

オラクルの面接の質問と回答を整理する


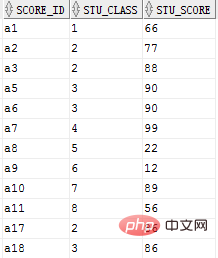
select stu_class, max(stu_score) from core group by stu_class ;
select t2.* from table1 t1, table1 t2 where t1.fid = t2.fid and t1.fno <> t2.fno;
select * from core co1 where co1.STU_CLASS in ( select co.STU_CLASS from CORE co group by co.STU_CLASS having count(co.STU_CLASS) >1); select DISTINCT c2.* from core c1 ,core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE; SELECT * FROM core c1 where 1=1 and EXISTS (select 1 from core c2 where c1.STU_CLASS = c2.STU_CLASS and c1.STU_SCORE <> c2.STU_SCORE);
( Fempno varchar2(10) not null pk, Fempname varchar2(20) not null, Fage number not null, Fsalary number not null );
fsalary>9999 and fage > 35 fsalary>9999 and fage < 35 fsalary <9999 and fage > 35 fsalary <9999 and fage < 35
select sum(case when fsalary > 9999 and fage > 35then 1else 0end) as "fsalary>9999_fage>35",sum(case when fsalary > 9999 and fage < 35then 1else 0end) as "fsalary>9999_fage<35",sum(case when fsalary < 9999 and fage > 35then 1else 0end) as "fsalary<9999_fage>35",sum(case when fsalary < 9999 and fage < 35then 1else 0end) as "fsalary<9999_fage<35"from empinfo;
select sum(case when stu_score < 60 then 1 else 0 end ) as "60分以下人数" ,sum(case when stu_score > 60 and stu_score <= 70 then 1 else 0 end ) as "60到70分人数" ,sum(case when stu_score > 70 and stu_score <= 80 then 1 else 0 end ) as "70到80分人数" ,sum(case when stu_score > 80 and stu_score <= 100 then 1 else 0 end ) as "80分以上人数" from core;
月の人所得 月の人所得
個人の総所得に対して 1 つの SQL ステートメント (1 つであることに注意) が必要です(人を区別しない) 毎月と前月と来月
要件リスト 出力は
月の収入、前月の収入、来月の収入です
MONTHS PERSON INCOME ---------- ---------- ----------200807 mantisXF 5000200806 mantisXF2 3500200806 mantisXF3 3000200805 mantisXF1 2000200805 mantisXF6 2200200804 mantisXF7 1800200803 8mantisXF 4000200802 9mantisXF 4200200802 10mantisXF 3300200801 11mantisXF 4600200809 11mantisXF 6800
months, (incomes), (prev_months), (( ), ), ), lag(incomes) ( months), ) prev_months, decode(lead(months) ( months), to_char(add_months(to_date(months, ), ), ), lead(incomes) ( months), ) next_months ( months, (income) incomes a months) aa) aaagroup (INCOMES) (PREV_MONTHS) (NEXT_MONTHS)
C1 c2
2005-01- 01 1
2005-01-01 3
2005-01-02 5
2005-01-01 4
2005-01-02 5
合計 9
SQL ステートメントを実行して完了してください。
select nvl(to_char(t02,'yyyy-mm-dd'),'合计'),sum(t01)from test group by rollup(t02)
1NF (第 1 正規形)、2NF (第 2 正規形)、3NF (第 3 正規形)、
第一正規形 (1NF) の簡単な紹介: リレーショナル モデルの各特定のパラメーターR 関係 r において、各属性値がそれ以上分割できない最小のデータ単位である場合、R は第一正規形の関係であると言われます。
2 番目は従業員番号がキーワードであり、電話番号は職場の電話番号と自宅の電話番号の 2 つの属性に分かれています。
3 番目は従業員番号がキーワードですが、それぞれのレコードが必須です電話番号は 1 つだけ持つことができます。
上記 3 つの方法のうち、最初の方法が最も推奨されません。後の 2 つの方法は、実際の状況に応じて選択してください。
第 2 正規形 (2NF): 関係スキーマ R (U, F) 内のすべての非主属性が候補キーワードに完全に依存している場合、関係 R は第 2 正規形に属すると言われます。
条件に基づいて、キーワードは結合されたキーワード (SNO、CNO) です。
上記のリレーショナル モデルをアプリケーションで使用すると、次の問題があります:
b. 更新異常 ある科目の単位数が調整されると、対応するタプル CREDIT 値が更新され、同じ科目の単位数が異なる場合があります。c. 例外を挿入します。たとえば、新しいコースを開く予定の場合、誰も受講しておらず、学生番号のキーワードもないため、コースを登録する前に誰かが受講するのを待つしかありません。そしてクレジット。
理由: 非キーワード属性 CREDIT は機能的にのみ CNO に依存します。つまり、CREDIT は完全にではなく、結合されたキーワード (SNO、CNO) に部分的に依存します。
d. 削除の例外として、学生が卒業した場合は、現在のデータベースから選択レコードを削除します。新入生がまだ一部のコースを受講していない場合、コースと単位記録は保存できません。
解決策: 2 つの関係モード SC1 (SNO、CNO、GRADE) と C2 (CNO、CREDIT) に分割します。新しい関係には 2 つの関係スキーマが含まれており、SCN の
外部キーワード CNO を介して接続されています。必要に応じて、元の関係を復元するために自然な接続が作成されます。 第 3 正規形 (3NF): 関係スキーマがすべて非である場合- R (U, F) の主属性がどの候補キーワードにも推移的に依存しない場合、関係 R は第 3 正規形に属すると言われます。
名前、学部、学部名、学部住所を表します。キーワード SNO は各属性を決定します。単一キーワードなので部分依存の問題はないので2NFでなければなりません。ただし、この関係には多くの冗長性が必要です。学生がいる
属性 DNO、DNAME、および LOCATION は、繰り返し保存、挿入、削除、変更され、上記の例と同様の状況が発生します。 。
原因: 関係には推移的な依存関係があります。つまり、SNO -> DNO です。しかし、DNO -> SNO は存在せず、DNO -> LOCATION であるため、重要なのは SNO と LOCATIO
です。
N 函数决定是通过传递依赖 SNO -> LOCATION 实现的。也就是说,SNO不直接决定非主属性LOCATION。
解决目地:每个关系模式中不能留有传递依赖。
解决方法:分为两个关系 S(SNO,SNAME,DNO),D(DNO,DNAME,LOCATION)
注意:关系S中不能没有外关键字DNO。否则两个关系之间失去联系。
7,简述oracle行触发器的变化表限制表的概念和使用限制,行触发器里面对这两个表有什么限制。
变化表mutating table
被DML语句正在修改的表
需要作为DELETE CASCADE参考完整性限制的结果进行更新的表也是变化的
限制:对于Session本身,不能读取正在变化的表
限制表constraining table
需要对参考完整性限制执行读操作的表
限制:如果限制列正在被改变,那么读取或修改会触发错误,但是修改其它列是允许的。
8、oracle临时表有几种。
临时表和普通表的主要区别有哪些,使用临时表的主要原因是什么?
在Oracle中,可以创建以下两种临时表:
a。会话特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT PRESERVE ROWS;
b。事务特有的临时表
CREATE GLOBAL TEMPORARY ( ) ON COMMIT DELETE ROWS; CREATE GLOBAL TEMPORARY TABLE MyTempTable
所建的临时表虽然是存在的,但是你试一下insert 一条记录然后用别的连接登上去select,记录是空的,明白了吧。
下面两句话再贴一下:
ON COMMIT DELETE ROWS说明临时表是事务指定,每次提交后ORACLE将截断表(删除全部行)ON COMMIT PRESERVE ROWS说明临时表是会话指定,当中断会话时ORACLE将截断表。
9,怎么实现:使一个会话里面执行的多个过程函数或触发器里面都可以访问的全局变量的效果,并且要实现会话间隔离?
--个人理解就是建立一个包,将常量或所谓的全局变量用包中的函数返回出来就可以了,摘抄一短网上的解决方法Oracle数据库程序包中的变量,在本程序包中可以直接引用,但是在程序包之外,则不可以直接引用。对程序包变量的存取,可以为每个变量配套相应的存储过程<用于存储数据>和函数<用于读取数据>来实现。 3.2 实例 --定义程序包 create or replace package PKG_System_Constant is C_SystemTitle nVarChar2(100):='测试全局程序变量'; --定义常数 --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2; G_CurrentDate Date:=SysDate; --定义全局变量 --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date); End PKG_System_Constant; / create or replace package body PKG_System_Constant is --获取常数<系统标题> Function FN_GetSystemTitle Return nVarChar2 Is Begin Return C_SystemTitle; End FN_GetSystemTitle; --获取全局变量<当前日期> Function FN_GetCurrentDate Return Date Is Begin Return G_CurrentDate; End FN_GetCurrentDate; --设置全局变量<当前日期> Procedure SP_SetCurrentDate (P_CurrentDate In Date) Is Begin G_CurrentDate:=P_CurrentDate; End SP_SetCurrentDate; End PKG_System_Constant; / 3.3 测试 --测试读取常数 Select PKG_System_Constant.FN_GetSystemTitle From Dual; --测试设置全局变量 Declare Begin PKG_System_Constant.SP_SetCurrentDate(To_Date('2001.01.01','yyyy.mm.dd')); End; / --测试读取全局变量 Select PKG_System_Constant.FN_GetCurrentDate From Dual;
10,aa,bb表都有20个字段,且记录数量都很大,aa,bb表的X字段(非空)上有索引,
请用SQL列出aa表里面存在的X在bb表不存在的X的值,请写出认为最快的语句,并解译原因。
select aa.x from aa where not exists (select 'x' from bb where aa.x = bb.x) ;
以上语句同时使用到了aa中x的索引和的bb中x的索引
11,简述SGA主要组成结构和用途?
SGA是Oracle为一个实例分配的一组共享内存缓冲区,它包含该实例的数据和控制信息。SGA在实例启动时被自动分配,当实例关闭时被收回。数据库的所有数据操作都要通过SGA来进行。
SGA中内存根据存放信息的不同,可以分为如下几个区域:
a.Buffer Cache:存放数据库中数据库块的拷贝。它是由一组缓冲块所组成,这些缓冲块为所有与该实例相链接的用户进程所共享。缓冲块的数目由初始化参数DB_BLOCK_BUFFERS确定,缓冲块的大小由初始化参数DB_BLOCK_SIZE确定。大的数据块可提高查询速度。它由DBWR操作。
b. 日志缓冲区Redo Log Buffer:存放数据操作的更改信息。它们以日志项(redo entry)的形式存放在日志缓冲区中。当需要进行数据库恢复时,日志项用于重构或回滚对数据库所做的变更。日志缓冲区的大小由初始化参数LOG_BUFFER确定。大的日志缓冲区可减少日志文件I/O的次数。后台进程LGWR将日志缓冲区中的信息写入磁盘的日志文件中,可启动ARCH后台进程进行日志信息归档。
c. 共享池Shared Pool:包含用来处理的SQL语句信息。它包含共享SQL区和数据字典存储区。共享SQL区包含执行特定的SQL语句所用的信息。数据字典区用于存放数据字典,它为所有用户进程所共享。
12什么是分区表?简述范围分区和列表分区的区别,分区表的主要优势有哪些?
使用分区方式建立的表叫分区表
范围分区
每个分区都由一个分区键值范围指定(对于一个以日期列作为分区键的表,“2005 年 1 月”分区包含分区键值为从“2005 年 1 月 1 日”
到“2005 年 1 月 31 日”的行)。
列表分区
每个分区都由一个分区键值列表指定(对于一个地区列作为分区键的表,“北美”分区可能包含值“加拿大”“美国”和“墨西哥”)。
分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务。通过分区,数据库设计人员和管理员能够解决前沿应用程序带来的一些难题。分区是构建千兆字节数据系统或超高可用性系统的关键工具。
13、背景: 特定のデータがアーカイブ ログで実行されており、RMAN を使用してデータベースの完全バックアップとコールド バックアップが作成されています。
すべてのアーカイブ ログが利用可能です。現在、すべての制御ファイルが破損しており、他のファイルはすべて無傷です。何が問題ですか?データベースを復元する方法を 1 つまたは 2 つ教えてください。
返信方法:
1. コールド バックアップを使用し、すべてのコールド バックアップ ファイルを元のディレクトリに直接コピーし、データベースを再起動します
2. アーカイブ ログを使用します
- #データベース NOMOUNT #データ ファイルと REDO ログ ファイルの場所を指定する制御ファイルを作成します。
- キャンセルするまでバックアップ制御ファイルを使用して RECOVER DATABASE コマンドを使用してデータベースを復元します。このとき、アーカイブ ログ
- ALETER DATABASE OPEN RESETLOGS;
-
## を使用できます。
#データベースと制御ファイルを再度バックアップします - 14. rman を使用してバックアップ ステートメント (バックアップ テーブル スペース TSB、レベル 2 増分バックアップ) を作成します。
関連する学習の推奨事項:
oracle データベース学習チュートリアル[トピックの推奨事項]:2020 年の Oracle 面接の質問の概要 ( 上へ現在まで)#########
以上がオラクルの面接の質問と回答を整理するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
81
11
21
75
15
1378
52
81
11
21
75

 Oracleでユーザーと役割を作成するにはどうすればよいですか?
Mar 17, 2025 pm 06:41 PM
Oracleでユーザーと役割を作成するにはどうすればよいですか?
Mar 17, 2025 pm 06:41 PM
この記事では、SQLコマンドを使用してOracleでユーザーと役割を作成する方法について説明し、役割の使用を含むユーザー許可を管理するためのベストプラクティス、最小特権の原則、定期的な監査について説明します。
 透明なデータ暗号化(TDE)を使用して、Oracleで暗号化を構成するにはどうすればよいですか?
Mar 17, 2025 pm 06:43 PM
透明なデータ暗号化(TDE)を使用して、Oracleで暗号化を構成するにはどうすればよいですか?
Mar 17, 2025 pm 06:43 PM
この記事では、Oracleで透明なデータ暗号化(TDE)を構成する手順を概説し、ウォレットの作成、TDEの有効化、およびさまざまなレベルでのデータ暗号化の詳細を説明します。また、データ保護やコンプライアンスなどのTDEのメリット、およびVeriの方法についても説明しています
 最小限のダウンタイムでOracleでオンラインバックアップを実行するにはどうすればよいですか?
Mar 17, 2025 pm 06:39 PM
最小限のダウンタイムでOracleでオンラインバックアップを実行するにはどうすればよいですか?
Mar 17, 2025 pm 06:39 PM
この記事では、RMANを使用した最小限のダウンタイムでOracleでオンラインバックアップを実行する方法、ダウンタイムを減らし、データの一貫性を確保し、バックアップの進捗を監視するためのベストプラクティスを実行する方法について説明します。
 Oracleで自動ワークロードリポジトリ(AWR)および自動データベース診断モニター(ADDM)を使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:44 PM
Oracleで自動ワークロードリポジトリ(AWR)および自動データベース診断モニター(ADDM)を使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:44 PM
この記事では、データベースのパフォーマンス最適化にOracleのAWRとADDMの使用方法について説明します。 AWRレポートの生成と分析の詳細、およびADDMを使用してパフォーマンスボトルネックを識別および解決します。
 Oracle PL/SQL Deep Dive:マスタリング手順、機能、パッケージ
Apr 03, 2025 am 12:03 AM
Oracle PL/SQL Deep Dive:マスタリング手順、機能、パッケージ
Apr 03, 2025 am 12:03 AM
OraclePl/SQLの手順、機能、パッケージは、それぞれ操作、返品値、および整理コードを実行するために使用されます。 1.プロセスは、挨拶の出力などの操作を実行するために使用されます。 2。関数は、2つの数値の合計を計算するなど、値を計算して返すために使用されます。 3.パッケージは、関連する要素を整理し、在庫を管理するパッケージなど、コードのモジュール性と保守性を向上させるために使用されます。
 Oracle Goldengate:リアルタイムのデータレプリケーションと統合
Apr 04, 2025 am 12:12 AM
Oracle Goldengate:リアルタイムのデータレプリケーションと統合
Apr 04, 2025 am 12:12 AM
OracleGoldEngateを有効にして、ソースデータベースのトランザクションログをキャプチャし、ターゲットデータベースに変更を適用することにより、リアルタイムのデータレプリケーションと統合を可能にします。 1)変更のキャプチャ:ソースデータベースのトランザクションログを読み取り、トレイルファイルに変換します。 2)送信の変更:ネットワーク上のターゲットシステムへの送信、および送信はデータポンププロセスを使用して管理されます。 3)アプリケーションの変更:ターゲットシステムでは、コピープロセスがトレイルファイルを読み取り、変更を適用してデータの一貫性を確保します。
 Oracle Data Guardでスイッチオーバーおよびフェールオーバー操作を実行するにはどうすればよいですか?
Mar 17, 2025 pm 06:37 PM
Oracle Data Guardでスイッチオーバーおよびフェールオーバー操作を実行するにはどうすればよいですか?
Mar 17, 2025 pm 06:37 PM
この記事では、Oracle Data Guardのスイッチオーバーとフェールオーバーの手順を詳述し、データの損失を最小限に抑え、スムーズな操作を確保するために、違い、計画、テストを強調します。
 Oracleの表空間サイズを確認する方法
Apr 11, 2025 pm 08:15 PM
Oracleの表空間サイズを確認する方法
Apr 11, 2025 pm 08:15 PM
Oracle Tablespaceサイズを照会するには、次の手順に従ってください。クエリを実行して、TableSpace名を決定します。DBA_TABLESPACesからTableSpace_Nameを選択します。クエリを実行してテーブルスペースのサイズをクエリします:sum(bytes)をtotal_size、sum(bytes_free)asavail_space、sum(bytes) - sum(bytes_free)as sum(bytes_free)as dba_data_files from tablespace_
