

JavaScript 列開発者として、JavaScript エンジンがどのように動作するかを深く理解することは、コードのパフォーマンス特性を理解するのに役立ちます。この記事では、V8 だけでなく、すべての JavaScript エンジンに共通するいくつかの重要な基本について説明します。
すべては、作成する JavaScript コードから始まります。 JavaScript エンジンはソース コードを解析し、抽象構文ツリー (AST) に変換します。 AST に基づいて、インタプリタが動作を開始し、バイトコードを生成できます。この時点で、エンジンは実際に JavaScript コードの実行を開始します。 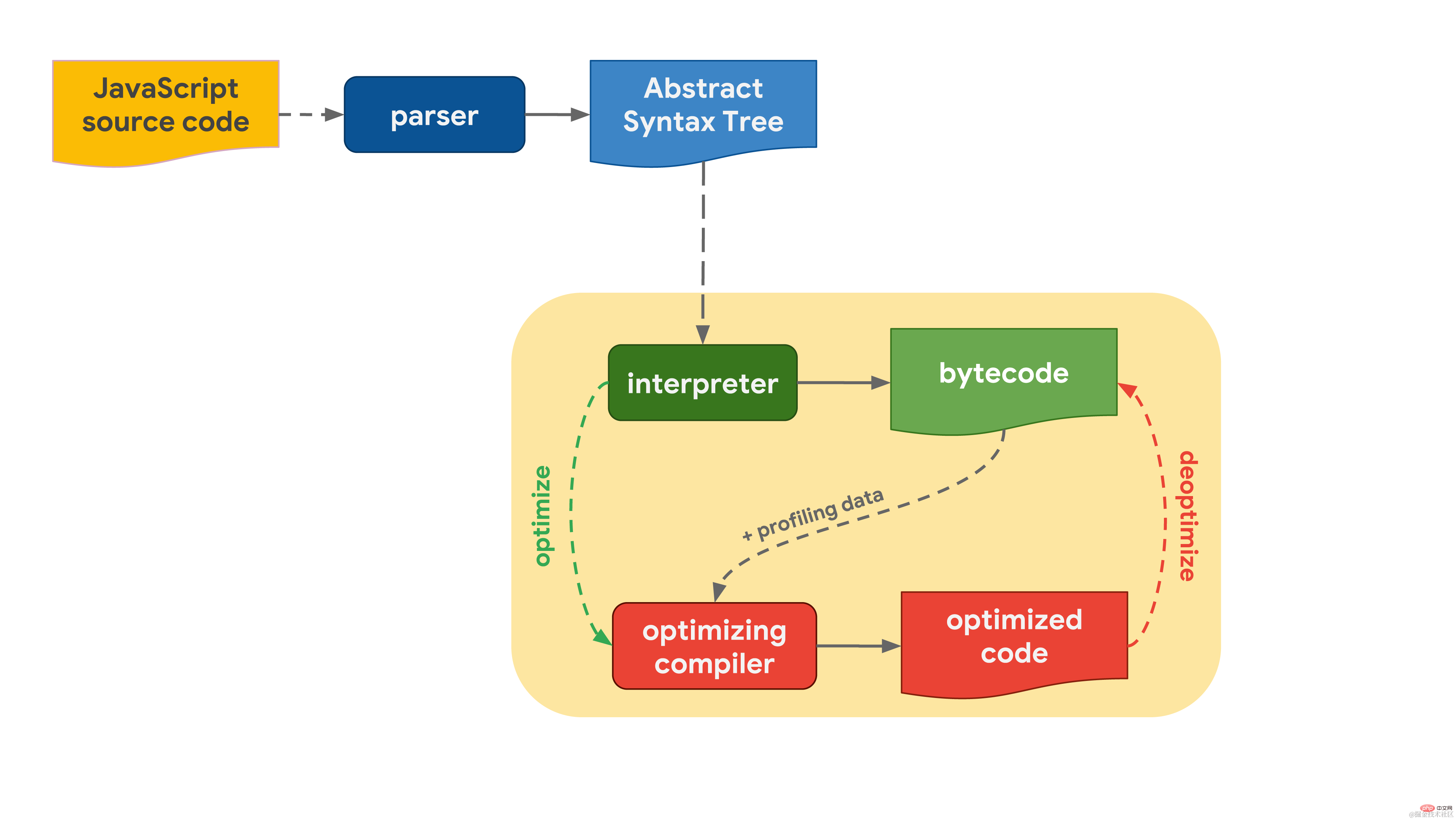 実行を高速化するために、バイトコードをプロファイリング データとともに最適化コンパイラーに送信できます。最適化コンパイラーは、利用可能なプロファイリング データに基づいて特定の仮定を立て、高度に最適化されたマシン コードを生成します。
実行を高速化するために、バイトコードをプロファイリング データとともに最適化コンパイラーに送信できます。最適化コンパイラーは、利用可能なプロファイリング データに基づいて特定の仮定を立て、高度に最適化されたマシン コードを生成します。
ある時点で仮定が間違っていることが判明した場合、最適化コンパイラは最適化をキャンセルし、インタプリタ段階に戻ります。
ここでは、実際に JavaScript コードを実行するプロセスの部分、つまりコードが解釈され最適化される部分を見て説明します。主要な JavaScript エンジンにはいくつかの違いがあります。
一般的に、JavaScript エンジンにはインタプリタと最適化コンパイラを含む処理フローがあります。このうち、インタプリタは最適化されていないバイトコードを迅速に生成できますが、最適化コンパイラは時間はかかりますが、最終的には高度に最適化されたマシンコードを生成できます。 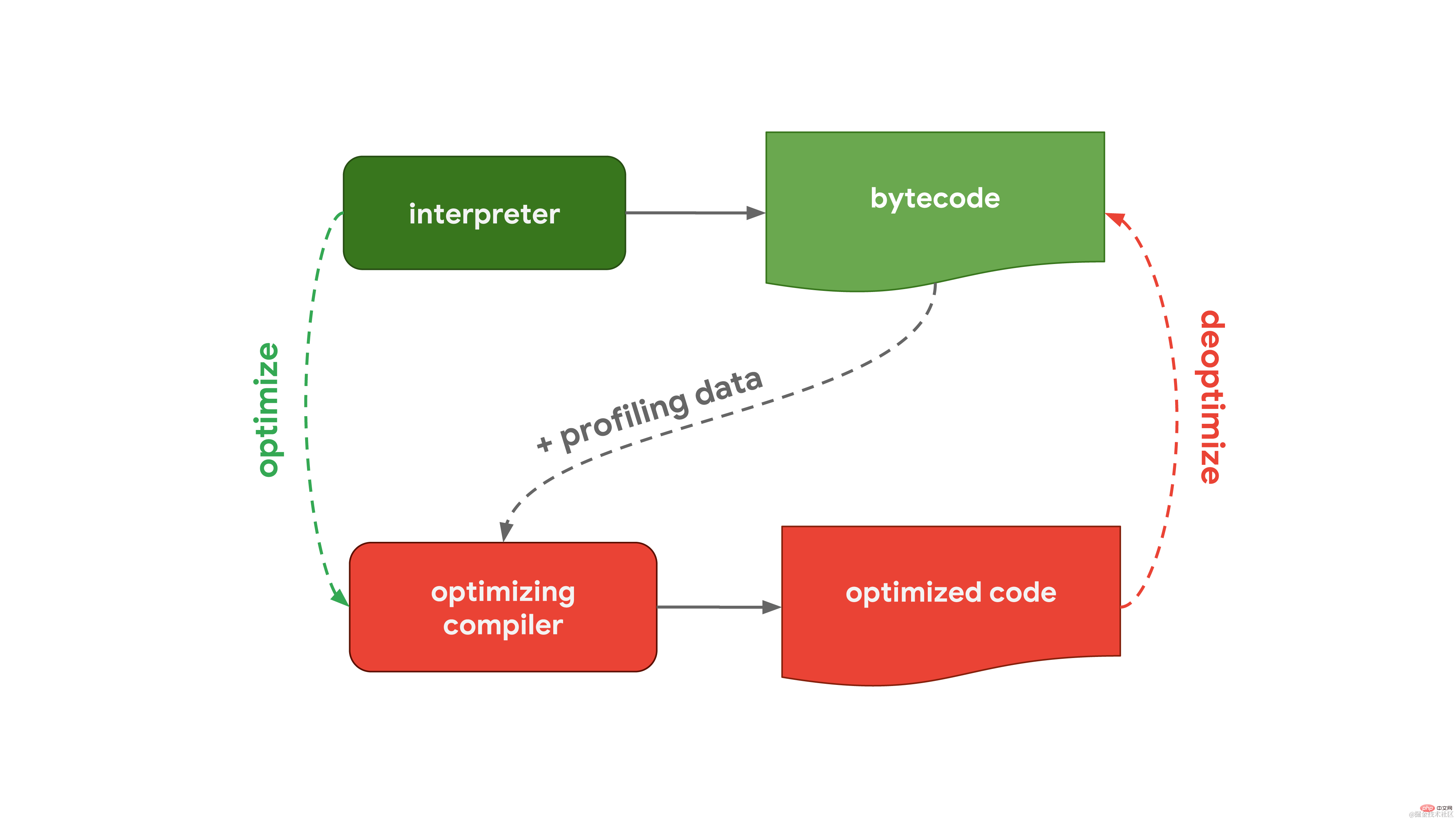 この一般的なプロセスは、Chrome および Node.js で使用される Javascript エンジンである V8 のワークフローとほぼ同じです。
この一般的なプロセスは、Chrome および Node.js で使用される Javascript エンジンである V8 のワークフローとほぼ同じです。 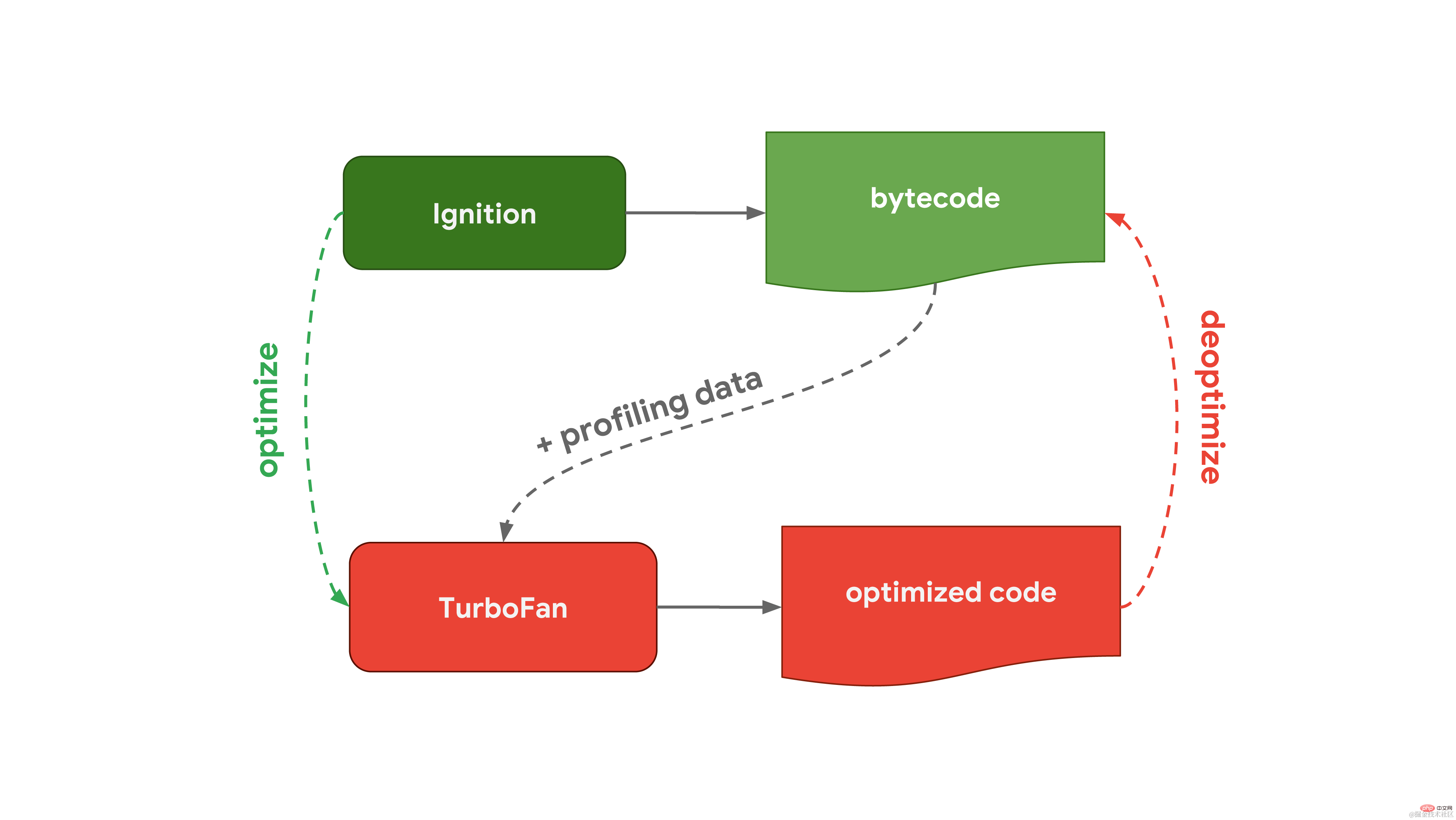 V8 のインタープリターは Ignition と呼ばれ、バイトコードの生成と実行を担当します。バイトコードを実行すると、後でコードの実行を高速化するために使用できるプロファイリング データが収集されます。関数が頻繁に実行される場合など、関数がホットになると、生成されたバイトコードとプロファイリング データが最適化コンパイラーである Turbofan に渡され、プロファイリング データに基づいて高度に最適化されたマシン コードが生成されます。
V8 のインタープリターは Ignition と呼ばれ、バイトコードの生成と実行を担当します。バイトコードを実行すると、後でコードの実行を高速化するために使用できるプロファイリング データが収集されます。関数が頻繁に実行される場合など、関数がホットになると、生成されたバイトコードとプロファイリング データが最適化コンパイラーである Turbofan に渡され、プロファイリング データに基づいて高度に最適化されたマシン コードが生成されます。 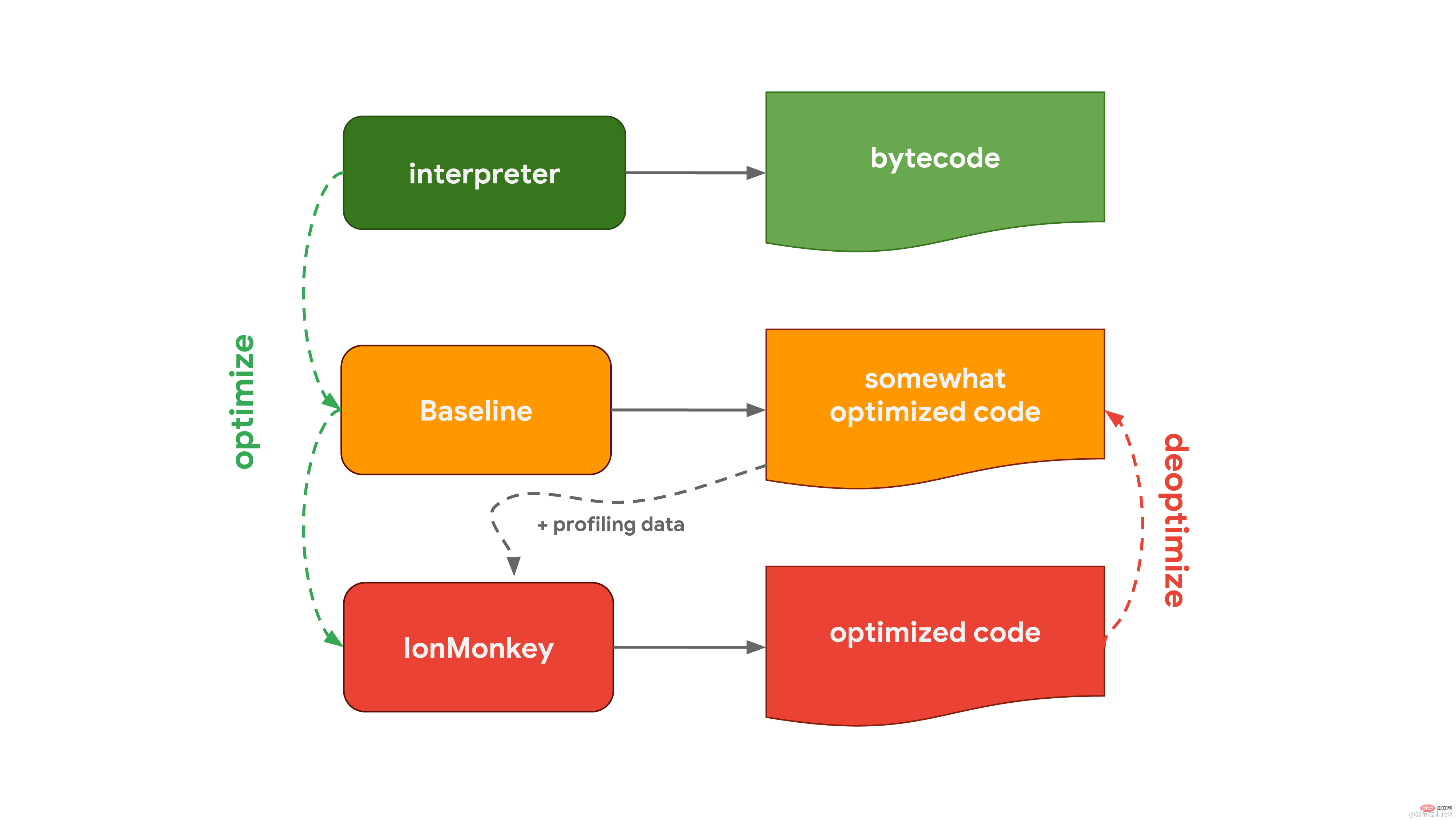 SpiderMonkey は、Mozilla が Firefox と Spidernode で使用する JavaScript エンジンです。最適化コンパイラは 1 つではなく 2 つあります。インタプリタはまずベースライン コンパイラを通過して、最適化されたコードを生成します。次に、コードの実行中に収集されたプロファイリング データと組み合わせることで、IonMonkey コンパイラーはより高度に最適化されたコードを生成できます。最適化の試行が失敗した場合、IonMonkey はベースライン段階のコードに戻ります。
SpiderMonkey は、Mozilla が Firefox と Spidernode で使用する JavaScript エンジンです。最適化コンパイラは 1 つではなく 2 つあります。インタプリタはまずベースライン コンパイラを通過して、最適化されたコードを生成します。次に、コードの実行中に収集されたプロファイリング データと組み合わせることで、IonMonkey コンパイラーはより高度に最適化されたコードを生成できます。最適化の試行が失敗した場合、IonMonkey はベースライン段階のコードに戻ります。
Edge で使用される Microsoft の JavaScript エンジンである Chakra は非常によく似ており、2 つの最適化コンパイラーも備えています。インタプリタはコードを SimpleJIT (JIT は Just-In-Time コンパイラ、ジャストインタイム コンパイラの略) に最適化し、わずかに最適化されたコードを生成します。 FullJIT は分析データを結合して、より最適化されたコードを生成します。 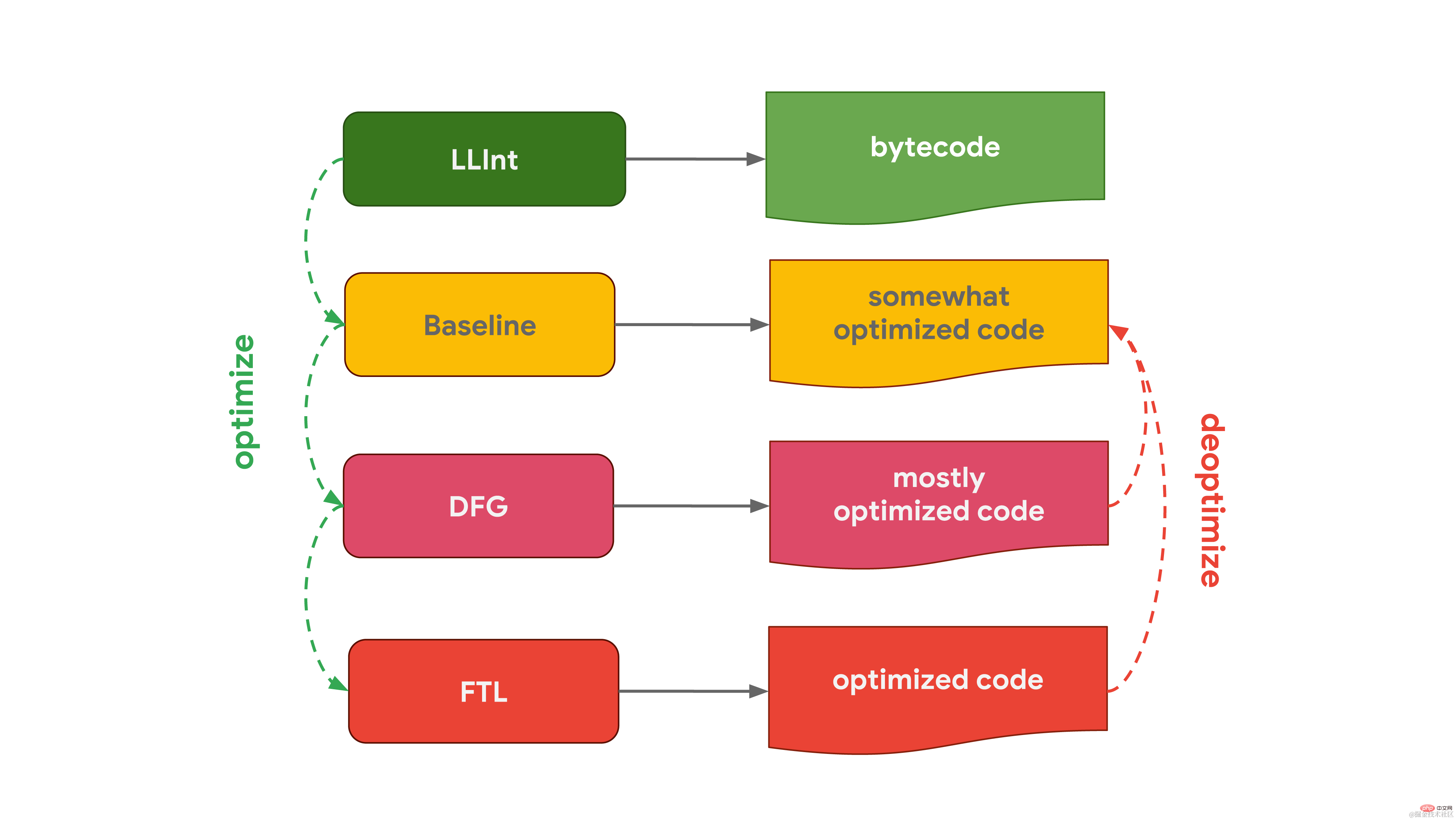 JavaScriptCore (JSC と略称) は、Safari と React Native で使用される Apple の JavaScript エンジンで、3 つの異なる最適化コンパイラーを使用して極限まで機能します。低レベル インタプリタ LInt はコードをベースライン コンパイラに最適化し、次にコードを DFG (データ フロー グラフ) コンパイラに最適化します。DFG (データ フロー グラフ) コンパイラは、最適化されたコードを FTL (Faster Than Light) に渡すことができます。 ) コンパイル用に容器に入れます。
JavaScriptCore (JSC と略称) は、Safari と React Native で使用される Apple の JavaScript エンジンで、3 つの異なる最適化コンパイラーを使用して極限まで機能します。低レベル インタプリタ LInt はコードをベースライン コンパイラに最適化し、次にコードを DFG (データ フロー グラフ) コンパイラに最適化します。DFG (データ フロー グラフ) コンパイラは、最適化されたコードを FTL (Faster Than Light) に渡すことができます。 ) コンパイル用に容器に入れます。
一部のエンジンには、より最適化されたコンパイラが搭載されているのはなぜですか?メリットとデメリットを天秤にかけた結果です。インタプリタはバイトコードを迅速に生成できますが、バイトコードは一般にあまり効率的ではありません。一方、コンパイラーの最適化には時間がかかりますが、最終的にはより効率的なマシンコードが生成されます。コードを迅速に実行する (インタープリター) か、より長い時間はかかりますが、最終的には最適なパフォーマンスでコードを実行する (コンパイラーの最適化) か、の間にはトレードオフがあります。一部のエンジンでは、異なる時間/効率特性を持つ複数の最適化コンパイラーを追加することを選択し、複雑さが増しますが、これらのトレードオフをよりきめ細かく制御できるようになります。考慮する必要があるもう 1 つの側面はメモリ使用量に関連しており、これについては後ほど専用の記事で詳しく説明します。
各 JavaScript エンジンのインタープリターとコンパイラー プロセスの最適化における主な違いを強調しました。これらの違いは別として、高レベルでは、すべての JavaScript エンジンは同じアーキテクチャを持っています。つまり、パーサーと、ある種のインタープリター/コンパイラー フローがあります。
実装のいくつかの側面に焦点を当てて、JavaScript エンジンの共通点を見てみましょう。
たとえば、JavaScript エンジンは JavaScript オブジェクト モデルをどのように実装し、JavaScript オブジェクトのプロパティへのアクセスを高速化するためにどのような手法を使用するのでしょうか?現時点では、すべての主要なエンジンが同様の実装をしていることがわかりました。
ECMAScript 仕様では、基本的にすべてのオブジェクトを、プロパティにマップされた文字列キーを持つ辞書として定義します。
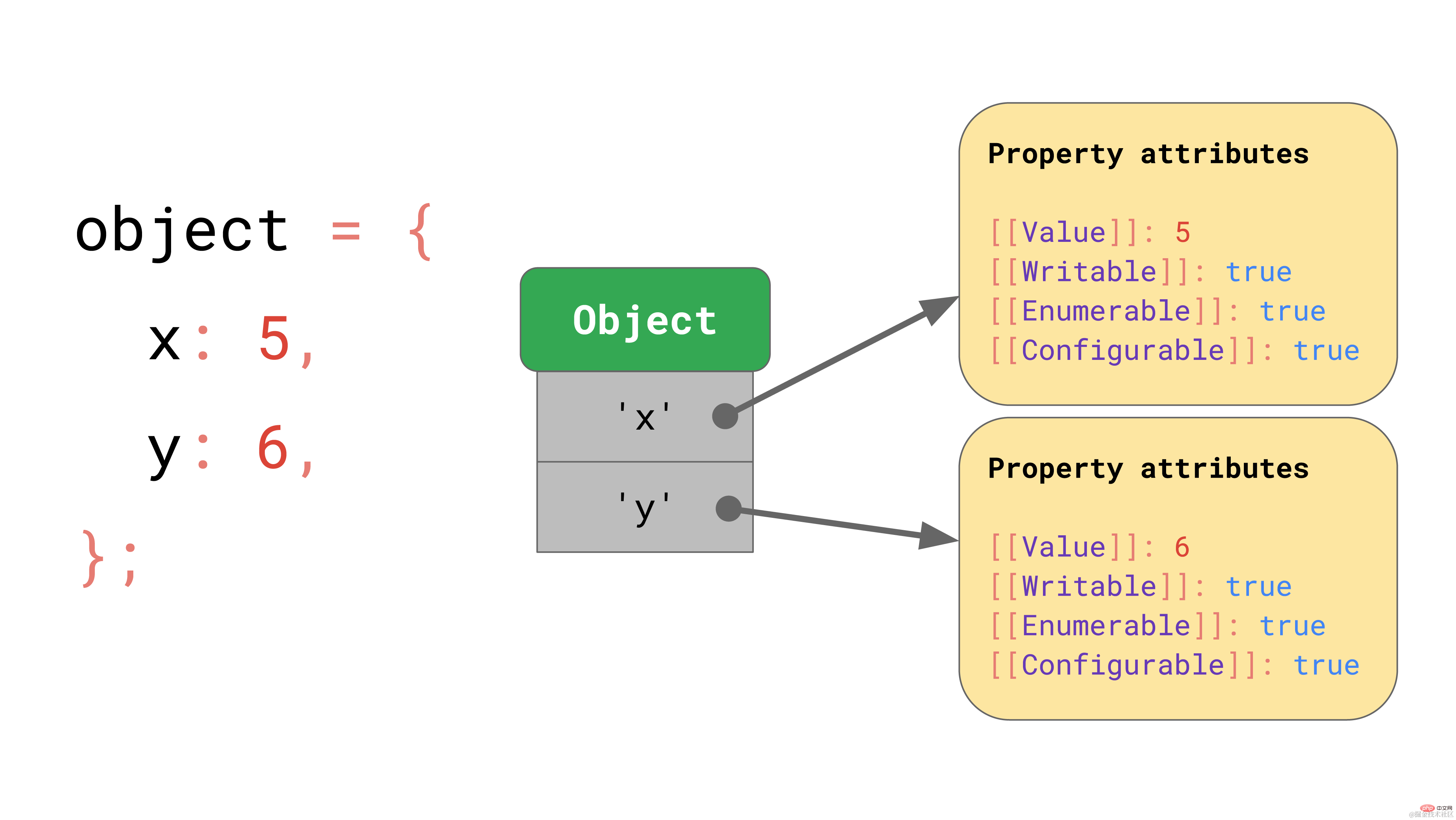 [[Value]] 自体に加えて、仕様では次のプロパティも定義します。
[[Value]] 自体に加えて、仕様では次のプロパティも定義します。
[[角括弧]] の表記は少し変わっていますが、仕様では JavaScript に直接公開できないプロパティをこのように定義しています。 JavaScript では、引き続き Object.getOwnPropertyDescriptor API を使用して、指定したオブジェクトのプロパティ値を取得できます。
const object = { foo: 42 };Object.getOwnPropertyDescriptor(object, 'foo');// → { value: 42, writable: true, enumerable: true, configurable: true }复制代码これは、JavaScript がオブジェクトを定義する方法ですが、配列はどうなるでしょうか?
配列は特別なオブジェクトと考えることができます。違いの 1 つは、配列が配列インデックスに対して特別な処理を実行することです。ここでの配列インデックス付けは、ECMAScript 仕様の特別な用語です。 JavaScript では、配列は要素数が最大 23²−1 に制限されており、配列インデックスはその範囲内の任意の有効なインデックス、つまり 0 から 23²−2 までの任意の整数です。
もう 1 つの違いは、配列には特別な長さのプロパティがあることです。
const array = ['a', 'b']; array.length; // → 2array[2] = 'c'; array.length; // → 3复制代码
この例では、長さ 2 の配列が作成されます。別の要素をインデックス 2 に割り当てると、長さは自動的に更新されます。
JavaScript は、オブジェクトと同様の方法で配列を定義します。たとえば、配列インデックスを含むすべてのキー値は、文字列として明示的に表されます。配列の最初の要素はキー値「0」の下に格納されます。 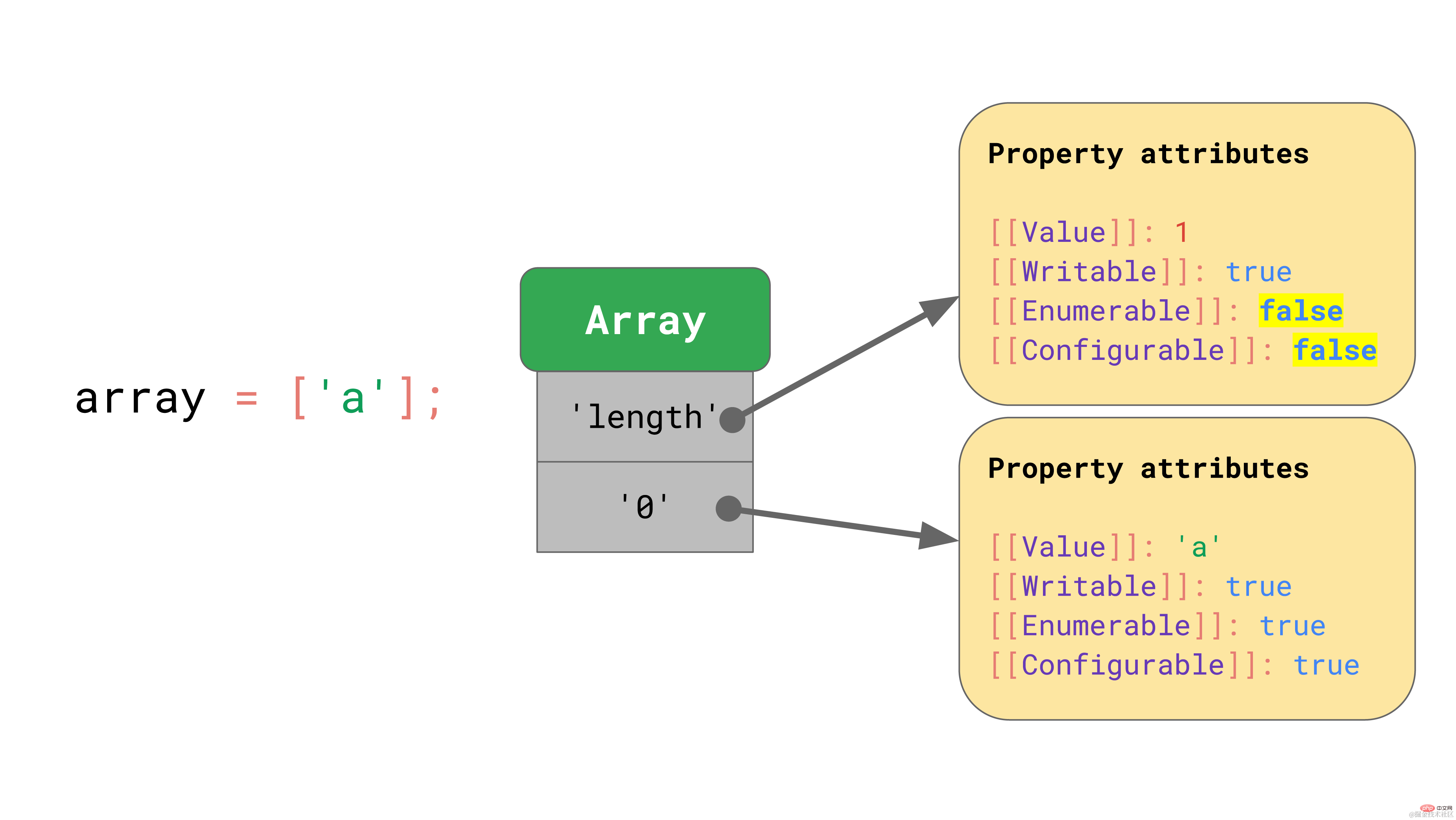 「長さ」プロパティも、列挙不可能で構成不可能なプロパティです。
要素が配列に追加されると、JavaScript は「length」プロパティの [[value]] プロパティを自動的に更新します。
「長さ」プロパティも、列挙不可能で構成不可能なプロパティです。
要素が配列に追加されると、JavaScript は「length」プロパティの [[value]] プロパティを自動的に更新します。 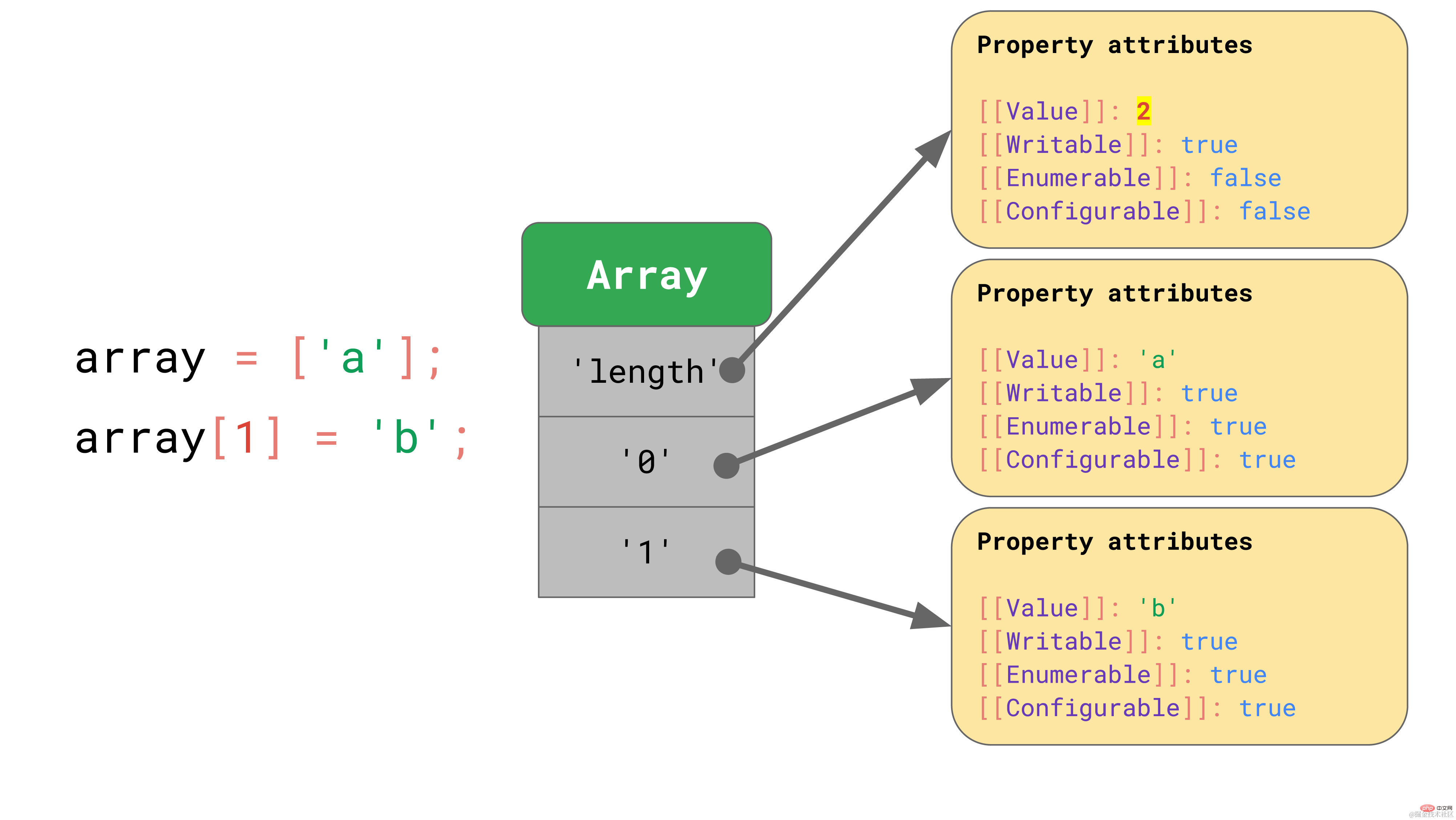
JavaScript でオブジェクトがどのように定義されるかがわかったので、JavaScript エンジンがオブジェクトを効率的に使用する方法を詳しく見てみましょう。 全体として、プロパティへのアクセスは、JavaScript プログラムで最も一般的な操作です。したがって、JavaScript エンジンがプロパティに迅速にアクセスできることが重要です。
JavaScript プログラムでは、複数のオブジェクトが同じキーと値のプロパティを持つことがよくあります。これらの物体は同じ形をしていると言えます。
const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };// object1 and object2 have the same shape.复制代码同じ形状を持つオブジェクトの同じプロパティにアクセスすることも非常に一般的です:
function logX(object) { console.log(object.x);
}const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);复制代码これを念頭に置いて、JavaScript エンジンはオブジェクトの形状に基づいてオブジェクト プロパティへのアクセスを最適化できます。以下にその原理を紹介します。
先ほど説明した辞書データ構造を使用するプロパティ x と y を持つオブジェクトがあるとします。オブジェクトには、それぞれのプロパティ値を指す文字列形式のキーが含まれています。 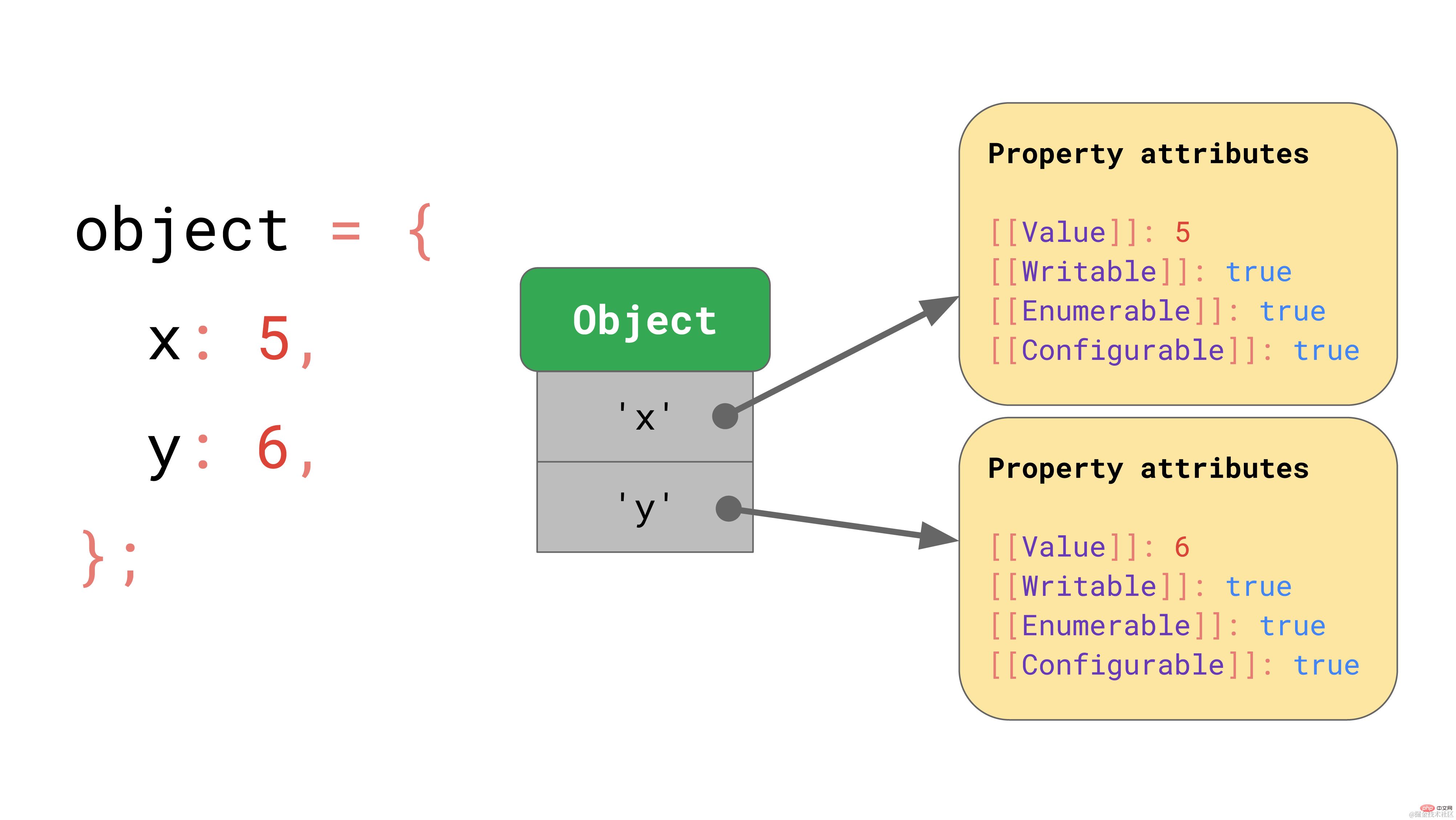
object.y などのプロパティにアクセスすると、JavaScript エンジンは JSObject 内のキー値 'y' を検索し、対応するプロパティ値をロードして、最後に [[Value] を返します。 ]]。
しかし、これらの属性値はメモリのどこに保存されるのでしょうか?それらを JSObject の一部として保存する必要がありますか?後で同じ形状のさらに多くのオブジェクトに遭遇すると仮定すると、プロパティ名とプロパティ値を含む完全な辞書を JSObject 自体に格納することは無駄です。なぜなら、プロパティ名は同じ形状を持つすべてのオブジェクトに対して繰り返されるからです。これは重複が多く、不必要なメモリ使用量が多くなります。最適化として、エンジンはオブジェクトのシェイプを個別に保存します。 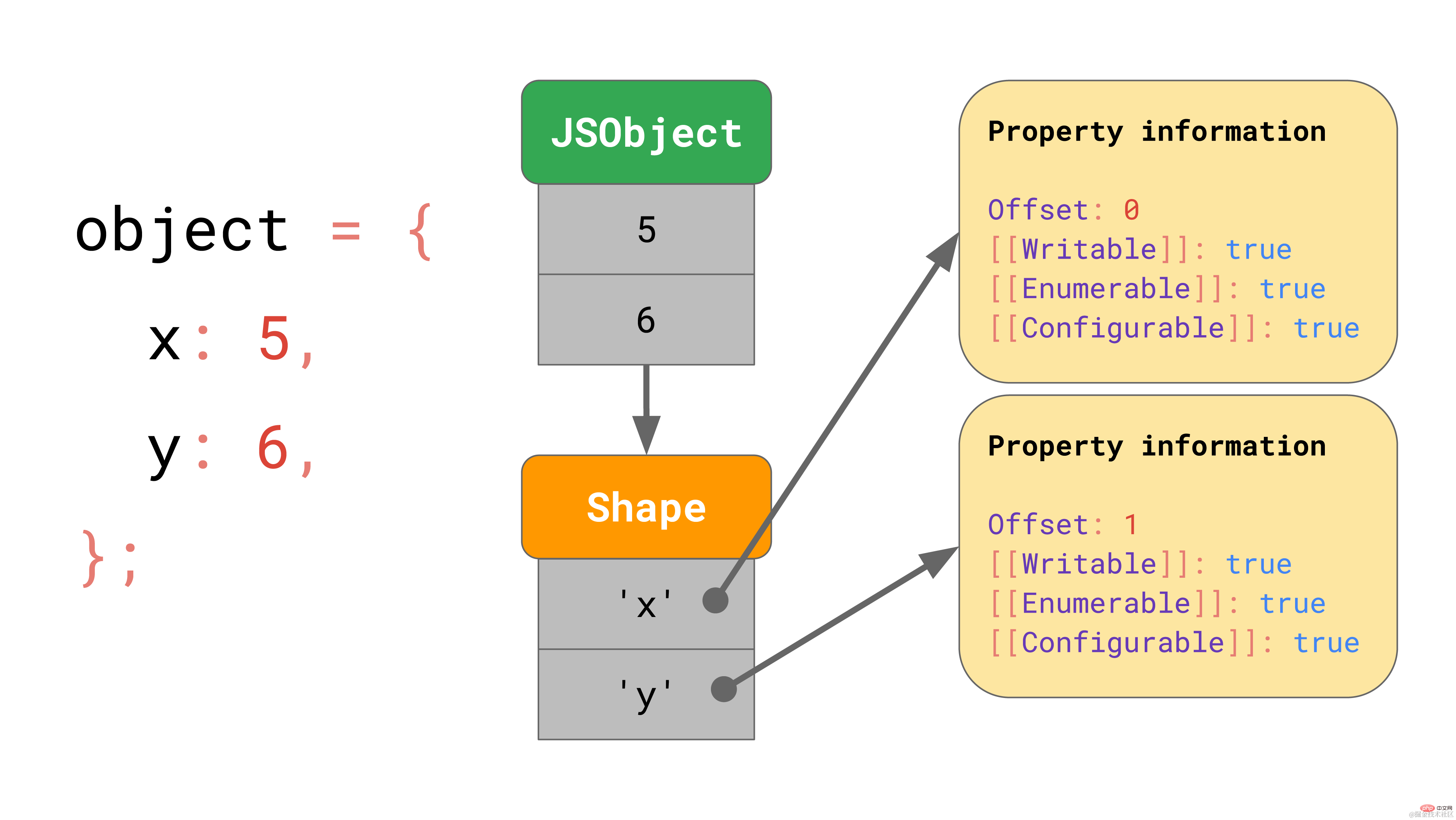 shape には、[[Value]] を除くすべての属性名と属性が含まれます。さらに、シェイプには JSObject の内部値のオフセットが含まれているため、JavaScript エンジンは値を検索する場所を認識できます。同じ形状を持つすべての JSObject は、その形状インスタンスを指します。これで、各 JSObject は、そのオブジェクトに固有の値を格納するだけで済みます。
shape には、[[Value]] を除くすべての属性名と属性が含まれます。さらに、シェイプには JSObject の内部値のオフセットが含まれているため、JavaScript エンジンは値を検索する場所を認識できます。同じ形状を持つすべての JSObject は、その形状インスタンスを指します。これで、各 JSObject は、そのオブジェクトに固有の値を格納するだけで済みます。 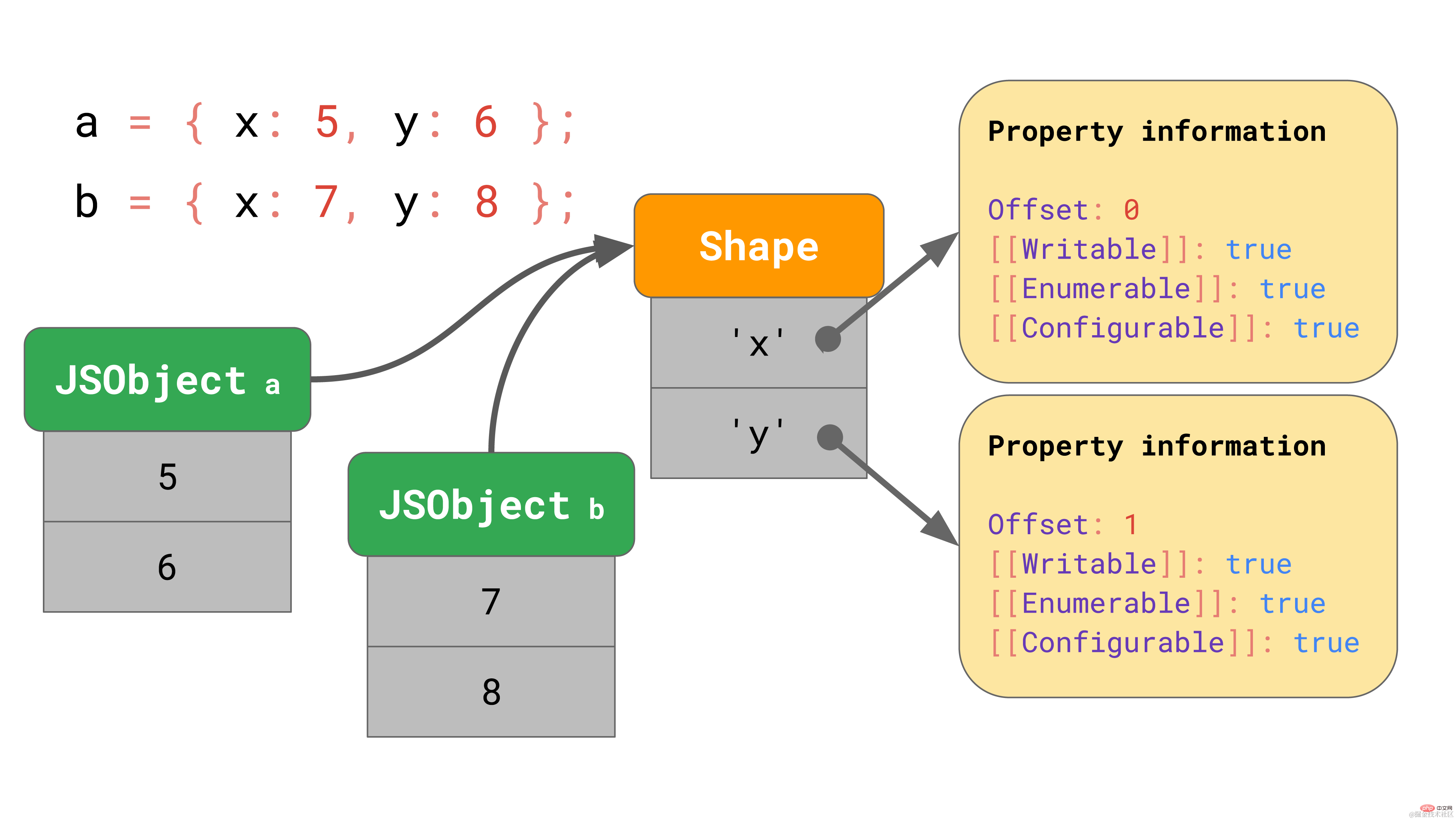 複数のオブジェクトがある場合、利点は明らかです。オブジェクトが何個あっても、同じ形状であれば、形状と属性情報を一度保存するだけで済みます。
複数のオブジェクトがある場合、利点は明らかです。オブジェクトが何個あっても、同じ形状であれば、形状と属性情報を一度保存するだけで済みます。
すべての JavaScript エンジンは最適化としてシェイプを使用しますが、名前は異なります:
本文中,我们将继续使用术语 shapes.
如果你有一个具有特定 shape 的对象,但你又向它添加了一个属性,此时会发生什么? JavaScript 引擎是如何找到这个新 shape 的?
const object = {};
object.x = 5;
object.y = 6;复制代码这些 shapes 在 JavaScript 引擎中形成所谓的转换链(transition chains)。下面是一个例子:
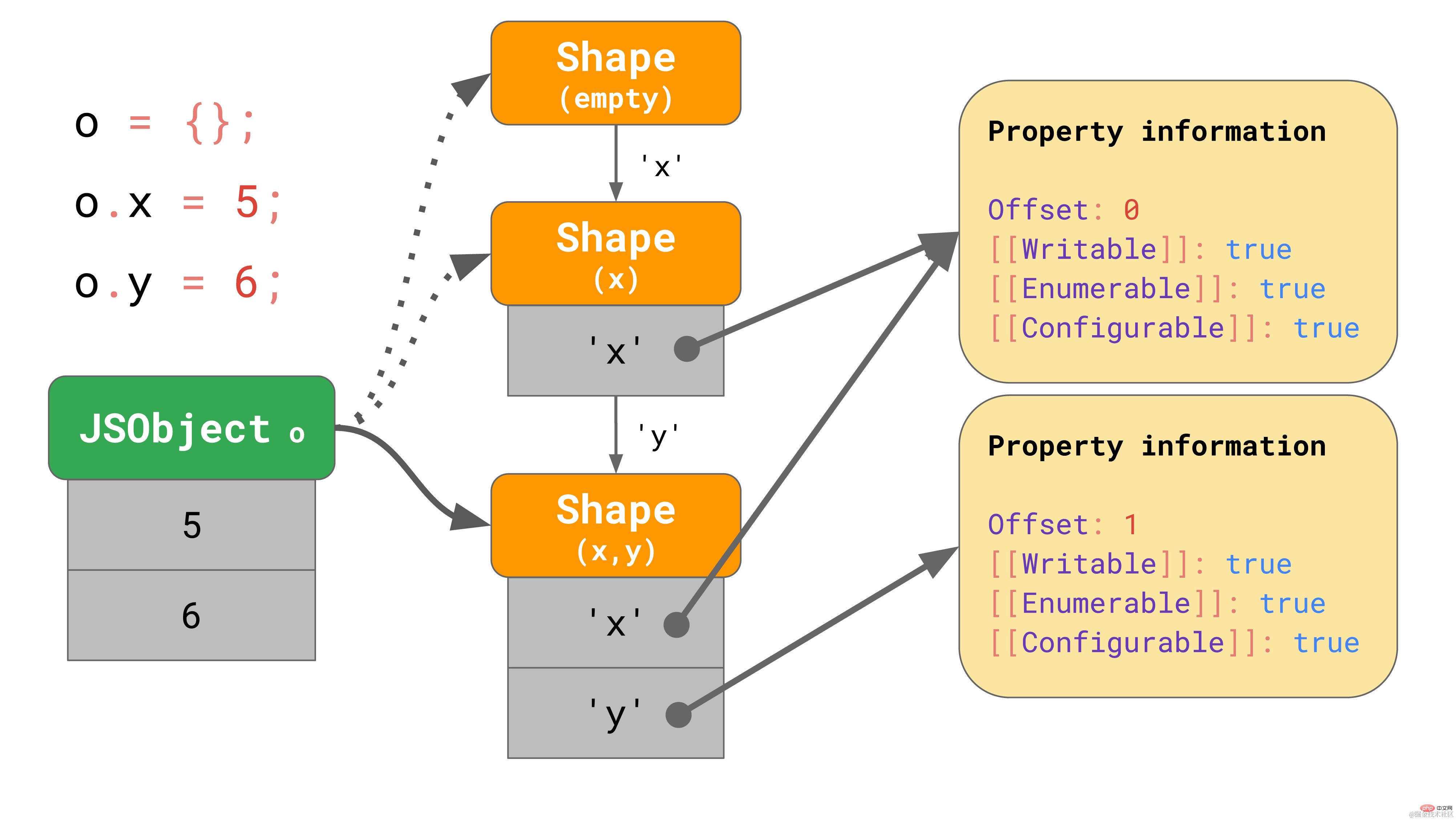
该对象开始没有任何属性,因此它指向一个空的 shape。下一个语句为该对象添加一个值为 5 的属性 "x",所以 JavaScript 引擎转向一个包含属性 "x" 的 shape,并在第一个偏移量为 0 处向 JSObject 添加了一个值 5。 下一行添加了一个属性 'y',引擎便转向另一个包含 'x' 和 'y' 的 shape,并将值 6 添加到 JSObject(位于偏移量 1 处)。
我们甚至不需要为每个 shape 存储完整的属性表。相反,每个shape 只需要知道它引入的新属性。例如,在本例中,我们不必将有关 “x” 的信息存储在最后一个 shape 中,因为它可以在更早的链上找到。要实现这一点,每个 shape 都会链接回其上一个 shape: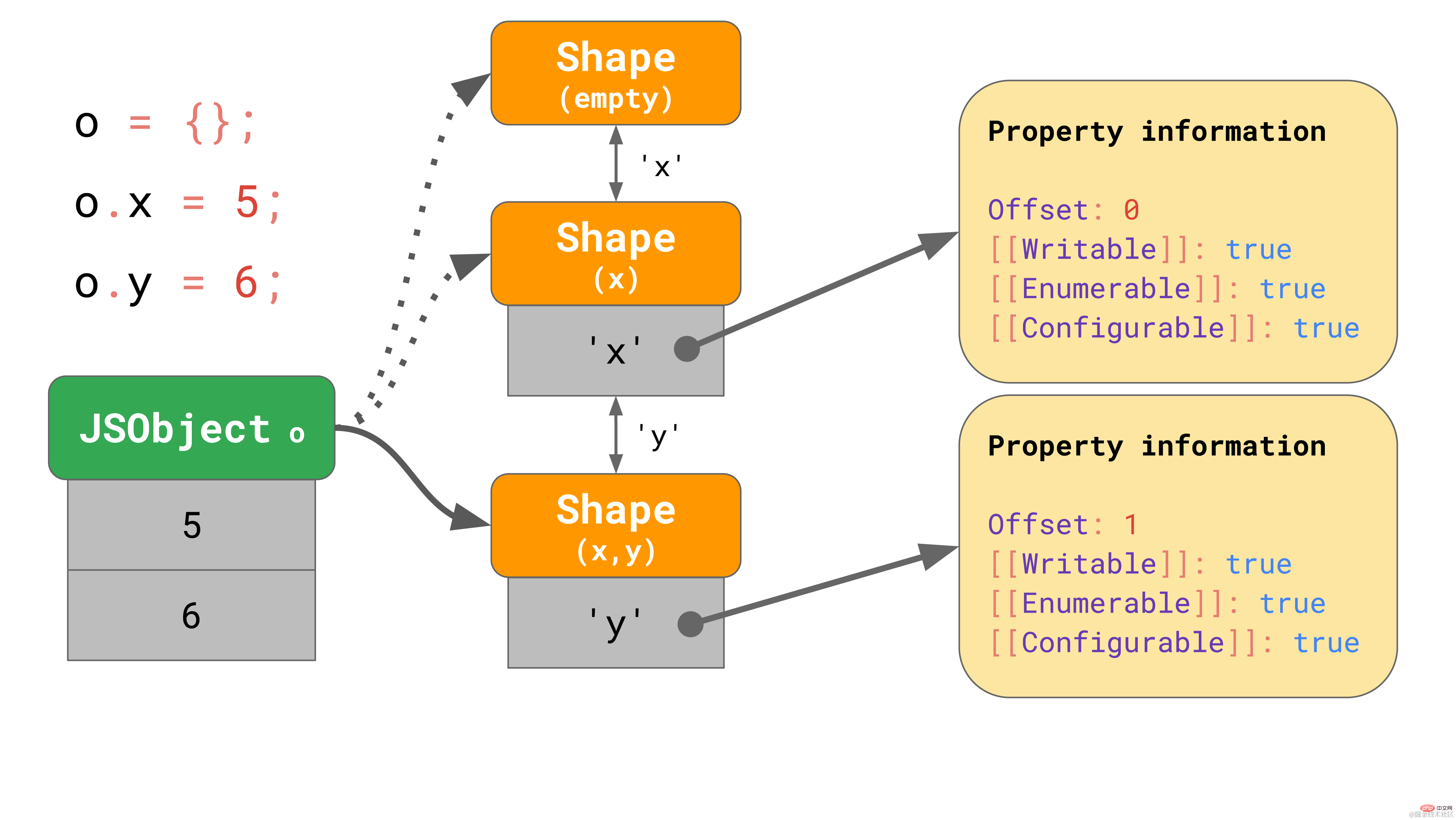
如果你在 JavaScript 代码中写 o.x,JavaScript 引擎会沿着转换链去查找属性 "x",直到找到引入属性 "x" 的 Shape。
但是如果没有办法创建一个转换链会怎么样呢?例如,如果有两个空对象,并且你为每个对象添加了不同的属性,该怎么办?
const object1 = {};
object1.x = 5;const object2 = {};
object2.y = 6;复制代码在这种情况下,我们必须进行分支操作,最终我们会得到一个转换树而不是转换链。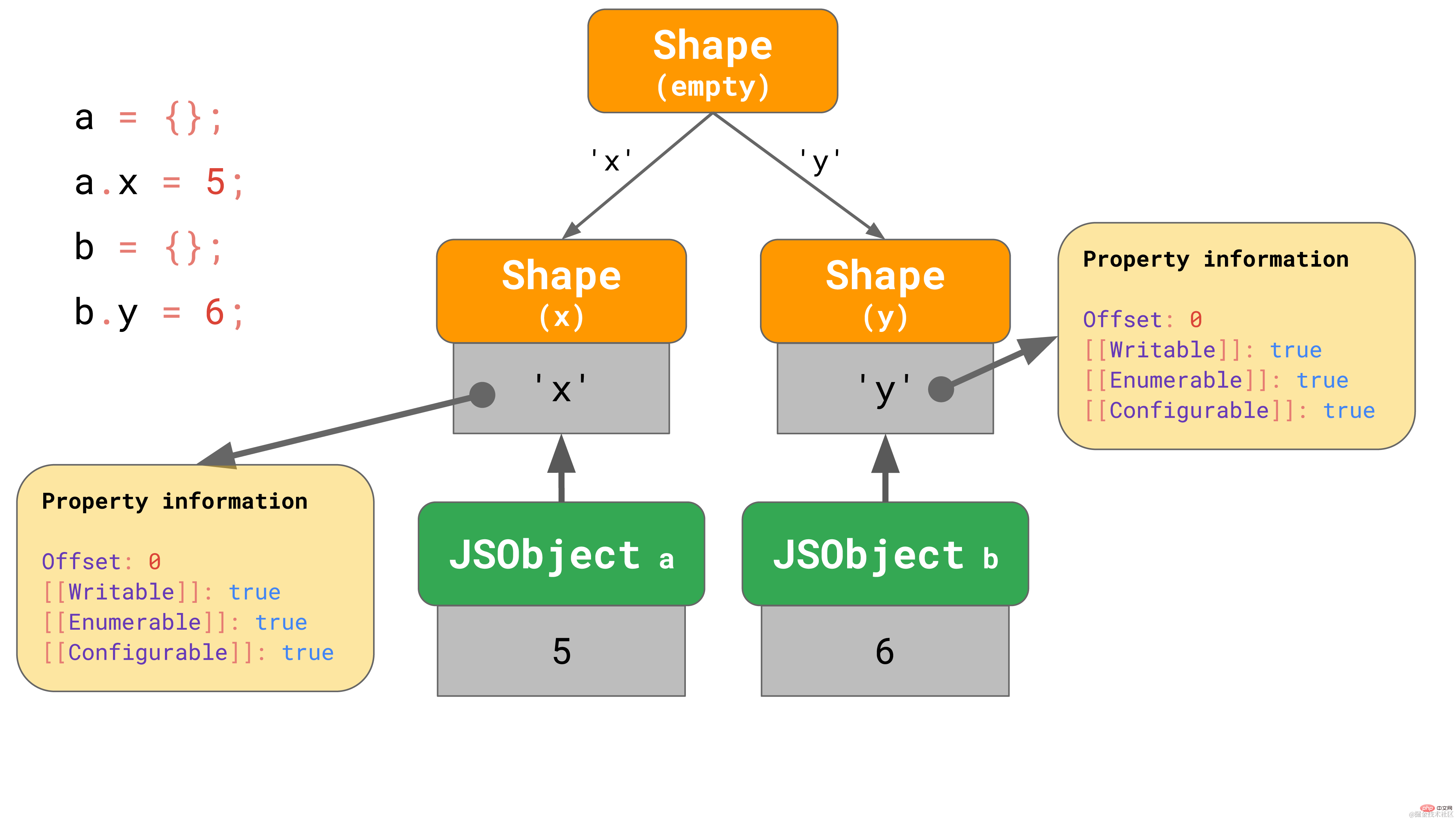
这里,我们创建了一个空对象 a,然后给它添加了一个属性 ‘x’。最终,我们得到了一个包含唯一值的 JSObject 和两个 Shape :空 shape 以及只包含属性 x 的 shape。
第二个例子也是从一个空对象 b 开始的,但是我们给它添加了一个不同的属性 ‘y’。最终,我们得到了两个 shape 链,总共 3 个 shape。
这是否意味着我们总是需要从空 shape 开始呢? 不一定。引擎对已含有属性的对象字面量会进行一些优化。比方说,我们要么从空对象字面量开始添加 x 属性,要么有一个已经包含属性 x 的对象字面量:
const object1 = {};
object1.x = 5;const object2 = { x: 6 };复制代码在第一个例子中,我们从空 shape 开始,然后转到包含 x 的shape,这正如我们之前所见那样。
在 object2 的例子中,直接在一开始就生成含有 x 属性的对象,而不是生成一个空对象是有意义的。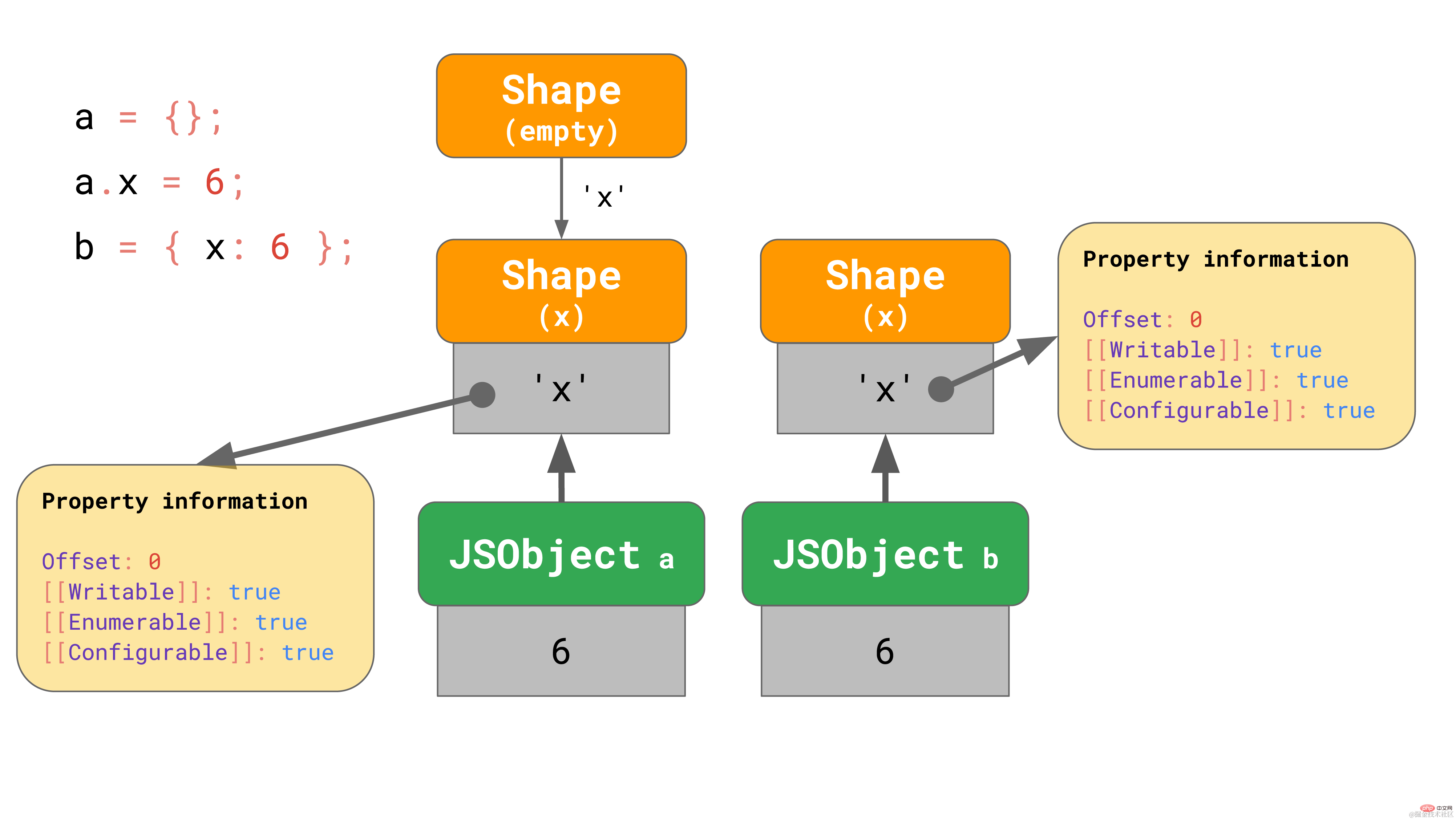
包含属性 ‘x’ 的对象字面量从含有 ‘x’ 的 shape 开始,有效地跳过了空 shape。V8 和 SpiderMonkey (至少)正是这么做的。这种优化缩短了转换链并且使从字面量构建对象更加高效。
下面是一个包含属性 ‘x'、'y' 和 'z' 的 3D 点对象的示例。
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;复制代码正如我们之前所了解的, 这会在内存中创建一个有3个 shape 的对象(不算空 shape 的话)。 当访问该对象的属性 ‘x’ 的时候,比如, 你在程序里写 point.x,javaScript 引擎需要循着链接列表寻找:它会从底部的 shape 开始,一层层向上寻找,直到找到顶部包含 ‘x’ 的 shape。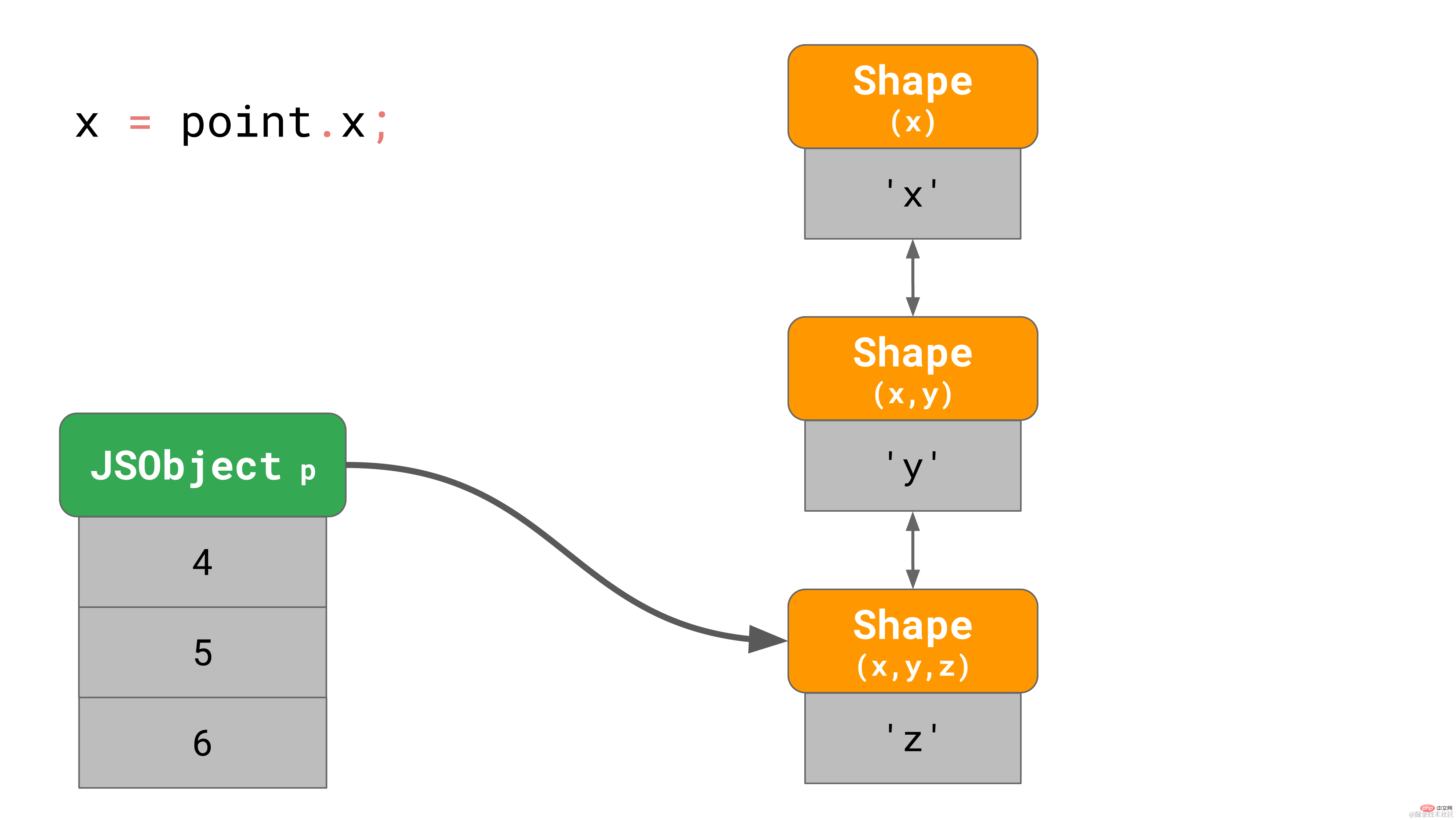
当这样的操作更频繁时, 速度会变得非常慢,特别是当对象有很多属性的时候。寻找属性的时间复杂度为 O(n), 即和对象上的属性数量线性相关。为了加快属性的搜索速度, JavaScript 引擎增加了一种 ShapeTable 的数据结构。这个 ShapeTable 是一个字典,它将属性键映射到描述对应属性的 shape 上。
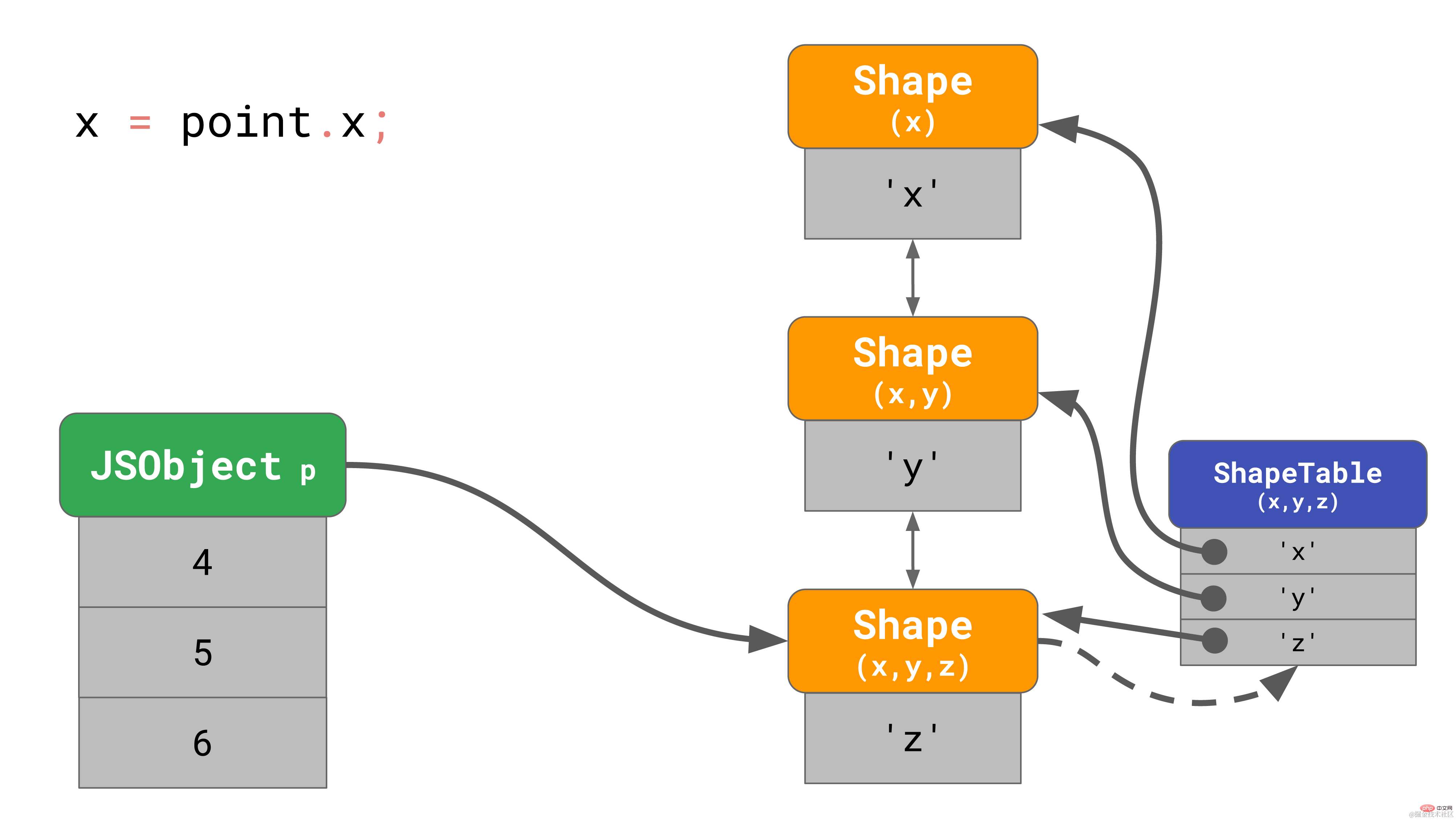
现在我们又回到字典查找了我们添加 shape 就是为了对此进行优化!那我们为什么要去纠结 shape 呢? 原因是 shape 启用了另一种称为 Inline Caches 的优化。
shapes 背后的主要动机是 Inline Caches 或 ICs 的概念。ICs 是让 JavaScript 快速运行的关键要素!JavaScript 引擎使用 ICs 来存储查找到对象属性的位置信息,以减少昂贵的查找次数。
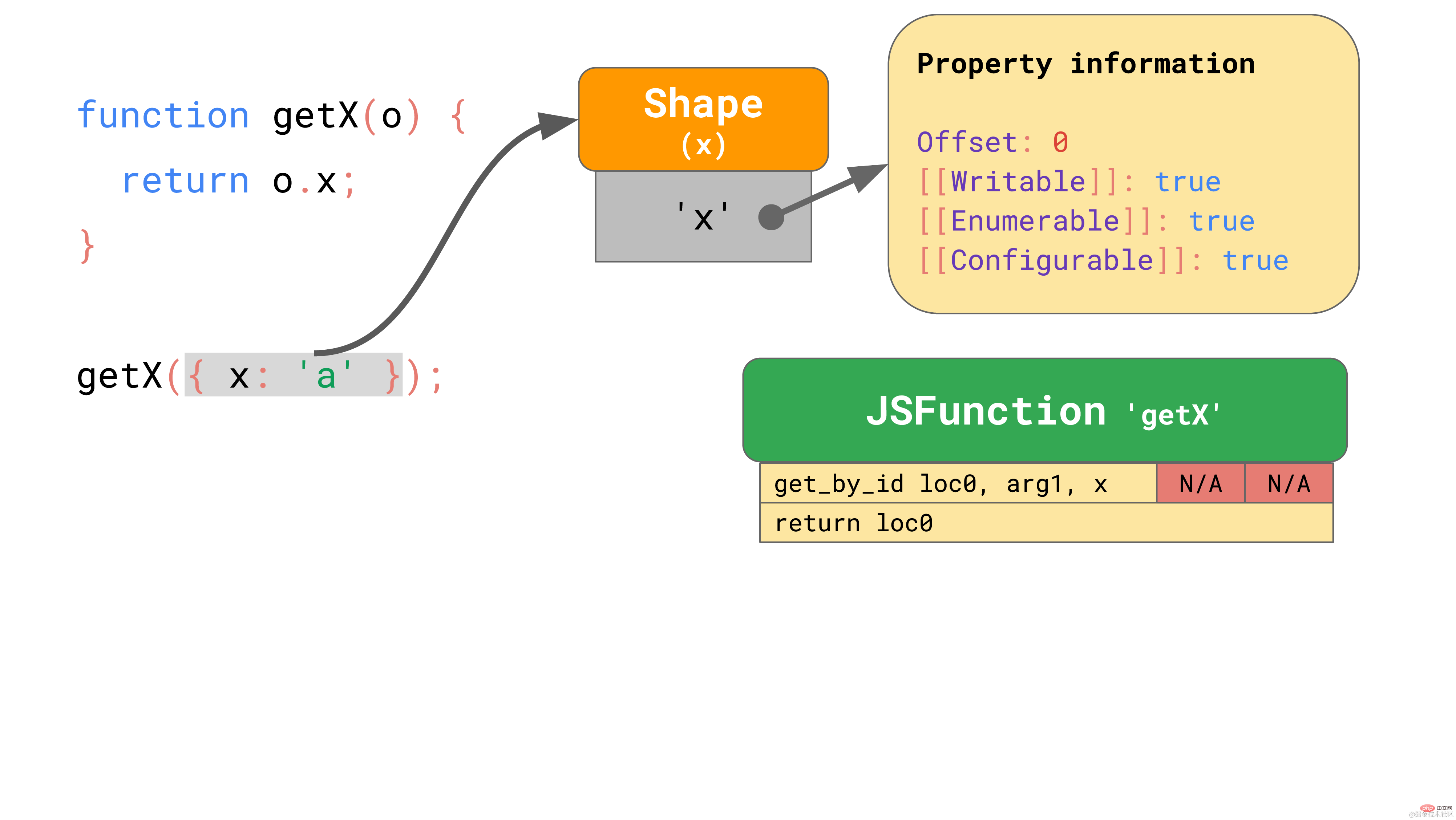
这里有一个函数 getX,该函数接收一个对象并从中加载属性 x:
function getX(o) { return o.x;
}复制代码如果我们在 JSC 中运行该函数,它会产生以下字节码:
第一条 get_by_id 指令从第一个参数(arg1)加载属性 ‘x’,并将结果存储到 loc0 中。第二条指令将存储的内容返回给 loc0。
JSC 还将一个 Inline Cache 嵌入到 get_by_id 指令中,该指令由两个未初始化的插槽组成。
 现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
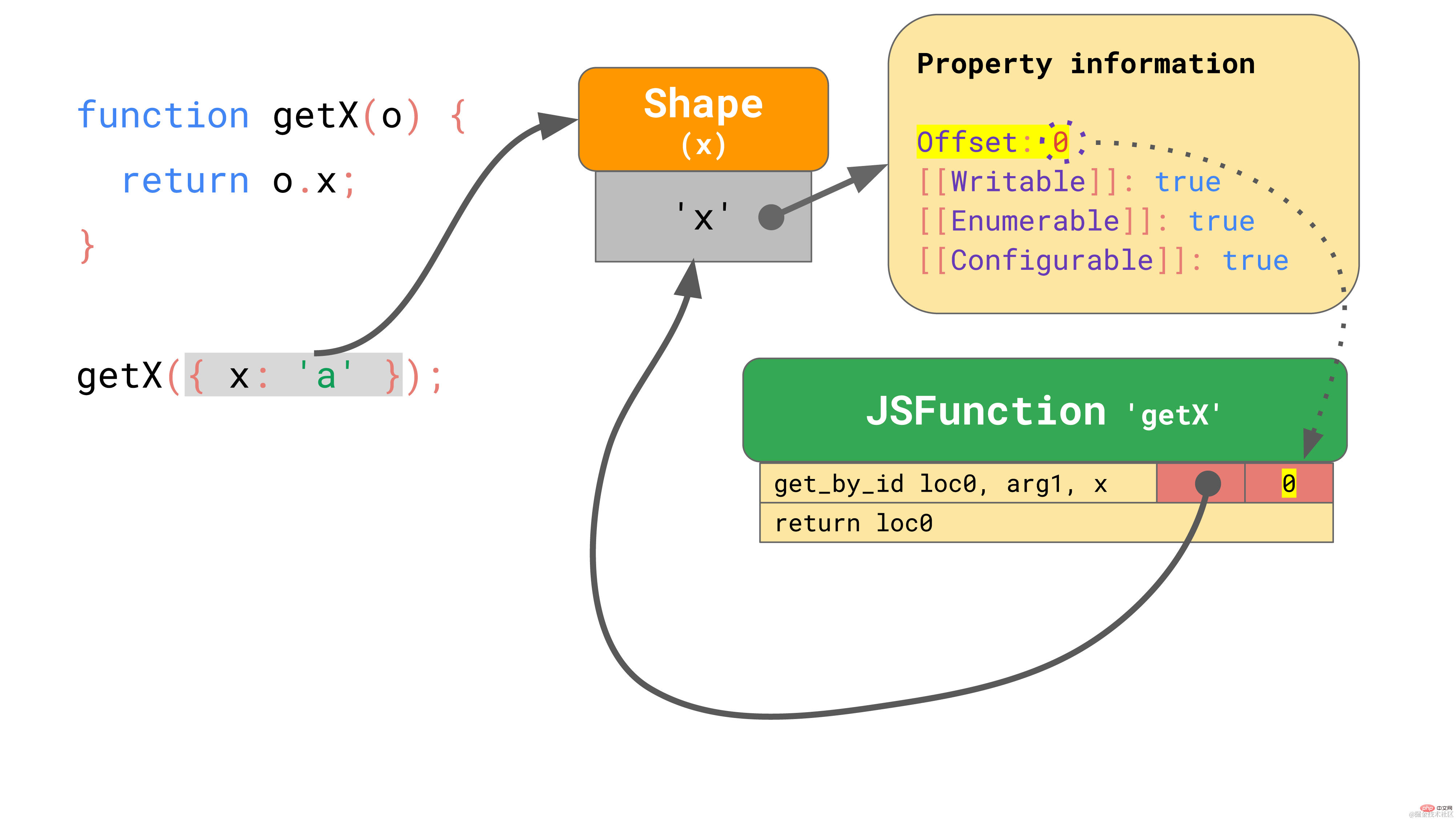
嵌入到 get_by_id 指令中的 IC 存储了 shape 和该属性的偏移量:
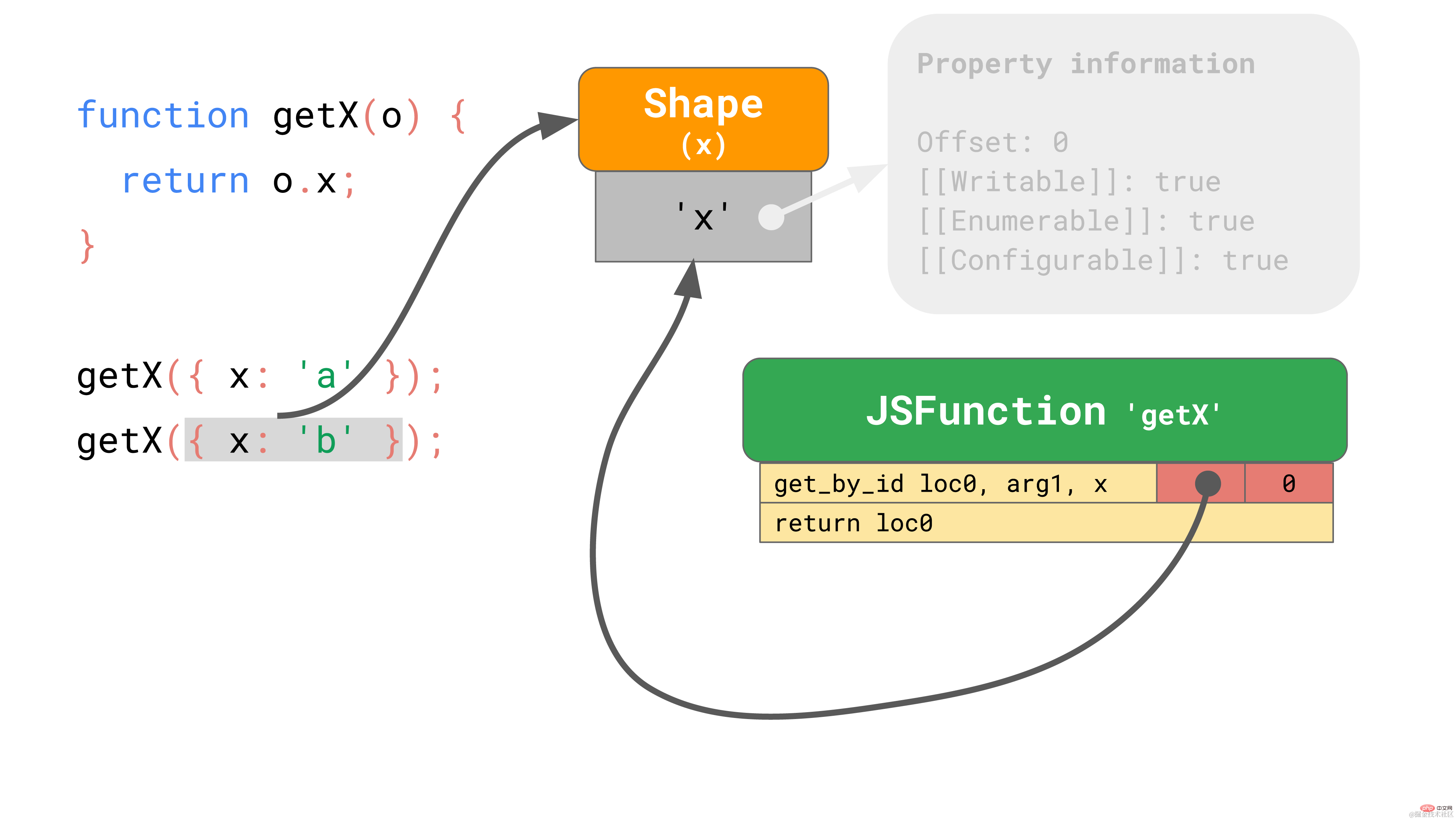
对于后续运行,IC 只需要比较 shape,如果 shape 与之前相同,只需从存储的偏移量加载值。具体来说,如果 JavaScript 引擎看到对象的 shape 是 IC 以前记录过的,那么它根本不需要接触属性信息,相反,可以完全跳过昂贵的属性信息查找过程。这要比每次都查找属性快得多。
对于数组,存储数组索引属性是很常见的。这些属性的值称为数组元素。为每个数组中的每个数组元素存储属性特性是非常浪费内存的。相反,默认情况下,数组索引属性是可写的、可枚举的和可配置的,JavaScript 引擎基于这一点将数组元素与其他命名属性分开存储。
思考下面的数组:
const array = [ '#jsconfeu', ];复制代码
引擎存储了数组长度(1),并指向包含偏移量和 'length' 属性特性的 shape。
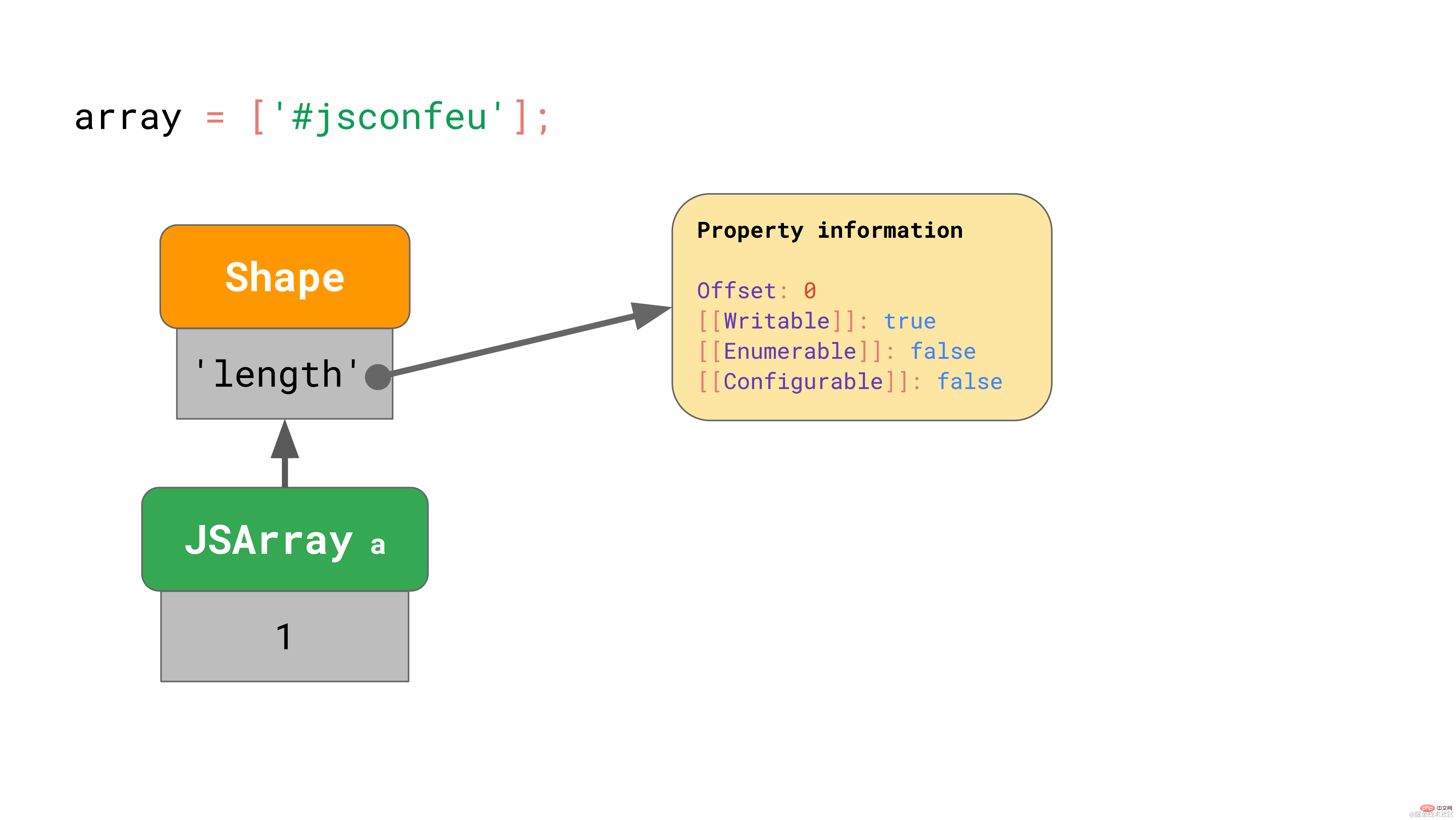
这和我们之前看到的很相似……但是数组的值存到哪里了呢?
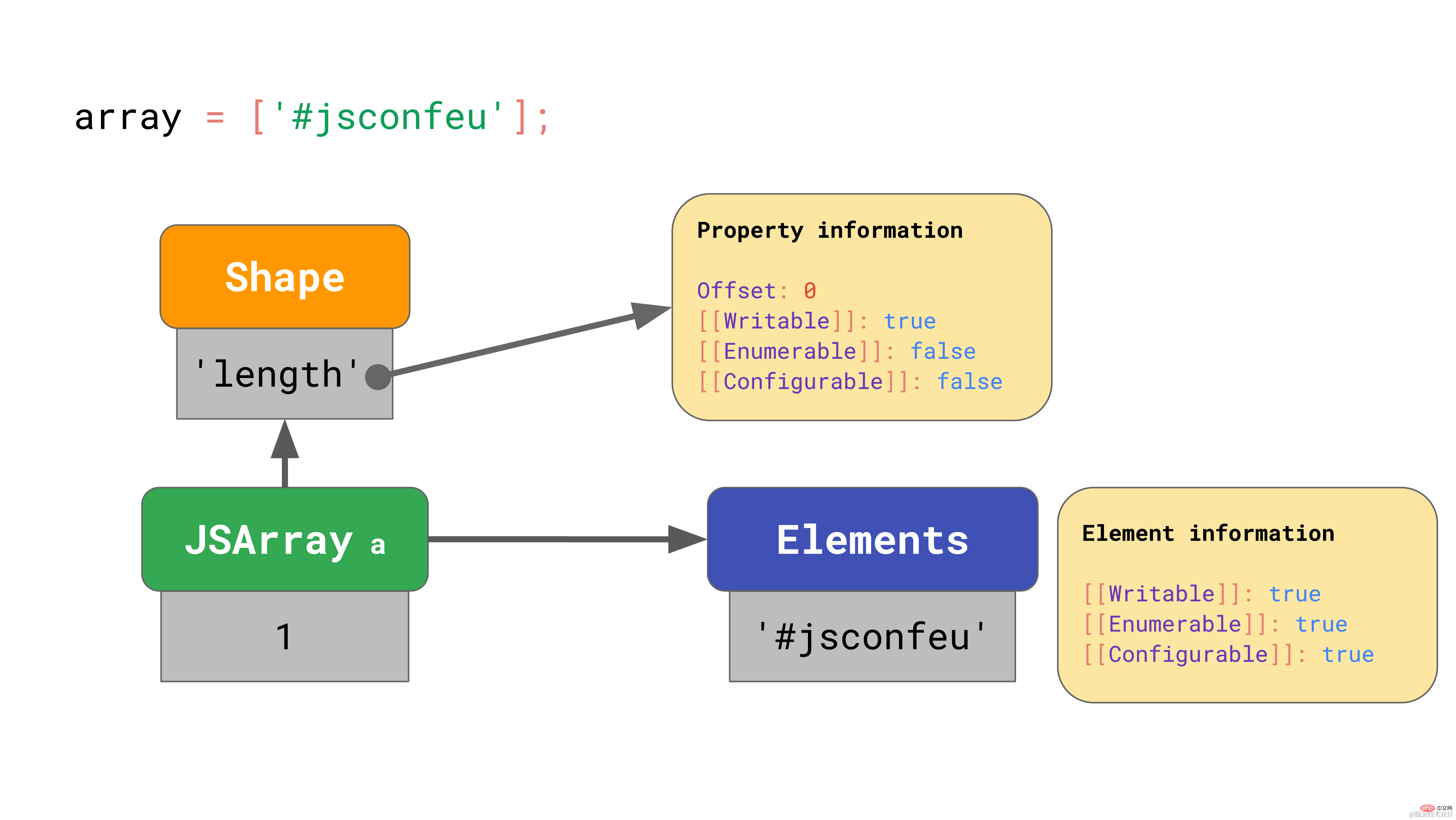
每个数组都有一个单独的元素备份存储区,包含所有数组索引的属性值。JavaScript 引擎不必为数组元素存储任何属性特性,因为它们通常都是可写的、可枚举的和可配置的。
那么,在非通常情况下会怎么样呢?如果更改了数组元素的属性特性,该怎么办?
// Please don’t ever do this!const array = Object.defineProperty(
[], '0',
{
value: 'Oh noes!!1',
writable: false,
enumerable: false,
configurable: false,
});复制代码上面的代码片段定义了名为 “0” 的属性(恰好是数组索引),但将其特性设置为非默认值。
在这种边缘情况下,JavaScript 引擎将整个元素备份存储区表示成一个字典,该字典将数组索引映射到属性特性。
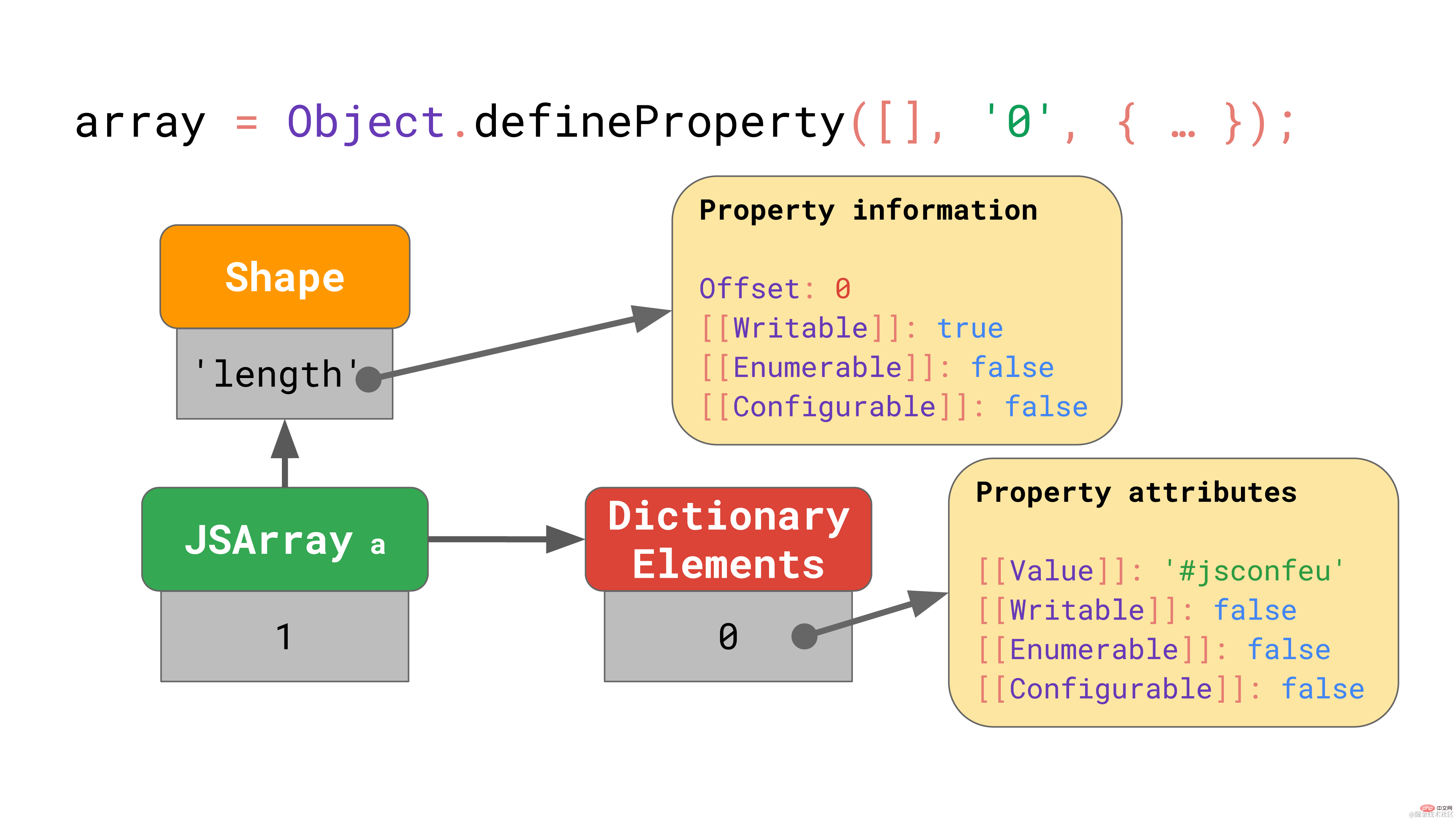
即使只有一个数组元素具有非默认特性,整个数组的备份存储区也会进入这种缓慢而低效的模式。避免对数组索引使用Object.defineProperty!
我们已经了解了 JavaScript 引擎如何存储对象和数组,以及 shape 和 ICs 如何优化对它们的常见操作。基于这些知识,我们确定了一些可以帮助提高性能的实用的 JavaScript 编码技巧:
# 関連する無料学習の推奨事項: javascript (ビデオ)
以上がJavaScript エンジンの基本原理を理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



