

mysqlのマスター/スレーブ同期とは何ですか?

mysql のマスターとスレーブの同期はバックアップを意味します。マスター ライブラリ (マスター) は、自身のライブラリの書き込みをスレーブ ライブラリ (スレーブ) に同期します。マスター ライブラリで予期しない状況が発生すると、サーバー全体がは利用できませんが、スレーブ データベースにもデータのコピーがあるため、データ損失を引き起こしたり軽減したりすることなく、データを迅速に復元できます。

mysql のマスター/スレーブ同期とは何ですか?
マスター (メイン) ライブラリ内のデータが変更されると、その変更はスレーブ (スレーブ) ライブラリにリアルタイムで同期されます。
データはアプリケーションの重要な部分です。 マスターとスレーブの同期は目的から言えばバックアップの意味もあり、マスターライブラリ(Master)は自身のライブラリへの書き込みを同時にスレーブライブラリ(Slave)に同期させます。マスターライブラリにある 何らかの事情でサーバー全体が使用できなくなった場合でも、スレーブデータベースにもデータのコピーが存在するため、データ損失を発生させたり軽減したりすることなく、迅速にデータを復元できます。
もちろん、これは最初のレベルにすぎません。マスター/スレーブ ライブラリの役割がこれに限定されるのであれば、個人的には 2 つのデータベースに分割する必要はないと考えています。データベースの内容をスナップショットとして定期的に送信する必要がある別のサーバーを使用するか、書き込まれた内容を書き込まれるたびにリアルタイムで別のサーバーに送信できたら便利ではないでしょうか?これにより、リソースが節約されるだけでなく、目的も達成されます。災害復旧とバックアップの役割を果たします。もちろん、マスターとスレーブの同期の役割はこれに限定されるわけではなく、マスターとスレーブの構造を構成したら、通常はスレーブ ノードを単にバックアップ データベースとして機能させることはできません。読み取りと書き込みの分離 (MyCat または他のミドルウェアを使用できます。それについては自分で学ぶことができます。これについては、MyCat に関する次のブログで説明します。少し長くなる可能性があるので、別の記事を書きます)。
実際の環境では、データベースの読み取り操作の数がデータベースの書き込み操作の数よりもはるかに多いため、マスターに書き込み機能のみを提供させ、その後すべての読み取り操作を移動することができます。スレーブ データベースへの接続です。これは通常、読み取りと書き込みの分離について話します。これにより、マスターへの負担が軽減されるだけでなく、災害復旧のバックアップも提供され、一石二鳥になります。
マスター/スレーブ同期の利点は何ですか?- データベースの負荷容量を水平方向に拡張します。 #フォールト トレランス、高可用性。フェイルオーバー/高可用性
- データのバックアップ。
- MySQL マスター/スレーブ同期の原理
マスター/スレーブ同期の概念について説明した後、マスター/スレーブ同期の原理について説明します。原理も非常にシンプルで、Redis はありません。クラスターには非常に多くの概念があります。
実際、MySQL でマスター/スレーブを構成した後、マスター ノードで書き込み操作を実行する限り、この操作は MySQL のバイナリログ (bin-log) ログに保存されます。スレーブがマスターに接続すると、マスター マシンはスレーブのバイナリ ログ ダンプ スレッドを開きます。マスターのバイナリログが変更されると、マスターのダンプ スレッドはスレーブに通知し、対応するバイナリログの内容をスレーブに送信します。マスターとスレーブの同期がオンになると、スレーブ ノードは I/O スレッドと SQL スレッドの 2 つのスレッドを作成しますが、これはその後の構築で確認できます。
- I/0 スレッド:
このスレッドはマスター マシンにリンクされています。マスター マシンのバイナリログがスレーブに送信されると、IO スレッドは次のように書き込みます。リレーログ内のログコンテンツをローカルに保存します。
- SQL スレッド:
このスレッドは、リレー ログの内容を読み取り、リレー ログの内容に基づいてスレーブ データベース上で対応する操作を実行します。
- 考えられる問題:
書き込みリクエストが多い場合、ログ転送処理によりスレーブデータとマスターデータの不整合が発生する場合があります。これは、システムの短い遅延、多数の書き込みコマンド、またはシステム速度の不一致によって発生します。
これは MySQL のマスター/スレーブ同期の原理の大まかですが、実際に役割を果たすのは、実際にはこれら 2 つのログ ファイル、binlog とリレー ログです。
 MySQL マスタースレーブ同期を手動で構築する
MySQL マスタースレーブ同期を手動で構築する
環境準備
今回マスタースレーブ同期を設定する環境:CentOS 7 、MySQL 8.0.18 (バイナリ パッケージを使用してインストール)。
シナリオ紹介
今回は、1 つのマスターと 2 つのスレーブを使用して、MySQL のマスター/スレーブ同期を構築します。
Master:IP :192.168.43.201 Port:3306 Slave1:IP:192.168.43.202 Port:3306 Slave2:IP:192.168.43.203 Port:3306
ビルドの開始
構成ファイルを変更する
MySQL をインストールすると、/etc/ ディレクトリに my.cnf ファイルが作成されます。ファイルを開いて追加します。次のコンテンツ (変更する前にバックアップを作成することを忘れないでください):
#xx#该配置为Master的配置 server-id=201 #Server id 每台MySQL的必须不同 log-bin=/var/lib/mysql/mysql-bin.log #代表开启binlog日志 expire_logs_days=10 #日志过期时间 max_binlog_size=200M #日志最大容量 binlog_ignore_db=mysql #忽略mysql库,表示不同步此库
#该配置为Slave的配置,第二台Slave也是这么配置,不过要修改一下server-id server-id=202 expire_logs_days=10 #日志的缓存时间 max_binlog_size=200M #日志的最大大小 replicate_ignore_db=mysql #忽略同步的数据库
ユーザー '123456' で識別されるユーザー 'スレーブ'@'%' を作成;
新しく作成されたノードに権限を与えるuser: grant replication smile on '*.*' to 'Slave'@'%';
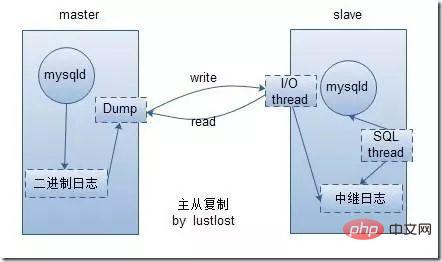
マスターノードのステータスを確認
配置两个Slave节点
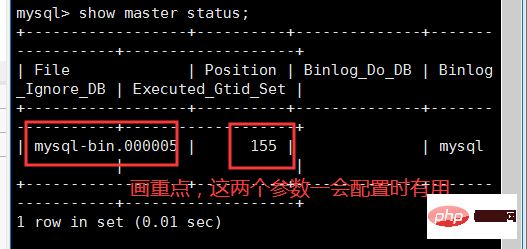
打开两个Slave节点客户端,在我们的另外两个Slave节点中输入如下命令:
change master to master_user='Slave',master_password='123456',master_host='192.168.43.201',master_log_file='mysql-bin.000005',master_log_pos=155,get_master_public_key=1; #注意,这里的master_log_file,就是binlog的文件名,输入上图中的mysql-bin.000005,每个人的都可能不一样。 #注意,这里的master_log_pos是binlog偏移量,输入上图中的155,每个人的都可能不一样。
配置完成后,输入start slave;开启从节点,然后输入show slave status\G;查看从节点状态
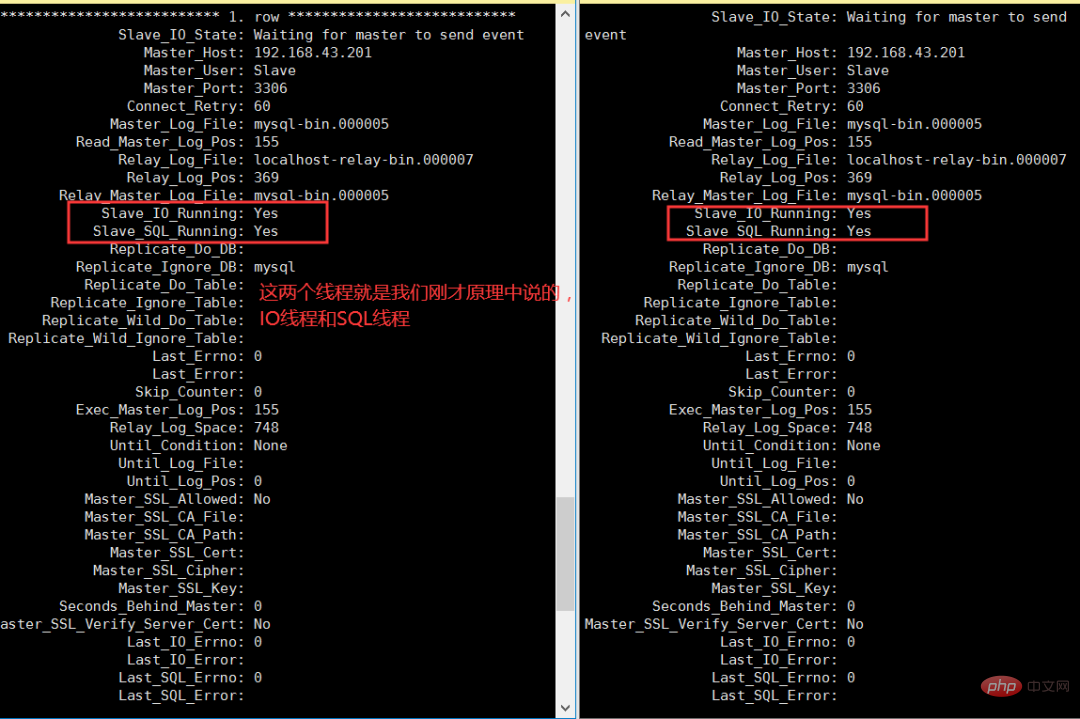
可以看到,在两台Slave的状态中,我们能亲眼看到IO线程和SQL线程的运行状态,这两个线程必须都是yes,才算配置搭建完成。
搭建完成
通过上述步骤,就完成了MySQL主从同步的搭建,相对Redis而言MySQL配置相当简单。下面我们可以进行测试。
先看看三个MySQL的数据库状态:SHOW DATABASES;

可以看到现在数据库都是初始默认状态,没有任何额外的库。
在Master节点中创建一个数据库,库名可以自己设置。
CREATE DATABASE testcluster;
<img class="has lazy" src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/024/fefa55750f9a4ddaec29168c6cc022e9-4.png" alt="">
可以看到,在Slave中也出现了Master中创建的数据库,说明我们的配置没有问题,主从搭建成功。这里就不再创建表了,大家可以自己试试,创建表再往表中插入数据,也是没有任何问题的。
注意事项
如果出现IO线程一直在Connecting状态,可以看看是不是三台机器无法相互连接,如果可以相互连接,那么有可能是Slave账号密码写错了,重新关闭Slave然后输入上面的配置命令再打开Slave即可。
如果出现SQL线程为NO状态,那么有可能是从数据库和主数据库的数据不一致造成的,或者事务回滚,如果是后者,先关闭Slave,然后先查看master的binlog和position,然后输入配置命令,再输入set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;,再重新start slave;即可,如通过是前者,那么就排查一下是不是存在哪张表没有被同步,是否存在主库存在而从库不存在的表,自己同步一下再重新配置一遍即可。
结语
在写这篇文章之前自己也被一些计算机领域的“名词”吓到过,相信有不少同学都有一样的体会,碰上某些高大上的名词总是先被吓到,例如像“分布式”、“集群”等等等等,甚至在没接触过nginx之前,连”负载均衡“、”反向代理“这样的词都让人觉得,这么高达上的词,肯定很难吧,但其实自己了解了nginx、ribbon等之后才发现,其实也就那么回事吧,没有想象中的那么难。
所以写这篇文章的初衷是想让大家对集群化或者分布式或者其他的一些技术或者解决方案不要有一种望而却步的感觉(感觉计算机领域的词都有这么一种特点,词汇高大上,但是其实思想是比较好理解的),其实自己手动配置出一个简单的集群并没有那么难。
如果学会docker之后再来配置就更加简单了,但是更希望不要只局限于会配置,配置出来的东西只能说你会配置了,但是在这层配置底下是前人做了相当多的工作,才能使我们通过简单配置就能实现一些功能,应该要深入底层,了解配置下面的工作原理,这个才是最重要的,也是体现一个程序员水平的地方。
推荐教程:mysql视频教程
以上がmysqlのマスター/スレーブ同期とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7642
7642
 15
1392
52
91
11
33
150
15
1392
52
91
11
33
150

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redis ExporterサービスでRedis Dropletを監視します
Apr 10, 2025 pm 01:36 PM
Redisデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Redis Exporter Serviceは、Prometheusを使用してRedisデータベースを監視するために設計された強力なユーティリティです。 このチュートリアルでは、Redis Exporterサービスの完全なセットアップと構成をガイドし、監視ソリューションをシームレスに構築します。このチュートリアルを研究することにより、完全に動作する監視設定を実現します
 SQLデータベースエラーを表示する方法
Apr 10, 2025 pm 12:09 PM
SQLデータベースエラーを表示する方法
Apr 10, 2025 pm 12:09 PM
SQLデータベースエラーを表示する方法は次のとおりです。1。エラーメッセージを直接表示します。 2。エラーを表示し、警告コマンドを表示します。 3.エラーログにアクセスします。 4.エラーコードを使用して、エラーの原因を見つけます。 5.データベース接続とクエリ構文を確認します。 6.デバッグツールを使用します。
