

SQL Server での Partition By 関数と row_number 関数の使用方法の詳細な説明


partition by キーワードは分析関数の一部です。集計関数とは異なり、グループ内の複数のレコードを返すことができますが、集計関数には通常 1 つのレコードしかありません統計を反映します。値のレコード、パーティションによる結果セットのグループ化に使用されます。指定しない場合、結果セット全体がグループとして扱われます。
今日グループで質問を見たので、ここで要約します: さまざまなカテゴリの最新レコードをクエリする。一見するととてもシンプルですね? 分類したい場合は Group By を使用し、最新のレコードが必要な場合は Order By を使用します。次に、それを独自のテーブルに作成してみます:
関連する学習の推奨事項: mysql ビデオ チュートリアル
まず、データを次のように入力します。表は送信時刻の逆順にリストされています。
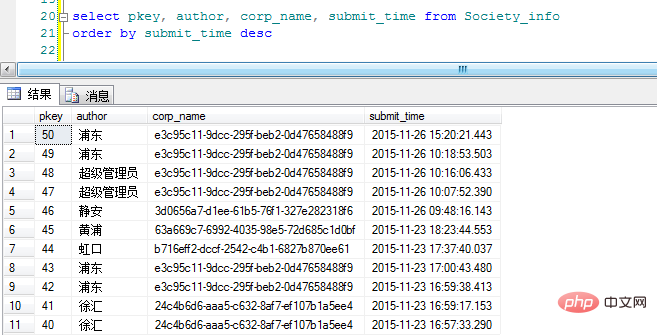
"corp_name" はカテゴリの GUID です (私の命名が恣意的であることをご容赦ください)。 OK、ここで元のアイデアに従って Group By を追加して、表示効果を確認します。
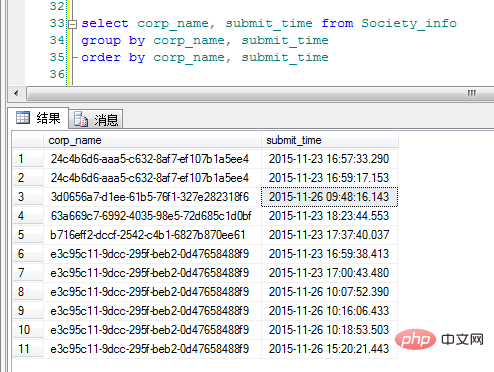
ええと、ええと。この結果は私が想像していたものとは異なります。コードを書くときは、やはり問題を合理的に分析する必要があるようです。結果は頭ではコントロールできません。
要件が異なるカテゴリのデータであるため、Group By を使用する以外に使用できる機能はありますか?調べてみると、確かにover(partition by)関数があることが分かりましたが、普段よく使うGroup Byとは何が違うのでしょうか? Group Byは単純に結果をグループ化するだけでなく、集計関数と併用するのが一般的で、Partition Byもグループ化機能を備えたOracleの分析機能ですが、ここでは詳しく説明しません。
コードを見てください:
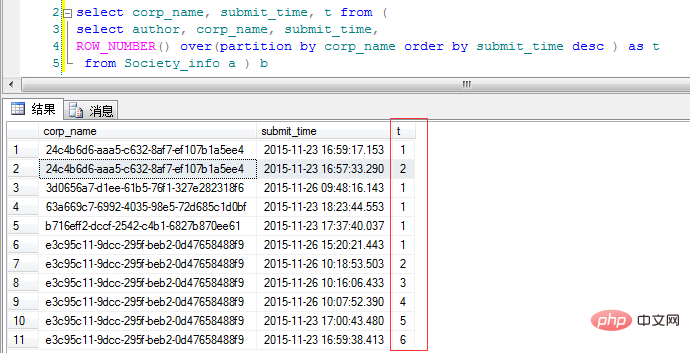
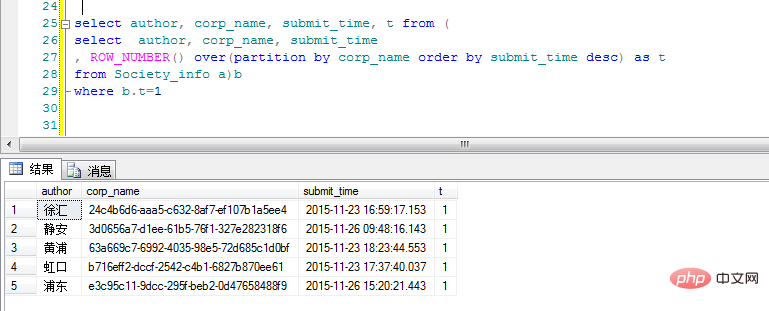
ps: SQL Server データベース パーティションによるおよび ROW_NUMBER() 関数の使用に関する詳細な説明
フィールドによる SQL パーティションの使用体験最初にお読みください 例:if object_id('TESTDB') is not null drop table TESTDB create table TESTDB(A varchar(8), B varchar(8)) insert into TESTDB select 'A1', 'B1' union all select 'A1', 'B2' union all select 'A1', 'B3' union all select 'A2', 'B4' union all select 'A2', 'B5' union all select 'A2', 'B6' union all select 'A3', 'B7' union all select 'A3', 'B3' union all select 'A3', 'B4'
SELECT * FROM TESTDB A B ------- A1 B1 A1 B2 A1 B3 A2 B4 A2 B5 A2 B6 A3 B7 A3 B3 A3 B4
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB A B NUM ------------- A1 B1 1 A1 B2 2 A1 B3 3 A2 B4 1 A2 B5 2 A2 B6 3 A3 B7 1 A3 B3 2 A3 B4 3
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB A B NUM ------------------------ A3 B7 1 A3 B3 2 A3 B4 3 A2 B4 4 A2 B5 5 A2 B6 6 A1 B1 7 A1 B2 8 A1 B3 9
SELECT A = CASE WHEN NUM = 1 THEN A ELSE '' END,B FROM (SELECT A,NUM = ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) FROM TESTDB) T A B --------- A1 B1 B2 B3 A2 B4 B5 B6 A3 B7 B3 B4
次に、いくつかの例を通して ROW_NUMBER() 関数の使用法を 1 つずつ紹介します。
例は次のとおりです:1.
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
2. 注文を価格の昇順に並べ替え、次のコードを使用して各レコードを並べ替えます:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3. 各レコードをカウントします。各世帯は各顧客の注文金額の昇順に並べ替えられ、各顧客の注文には番号が付けられます。このようにして、各顧客がどれだけの注文をしたかを知ることができます。 図に示すように:
 コードは次のとおりです:
コードは次のとおりです:
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4. 各顧客の最近の回数を数えます。注文しました。注文しました。
 コードは次のとおりです:
コードは次のとおりです:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
如图: 上图:rows表示客户是第几次购买。 思路:利用临时表来执行这一操作。 1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。 2.然后利用子查询查找出每一个客户购买时的最小价格。 3.根据查找出每一个客户的最小价格来查找相应的记录。 代码如下: 6.筛选出客户第一次下的订单。 思路。利用rows=1来查询客户第一次下的订单记录。 代码如下: 7.rows_number()可用于分页 思路:先把所有的产品筛选出来,然后对这些产品进行编号。然后在where子句中进行过滤。 8.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。 如下代码:
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)

with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>'2011-07-22'
以上代码是先执行where子句,执行完后,再给每一条记录进行编号。
以上がSQL Server での Partition By 関数と row_number 関数の使用方法の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 INNODBフルテキスト検索機能を説明します。
Apr 02, 2025 pm 06:09 PM
INNODBフルテキスト検索機能を説明します。
Apr 02, 2025 pm 06:09 PM
INNODBのフルテキスト検索機能は非常に強力であり、データベースクエリの効率と大量のテキストデータを処理する能力を大幅に改善できます。 1)INNODBは、倒立インデックスを介してフルテキスト検索を実装し、基本的および高度な検索クエリをサポートします。 2)一致を使用してキーワードを使用して、ブールモードとフレーズ検索を検索、サポートします。 3)最適化方法には、単語セグメンテーションテクノロジーの使用、インデックスの定期的な再構築、およびパフォーマンスと精度を改善するためのキャッシュサイズの調整が含まれます。
 Alter Tableステートメントを使用してMySQLのテーブルをどのように変更しますか?
Mar 19, 2025 pm 03:51 PM
Alter Tableステートメントを使用してMySQLのテーブルをどのように変更しますか?
Mar 19, 2025 pm 03:51 PM
この記事では、MySQLのAlter Tableステートメントを使用して、列の追加/ドロップ、テーブル/列の名前の変更、列データ型の変更など、テーブルを変更することについて説明します。
 MySQLでインデックスを使用するよりも、フルテーブルスキャンがいつ速くなるのでしょうか?
Apr 09, 2025 am 12:05 AM
MySQLでインデックスを使用するよりも、フルテーブルスキャンがいつ速くなるのでしょうか?
Apr 09, 2025 am 12:05 AM
完全なテーブルスキャンは、MySQLでインデックスを使用するよりも速い場合があります。特定のケースには以下が含まれます。1)データボリュームは小さい。 2)クエリが大量のデータを返すとき。 3)インデックス列が高度に選択的でない場合。 4)複雑なクエリの場合。クエリプランを分析し、インデックスを最適化し、オーバーインデックスを回避し、テーブルを定期的にメンテナンスすることにより、実際のアプリケーションで最良の選択をすることができます。
 Windows 7にMySQLをインストールできますか?
Apr 08, 2025 pm 03:21 PM
Windows 7にMySQLをインストールできますか?
Apr 08, 2025 pm 03:21 PM
はい、MySQLはWindows 7にインストールできます。MicrosoftはWindows 7のサポートを停止しましたが、MySQLは引き続き互換性があります。ただし、インストールプロセス中に次のポイントに注意する必要があります。WindowsのMySQLインストーラーをダウンロードしてください。 MySQL(コミュニティまたはエンタープライズ)の適切なバージョンを選択します。インストールプロセス中に適切なインストールディレクトリと文字セットを選択します。ルートユーザーパスワードを設定し、適切に保ちます。テストのためにデータベースに接続します。 Windows 7の互換性とセキュリティの問題に注意してください。サポートされているオペレーティングシステムにアップグレードすることをお勧めします。
 INNODBのクラスターインデックスと非クラスターインデックス(セカンダリインデックス)の違い。
Apr 02, 2025 pm 06:25 PM
INNODBのクラスターインデックスと非クラスターインデックス(セカンダリインデックス)の違い。
Apr 02, 2025 pm 06:25 PM
クラスター化されたインデックスと非クラスター化されたインデックスの違いは次のとおりです。1。クラスター化されたインデックスは、インデックス構造にデータを保存します。これは、プライマリキーと範囲でクエリするのに適しています。 2.非クラスター化されたインデックスストアは、インデックスキー値とデータの行へのポインターであり、非プリマリーキー列クエリに適しています。
 人気のあるMySQL GUIツール(MySQL Workbench、PhpMyAdminなど)は何ですか?
Mar 21, 2025 pm 06:28 PM
人気のあるMySQL GUIツール(MySQL Workbench、PhpMyAdminなど)は何ですか?
Mar 21, 2025 pm 06:28 PM
記事では、MySQLワークベンチやPHPMyAdminなどの人気のあるMySQL GUIツールについて説明し、初心者と上級ユーザーの機能と適合性を比較します。[159文字]
 MySQLの大きなデータセットをどのように処理しますか?
Mar 21, 2025 pm 12:15 PM
MySQLの大きなデータセットをどのように処理しますか?
Mar 21, 2025 pm 12:15 PM
記事では、MySQLで大規模なデータセットを処理するための戦略について説明します。これには、パーティション化、シャード、インデックス作成、クエリ最適化などがあります。
 ドロップテーブルステートメントを使用してMySQLにテーブルをドロップするにはどうすればよいですか?
Mar 19, 2025 pm 03:52 PM
ドロップテーブルステートメントを使用してMySQLにテーブルをドロップするにはどうすればよいですか?
Mar 19, 2025 pm 03:52 PM
この記事では、ドロップテーブルステートメントを使用してMySQLのドロップテーブルについて説明し、予防策とリスクを強調しています。これは、バックアップなしでアクションが不可逆的であることを強調し、回復方法と潜在的な生産環境の危険を詳述しています。
