


関連する学習の推奨事項: python チュートリアル
Pandas です。
Pandas の正式名は Python Data Analysis Library で、Numpyに基づく 科学技術コンピューティング ツールです。最大の特徴は構造化データをデータベースの表を操作するのと同じように操作できることであり、多くの複雑で高度な操作をサポートしており、Numpyの強化版とも言えます。 CSV または Excel テーブルから完全なデータを簡単に構築でき、多くのテーブル レベルのバッチ データ計算インターフェイスをサポートします。
pip install pandas复制代码
import pandas as pd复制代码
pip install scipy matplotlib复制代码
まず Series について見てみましょう。Series に保存されるデータには主に 2 つのタイプがあります。1 つはデータのセットで構成される配列で、もう 1 つはこのデータのセットのインデックスまたはラベルです。シリーズを作成し、理解するために印刷するだけです。
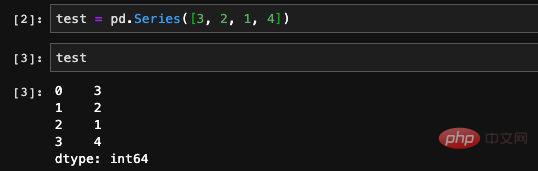 最初の列はそのインデックス
最初の列はそのインデックス 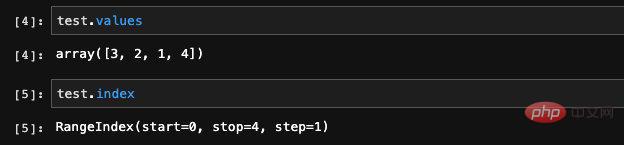
ここで出力される values 出力は Numpy 配列 . 前述したように、pandas は Numpy に基づいて開発された科学計算ライブラリであるため、これは驚くべきことではありません。 Numpy はその基礎となる層です。出力されたインデックス情報から、これが Range タイプのインデックス、その範囲とステップ サイズであることがわかります。
インデックスは Series 構築関数のデフォルト パラメータです。これを入力しない場合は、デフォルトで Range インデックスが生成されます。これは、実際には ## の行番号 です。 # データ。データのインデックスを自分で指定することもできます。たとえば、先ほどのコードにindexパラメータを追加すると、インデックスを自分で指定することができます。

インデックスを配列の添え字として直接使用することもできますが、この 2 つの効果は同じです。それだけでなく、インデックス配列も使用でき、複数のインデックスの値を直接クエリできます。
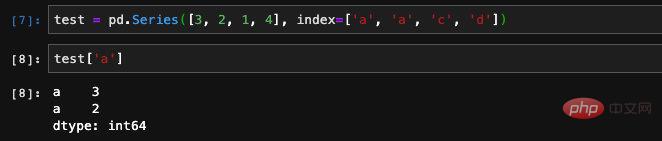
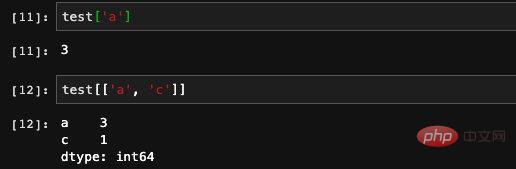 さらに、シリーズを作成するときは、
さらに、シリーズを作成するときは、。同様に、インデックス クエリを使用すると、複数の結果が得られます。

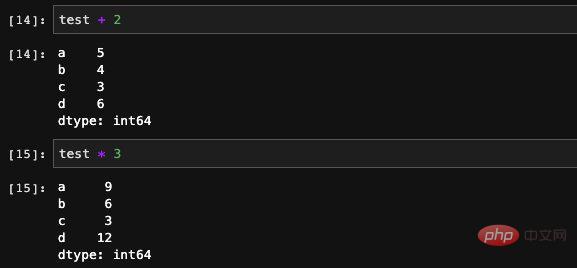
シリーズは多くの種類の計算をサポートしており、
加算、減算、乗算、除算の演算を直接使用できます。シリーズ全体の操作
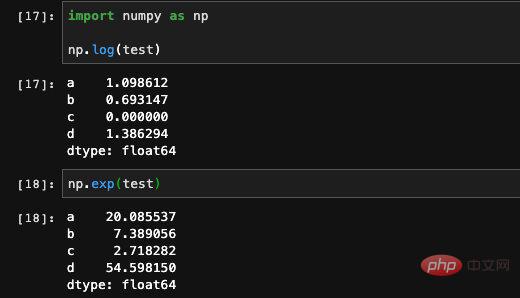
Numpy の演算関数 を使用して複雑な数学演算を実行することもできますが、この計算の結果は Numpy 配列になります。
 #シリーズにはインデックスがあるため、dict
#シリーズにはインデックスがあるため、dict :
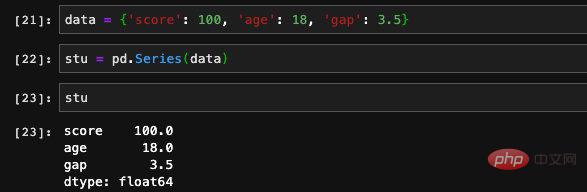
 Series にはインデックスと値があります。実際、ストレージ構造は dict と同じであるため、seires は dict による初期化もサポートしています。 ##これを通して このようにして作成された順序は、辞書にキーが格納される順序になります。作成時に
Series にはインデックスと値があります。実際、ストレージ構造は dict と同じであるため、seires は dict による初期化もサポートしています。 ##これを通して このようにして作成された順序は、辞書にキーが格納される順序になります。作成時に を指定することで、その順序を制御できます。
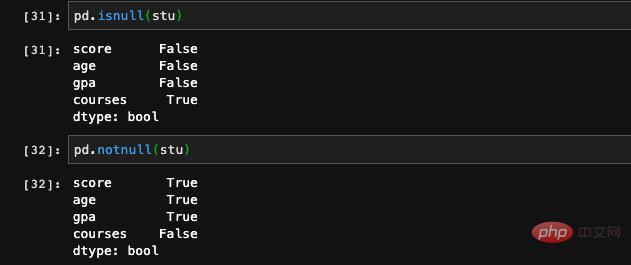
インデックスを指定するときに辞書に現れなかった追加のキーを渡しました。対応する値が辞書内に見つからないため、Series はそれを NAN として記録します(数値ではありません)。これは、不正な値または null 値 として理解できます。特徴やトレーニング データを処理するとき、いくつかのエントリを持つデータの特定の特徴が空白である状況によく遭遇します。パンダを使用できます。isnull と notnull空き状況をチェックする機能。
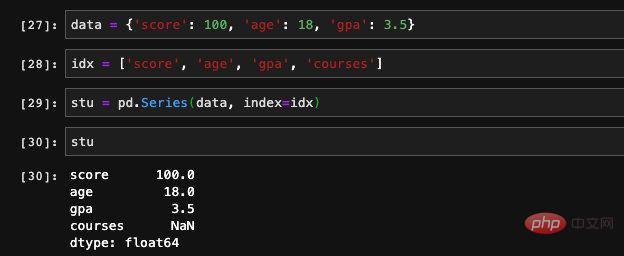
もちろん、Series には isnull 関数もあり、これを呼び出すこともできます。
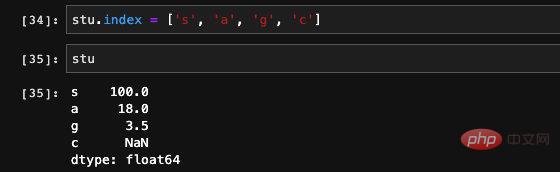
 最後に、シリーズの
最後に、シリーズの 、新しい値を直接割り当てることができます:
レイヤーですNumpy 1 次元配列 のカプセル化を行い、インデックス付けなどの関連関数を追加します。したがって、DataFrame は実際には Series 配列をカプセル化したものであり、さらにデータ処理関連の関数が追加されていると想像できます。核となる構造を理解したら、これらの API を 1 つずつ覚えるよりも、panda の機能全体を理解する方がはるかに役立ちます。
pandas はPython データ処理 に最適なツールです。資格のあるアルゴリズム エンジニアとして、これはほぼ必須の知識です。これは、機械学習や機械学習に Python を使用するための基礎でもあります。深い学習。調査データによると、アルゴリズム エンジニアの日常業務の 70% はデータ処理に費やされており、実際にモデルの実装とトレーニングに使用されているのは 30% 未満です。したがって、データ処理の重要性がわかりますが、業界で開発したい場合は、モデルを学ぶだけでは十分ではありません。 この記事では、組版に mdnice を使用しています
プログラミングについてさらに詳しく知りたい場合は、列に注目してください。
以上がpandasを使った一連のデータ処理の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



