

同じPHP文字列でも長さが異なる問題を解決する

PHP 文字列の長さの不一致を解決する方法: 最初に「mb_detect_encoding()」関数を使用して 2 つの文字列のエンコード方法を確認し、次に特定の文字長を確認し、最後に中国語以外の文字を削除します。

質問:
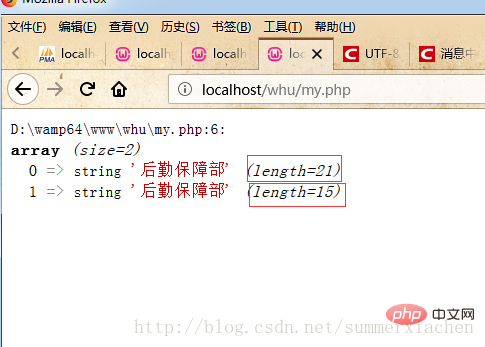
写真に示すように、2 つあります。一見すると同じ中国語の文字列「物流支援部」ですが、一方の長さは 21 で、もう一方は長さ 15 です。
まず、エンコード方法の違いが原因であると直感的に思われるかもしれません。mb_detect_encoding() 関数を使用して、2 つの文字列のエンコード方法を確認してください。は次のとおりです
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));echo "str1='".$str1."'"." 编码:".$encode1."</br>";echo "str2='".$str2."'"." 编码:".$encode2."</br>";?>しかし、出力結果はすべて UTF-8
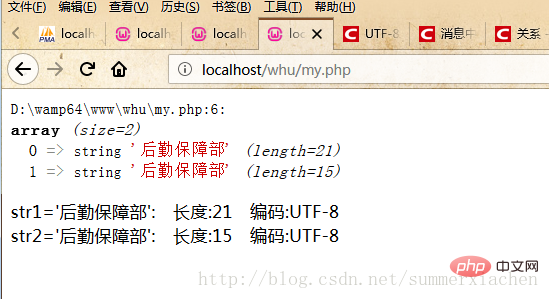
それでは、何が原因でしょうか?出力内の特定の文字長を確認してみましょう
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";?>出力結果は次のとおりです。
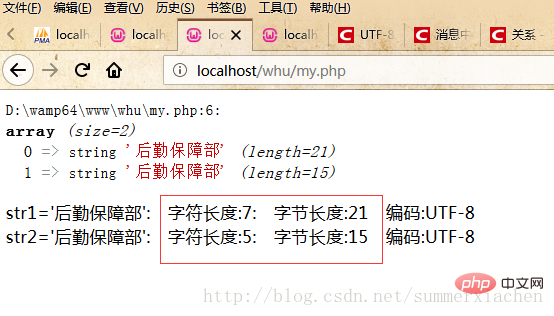
文字列 str1 には 7 つの漢字が含まれていますが、実際に表示されるのは 5 文字だけであることがわかりました。 「兵站支援部」
str1 の最後の 2 文字をインターセプトすることにより、文字ビュー
//截取str1后面两个未显示字符$res=mb_substr($str1, 5,2);echo "最后两字符:".$res."</br>";echo mb_strlen($res);
はエコー表示できませんが、2 文字を占有します
見た目は同じでも、実際には等しい必要があるため、中国語以外の文字を削除する処理が必要です:
//剔除str1字串中未显示的字符(非中文字符)preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);最終的なコードは次のとおりです
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";//截取str1后面两个未显示字符echo "</br>------------------截取str1后面两个未显示字符---------------------</br>";$res=mb_substr($str1, 5,2);echo "str1最后两字符: ".$res."</br>";echo "str1长度: ".mb_strlen($res)."</br>";//比较echo "</br>--------------------------相等比较----------------------------------</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";echo "str2 与 str2比较: ";echo strcomp($str2,$str2)."</br>";//剔除str1字串中非中文preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);echo "</br>---------------------剔除str1字串中非中文后----------------------</br>";echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";function strcomp($str1,$str2){
if($str1 == $str2){
return "相等";
}else{
return "不等";
}
}
?>実行結果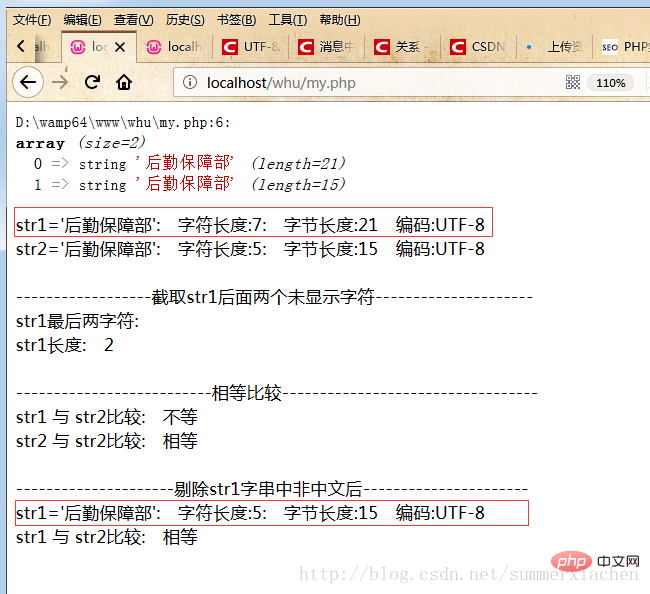
注:
21 バイトの str1 を phpmyadmin の SQL 入力ボックスにコピーすると、次のように表示されます
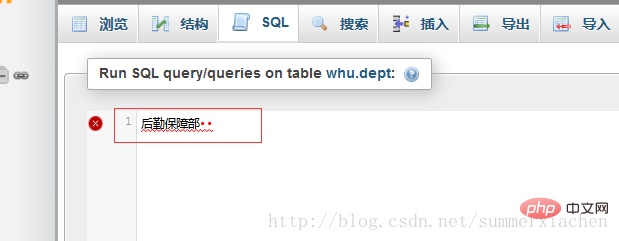
まあ、これは 2 つの余分な文字です
さらに関連する知識については、 PHP 中国語 Web サイト をご覧ください。
以上が同じPHP文字列でも長さが異なる問題を解決するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 Ubuntu および Debian 用の PHP 8.4 インストールおよびアップグレード ガイド
Dec 24, 2024 pm 04:42 PM
Ubuntu および Debian 用の PHP 8.4 インストールおよびアップグレード ガイド
Dec 24, 2024 pm 04:42 PM
PHP 8.4 では、いくつかの新機能、セキュリティの改善、パフォーマンスの改善が行われ、かなりの量の機能の非推奨と削除が行われています。 このガイドでは、Ubuntu、Debian、またはその派生版に PHP 8.4 をインストールする方法、または PHP 8.4 にアップグレードする方法について説明します。

 CakePHP ファイルのアップロード
Sep 10, 2024 pm 05:27 PM
CakePHP ファイルのアップロード
Sep 10, 2024 pm 05:27 PM
ファイルのアップロードを行うには、フォーム ヘルパーを使用します。ここではファイルアップロードの例を示します。
 CakePHP について話し合う
Sep 10, 2024 pm 05:28 PM
CakePHP について話し合う
Sep 10, 2024 pm 05:28 PM
CakePHP は、PHP 用のオープンソース フレームワークです。これは、アプリケーションの開発、展開、保守をより簡単にすることを目的としています。 CakePHP は、強力かつ理解しやすい MVC のようなアーキテクチャに基づいています。モデル、ビュー、コントローラー

 CakePHP のロギング
Sep 10, 2024 pm 05:26 PM
CakePHP のロギング
Sep 10, 2024 pm 05:26 PM
CakePHP へのログインは非常に簡単な作業です。使用する関数は 1 つだけです。 cronjob などのバックグラウンド プロセスのエラー、例外、ユーザー アクティビティ、ユーザーが実行したアクションをログに記録できます。 CakePHP でのデータのログ記録は簡単です。 log()関数が提供されています
 PHP 開発用に Visual Studio Code (VS Code) をセットアップする方法
Dec 20, 2024 am 11:31 AM
PHP 開発用に Visual Studio Code (VS Code) をセットアップする方法
Dec 20, 2024 am 11:31 AM
Visual Studio Code (VS Code とも呼ばれる) は、すべての主要なオペレーティング システムで利用できる無料のソース コード エディター (統合開発環境 (IDE)) です。 多くのプログラミング言語の拡張機能の大規模なコレクションを備えた VS Code は、
 CakePHP クイックガイド
Sep 10, 2024 pm 05:27 PM
CakePHP クイックガイド
Sep 10, 2024 pm 05:27 PM
CakePHP はオープンソースの MVC フレームワークです。これにより、アプリケーションの開発、展開、保守がはるかに簡単になります。 CakePHP には、最も一般的なタスクの過負荷を軽減するためのライブラリが多数あります。
