモリから 8 バイトをロードして、キャッシュ ライン全体を埋めます。なぜ?話し終わったら分かるでしょう。
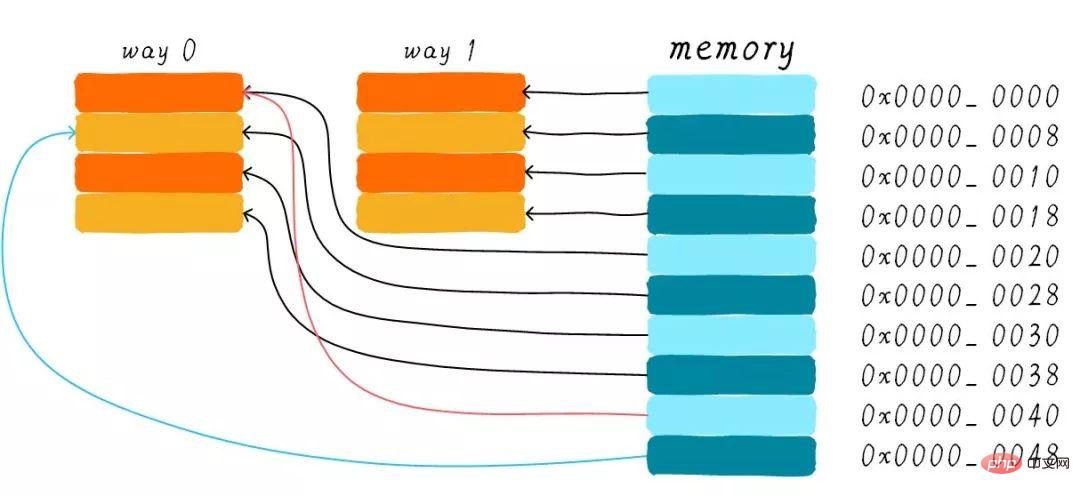
以下の説明は、64 バイト サイズのキャッシュ、およびキャッシュ ライン サイズは 8 バイトであると仮定します。このキャッシュは配列として考えることができ、配列には合計 8 つの要素があり、各要素のサイズは 8 バイトです。下の写真のようになります。

ここで問題を考えます。CPU はアドレス 0x0654 からバイトを読み取ります。キャッシュ コントローラーはデータがキャッシュにヒットしたかどうかをどのように判断するのでしょうか?キャッシュ サイズはメイン メモリに比べて小さくなります。したがって、キャッシュはメイン メモリ内のデータのごく一部のみをキャッシュできる必要があります。サイズが限られたキャッシュ内でアドレスに基づいてデータを見つけるにはどうすればよいでしょうか?ハードウェアが現在採用しているアプローチは、アドレスをハッシュすることです (これはアドレス モジュロ演算として理解できます)。次にそれがどのように行われるかを見てみましょう?

合計 8 つのキャッシュ ラインがあり、キャッシュ ラインのサイズは 8 バイトです。したがって、アドレスの下位 3 ビット (上記のアドレスの青い部分に示すように) を使用して、8 バイト内の特定のバイトをアドレス指定できます。このビットの組み合わせをオフセットと呼びます。同様に、すべてのラインをカバーするために 8 ラインのキャッシュ ラインが使用されます。
特定の行を見つけるには 3 ビット (上のアドレスの黄色の部分に示すように) が必要です。アドレスのこの部分はインデックスと呼ばれます。これで、2 つの異なるアドレスの bit3 ~ bit5 がまったく同じである場合、ハードウェア ハッシュ後に 2 つのアドレスが同じキャッシュ ラインを見つけることがわかりました。したがって、キャッシュラインが見つかった場合、それはアクセスしたアドレスに対応するデータがそのキャッシュラインに存在する可能性があることを意味するだけであり、他のアドレスに対応するデータである可能性もあります。そこでタグ配列領域を導入し、タグ配列とデータ配列を1対1に対応させます。
各キャッシュ ラインは固有のタグに対応しており、タグに格納されるのは、インデックスとオフセットで使用されるビットを除いたアドレス全体の残りのビット幅です (上記のアドレスの緑色の部分に示されています)。タグ、インデックス、オフセットの組み合わせによりアドレスを一意に決定できます。したがって、アドレスのインデックスビットに基づいてキャッシュラインを見つけると、現在のキャッシュラインに対応するタグを取り出し、アドレスのタグと比較し、それらが等しい場合、キャッシュヒットを意味します。 。それらが等しくない場合は、現在のキャッシュ ラインが他のアドレスにデータを格納していることを意味し、これはキャッシュ ミスです。
上の図では、タグの値が 0x19 であり、アドレスのタグ部分と等しいため、このアクセス中にヒットします。タグの導入により、以前の質問の 1 つである「ハードウェア キャッシュ ラインが 1 バイトにならないのはなぜですか?」が解決されました。これはハードウェアのコストの増加につながります。これは、当初は 8 バイトが 1 つのタグに対応していましたが、現在は 8 つのタグが必要となり、多くのメモリを占有するためです。
画像から、タグの隣に有効ビットがあることがわかります。このビットは、キャッシュ ライン内のデータが有効かどうかを示すために使用されます (例: 1 は有効、0 は無効を意味します) 。システムの最初の起動時は、まだデータがキャッシュされていないため、キャッシュ内のデータは無効であるはずです。キャッシュコントローラは、バリッドビットに基づいて現在のキャッシュラインデータが有効であるかどうかを確認することができる。したがって、上記の比較タグはキャッシュ ラインがヒットしたかどうかを確認する前に、有効ビットが有効かどうかも確認します。タグの比較は、タグが有効な場合にのみ意味を持ちます。無効な場合は、直接キャッシュが欠落していると判断される。
上記の例では、キャッシュ サイズは 64 バイト、キャッシュ ライン サイズは 8 バイトです。オフセット、インデックス、タグはそれぞれ 3 ビット、3 ビット、42 ビットを使用します (アドレス幅が 48 ビットであると仮定)。次に、別の例を見てみましょう。キャッシュ サイズが 512 バイト、キャッシュ ライン サイズが 64 バイトです。従来のアドレス分割方法では、オフセット、インデックス、タグにそれぞれ 6 ビット、3 ビット、39 ビットを使用します。以下に示すように。

ダイレクト マップ キャッシュはハードウェア設計が単純になるため、コストは次のようになります。低い 低い。ダイレクト マッピング キャッシュの動作方法に従って、メイン メモリ アドレス 0x00 ~ 0x88 に対応するキャッシュ分布図を描くことができます。
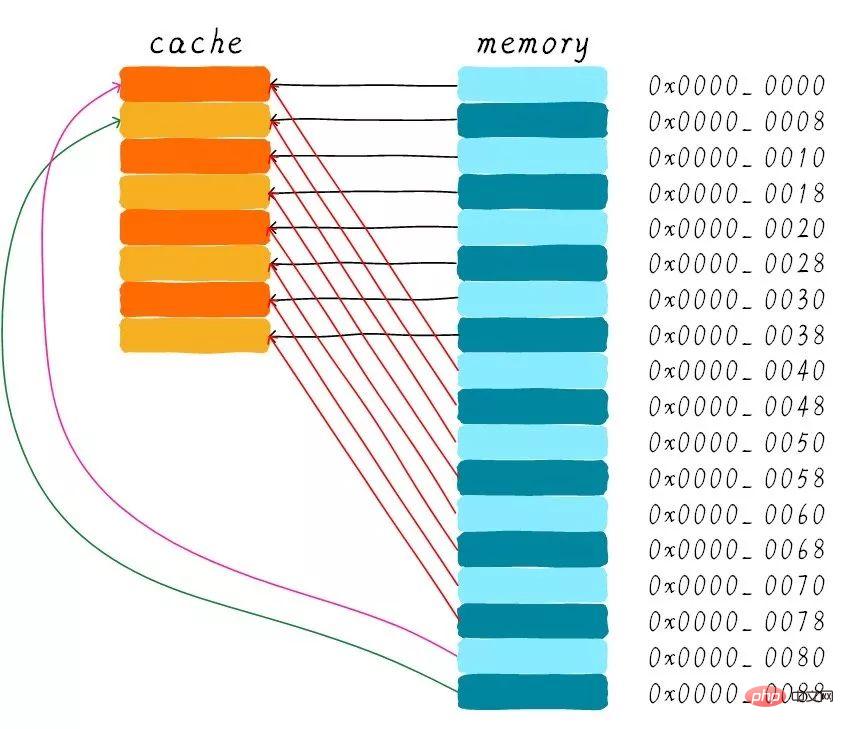
アドレス 0x00 ~ 0x3f に対応するデータがキャッシュ全体をカバーできることがわかります。アドレス 0x40 ~ 0x7f のデータもキャッシュ全体をカバーします。プログラムがアドレス 0x00、0x40、0x80 に順番にアクセスしようとすると、キャッシュ内のデータはどうなるでしょうか?
まず、0x00、0x40、0x80 アドレスのインデックス部分は同じであることを理解する必要があります。したがって、これら 3 つのアドレスに対応するキャッシュ ラインは同じです。したがって、アドレス 0x00 にアクセスすると、キャッシュが失われ、データはメイン メモリからキャッシュ ライン 0 にロードされます。 0x40 アドレスにアクセスすると、キャッシュ内の 0 番目のキャッシュ ラインにインデックスが付けられますが、この時点ではキャッシュ ラインにはアドレス 0x00 に対応するデータが格納されているため、この時点ではキャッシュはまだ存在しません。次に、0x40 アドレス データをメイン メモリから最初のキャッシュ ラインにロードします。同様に、0x80 アドレスにアクセスし続けると、キャッシュは引き続き失われます。
これは、毎回メイン メモリからデータを読み取ることに相当するため、キャッシュが存在してもパフォーマンスは向上しません。アドレス 0x40 にアクセスすると、アドレス 0x00 にキャッシュされたデータが置き換えられます。この現象はキャッシュ スラッシングと呼ばれます。この問題を解決するために、マルチウェイ グループ接続キャッシュを導入します。まず、最も単純な双方向のセット接続キャッシュがどのように機能するかを調べてみましょう。
キャッシュ サイズは 64 バイト、キャッシュ ライン サイズは 8 バイトであると仮定します。 。道路の概念とは何ですか?キャッシュを複数の等しい部分に分割し、各部分が 1 つのウェイになります。したがって、双方向セット接続キャッシュはキャッシュを 2 つの等しい部分に分割し、各部分は 32 バイトになります。以下に示すように。
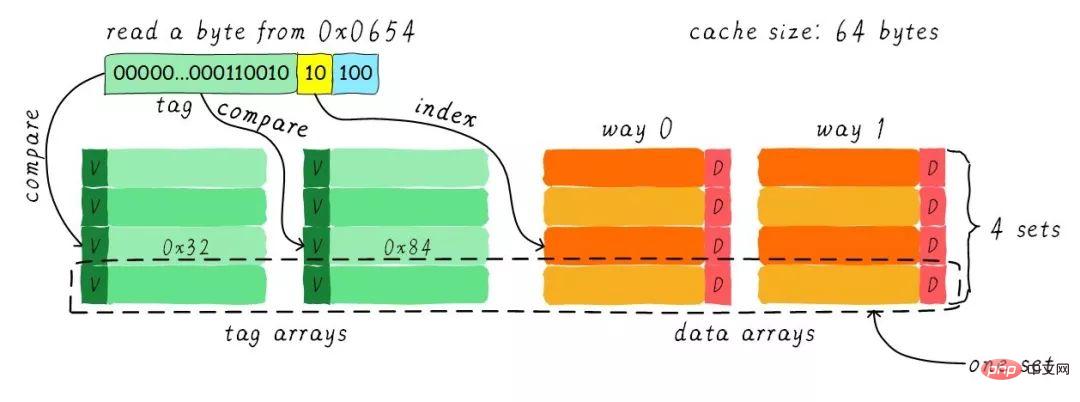
#キャッシュは 2 つのパスに分割されており、各パスには 4 つのキャッシュ ラインが含まれています。同じインデックスを持つすべてのキャッシュ ラインをグループ化し、グループと呼びます。たとえば、上の図では、グループに 2 つのキャッシュ ラインがあり、合計 4 つのグループがあります。ここでも、1 バイトのデータがアドレス 0x0654 から読み取られると仮定します。キャッシュラインのサイズは 8 バイトであるため、オフセットには 3 ビットが必要で、これは以前のダイレクト マッピング キャッシュと同じです。違いはインデックスであり、双方向セット接続キャッシュでは、片方向にキャッシュ ラインが 4 つしかないため、インデックスに必要なビットは 2 ビットだけです。
上記の例では、インデックス (0 から計算) に基づいて 2 番目のキャッシュ ラインを検索します。2 番目のラインは 2 つのキャッシュ ラインに対応し、それぞれウェイ 0 とウェイ 1 に対応します。したがって、インデックスはセットインデックス (グループインデックス) とも呼ばれます。まずインデックスに従ってセットを見つけ、グループ内のすべてのキャッシュラインに対応するタグを取り出し、アドレスのタグ部分と比較し、どれか1つでも一致すればヒットとなります。
したがって、双方向セット接続キャッシュとダイレクトマップキャッシュの最大の違いは、先頭アドレスに対応するデータが2キャッシュラインに対応できるのに対し、ダイレクトマップキャッシュでは、 1 つのアドレスは 1 つのキャッシュ ラインにのみ対応します。では、これには具体的にどのようなメリットがあるのでしょうか?
双方向セット接続キャッシュのハードウェア コストは、ダイレクト マップ キャッシュのハードウェア コストよりも高くなります。タグを比較するたびに、複数のキャッシュ ラインに対応するタグを比較する必要があるためです (一部のハードウェアでは、比較速度を上げるために並列比較を実行することもありますが、これによりハードウェア設計が複雑になります)。
なぜ依然として双方向グループ接続キャッシュが必要なのでしょうか?キャッシュのスラッシングの可能性を減らすことができるためです。では、どのように削減されるのでしょうか?双方向セット接続キャッシュの動作方法によれば、メインメモリアドレス 0x00 ~ 0x4f に対応するキャッシュ分布図を描くことができます。
ダイレクト マップ キャッシュのセクションでは、「プログラムがアドレス 0x00、0x40、0x80 に順番にアクセスしようとすると、データはどうなるのか」という質問について引き続き検討します。キャッシュにあるの?」これで、アドレス 0x00 のデータをウェイ 1 にロードし、0x40 をウェイ 0 にロードできるようになります。これにより、ダイレクト マッピング キャッシュという厄介な状況はある程度回避されますか?双方向セット接続キャッシュの場合、アドレス 0x00 と 0x40 のデータがキャッシュにキャッシュされます。想像してみてください。4 ウェイ グループ接続キャッシュを使用している場合、後で 0x80 にアクセスし続けると、それもキャッシュされる可能性があります。
したがって、キャッシュサイズが一定の場合、グループ接続キャッシュのパフォーマンス向上は、最悪の場合でもダイレクトマップキャッシュと同じであり、ほとんどの場合、グループ接続キャッシュの効果は次のとおりです。ダイレクトマップキャッシュよりも優れています。同時に、キャッシュのスラッシングの頻度も減少します。ある意味、ダイレクト マップ キャッシュはセットリンク キャッシュの特殊なケースであり、グループごとに 1 つのキャッシュ ラインしかありません。したがって、ダイレクト マップ キャッシュは、一方向セット接続キャッシュとも呼ばれます。
グループ関連キャッシュは非常に優れているため、すべてのキャッシュ ラインがグループ内にある場合。パフォーマンスも良くなるのではないでしょうか?はい、この種類のキャッシュは完全接続キャッシュです。ここでも例として 64 バイト サイズのキャッシュを取り上げます。
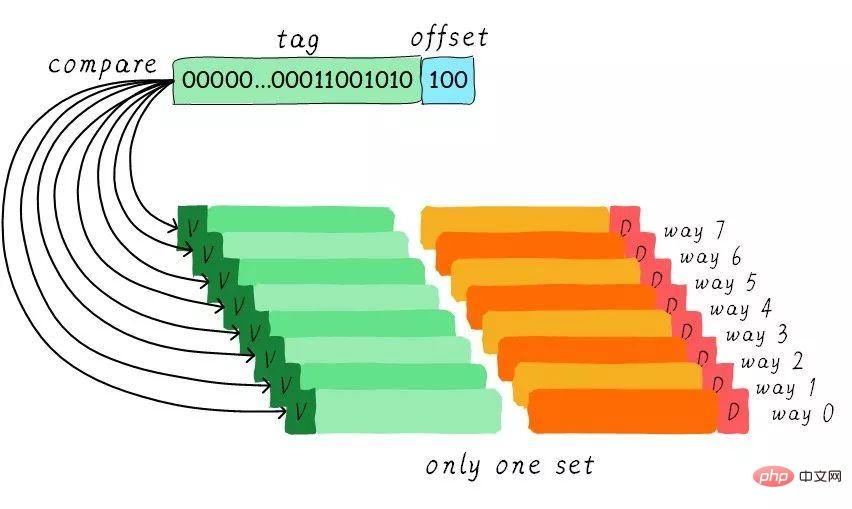
すべてのキャッシュ ラインがグループ内にあるため、アドレスにセット インデックス部分は必要ありません。なぜなら、選択できるグループは 1 つだけであり、間接的には選択の余地がないことを意味するからです。アドレスのタグ部分をすべてのキャッシュ ラインに対応するタグと比較します (ハードウェアは並列比較またはシリアル比較を実行できます)。どのタグが等しいということは、特定のキャッシュラインがヒットしたことを意味します。したがって、完全接続キャッシュでは、任意のアドレスのデータを任意のキャッシュ ラインにキャッシュできます。したがって、これによりキャッシュのスラッシングの頻度を最小限に抑えることができます。ただし、ハードウェアのコストも高くなります。
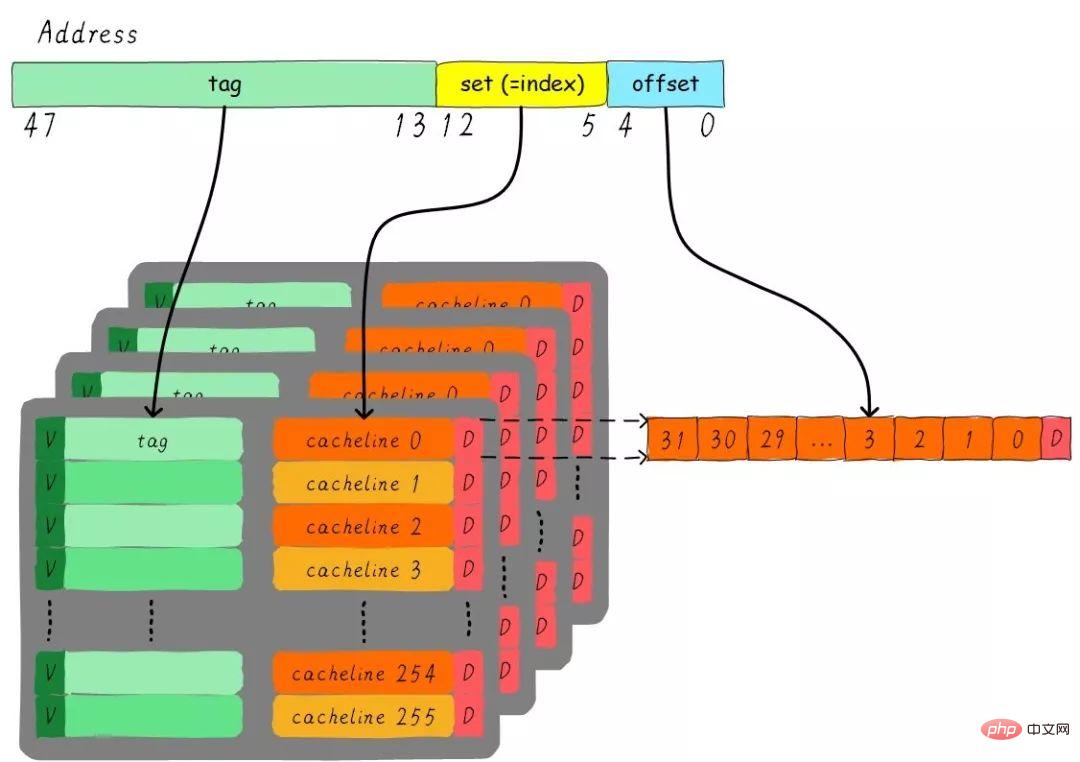
サイズ 32 KB の 4 ウェイ グループ接続キャッシュ、キャッシュ ライン サイズが 32 バイトのような問題を考えてみましょう。 。質問について考えてください:
1). グループはいくつありますか? 2). アドレス幅が 48 ビットであると仮定すると、インデックス、オフセット、タグはそれぞれ何ビットを占めるでしょうか?
合計 4 チャネルがあるため、各チャネルのサイズは 8 KB です。キャッシュ ライン サイズは 32 バイトなので、合計 256 グループ (8 KB / 32 バイト) があります。キャッシュ ライン サイズは 32 バイトであるため、オフセットには 5 ビットが必要です。グループは合計 256 個あるため、インデックスには 8 ビットが必要で、残りはタグ部分で 35 ビットが必要です。このキャッシュは次の図で表すことができます。
キャッシュ割り当てポリシーは、データ ラインにキャッシュを割り当てる必要がある状況を指します。キャッシュ割り当て戦略は、読み取りと書き込みの 2 つの状況に分けられます。
リード割り当て:
CPU がデータを読み出す際にキャッシュミスが発生した場合、メインメモリからの読み出しにキャッシュラインキャッシュが割り当てられます。データ。デフォルトでは、キャッシュは読み取り割り当てをサポートします。
書き込み割り当て:
CPU がデータを書き込み、キャッシュが見つからない場合、書き込み割り当て戦略が考慮されます。書き込み割り当てをサポートしていない場合、書き込み命令はメイン メモリ データを更新するだけで終了します。書き込み割り当てがサポートされている場合、まずメイン メモリからキャッシュ ラインにデータをロードし (最初に読み取り割り当てを実行するのと同じ)、次にキャッシュ ライン内のデータを更新します。
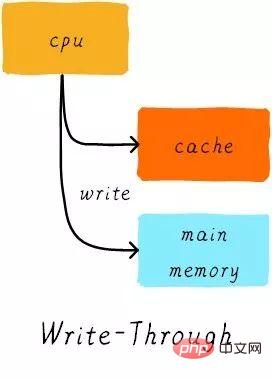
キャッシュ更新ポリシーは、キャッシュ ヒットが発生したときに書き込み操作でデータを更新する方法を指します。キャッシュ更新戦略は、ライトスルーとライトバックの 2 つのタイプに分類されます。
ライトスルー (ライトスルー):
CPU がストア命令を実行し、キャッシュがヒットすると、キャッシュ内のデータを更新し、キャッシュ内のデータを更新します。メインメモリ。キャッシュとメインメモリ内のデータは常に一貫しています。
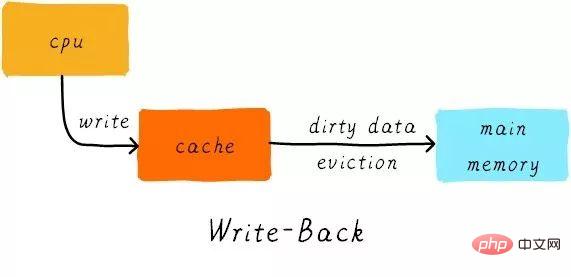
ライトバック:
CPU がストア命令を実行し、キャッシュがヒットすると、キャッシュ データのみが更新されます。また、各キャッシュ ラインには、ダーティ ビットと呼ばれる、データが変更されたかどうかを記録するビットがあります (前の図を見てください。キャッシュ ラインの隣に D があります。これがダーティ ビットです)。ダーティビットを設定します。メイン メモリ内のデータは、キャッシュ ラインが置き換えられるかクリーン操作が実行される場合にのみ更新されます。したがって、メイン メモリ内のデータは未変更のデータである可能性がありますが、変更されたデータはキャッシュ ラインに存在します。
同時に、なぜキャッシュ ライン サイズがキャッシュ コントローラーとメイン メモリ間のデータ転送の最小単位なのでしょうか?これは、各キャッシュ ラインにダーティ ビットが 1 つしかないためでもあります。このダーティ ビットは、キャッシュ ライン全体の変更されたステータスを表します。
サイズが 64 バイトのダイレクト マップ キャッシュがあると仮定します。書き込み割り当てを使用すると、キャッシュ ライン サイズは 8 バイトになります。ライトバックメカニズム。 CPU がアドレス 0x2a からバイトを読み取ると、キャッシュ内のデータはどのように変化しますか?現在のキャッシュの状態が下図のとおりであるとします。
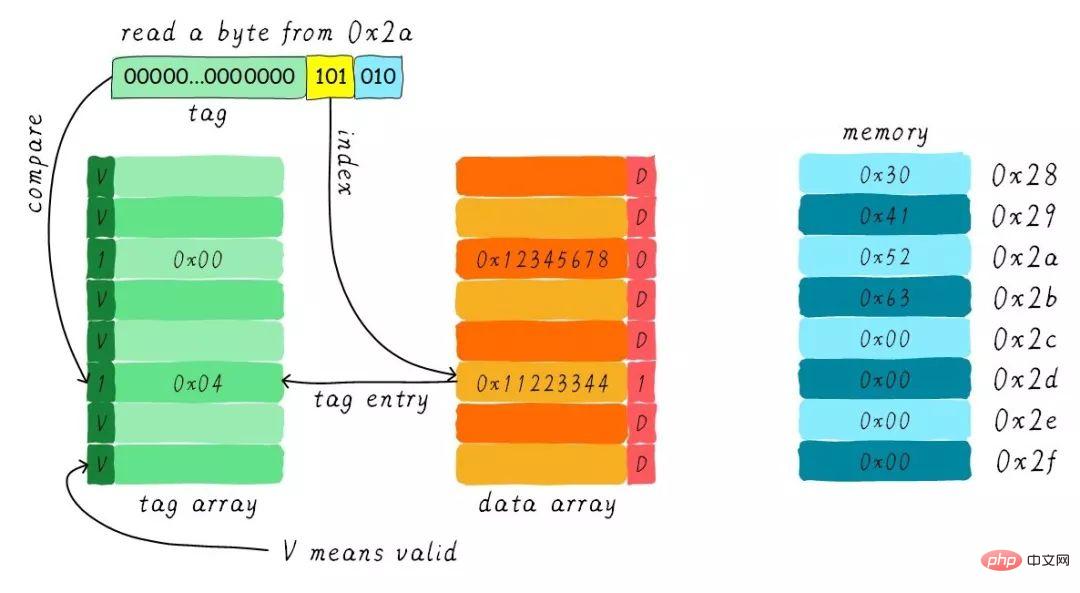
インデックスに従って、対応するキャッシュ ラインを検索します。対応するタグ部分の有効ビットは正当ですが、タグの値が等しくないため、削除が発生します。 。この時点で、アドレス 0x28 からキャッシュ ラインに 8 バイトのデータをロードする必要があります。ただし、現在のキャッシュ ラインのダーティ ビットが設定されていることがわかりました。したがって、キャッシュ ライン内のデータを単純に破棄することはできず、ライトバック メカニズムにより、キャッシュ内のデータ 0x11223344 をアドレス 0x0128 に書き込む必要があります (このアドレスは、タグとキャッシュの値に基づいて計算されます)。それが配置されている行) )。このプロセスを次の図に示します。
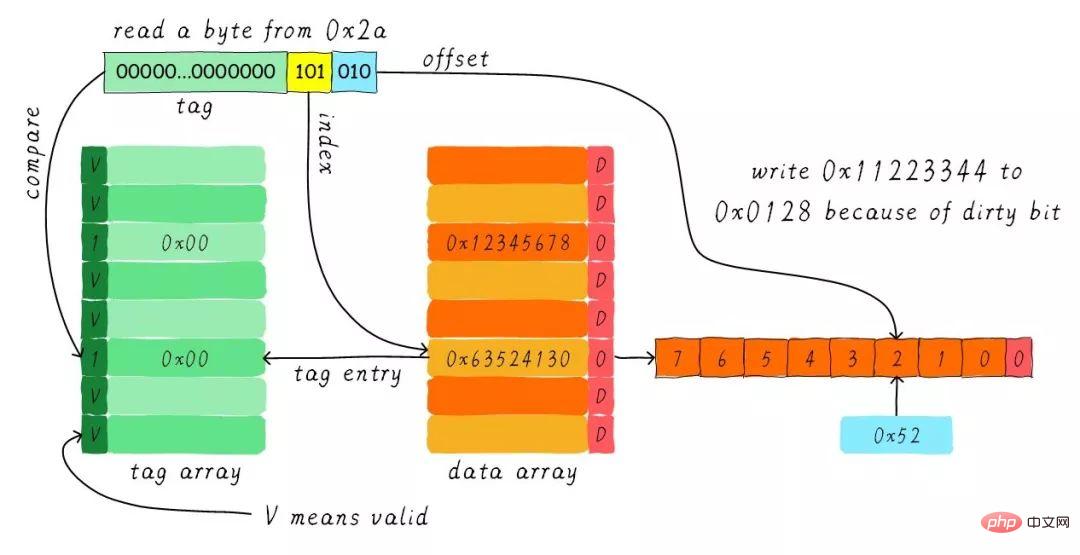
ライトバック操作が完了すると、メイン メモリのアドレス 0x28 から始まる 8 バイトがキャッシュ ラインにロードされ、ダーティ ビットがクリアされます。次に、オフセットに従って 0x52 を見つけて CPU に返します。
辛抱強く読んでいただきありがとうございます。お役に立てれば幸いです。
この記事は Wowotech からの転載です: http://www.wowotech.net/memory_management/458.html
推奨チュートリアル: 「Linux の運用とメンテナンス 」
以上がLinuxのキャッシュメモリについて(詳細画像と文章説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



