

Python コード例を使用して kNN アルゴリズムの実際の応用を実証する_基礎知識

近隣アルゴリズム、または K 最近傍 (kNN、k-NearestNeighbor) 分類アルゴリズムは、データ マイニング分類テクノロジの最も単純な方法の 1 つです。いわゆる K 最近傍とは、k 個の最近傍を意味します。これは、各サンプルがその k 個の最近傍によって表現できることを意味します。
kNN アルゴリズムの中心的な考え方は、特徴空間内のサンプルの k 個の最近接サンプルのほとんどが特定のカテゴリに属している場合、サンプルもこのカテゴリに属し、このカテゴリ内のサンプルの特性を持つということです。この方法では、分類の決定を行う際に、最も近い 1 つまたは複数のサンプルのカテゴリに基づいて、分類されるサンプルのカテゴリのみが決定されます。 kNN 法は、カテゴリの決定を行う際に、非常に少数の隣接するサンプルにのみ関連します。 kNN 法は、クラス領域を識別してカテゴリを決定する方法ではなく、主に限られた周囲のサンプルに依存するため、サンプルセットが多数の交差または重複で分割される場合、他の方法よりも効率的です。フィットのクラスドメイン。
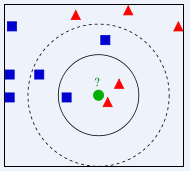
上の図で、緑の丸はどのクラスに割り当てられるべきですか? 赤い三角形ですか?それとも青い四角ですか? K=3 の場合、赤い三角形の割合は 2/3 であるため、緑の円には赤い三角形のクラスが割り当てられます。 K=5 の場合、青い正方形の割合は 3/5 であるため、緑の円が割り当てられます。青い正方形タイプのクラスが割り当てられます。
K 最近傍 (KNN) 分類アルゴリズムは理論的に成熟した手法であり、最も単純な機械学習アルゴリズムの 1 つです。この方法の考え方は、サンプルが特徴空間内の k 個の最も類似した (つまり、特徴空間内で最も近い) サンプルの中の特定のカテゴリに属する場合、サンプルもこのカテゴリに属するということです。 KNN アルゴリズムでは、選択された近傍オブジェクトはすべて正しく分類されたオブジェクトです。この方法は、分類の意思決定において、最も近い 1 つまたは複数のサンプルのカテゴリに基づいて、分類されるサンプルのカテゴリを決定するだけです。 KNN 法も原理的には極限定理に依存しますが、カテゴリーの決定を行う際に関係するのは、非常に少数の隣接するサンプルのみです。 KNN 法は、クラス領域を識別してカテゴリを決定する方法ではなく、主に周囲の限られたサンプルに依存するため、多数の交差または重複でサンプルセットを分割する場合、KNN 方法は他の方法よりも効率的です。フィットのクラスドメイン。
KNN アルゴリズムは分類だけでなく回帰にも使用できます。サンプルの k 個の最近傍を見つけて、これらの近傍の属性の平均をサンプルに割り当てることによって、サンプルの属性を取得できます。より有用な方法は、サンプル上の異なる距離にある近隣の影響に異なる重みを与えることです。たとえば、重みは距離に反比例します。
kNN アルゴリズムを使用して Douban 映画ユーザーの性別を予測します
概要
この記事では、性別が異なれば好む映画の種類も異なると考え、この実験を実施しました。 274 人のアクティブな Douban ユーザーが最近視聴した 100 本の映画を使用して、そのタイプに関する統計を作成しました。得られた 37 種類の映画を属性特徴として使用し、ユーザーの性別をサンプル セットを構築するためのラベルとして使用しました。 kNN アルゴリズムを使用して、サンプルの 90% をトレーニング サンプルとして、10% をテスト サンプルとして使用して Douban ムービー ユーザーの性別分類器を構築すると、精度は 81.48% に達します。
実験データ
この実験で使用されたデータは、Douban ユーザーがマークした映画であり、274 人の Douban ユーザーが最近視聴した 100 本の映画が選択されました。ユーザーごとの映画タイプの統計。今回の実験で使用したデータには映画の種類が合計 37 種類あるので、この 37 種類をユーザーの属性特徴量とし、各特徴量の値がユーザーの映画 100 本のうちその種類の映画の数となります。ユーザーは性別によってラベル付けされます。Douban にはユーザーの性別情報がないため、すべて手動でラベル付けされます。
データ形式は次のとおりです:
X1,1,X1,2,X1,3,X1,4……X1,36,X1,37,Y1 X2,1,X2,2,X2,3,X2,4……X2,36,X2,37,Y2 ………… X274,1,X274,2,X274,3,X274,4……X274,36,X274,37,Y274
例:
0,0,0,3,1,34,5,0,0,0,11,31,0,0,38,40,0,0,15,8,3,9,14,2,3,0,4,1,1,15,0,0,1,13,0,0,1,1 0,1,0,2,2,24,8,0,0,0,10,37,0,0,44,34,0,0,3,0,4,10,15,5,3,0,0,7,2,13,0,0,2,12,0,0,0,0
像这样的数据一共有274行,表示274个样本。每一个的前37个数据是该样本的37个特征值,最后一个数据为标签,即性别:0表示男性,1表示女性。
在此次试验中取样本的前10%作为测试样本,其余作为训练样本。
首先对所有数据归一化。对矩阵中的每一列求取最大值(max_j)、最小值(min_j),对矩阵中的数据X_j,
X_j=(X_j-min_j)/(max_j-min_j) 。
然后对于每一条测试样本,计算其与所有训练样本的欧氏距离。测试样本i与训练样本j之间的距离为:
distance_i_j=sqrt((Xi,1-Xj,1)^2+(Xi,2-Xj,2)^2+……+(Xi,37-Xj,37)^2) ,
对样本i的所有距离从小到大排序,在前k个中选择出现次数最多的标签,即为样本i的预测值。
实验结果
首先选择一个合适的k值。 对于k=1,3,5,7,均使用同一个测试样本和训练样本,测试其正确率,结果如下表所示。
选取不同k值的正确率表
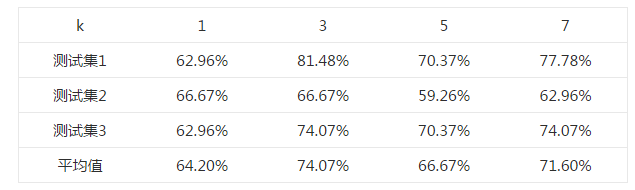
由上述结果可知,在k=3时,测试的平均正确率最高,为74.07%,最高可以达到81.48%。
上述不同的测试集均来自同一样本集中,为随机选取所得。
Python代码
这段代码并非原创,来自《机器学习实战》(Peter Harrington,2013),并有所改动。
#coding:utf-8
from numpy import *
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,37)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
returnMat[index,:] = listFromLine[0:37]
classLabelVector.append(int(listFromLine[-1]))
index += 1
fr.close()
return returnMat,classLabelVector
def genderClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('doubanMovieDataSet.txt') #load data setfrom file
normMat,ranges,minVals=autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
testMat=normMat[0:numTestVecs,:]
trainMat=normMat[numTestVecs:m,:]
trainLabels=datingLabels[numTestVecs:m]
k=3
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(testMat[i,:],trainMat,trainLabels,k)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "Total errors:%d" %errorCount
print "The total accuracy rate is %f" %(1.0-errorCount/float(numTestVecs))

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7636
7636
 15
1391
52
90
11
32
150
15
1391
52
90
11
32
150

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。
 VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSコード拡張機能は、悪意のあるコードの隠れ、脆弱性の活用、合法的な拡張機能としての自慰行為など、悪意のあるリスクを引き起こします。悪意のある拡張機能を識別する方法には、パブリッシャーのチェック、コメントの読み取り、コードのチェック、およびインストールに注意してください。セキュリティ対策には、セキュリティ認識、良好な習慣、定期的な更新、ウイルス対策ソフトウェアも含まれます。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
VSコードでは、次の手順を通じて端末でプログラムを実行できます。コードを準備し、統合端子を開き、コードディレクトリが端末作業ディレクトリと一致していることを確認します。プログラミング言語(pythonのpython your_file_name.pyなど)に従って実行コマンドを選択して、それが正常に実行されるかどうかを確認し、エラーを解決します。デバッガーを使用して、デバッグ効率を向上させます。
 vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
vscodeはMacに使用できますか
Apr 15, 2025 pm 07:36 PM
VSコードはMacで利用できます。強力な拡張機能、GIT統合、ターミナル、デバッガーがあり、豊富なセットアップオプションも提供しています。ただし、特に大規模なプロジェクトまたは非常に専門的な開発の場合、コードと機能的な制限がある場合があります。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
