

はじめに: Redis は、ANSI C 言語で書かれたオープンソースのログタイプの Key-Value データベースで、BSD プロトコルに準拠し、ネットワークをサポートしており、メモリまたは永続性を備え、複数言語の API を備えた非リレーショナル データベースを提供します。
特別な推奨事項: 2020 Redis 面接質問集 (最新)
従来のデータベースは ACID ルールに従います。 Nosql (Not Only SQL の略で、従来のリレーショナル データベースとは異なるデータベース管理システムの総称) は一般に配布されており、配布は一般に CAP 定理に従います。
Github ソース コード: https://github.com/antirez/redis
Redis 公式 Web サイト: https://redis.io/
推奨: "redis チュートリアル>>
#Redis はどのようなデータ型をサポートしていますか?
文字列:
形式: キー値を設定
文字列型はバイナリ セーフです。これは、redis 文字列には任意のデータを含めることができることを意味します。たとえば、jpg 画像やシリアル化されたオブジェクトなどです。
文字列型は Redis の最も基本的なデータ型であり、キーは最大 512MB まで保存できます。
Hash(Hash)
形式: hmset name key1 value1 key2 value2
Redis ハッシュは、キーと値 (key=>value) のペアのセットです。
Redis ハッシュは文字列型のフィールドと値のマッピング テーブルであり、オブジェクトの保存に特に適しています。
List (リスト)
Redis リストは、挿入順に並べ替えられた文字列の単純なリストです。リストの先頭 (左) または末尾 (右) に要素を追加できます。
形式: lpush name value
キーに対応するリストの先頭に文字列要素を追加します。
形式: rpush name value
キー対応リストの末尾に文字列要素を追加
形式: lrem nameindex
から count 項目を削除します。値要素と同じキーに対応するリスト
形式: llen name
リストに対応するキーの長さを返します
Set (set)
形式:sadd name value
Redis の Set は、文字列型の順序付けされていないコレクションです。
セットはハッシュ テーブルを通じて実装されるため、追加、削除、検索の複雑さは O(1) です。
zset(並べ替えられたセット:順序付けされたセット)
形式: zadd 名スコア値
Redis zset も、set と同様に文字列型要素のコレクションであり、重複は許可されていないメンバーです。
違いは、各要素が double 型のスコアに関連付けられていることです。 Redis はスコアを使用して、コレクションのメンバーを小さいものから大きいものまで並べ替えます。
zset のメンバーはユニークですが、スコアは繰り返すことができます。
Redis 永続性とは何ですか? Redis にはどのような永続化メソッドがありますか?長所と短所は何ですか?
永続化とは、サービスがダウンした場合にメモリ データが失われるのを防ぐために、メモリ データをディスクに書き込むことです。
Redis は、RDB (デフォルト) と AOF の 2 つの永続化メソッドを提供します。
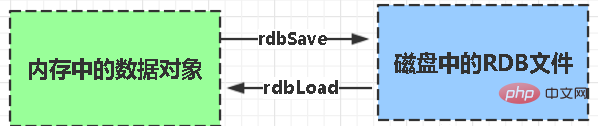
RDB:
rdb は、Redis DataBase の略語です
関数のコア関数 rdbSave (RDB ファイルの生成) と rdbLoad (ファイルからメモリをロード) の 2 つの関数
AOF:
Aof
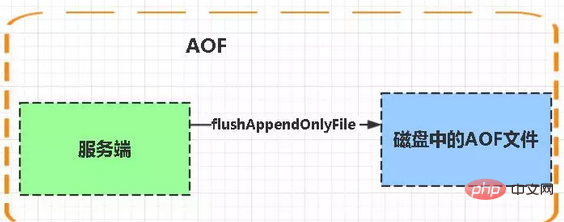
aof 書き込みと保存: WRITE: 条件に従って、aof_buf 内のキャッシュを AOF ファイルに書き込みます。 SAVE: 条件に従って、fsync または fdatasync 関数を呼び出して、 AOF ファイルをディスクに保存します。
ストレージ構造:
内容は、Redis Communication Protocol (RESP) 形式のコマンド テキストのストレージです。比較:
1. Aof ファイルは rdb よりも頻繁に更新されるため、最初に aof を使用してデータを復元します。 2. AOF は rdb より安全で容量が大きいです3. RDB のパフォーマンスは aof より優れています4. 両方が設定されている場合、AOF が最初にロードされます上で Redis 通信プロトコル (RESP) について言及しましたが、RESP とは何なのか説明してもらえますか?特徴は何ですか? (多くの面接は実際には質問の連続であることがわかります。面接官は実際にこの点に答えるのを待っています。質問に答えると、評価にさらに 1 点追加されます。)
RESP これは、Redis クライアントとサーバーによって以前に使用されていた通信プロトコルです。 RESP の特徴: シンプルな実装、高速な解析、優れた可読性単純な文字列の場合、応答の最初のバイトは次のとおりです。 " " Replyエラーの場合、応答の最初のバイトは「-」です。エラー整数の場合、応答の最初のバイトは「:」です。整数バルク文字列の場合応答の最初のバイトは "$" String配列の場合、応答の最初のバイトは "*" 配列Redis のアーキテクチャ パターンは何ですか?それぞれの特徴について話す
スタンドアロン バージョン
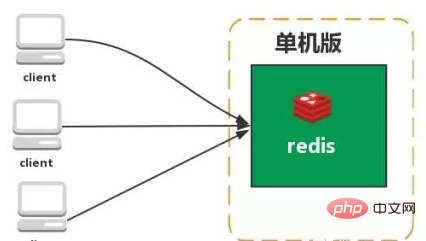
特徴: シンプル
問題点:
1. メモリ容量が限られている 2. 処理能力が限られている 3. 高可用性が得られない。
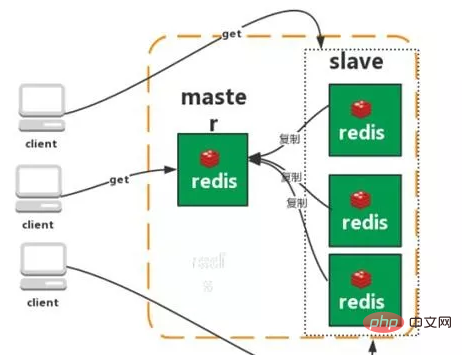
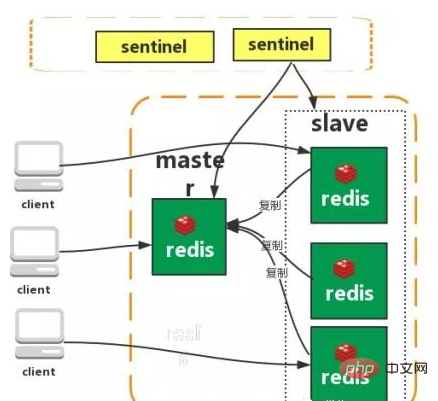
マスター/スレーブ レプリケーション
Sentinel
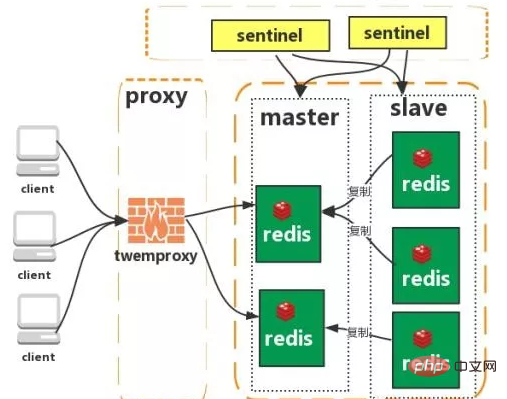
クラスター (プロキシ タイプ):
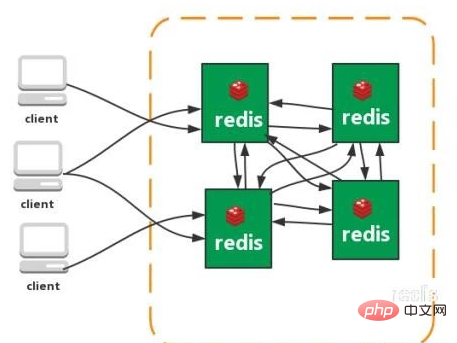
クラスター (直接接続タイプ):
一貫性のあるハッシュ アルゴリズムとは何ですか?ハッシュスロットとは何ですか?
Redis で一般的に使用されるコマンド?
キー パターン
* は、ビットで始まるすべての を割り当てることを意味しますExists キーが存在するかどうかを確認しますSet キーに対応する値を文字列型の値に設定します。 setnxキーに対応する値を文字列型の値に設定します。キーがすでに存在する場合は 0 を返します。nx は存在しないことを意味します。 キーを削除します#初回は 1 を返し、削除後の 2 回目は 0 を返します
Expire 有効期限を設定します (秒単位)
TTL ビュー 残り時間
負の数値が返された場合、キーは無効となり、キーは存在しません
Setex
に対応する値を設定しますキーを文字列型の値に変換し、このキーの有効期間の対応する値を指定します。
Mset
複数のキーの値を一度に設定します。成功した場合に ok が返されると、すべての値が設定されたことを意味し、失敗した場合に 0 が返された場合は、値が設定されていないことを意味します。
Getset
キーの値を設定し、キーの古い値を返します。
Mget
複数のキーの値を一度に取得します。対応するキーが存在しない場合は、それに応じて nil が返されます。
Incr
キーの値を追加し、新しい値を返します。 incr が int ではない値の場合はエラーが返されることに注意してください。incr が存在しないキーの場合は、キーを 1
incrby
に設定します。これは incr と同様です。 、指定した値を加算すると、キーが存在しない場合に設定され、元の値が0
Decr
キーの値が減算されます。 Decr キーが存在しません。キーを -1
Decrby
Decr と同じですが、指定された値を引いたものです。
Append
指定されたキーの文字列値に値を追加し、新しい文字列値の長さを返します。
Strlen
指定されたキーの値の長さを取得します。
persist xxx (有効期限をキャンセル)
データベースを選択 (0-15 データベース)
Select 0 //データベースを選択
move age 1//年齢を 1 つのライブラリに移動します
Randomkey はキーをランダムに返します
Rename rename
Type はデータ型を返します
08
Redis 分散ロックを使用したことがありますか?それはどのように実装されていますか?
最初に setnx を使用してロックを取得し、取得後、expired を使用してロックの解放忘れを防ぐために有効期限をロックに追加します。
setnx 後に期限切れが実行される前にプロセスが予期せずクラッシュした場合、またはメンテナンスのために再起動する必要がある場合はどうなりますか?
set 命令には非常に複雑なパラメータがあります。これにより、setnx と Expired を同時に 1 つの命令に結合できるはずです。
09
Redis を非同期キューとして使用したことがありますか?どのように使用しましたか?デメリットは何ですか?
通常、リスト構造をキューとして使用し、rpush がメッセージを生成し、lpop がメッセージを消費します。 lpop からのメッセージがない場合は、しばらくスリープしてから再試行してください。
欠点:
コンシューマーがオフラインになると、生成されたメッセージが失われるため、rabbitmq などの専門的なメッセージ キューを使用する必要があります。
一度生産して複数回消費することはできますか?
パブリッシュ/サブトピック サブスクライバ モードを使用すると、1:N メッセージ キューを実現できます。
10
キャッシュペネトレーションとは何ですか?それを避けるにはどうすればよいでしょうか?キャッシュアバランチとは何ですか?それを避けるにはどうすればよいでしょうか?
キャッシュペネトレーション
一般的なキャッシュシステムはキーに基づいてクエリをキャッシュするため、対応する値が存在しない場合はバックエンドシステム(DBなど)で検索する必要があります。一部の悪意のあるリクエストは、存在しないキーを意図的にクエリするため、リクエストの量が多い場合、バックエンド システムに多大な負荷がかかります。これをキャッシュペネトレーションと呼びます。
回避するにはどうすればよいですか?
1: クエリ結果が空の場合もキャッシュされるため、キャッシュ時間を短く設定するか、キーに対応するデータを挿入した後にキャッシュをクリアします。
2: 存在してはいけないキーをフィルターします。考えられるすべてのキーを大きなビットマップに配置し、クエリ時にビットマップをフィルター処理することができます。
キャッシュ雪崩
キャッシュ サーバーが再起動されるか、一定期間内に多数のキャッシュが失敗すると、障害が発生したときにバックエンド システムに多大な負荷がかかります。 。システムのクラッシュを引き起こします。
回避するにはどうすればよいですか?
1: キャッシュの有効期限が切れたら、ロックまたはキューイングを使用して、データベースを読み取り、キャッシュに書き込むスレッドの数を制御します。たとえば、データのクエリと特定のキーのキャッシュの書き込みを許可されるのは 1 つのスレッドだけであり、他のスレッドは待機します。
2: 2 次キャッシュを作成します。A1 はオリジナル キャッシュ、A2 はコピー キャッシュです。A1 が失敗した場合、A2 にアクセスできます。A1 キャッシュの有効期限は短期に設定され、A2 はto long-term
3 : キャッシュの無効化時間ができるだけ均一になるように、キーごとに異なる有効期限を設定します。
以上がRedis の面接でよくある質問を共有するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



