

Redisのデータ構造のジャンプテーブルの詳細説明

次のコラム Redis チュートリアル では、Redis データ構造のジャンプ テーブルについて詳しく説明します。困っている友人の役に立てば幸いです。

まえがき
ジャンプ リストは、ノードにすばやくアクセスするという目的を達成するために、各ノード内の他のノードへの複数のポインタを保持する順序付けされたデータ構造です。このように、理解するのは難しいかもしれませんが、まずリンクされたリストを思い出してください。
1. ジャンプ テーブルを確認する
1.1 ジャンプ テーブルとは
単一リンク リストの場合、必要に応じて、リンク リストに格納されているデータが順序付けされている場合でも、その中の特定のデータを見つけるには、リンクされたリストを最初から最後までたどることしかできません。この方法では、検索効率は非常に低くなり、時間計算量は O(n) と非常に高くなります。
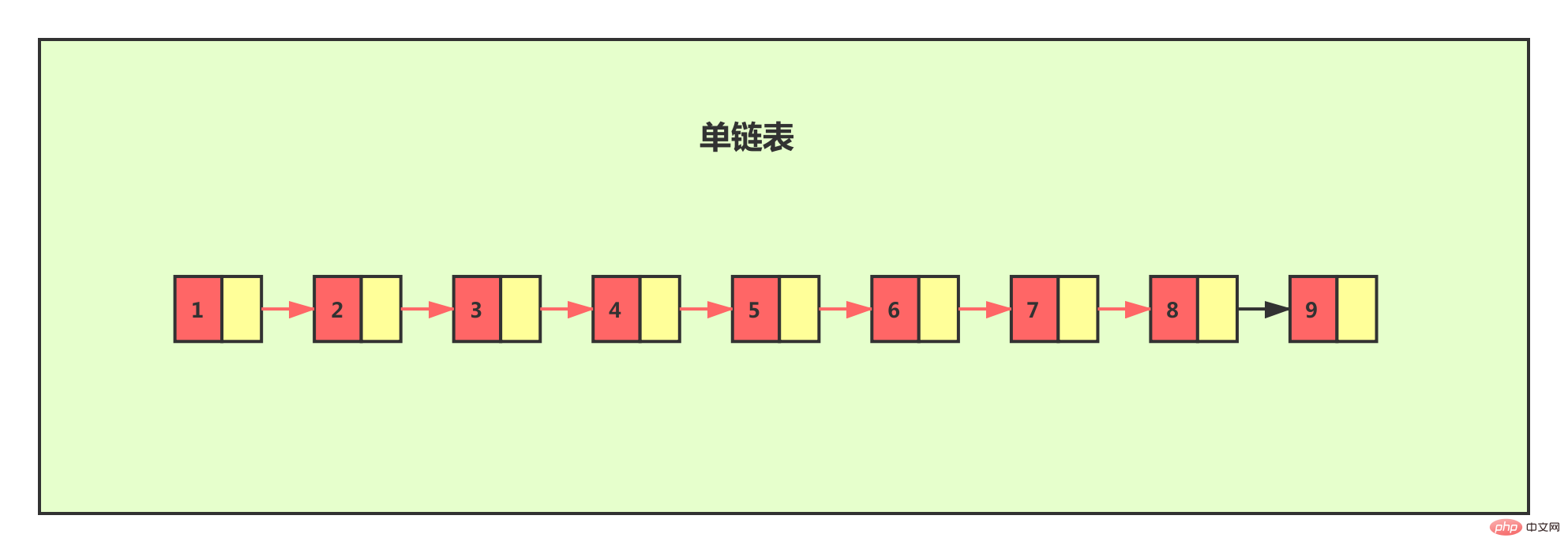
検索効率を向上させたい場合は、リンクされたリストにインデックスを構築することを検討できます。前のレベルまでの 2 つのノードごとに 1 つのノードを抽出し、抽出されたレベルをインデックスと呼びます。 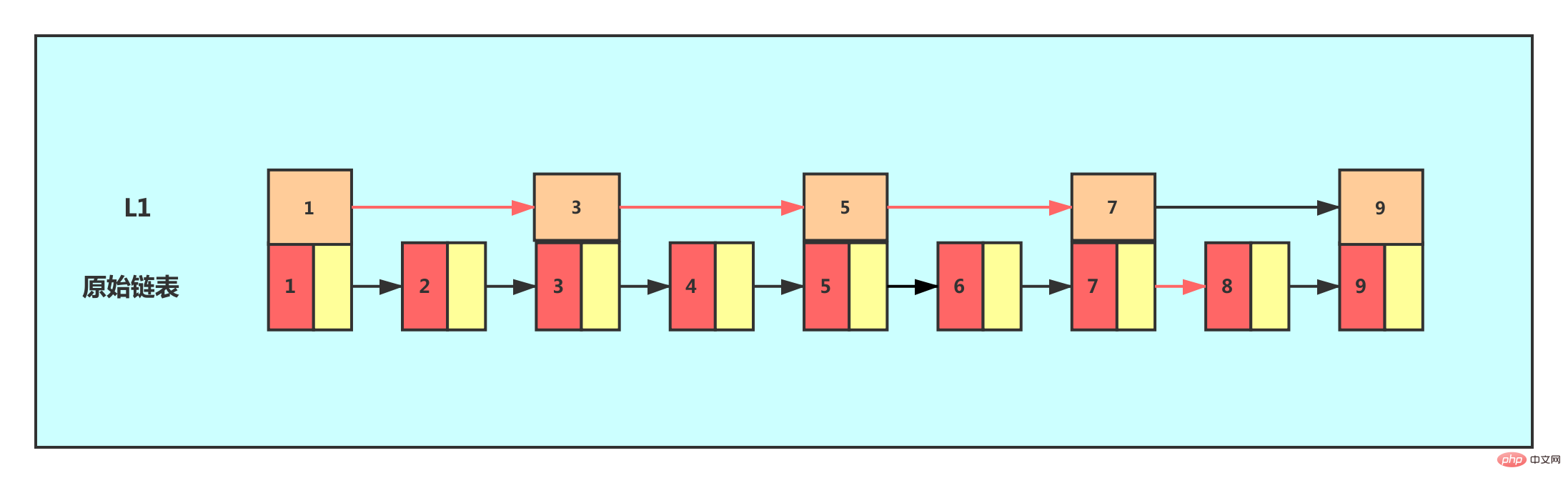
この時点では、ノード 8 を見つけたいと仮定します。最初にインデックス レイヤをトラバースできます。インデックス レイヤの値 7 を持つノードまでトラバースすると、次のことがわかります。次のノードが 9 である場合、検索するノード 8 はこれら 2 つのノードの間にある必要があります。リンク リスト レベルまで降下し、ノード 8 を見つけるためにトラバースを続けました。当初、単一リンク リストでノード 8 を見つけるには 8 つのノードを走査する必要がありましたが、第 1 レベルのインデックスを使用することで、5 つのノードを走査するだけで済みます。
この例から、インデックスのレイヤーを追加した後、ノードを見つけるために通過する必要があるノードの数が減少し、検索効率が向上していることがわかります。 、別のレベルのインデックスを追加します。
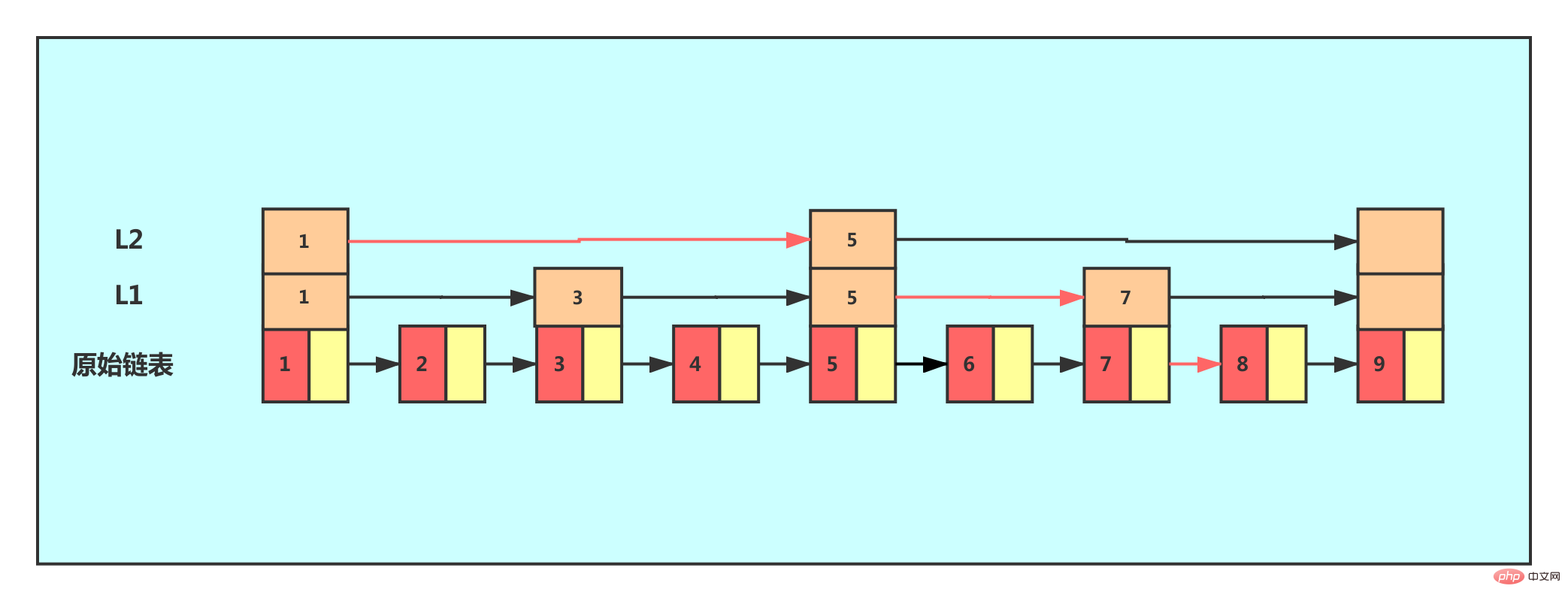
写真を見ると、検索効率が再び向上していることがわかります。この例ではデータが非常に少ないですが、データが大量にある場合は、マルチレベルのインデックスを追加すると、検索効率が大幅に向上します。
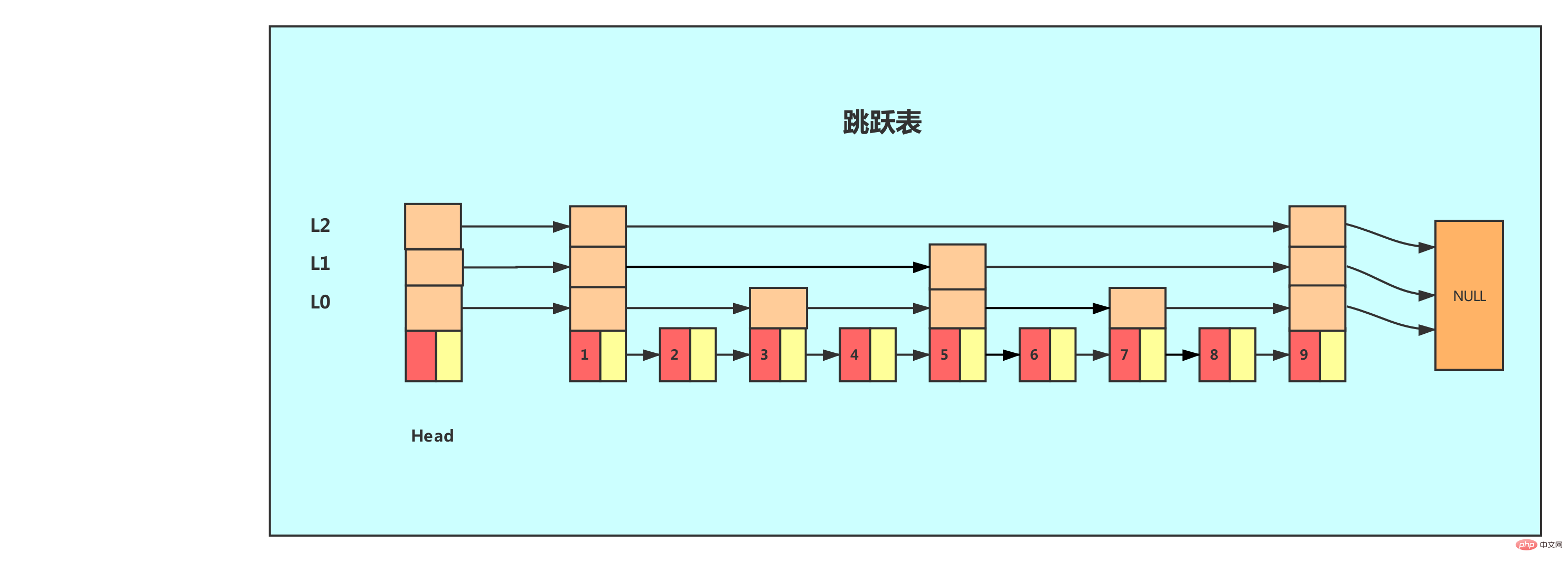
このリンク リストと複数レベルのインデックスのような構造は、ジャンプ リストです。
2. Redis ジャンプ テーブル
Redis は、順序付きセット キーの基礎となる実装の 1 つとしてジャンプ テーブルを使用します。順序付きセットに多数の 要素が含まれる場合、または順序付きセット内の要素の メンバーが比較的長い文字列 である場合、Redis は順序付きセット キーの基礎となる実装としてジャンプ テーブルを使用します。
ここで、疑問について考える必要があります。多数の要素がある場合、またはメンバーが比較的長い文字列である場合、Redis はなぜジャンプ テーブルを使用して実装するのでしょうか?
上記のことから、ジャンプ リストはリンク リストにマルチレベルのインデックスを追加して検索の効率を向上させていることがわかりますが、これは時間に対するスペースを考慮したソリューションであり、必然的に問題 - インデックスはメモリを消費します。元のリンク リストは非常に大きなオブジェクトを格納する場合がありますが、インデックス ノードはキー値といくつかのポインタを格納するだけでよく、オブジェクトを格納する必要がないため、ノード自体が比較的大きい場合や要素数が少ない場合には、比較的大きいため、その利点は必然的に拡大されますが、欠点は無視できます。
2.1 Redis でのスキップ テーブルの実装
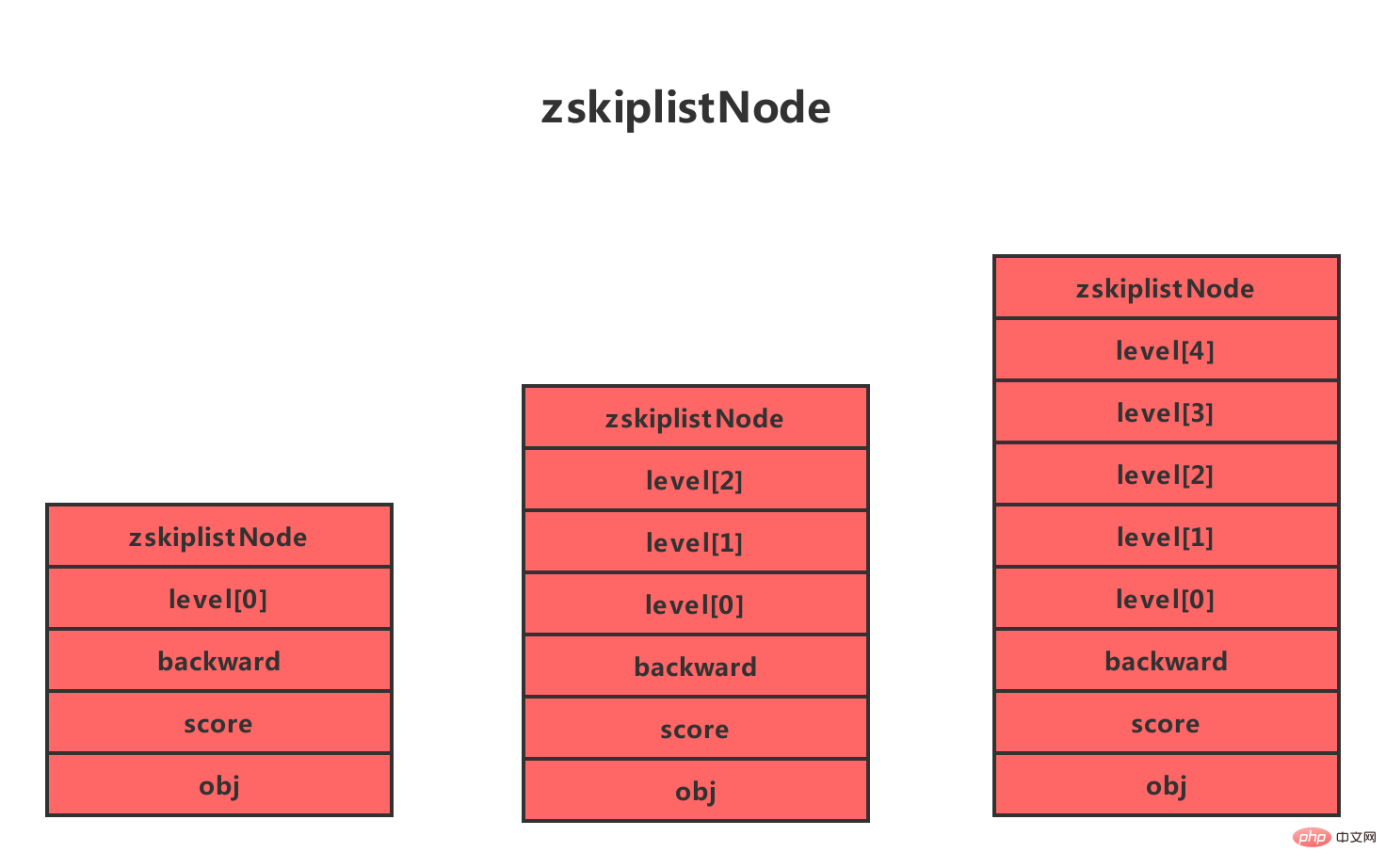
Redis のスキップ テーブルは、Redisのデータ構造のジャンプテーブルの詳細説明 と Skiplist の 2 つの構造体によって定義されます。Redisのデータ構造のジャンプテーブルの詳細説明 構造体はスキップ テーブル ノードを表すために使用され、zskiplist 構造体はジャンプを保存するために使用されます。ノード数、先頭ノードと末尾ノードへのポインタなど、テーブル ノードに関連する情報です。
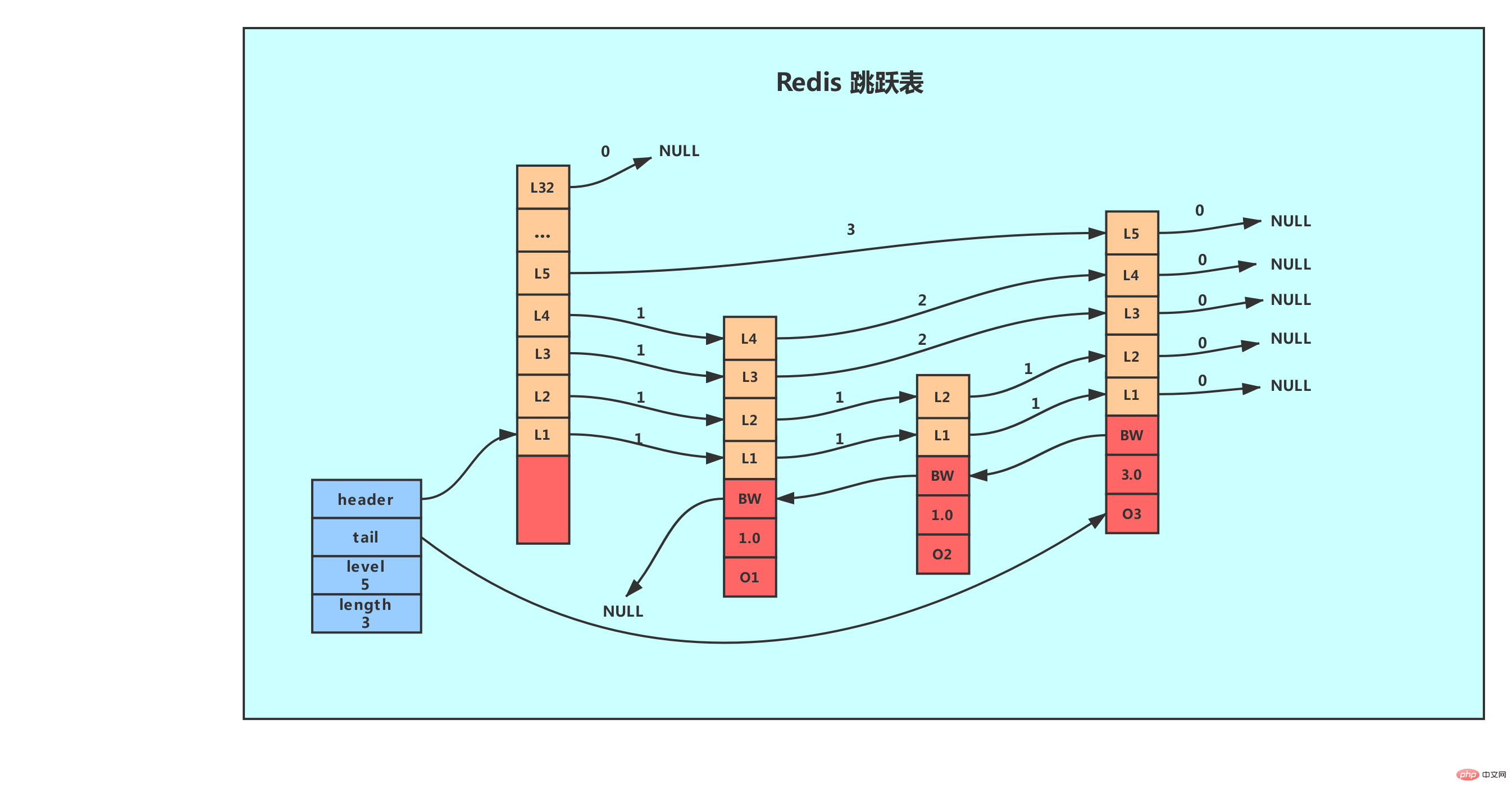
上図はスキップ リストの例を示しており、一番左はスキップリスト構造であり、次の属性が含まれています。
header: ジャンプ テーブルのヘッダー ノードを指します。このポインター プログラムを通じてヘッダー ノードを見つける時間計算量は O(1)
- です。
tail: ジャンプ テーブルの末尾ノードを指します。このポインタ プログラムを通じてテーブルの末尾ノードを見つける時間計算量は O(1)
レベル: レコードです現在のジャンプ テーブル、最大レイヤー数を持つノードのレイヤー数 (ヘッダー ノードのレイヤー数は含まれません)、この属性を通じて、最適なレイヤー高さを持つノードのレイヤー数を決定できます。 O(1) 時間計算量で取得されます。
-
length: ジャンプ テーブルの長さ、つまり、ジャンプ テーブルに現在含まれているノードの数 (ヘッド ノードは含まれません) を記録します。この属性により、プログラムは O( 1) ジャンプ リストの長さを時間計算量で返します。
構造体の右側には 4 つの Redisのデータ構造のジャンプテーブルの詳細説明 構造体があり、次の属性が含まれています。
- ## レベル (レベル): 1、2 を使用します。ノード 、L3 およびその他の単語はノードの各層をマークし、L1 は最初の層を表し、L は 2 番目の層を表します。 各レイヤーには、フォワード ポインターとスパンという 2 つの属性があります。前方ポインタはテーブルの最後にある他のノードにアクセスするために使用され、スパンは前方ポインタが指すノードと現在のノードの間の距離を記録します (スパンが大きいほど、距離は長くなります)。上の図では、接続線上の数字の付いた矢印は前方ポインタを表しており、その数字がスパンです。プログラムがテーブルの先頭からテーブルの末尾まで移動するとき、アクセスはレイヤーの前方ポインタに沿って進行します。 新しいジャンプ テーブル ノードが作成されるたびに、プログラムはべき乗則 (べき乗則、数値が大きいほど発生確率が小さくなります) に基づいてレベルとして 1 ~ 32 の値をランダムに生成します。配列のサイズ。このサイズはレイヤーの「高さ」です。
- 後方ポインタ: ノード内の BW とマークされたノードの後方ポインタは、現在のノードの前のノードを指します。バック ポインタは、プログラムがテーブルの末尾から先頭に移動するときに使用されます。前方ポインタとの違いは、各ノードが後方ポインタを 1 つだけ持つため、一度に 1 ノードしか後方に移動できないことです。
- スコア: 各ノードの 1.0、2.0、および 3.0 は、ノードによって保存されたスコアです。ジャンプ テーブルでは、保存されたスコアに従ってノードが小さいものから大きいものへと配置されます。
- メンバー オブジェクト (oj): 各ノードの o1、o2、および o3 は、ノードによって保存されたメンバー オブジェクトです。同じジャンプ テーブル内では、各ノードによって保存されるメンバー オブジェクトは一意である必要がありますが、複数のノードによって保存されるスコアは同じであってもかまいません。同じスコアを持つノードは、メンバー オブジェクトのサイズに従って辞書順に並べ替えられます。小さいメンバー オブジェクトを持つノードは前 (テーブルの先頭に近い方向) に配置され、大きいメンバー オブジェクトを持つノードは後ろ (テーブルの最後に近い方向) に配置されます。
| 時間計算量 | |
|---|---|
| O(1) | |
| O(N) | |
| 平均 O (logN)、最悪の場合 O(logN) (N はスキップ リストの長さ) | |
| 平均は O(logN)、最悪は O(logN) (N はジャンプ テーブルの長さ) | |
| 平均 O(logN)、最悪 O(logN) (N はジャンプ テーブルの長さ) | |
| 平均 O(logN)、最悪 O(logN) (N はジャンプ リストの長さ) | |
| #O(1) | #スコア範囲を指定すると、この範囲に一致するジャンプ テーブル内の最後のノードを返します |
| スコア範囲を指定します。ただし、この範囲内にあるジャンプ テーブル内のすべてのノードは除きます。範囲 | |
| 指定されたランキングの範囲。ただし、ジャンプ リスト この範囲内のノード | |
| 0 ~ などのスコア範囲 (範囲) を指定します。 15 、 20 ~ 28 など。ジャンプ テーブル内の少なくとも 1 つのノードのスコアがこの範囲内にある場合は 1 が返され、そうでない場合は 0 が返されます。 | |
この記事の焦点
概要ジャンプ テーブルは、私たちにとって少し馴染みのないデータ構造かもしれません。この記事では、ジャンプ テーブルのデータ構造を簡単に紹介し、Redis でのジャンプ テーブルの使用法を分析します。次の記事では、引き続き Redis で使用されるデータ構造の整数コレクションを共有します。乞うご期待!### |
以上がRedisのデータ構造のジャンプテーブルの詳細説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisバージョン番号を表示するには、次の3つの方法を使用できます。(1)情報コマンドを入力し、(2) - versionオプションでサーバーを起動し、(3)構成ファイルを表示します。
 Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない問題を解決するための手順:インストールを確認して、Redisが正しくインストールされていることを確認します。環境変数Redis_hostとredis_portを設定します。 Redis Server Redis-Serverを起動します。サーバーがRedis-Cli pingを実行しているかどうかを確認します。
 Redis Zsetの使用方法
Apr 10, 2025 pm 07:27 PM
Redis Zsetの使用方法
Apr 10, 2025 pm 07:27 PM
Redis Orderedセット(ZSET)は、並べ替えられた要素を保存し、関連するスコアでソートするために使用されます。 zsetを使用する手順には次のものがあります。1。zsetを作成します。 2。メンバーを追加します。 3.メンバースコアを取得します。 4。ランキングを取得します。 5.ランキング範囲のメンバーを取得します。 6.メンバーを削除します。 7.要素の数を取得します。 8。スコア範囲のメンバーの数を取得します。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
