

クラスターの主なボトルネックは何ですか?

クラスターの主なボトルネックはディスクです。集団作戦に直面したとき、私たちが望むのはすぐにそれを読むことです。しかし、ビッグデータの前では、データの読み取りにはディスク IO が必要であり、ここでの IO は水道管として理解できます。パイプラインが大きくて強力であればあるほど、T レベルのデータをより速く読み取ることができます。したがって、IO の品質はクラスターのデータ処理に直接影響します。

#クラスターのボトルネックについては多くの意見がありますが、その中でもネットワークとディスク IO についてはより議論の余地があります。ここで説明する必要があるのは、 ネットワークは希少なリソースであり、ボトルネックではないということです。
ディスク IO の場合: (ディスク IO: ディスク出力出力)
クラスター操作に直面したときに必要なのは、即時の可読性です。しかし、ビッグデータの前では、データの読み取りには IO が必要であり、ここでの IO は水道管として理解できます。パイプラインが大きくて強力であればあるほど、T レベルのデータをより速く読み取ることができます。したがって、IO の品質はクラスターのデータ処理に直接影響します。
参考のためにいくつかの例を示します。
ケース 1
Alibaba Cloud を使用して以来、3 つの障害 (1、2、および 3) が発生しました。これら 3 つの障害はすべて、高ディスク IO に関連しています。
最初の障害は、zzk.cnblogs.com インデックス サービスを実行しているクラウドで発生しました。 サーバー上の Avg.Disk Read Queue 長さは 200 を超えます。
2 番目の障害は、images.cnblogs.com 静的ファイルを実行しているクラウド サーバーで発生しました。そのとき、Avg.Disk Read キューの長さは約 2 (後で分析すると、ファイルを直接読み取って応答する画像サイトなどのアプリケーションの場合、ディスク読み取りキュー) この値に達する長さは応答速度に大きく影響します);
データベース サービスを実行しているクラウド サーバーで 3 回目の障害が発生しました。そのときの平均ディスク書き込みキュー 長さが 4 ~ 5 に達すると、多くのデータベース書き込み操作がタイムアウトになります。
(ここでは、「ハードディスク」と「ディスク」の両方について言及します。このように定義します。クラウド サーバーで見られるハードディスクはディスク [仮想ハードディスク] と呼ばれ、物理的なハードディスクはクラウド サーバーで見られます。クラスターはハードディスクと呼ばれます)
これら 3 回の高いディスク IO は、クラウド サーバー内のアプリケーションが原因ではありませんでした。最も直接的な証拠は、クラウド サービスを別のクラスターに移行した後、問題が解決されたことです。すぐに。言い換えれば、クラウド サーバーのディスク IO が高いのは、次のような理由があります。 クラスターが配置されているクラスターのハードディスク IO が高くなります。
クラスターのハードディスク IO は、クラスター内のすべてのクラウド サーバーのディスク IO の累積です。クラスターのハードディスク IO が高いのは、クラスター内の一部のクラウド サーバーのディスク IO が高すぎるためです。高い。そしてそれ以来、私たちは クラウド サーバー内のアプリケーションによって生成されるディスク IO は正常の範囲内ですが、問題は、他のユーザーのクラウド サーバーが大量のディスク IO を生成し、クラスター全体のハードディスク IO が高くなり、影響を受けることです。
他のクラウド サーバーによって引き起こされるハードディスク IO の問題が私たちに影響を与えるのはなぜですか?問題の根本は、クラスターのハードディスク IO がクラスター内のすべてのクラウド サーバーで共有されており、この共有が効果的に制限されていないことです。 事実上孤立しているため、誰もがこのリソースを求めて競争しており、同時に多くの人がそれを求めて競争すると、長い列ができてしまいます。
そして、各クラウド サーバーについて、何台のクラウド サーバーが競合しているのかわかりません。クラウド サーバー ユーザーの観点から見ると、 この競争を避ける方法はなく、万博の時と同じように、どれだけ早く起きて並んでも、非常に長い行列に並ばなければなりません。
各クラウド サーバーが使用するハードディスク IO リソースが制限または分離されている場合、他のクラウド サーバーは 過剰なディスク IO がクラウド サーバーに影響を与えることはありません。コミュニティと同じように、1 人で家を借りていれば、たとえ 100 人が別の家に住んでいたとしても、影響は受けません。
CPU、メモリ、帯域幅、ハードディスク容量は購入できますが、心から役立つハードディスク IO は購入できません。これは現在のものです。 Alibaba Cloud 仮想化 プラットフォームの設計時に考慮されていなかった重要な問題。
Alibaba Cloud の技術スタッフと連絡を取ったところ、彼らはこの問題を認識しており、この問題ができるだけ早く解決されることを望んでいることがわかりました。
------------------------------------------------- --- --------------------------------------------------- --- ------------------------------------------------
ケース 2
クラウド コンピューティングへの道 - Alibaba Cloud への移行後: 20130314 クラウド サーバー障害
##まず最初に、このクラウド サーバーの皆様にお詫びを申し上げます。 17:30頃に障害が判明しましたが、18:30頃には正常に戻り、皆様にはご迷惑をおかけしましたが、ご容赦ください。 障害の原因は、クラウド サーバーのクラスター負荷が高すぎて、ディスク書き込みパフォーマンスが急激に低下し、多くのデータベース書き込み操作がタイムアウトになったことでした。後で通常の状態に戻った解決策は、クラウド サーバーを別のクラスターに移行することでした。 障害の主なプロセスは次のとおりです。 今朝 9 時 15 分頃、庭師が庭を訪れた際に 502 Bad Gateway エラーが発生したと電子メールで報告しました。 これは、Alibaba Cloud Load Balancer によって返されたエラーです。Tegine は、Alibaba によって開発されたオープンソース Web サーバーです。 Alibaba Cloud が提供する負荷分散サービスは、Tegine リバース プロキシを通じて実装される可能性があると推測されます。このエラー ページは、ロード バランサーのクラウド サーバーが 500 シリーズ エラーなどの無効な応答を返したことをロード バランサーが検出したことを示します。
この状況を作業指示書を通じて Alibaba Cloud に報告しました。受け取ったフィードバックは、引き続き観察するというものでした。これは、ユーザーのネットワーク回線の一時的な問題が原因である可能性があります。
この期間中にこの問題は発生しておらず、他のユーザーからもこの問題の報告がなかったため、引き続き観察するという対処方法も承認しました。
(その後の分析によると、502 Bad Gateway エラーの発生は、クラスタの瞬間的な負荷が高いことが原因である可能性があります)
午後 17 時 20 分頃、私たち自身もエラーに遭遇しました。 502 Bad Gateway エラー。約 1 ~ 2 分間続きました。下の図を参照してください: 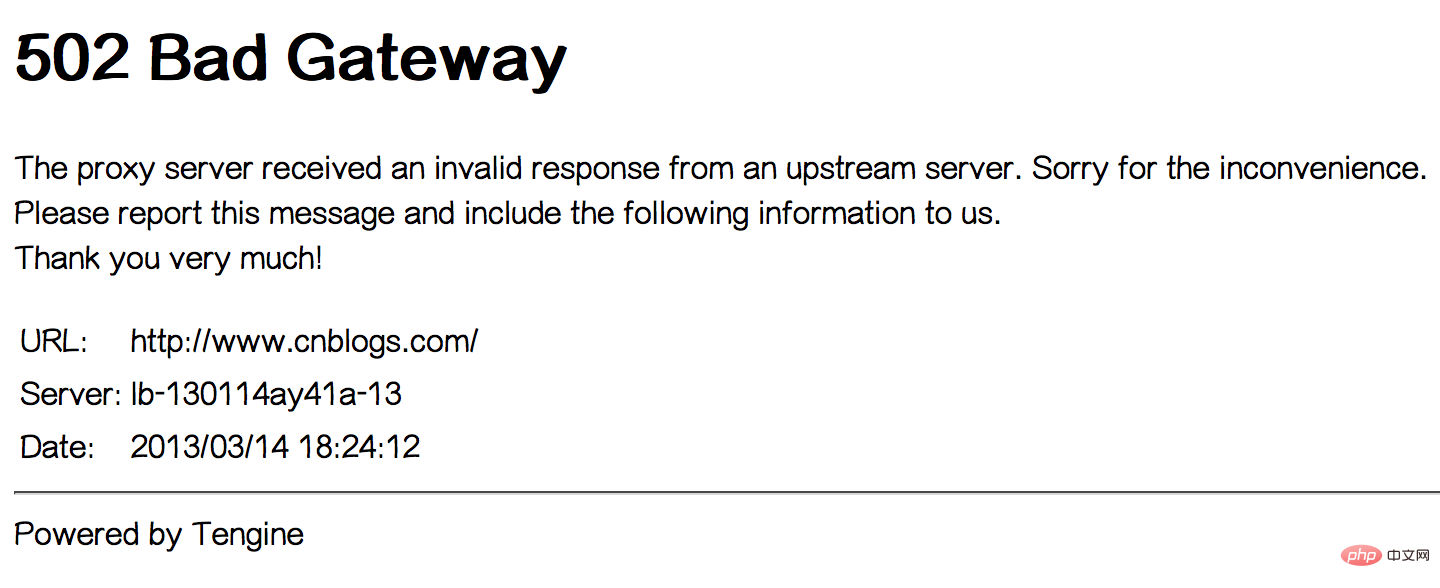
問題が発生している間、すぐに 2 つのクラウド サーバーにログインして状況を確認したところ、IIS の同時接続数が 30 倍以上に増加していることがわかりました。
Send/sec は 0 で、状況は両方のクラウド サーバーで同じです。その時点では、2 つのクラウド サーバー自体には問題はないが、問題はそれらとデータベース サーバー間のネットワーク通信にある可能性があると結論付けられました。
手紙。今後も作業指示書を通じてこの状況を Alibaba Cloud に報告していきます。
作業指示書に記入するとすぐに、庭の友人から電話があり、ブログのバックエンドで記事を公開できないとの連絡を受けました。テストしたところ、確かに公開は不可能で、データベース タイムアウトが発生しました。以下の図に示すように、エラーが報告されました。 
しかし既存の記事を開くのは非常に高速です。つまり、読み取りは正常ですが、書き込みには問題があります。データベース サーバーにすばやくログインし、パフォーマンス モニターでディスク IO ステータスを確認します。 案の定、ディスク書き込みパフォーマンスに問題があります。下の図を参照してください: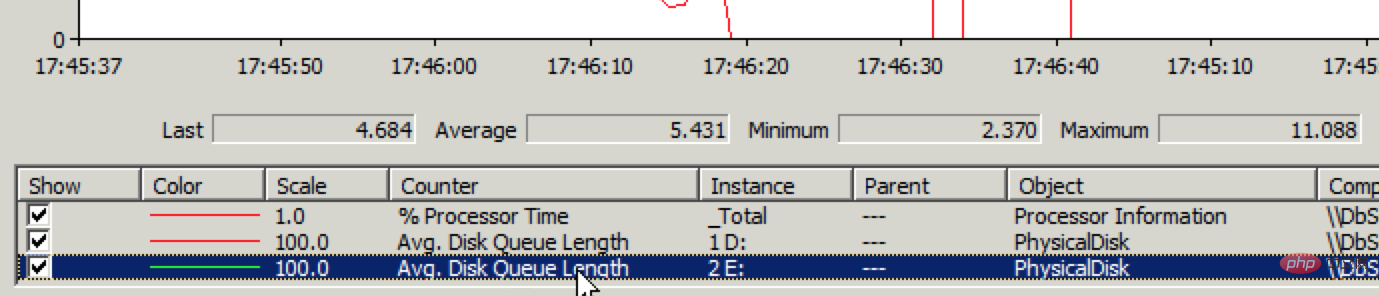

Avg. Disk Write Queue Length が 1 を超える場合は問題があることを意味し、現在は平均が 4 ~ 5 に達しています。 Alibaba Cloud Web サイトの管理コンソールに入ると、以下の図に示すように、ディスク IO の問題がより明確になります。
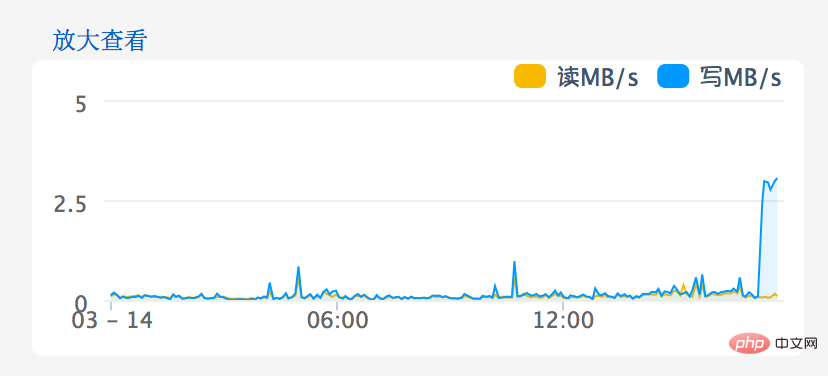
引き続き Alibaba Cloud に状況を報告してください。私が受け取ったフィードバックは次のとおりです。下の図に示すように、このクラウド サーバーの IOPS が高すぎました。
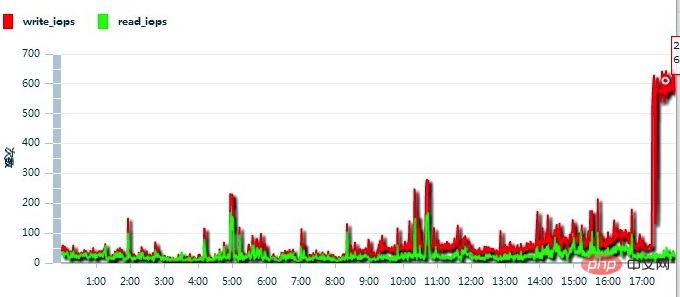
#そこで、Alibaba Cloud スタッフはクラウド サーバーを次の場所に移行しました。別のクラスターが発生し、問題はすぐに解決されました。
------------------------------------------------- --- --------------------------------------------------- --- --------------------------------------
ケース 3
14:17頃、このフラッシュメモリが見えました。すぐにブログのバックグラウンド テストに入り、送信時に次のエラーが発生することがわかります:

「タイムアウトの期限が切れました。操作が完了する前にタイムアウト期間が経過するか、サーバーが停止します。」応答していません。"
これはデータベース書き込みタイムアウト エラーです。このエラー メッセージは今でも覚えています。私はこれまでに 2 回 (3 月 14 日と 4 月 2 日)、この問題に遭遇しました。いずれも、データベース サーバーが配置されているクラウド サーバー上のディスク IO の問題が原因でした。
クラウド サーバーにログオンし、Windows パフォーマンス モニターを確認し、ログ ファイルが存在するディスクの IO 監視データ Avg.Disk Write Queue を見つけます。 平均の長さは5を超えています。パフォーマンス モニターでのこの値の縦軸の最大値は 1 です。値 5 がどれほど高いか想像できるでしょう。パフォーマンス モニターのグラフはほぼ直線です。下の図を参照してください(最高値) 実際には 20 に達しました。本当に恐ろしいです):
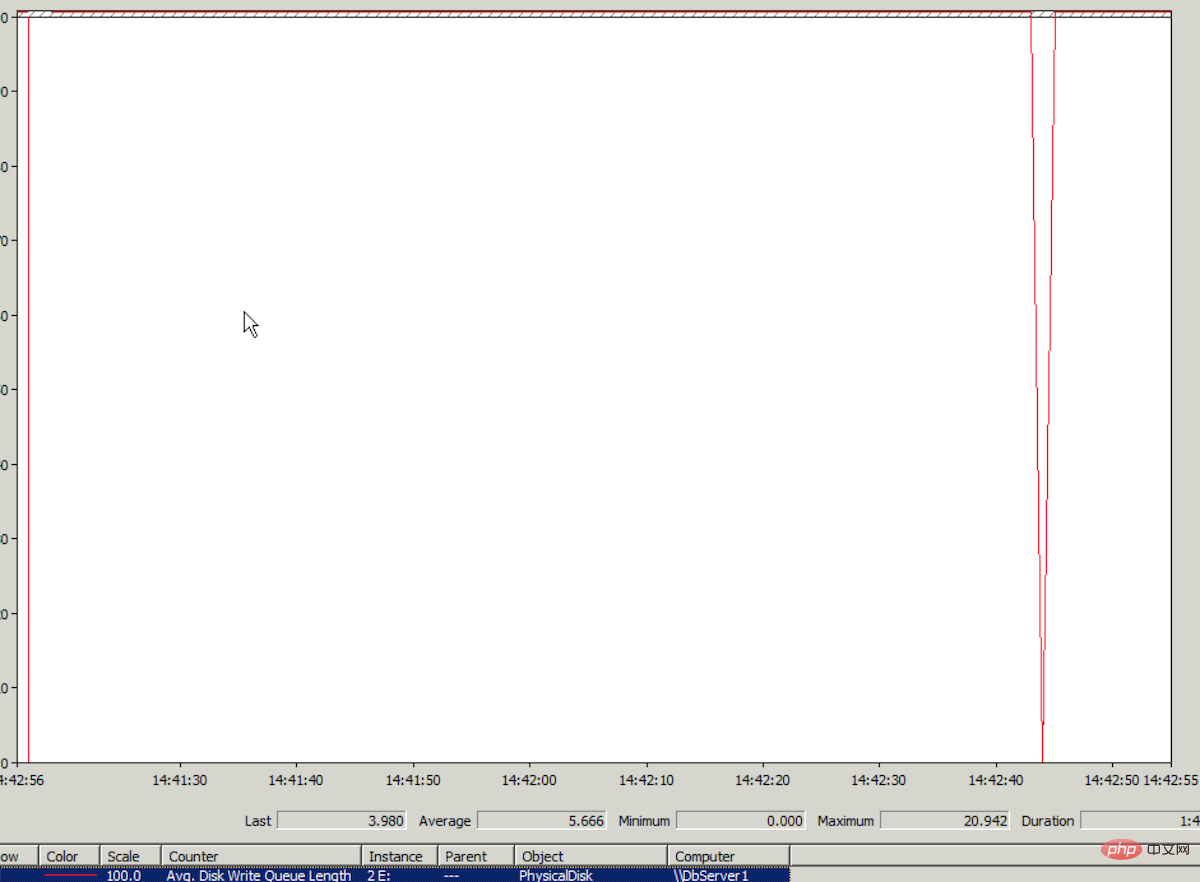
(ログ ファイルが配置されているディスク上の IO が高くなると、データベース書き込みタイムアウトが表示されるのはなぜですか?モードは Full を使用します。データベースにデータを書き込むとき、書き込み操作は最初にログで実行されます。)
この問題のパフォーマンスは、3 月 14 日のディスク IO 問題のパフォーマンスと同じであるため、今回も同様の理由で、クラウドサーバーが配置されているクラスターのディスクIO負荷が高いことが原因であると結論付けています。
14:19、私たちは Alibaba Cloud に作業指示書を送信しました。特にタイトルに「緊急」を追加しました。
14:23、Alibaba Cloud カスタマー サービスは、私たちが提出した問題を確認していると返信しました。
14:31、Alibaba Cloud カスタマー サービスは、検査のために関連部門にフィードバックされたと回答しました。
14:42、Alibaba Cloud カスタマーサービスからはそれ以上の連絡がなかったので、「短期間で解決できない場合は、できるだけ早くクラスターの移行を実施したいと考えています」と回答しました(この問題は解決しました) 3 月 14 日のクラスター移行を通じて、Alibaba Cloud の技術スタッフも、クラスターの高負荷によって引き起こされるディスク IO 問題については、現時点での唯一の解決策はクラスター移行であると述べました);
14:47、Alibaba Cloud カスタマー サービスのみが回答しました処理中であること;
14:59になっても何も知らせはなく、私たちは非常に不安でした(40分が経過しても何の説明もありませんでした)。クラスターの移行が先ですか?";
その後、Ali から電話を受けました。クラウド カスタマー サービスから電話があり、クラスター内の他のクラウド サーバーが占有している高ディスク IO が影響しており、対応中であるとのことでした。 。 。 。
しばらくして、Alibaba Cloud カスタマー サービスから再度電話があり、クラウド サーバーのシステムまたはアプリケーションがサーバー ディスクの書き込み停止の原因である可能性があります。クラウド サーバーを再起動しましょうとのことでした。 (この時点でクラスターの負荷が低下しているにもかかわらず、クラウド サーバーのディスク IO がまだ高いことが考えられます。)
15:23 頃、データベース サーバーを再起動しましたが、問題は残りました。
15:30、Alibaba Cloud カスタマー サービスは最終的にクラスターの移行を決定しました (作業指示の送信からクラスターの移行の決定までに 1 時間 10 分かかりました)
15:45、クラスターの移行が完了しました (前回は移行に 5 分未満かかりましたが、今回は 15 分かかりました。これは、Alibaba Cloud カスタマー サービスによると、クラスターの移行に必要な最長時間でもあります)
移行後、ディスク IO (平均ディスク書き込みキュー長) は依然として非常に高いです。
今回のクラスター移行では、前回のように問題をすぐに解決できないのはなぜですか?考えられる理由は 2 つあります:
1. 移行後もクラスターのディスク IO 負荷が依然として高い;
2. クラウド サーバー上のディスク IO が多いパーティションには、データベース ログ ファイルが含まれています。おそらく、この期間中はログの書き込み操作が通常よりも頻繁に行われ (ただし、急増はほぼ不可能です)、すべてのログ ファイルが同じパーティションに存在します。 領域がクラウド サーバーのディスク IO の一定の制限を超え、ディスク IO パフォーマンスが急激に低下します (クラウド コンピューティングへの道のりに基づいて、可能性は比較的高いです - Alibaba Cloud に入った後: image.cnblogs.com を解決します) 応答速度が遅いという奇妙な問題)。以前、物理サーバーを使用していたときは、ログ ファイルが同じパーティションに配置されていたため、この問題は発生しませんでしたが、現在、クラウド サーバーのディスク IO 能力は物理サーバーのディスク IO 能力と比較できません。 比率が高く、ディスク IO はクラスター上の他のクラウド サーバーと競合します (詳細については、クラウド コンピューティングへの道 - Alibaba Cloud への移行後: 問題の根本 - 彼女の「人」は買うが、「心」は買わないを参照してください) ")。
理由が何であれ、問題を解決するための最後の手段は 1 つだけです。それは、ログ ファイルが配置されているディスク パーティションの IO 負荷を軽減することです。
ストレスを軽減するにはどうすればよいですか? 「Alibaba Cloud に移行後のいくつかの経験」の記事の「全体的なディスク IO パフォーマンスを向上させるための小さなレシピ」によると、別のディスク領域を購入し、ブログのコンテンツを保存するデータベース CNBlogsText (大きなテキスト データ) を書き込みます。ディスク IO (高圧) ログ ファイルが別のディスク パーティションに作成されます。
SQL Server では、データベース ログ ファイルをあるディスク パーティションから別のディスク パーティションに移動することをオンラインで行うことはできません。最初にデータベースをデタッチし、次にログ ファイルをターゲット パーティションにコピーしてからデータベースをアタッチする必要があります。アタッチするときは、ログ ファイルの場所を新しいパスに変更します。
したがって、選択の余地なく、CNBlogsText データベースは接続解除操作を実行し、接続を削除することを選択しました。予期せぬことに、接続解除プロセス中に悲劇が発生しました。接続解除は失敗し、エラーは次のとおりでした:
## #取引 (プロセス ID 124) が別のプロセスとのロック リソースでデッドロックされました デッドロックの犠牲者として選択されました。トランザクションを再実行してください。切り離しプロセス中にデッドロックが発生し、その後「犠牲」になりました。混乱を招くのは、接続が切断されない場合でも、デッドロックがなぜ発生するのかということです。ドロップする可能性があります 接続は、切り離し操作が正式に開始される前です。切り離しプロセス中に、データベースの書き込み操作も発生します。このときの書き込み操作により、デッドロックがトリガーされます。なぜ なぜデタッチが犠牲になる必要があるのでしょうか?良心的ではない。 接続解除が失敗すると、CNBlogsText データベースはシングル ユーザー状態になります。切り離しを続行すると、同じエラーが発生し、同じ「犠牲」が発生します。 そこで、SQL Server サービスを再起動しました。再起動後、CNBlogsText データベースのステータスは「回復中」に変わります。 時刻は16時45分になりました。 私はこれまでこのような回復中状態に遭遇したことがなく、対処方法がわかりません。軽率な行動をとる勇気もありません。 しばらくしてから、SQL Server のデータベース リストを更新すると、CNBlogsText データベースが以前のシングル ユーザー状態で表示されました。 (SQL Server を再起動すると、自動的に最初に回復中状態になり、その後シングル ユーザー状態になることがわかりました) シングル ユーザー ステータスの問題については、作業中に Alibaba Cloud カスタマー サービスに相談しました。注文があり、Alibaba Cloud カスタマー サービスがデータベースに連絡しました。エンジニアは次の操作を実行するようにアドバイスされました: alter database $db_name SET multi_userしたがって、次の SQL が実行されました:
exec sp_dboption 'CNBlogsText', N'single', N'false'
Database 'CNBlogsText' is already open and can only have one user at a time.
(更新:后来从阿里云DBA那学习到解决这个问题的方法:
select spid from sys.sysprocesses where dbid=DB_ID('dbname'); --得到当前占用数据库的进程id kill [spid] go alter login [username] disable --禁用新的访问 go use cnblogstext go alter database cnblogstext set multi_user with rollback immediate go
)
当时的情形下,我们不够冷静,急着想完成detach操作。觉得屏蔽CNBlogsText数据库的所有写入操作可能需要禁止这台服务器的所有数据库连接,这样会影响整站的正常访问,所以没从这个角度下手。
这时时间已经到了17:08。
我们也准备了最最后一招,假如实在detach不了,假如日志文件也出了问题,我们可以通过数据文件恢复这个数据库。这个场景我们遇到过,也实际成功操作过,详见:SQL Server 2005数据库日志文件损坏的情况下如何恢复数据库。所需的SQL语句如下:
use master alter database dbname set emergency declare @databasename varchar(255) set @databasename='dbname' exec sp_dboption @databasename, N'single', N'true' --将目标数据库置为单用户状态 dbcc checkdb(@databasename,REPAIR_ALLOW_DATA_LOSS) dbcc checkdb(@databasename,REPAIR_REBUILD) exec sp_dboption @databasename, N'single', N'false'--将目标数据库置为多用户状态
即使最最后一招也失败了,我们在另外一台云服务器上有备份,在异地也有备份,都有办法恢复,只不过需要的恢复时间更长一些。
想到这些,内心平静了一些,认识到当前最重要的是抛开内疚、紧张、着急,冷静面对。
我们在工单中继续咨询阿里云客服,阿里云客服联系了数据库工程师,让我们加一下这位工程师的阿里旺旺。
我们的电脑上没装阿里旺旺,于是打算自己再试试,如果还是解决不了,再求助阿里云的数据库工程师。
在网上找了一个方法:SET DEADLOCK_PRIORITY NORMAL(来源),没有效果。
时间已经到了17:38。
这时,我们冷静地分析一下:detach时,因为死锁“被牺牲”;从单用户改为多用户时,提示“Database 'CNBlogsText' is already open and can only have one user at a time.”。可能都是因为程序中不断地对这个数据库有写入操作。试试修改一下程序,看看能不能屏蔽所有对这个数据库的写入操作,然后再将数据库恢复为多 用户状态。
修改好程序,18:00之后进行了更新。没想到更新之后,将单用户改为多用户的SQL就能执行了:
exec sp_dboption 'CNBlogsText', N'single', N'false'
于是,Single User状态消失,CNBlogsText数据库恢复了正常状态,然后尝试detach,一次成功。
接着将日志文件复制到新购的磁盘分区中,以新的日志路径attach数据库。attach成功之后,CNBlogsText数据库恢复正常,博客后台可以正常发布博文,CNBlogsText数据库日志文件所在分区的磁盘IO(单独的磁盘分区)也正常。问题就这么解决了。
当全部恢复正常,如释重负的时候,时间已经到了18:35。
原以为可以用更多的内存弥补云服务器磁盘IO性能低的不足。但万万没想到,云服务器的硬伤不是在磁盘IO性能低,而是在磁盘IO不稳定。
更多相关知识,请访问:PHP中文网!
以上がクラスターの主なボトルネックは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7667
7667
 15
1393
52
1206
24
91
11
15
1393
52
1206
24
91
11

 ノードが Proxmox VE から完全に退避し、クラスターに再参加します
Feb 21, 2024 pm 12:40 PM
ノードが Proxmox VE から完全に退避し、クラスターに再参加します
Feb 21, 2024 pm 12:40 PM
ノードが ProxmoxVE から完全に退避し、クラスターに再参加するためのシナリオの説明。ProxmoxVE クラスター内のノードが損傷し、すぐに修復できない場合、障害のあるノードをクラスターから完全に追い出し、残留情報をクリーンアップする必要があります。そうしないと、障害ノードが使用していた IP アドレスを使用する新しいノードが正常にクラスターに参加できなくなり、同様に、クラスターから切り離された障害ノードが修復された後、クラスターとは関係ありませんが、クラスターに参加できなくなります。この単一ノードの Web 管理にアクセスできなくなり、バックグラウンドで元の ProxmoxVE クラスター内の他のノードに関する情報が表示され、非常に迷惑になります。クラスターからノードを削除します。ProxmoxVE が Ceph ハイパーコンバージド クラスターの場合、ホスト システム Debian 上のクラスター内の任意のノード (削除するノードを除く) にログインし、コマンドを実行する必要があります。
 Docker を使用してマルチノード クラスターを管理および拡張する方法
Nov 07, 2023 am 10:06 AM
Docker を使用してマルチノード クラスターを管理および拡張する方法
Nov 07, 2023 am 10:06 AM
今日のクラウド コンピューティング時代において、コンテナ化テクノロジは、オープンソースの世界で最も人気のあるテクノロジの 1 つになっています。 Docker の登場により、クラウド コンピューティングはより便利かつ効率的になり、開発者や運用保守担当者にとって不可欠なツールになりました。マルチノード クラスター テクノロジーのアプリケーションは、Docker に基づいて広く使用されています。マルチノード クラスターの展開を通じて、リソースをより効率的に利用し、信頼性と拡張性を向上させることができ、さらに展開と管理をより柔軟に行うことができます。次にDockerを使って以下のことを行う方法を紹介します。
 PHP高同時実行環境におけるデータベースの最適化方法
Aug 11, 2023 pm 03:55 PM
PHP高同時実行環境におけるデータベースの最適化方法
Aug 11, 2023 pm 03:55 PM
高同時実行環境における PHP データベースの最適化方法 インターネットの急速な発展に伴い、ますます多くの Web サイトやアプリケーションが高同時実行の課題に直面する必要があります。この場合、特にバックエンド開発言語として PHP を使用するシステムでは、データベースのパフォーマンスの最適化が特に重要になります。この記事では、PHP の高同時実行環境におけるデータベースの最適化方法をいくつか紹介し、対応するコード例を示します。接続プーリングの使用 同時実行性の高い環境では、データベース接続の頻繁な作成と破棄がパフォーマンスのボトルネックを引き起こす可能性があります。したがって、接続プーリングを使用すると、
 php の一般的なクラスターは何ですか?
Aug 31, 2023 pm 05:45 PM
php の一般的なクラスターは何ですか?
Aug 31, 2023 pm 05:45 PM
PHP の一般的なクラスターには、LAMP クラスター、Nginx クラスター、Memcached クラスター、Redis クラスター、および Hadoop クラスターが含まれます。詳細な紹介: 1. LAMP クラスター. LAMP とは、Linux、Apache、MySQL、および PHP の組み合わせを指します. これは一般的な PHP 開発環境です. LAMP クラスターでは、複数のサーバーが同じアプリケーションを実行し、ロード バランサーによってバランスがとられます.異なるサーバーに分散されている; 2. Nginx クラスター、Nginx は高性能 Web サーバーなどです。
 Workerman ドキュメントのサーバー クラスターの実装方法
Nov 08, 2023 pm 08:09 PM
Workerman ドキュメントのサーバー クラスターの実装方法
Nov 08, 2023 pm 08:09 PM
Workerman は、PHP が非同期ネットワーク通信をより効率的に処理できるようにする高性能 PHPSocket フレームワークです。 Workerman のドキュメントには、サーバー クラスターの実装方法に関する詳細な手順とコード例が記載されています。サーバー クラスターを実装するには、まずサーバー クラスターの概念を明確にする必要があります。サーバー クラスターは複数のサーバーをネットワークに接続し、負荷とリソースを共有することでシステムのパフォーマンス、信頼性、拡張性を向上させます。 Workermanでは以下の2つの方法が利用できます
 MongoDB を使用してデータ クラスタリングと負荷分散機能を実装する方法
Sep 19, 2023 pm 01:22 PM
MongoDB を使用してデータ クラスタリングと負荷分散機能を実装する方法
Sep 19, 2023 pm 01:22 PM
MongoDB を使用してデータ クラスタリングおよびロード バランシング機能を実装する方法 はじめに: 今日のビッグ データ時代では、データ量の急速な増加により、データベースのパフォーマンスに対する要件がさらに高まっています。これらの要件を満たすために、データ クラスタリングと負荷分散は不可欠な技術手段となっています。 MongoDB は、成熟した NoSQL データベースとして、データ クラスタリングと負荷分散をサポートする豊富な機能とツールを提供します。この記事では、MongoDB を使用してデータ クラスタリングと負荷分散機能を実装する方法と、具体的なコードを紹介します。
 どの Linux サーバー クラスタ システムですか?どのようなコンポーネントが含まれていますか?
Feb 22, 2024 pm 07:55 PM
どの Linux サーバー クラスタ システムですか?どのようなコンポーネントが含まれていますか?
Feb 22, 2024 pm 07:55 PM
Linux (GNU/Linux の正式名) は、自由に使用および普及できる Unix に似たオペレーティング システムです。これは、POSIX に基づいたマルチユーザー、マルチタスク、マルチスレッド、およびマルチ CPU オペレーティング システムです。 Linux サーバクラスタシステムとは何でしょうか? その主なコンポーネントは何でしょうか? 以下に具体的な内容を紹介します。 Linux サーバー クラスタ システムは、Linux オペレーティング システムをベースとした分散コンピューティング環境であり、複数の独立したサーバー ノードで構成され、これらのノードは高速ネットワークを介して相互に接続され、さまざまなコンピューティング タスクを協調的に実行します。クラスタシステムは高信頼性、高性能、拡張性を備え、安定した強力なサービスサポートをユーザーに提供します。クラスタシステムにより、サーバーを効果的に分割できます。
 PHP マイクロサービスで分散コンテナーとクラスターを実装する方法
Sep 24, 2023 pm 02:28 PM
PHP マイクロサービスで分散コンテナーとクラスターを実装する方法
Sep 24, 2023 pm 02:28 PM
PHP マイクロサービスで分散コンテナーとクラスターを実装する方法 今日のインターネット アプリケーションとシステムの開発では、マイクロサービス アーキテクチャが一般的な設計パターンになっています。マイクロサービス アーキテクチャでは、分散コンテナとクラスタは不可欠なコンポーネントです。この記事では、PHP マイクロサービスで分散コンテナーとクラスターを実装する方法を紹介し、具体的なコード例を示します。 1. 分散コンテナの概念と実装 分散コンテナとは、アプリケーションのさまざまなコンポーネントを異なるサーバーに展開し、ネットワーク通信を通じて連携する方法を指します。存在する