


EXPLAIN キーワードを使用すると、オプティマイザによる SQL クエリ ステートメントの実行をシミュレートし、MySQL が SQL ステートメントをどのように処理するかを知ることができます。クエリ ステートメントまたはテーブル構造のパフォーマンスのボトルネックを分析します。
➤ EXPLAIN により、次の結果を分析できます:
➤ 次のように使用されます:
EXPLAIN SQL ステートメント
#EXPLAIN SELECT * FROM t1
実行計画に含まれる情報
select 句の順序を示す、一連の数字を含む選択クエリのシーケンス番号。またはクエリ内で操作テーブルが実行される
id の結果は 3 つのケースがあります
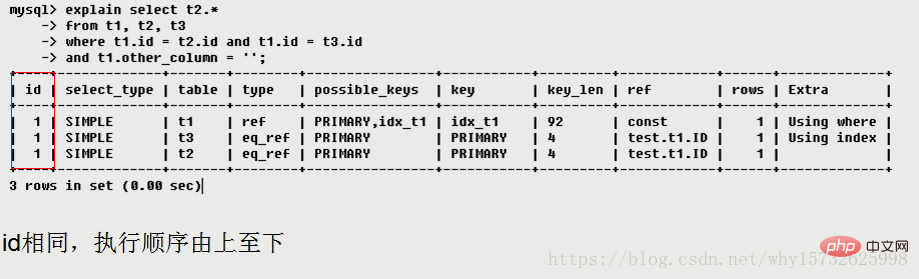
[概要] テーブルをロードする順序は、上のテーブル列に示されているとおりです: t1 t3 t2

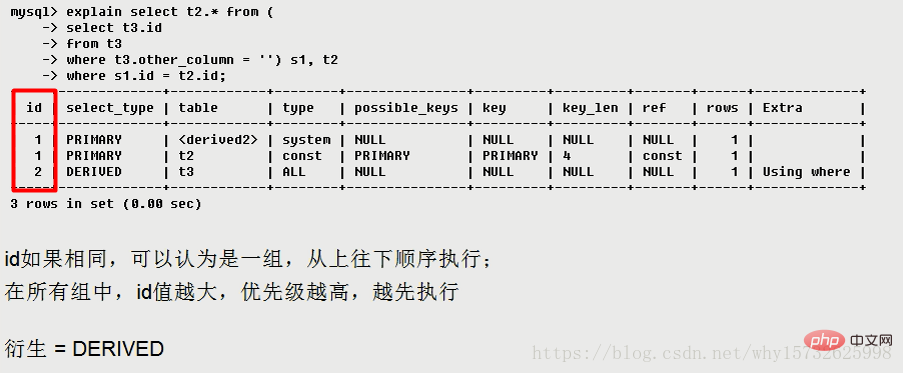
図に示すように、ID が 1 の場合、テーブルには < が表示されます。 ;derived2>、ID 2 のテーブル、つまり t3 テーブルの派生テーブルを参照します。
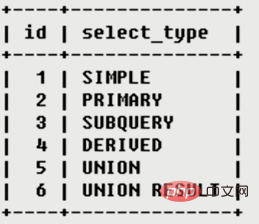
一般的で一般的に使用される値は次のとおりです。 は、主にクエリの種類を区別するために使用されます。通常のクエリ、ユニオンクエリ、サブクエリなどの複雑なクエリ。
SIMPLE 単純な選択クエリ、クエリ
PRIMARY クエリの には、複雑な サブパートが含まれます。
(派生) としてマークされ、MySQL はそれを再帰的に実行します。これらのサブクエリは # を置きます## 結果は一時テーブルになります
UNION 2 番目の SELECT が UNION の後に出現する場合、UNION としてマークされます。 FROM 句のサブクエリに UNION が含まれている場合、外側の SELECT は次のようにマークされます: DERIVED
UNION RESULT SELECT
### これは UNION テーブル 2.3 table#### から結果を取得します。 ## は、現在実行されているテーブルを参照します。######2.4 type######type は、クエリで使用される型を示します。type に含まれる型には、次の図に示すようなものが含まれます。いくつかの型: ### ######最良のものから最悪のものまで: ###system > const > eq_ref > ref > range > index > all
system テーブルにはレコードが 1 行だけあります (システム テーブルと同じ)。これは const 型の特別な列です。通常は表示されないため、無視できます。 const は、インデックスを通じて 1 回見つかることを意味し、const は主キーまたは一意のインデックスを比較するために使用されます。 1 行のデータのみが照合されるため、非常に高速です。主キーを where リストに配置すると、MySQL はクエリを定数に変換できます。 
eq_ref 一意のインデックス スキャン。インデックス キーごとに、テーブル内の 1 つのレコードのみがそれに一致します。主キーまたは一意のインデックス スキャンで一般的に見られますref 非一意のインデックス スキャンは、単一の値に一致するすべての行を返します。これは本質的にインデックス アクセスです。ただし、単一値の行の場合は、一致する行が複数見つかる可能性があるため、検索とスキャンを組み合わせて行う必要があります。 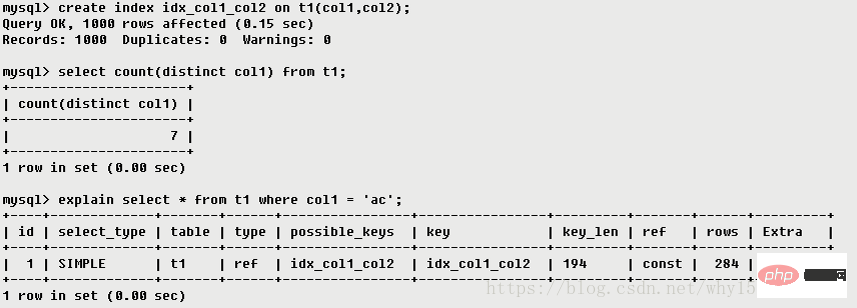
range 指定された範囲内の行のみを取得し、インデックスを使用して行を選択します。キー列は、通常は where ステートメントで使用されるインデックスを示します。 between、、in など、この範囲スキャン インデックスはテーブル全体をスキャンする必要がなく、インデックス内の特定のポイントで開始し、別のポイントで終了するだけでよいため、フル テーブル スキャンよりも優れています。索引。 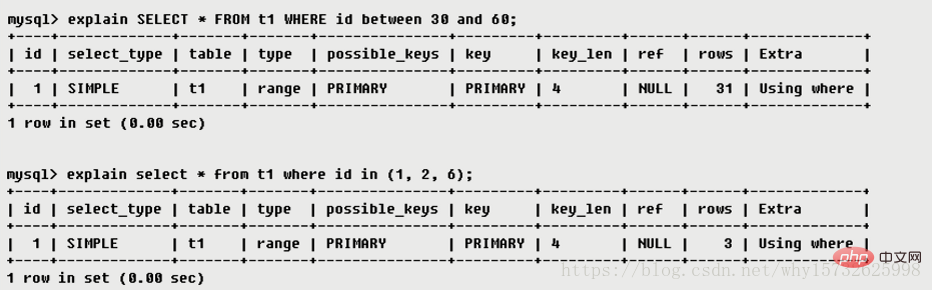
index フル インデックス スキャン。インデックスとすべての違いは、インデックス タイプがインデックス ツリーのみをスキャンすることです。通常、インデックス ファイルはデータ ファイルよりも小さいため、これは通常 ALL よりも高速です。 (つまり、all と Index は両方ともテーブル全体を読み取りますが、index はインデックスから読み取り、all はハードディスクから読み取ります) 
all フル テーブル スキャンはテーブル全体を走査して、一致する行を見つけます
possible_keys このテーブルに適用できる 1 つ以上のインデックスを表示します。クエリに関係するフィールドにインデックスが存在する場合、そのインデックスはリストに表示されますが、 ですが、実際にはクエリ で使用されない可能性があります。
key

カバー インデックスがクエリで使用されている場合 (選択後にクエリされるフィールドがまったく同じです)作成されたインデックス フィールドと同様))、インデックスはキー リストにのみ表示されます。

は、キー リストの数を表します。インデックスで使用されるバイト数。この列は、クエリで使用されるインデックスの長さを計算するために使用できます。長さが短いほど、精度を損なうことなく良好な になります。 key_len によって表示される値は、実際に使用される長さではなく、インデックス フィールドの可能な最大長です。つまり、key_len はテーブルから取得されるのではなく、テーブル定義に基づいて計算されます。 
インデックスを示す列が使用されます。できれば定数が望ましいです。インデックス列の値を検索するために使用される列または定数。 
テーブルの統計とインデックスの選択に従って、必要なレコードを見つけるために読み取る必要がある行数を大まかに見積もります。つまり、次のようになります。少ないほど良いです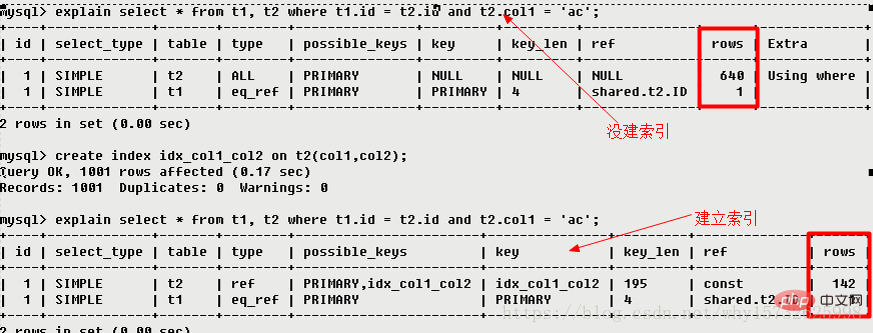
他の列での明示的な使用には適していない重要な追加情報が含まれています
mysql がテーブル内のインデックス順にデータを読み取るのではなく、外部インデックスを使用してデータを並べ替えることを示します。 MySQL のインデックスを使用して完了できないソート操作は、「ファイル ソート」と呼ばれます。 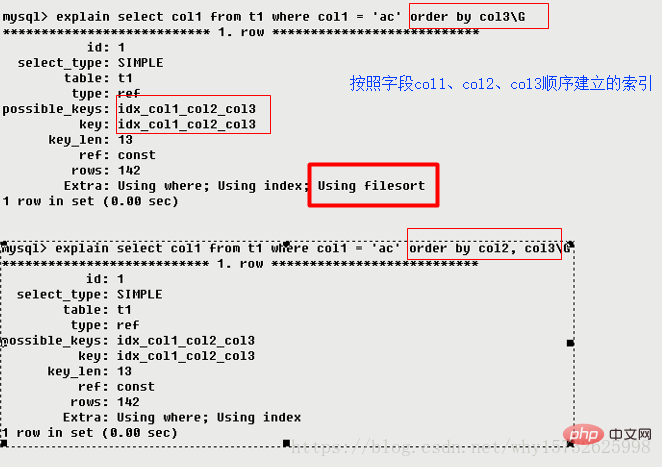
使用了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by。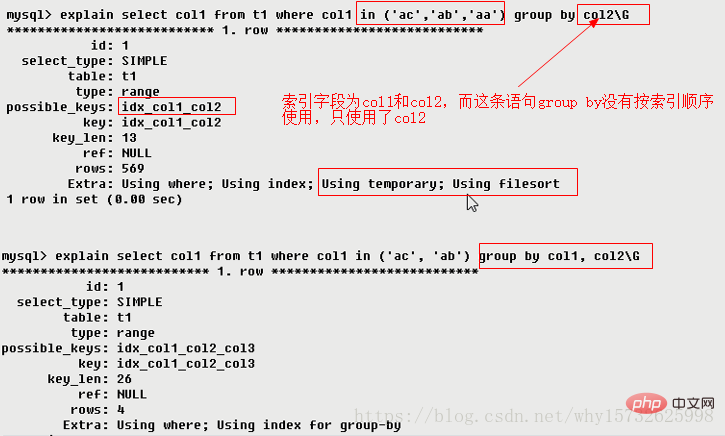
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错。如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。

表明使用了where过滤
表明使用了连接缓存,比如说在查询的时候,多表join的次数非常多,那么将配置文件中的缓冲区的join buffer调大一些。
where子句的值总是false,不能用来获取任何元组
SELECT * FROM t_user WHERE id = '1' and id = '2'
在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
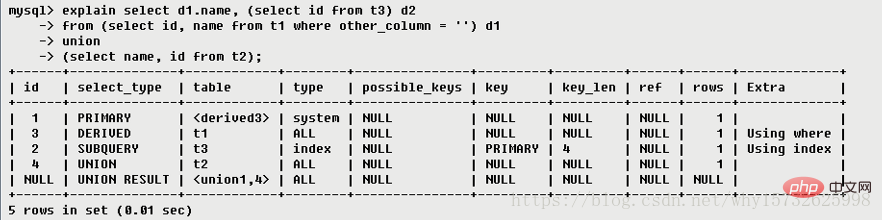
<derived3></derived3>,表示查询结果来自一个衍生表,其中derived3中的3代表该查询衍生自第三个select查询,即id为3的select。【select d1.name …】执行顺序5:代表从UNION的临时表中读取行的阶段,table列的表示用第一个和第四个select的结果进行UNION操作。【两个结果union操作】
推荐学习:mysql教程
以上がMySQLの使い方と結果解析を解説(詳細解説)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



