

i++ に起因するバグを解決する

java Basic Tutorial 列では、i によって引き起こされるバグを紹介します。

皆さん、こんにちは。毎日バグを書いて修正している者として、今日は数日前に修正されたばかりの事故を紹介します。どこにいても常にバグがたくさんあることを認めざるを得ません。

原因
この話は数日前に始まりました。あまり一般的に使用されておらず、ユーザーによって報告されたエクスポート機能がありました。条件は でした。エクスポートされたデータは 1 つだけですが、実際には条件に従って大量のデータがクエリされており、ページ上でも大量のデータがクエリされています。 (この問題は修正されたため、当時の Kibana ログはもう見つかりません。) そこで、私は仕事をやめて、この問題を調査することにしました。
分析
問題の説明によると、この問題は次の状況でのみ発生する可能性があります。
- に基づいてクエリされたレコードは 1 つだけです。検索条件
- クエリされたデータに対して関連するビジネス処理を実行し、最終結果は 1 つだけになります。
- ファイル エクスポート コンポーネントの論理処理後の結果は 1 つだけです。
余談
これを書いた後、MQメッセージ損失の原因の分析という古典的な面接の質問を突然思い出しました。ははは、実はいくつかの角度から大まかに分析されています。 (機会があれば MQ についての記事を書きます)
余談

ということで、一つずつ分析していきます:
- クエリで取得できる関連業務のSQLと対応するパラメータを検索します データは複数あるため、最初の状況は除外できます。
- 中間ビジネスには、関連する権限、データの機密性などが含まれます。これらを解放した後も、データは 1 つだけです。
- ファイル エクスポート コンポーネントがデータを受信すると、出力されるログにもエントリが 1 つだけ表示されます。これは、関連するビジネスのロジックに問題があることを意味します。
このコードはメソッド全体に記述されているため、Arthas によるトラブルシューティングが困難です。そのため、トラブルシューティングのためにログを段階的に設定する必要があります。 (そのため、大きなロジックの場合は、duoge のサブメソッドに分割することをお勧めします。まず、作成時にアイデアが明確になり、モジュールの概念が存在します。メソッドの再利用については、基本操作 ; 次に、経験から言えば、問題が発生するとトラブルシューティングが容易になります)。
最終的に for ループ内に配置されます。
コード
早速、コードを直接見てみましょう。ご存知のとおり、私は常に会社のコードを守る人間でしたので、ここにいる全員のためにそれをシミュレートする必要があります。問題から判断すると、エクスポートされたオブジェクト レコードは空です
import com.google.common.collect.Lists;import java.util.List;public class Test { public static void main(String[] args) { // 获取Customer数据,这里就简单模拟
List<Customer> customerList = Lists.newArrayList(new Customer("Java"), new Customer("Showyool"), new Customer("Soga")); int index = 0;
String[][] exportData = new String[customerList.size()][2]; for (Customer customer : customerList) {
exportData[index][0] = String.valueOf(index);
exportData[index][1] = customer.getName();
index = index++;
}
System.out.println(JSON.toJSONString(exportData));
}
}class Customer { public Customer(String name) { this.name = name;
} private String name; public String getName() { return name;
} public void setName(String name) { this.name = name;
}
}复制代码このコードは何もないようで、Customer コレクションを文字列の 2 次元配列に変換するものです。しかし、出力結果は次のようになります: 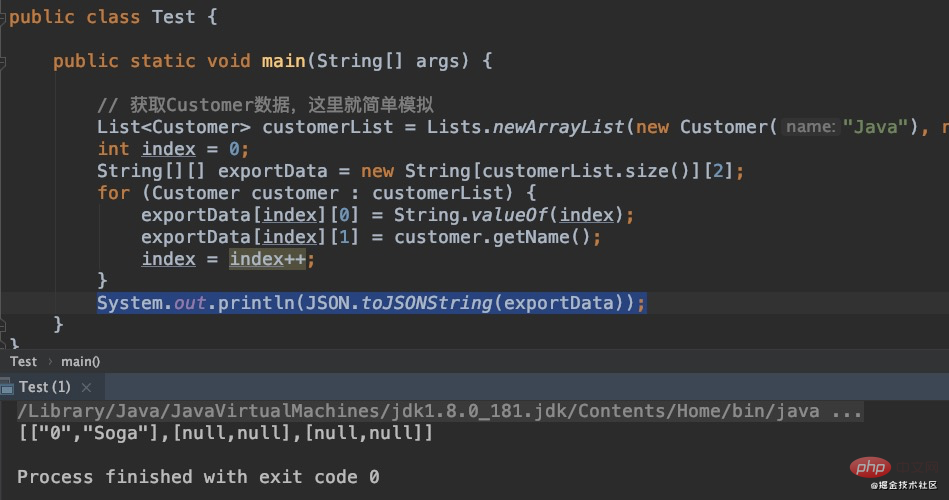 これは私たちが言ったことと一致しています。複数のクエリがありますが、出力されるのは 1 つだけです。
これは私たちが言ったことと一致しています。複数のクエリがありますが、出力されるのは 1 つだけです。
よく見ると、出力データは常に最後のデータであることがわかります。つまり、Customer コレクションが走査されるたびに、後者が前者を上書きします。つまり、このインデックスの下位部分は、スケールは決して変更されず、常に 0 です。
モデリング
自己インクリメントにはいくつかの問題があるようですので、単純にモデルを作成しましょう
public class Test2 { public static void main(String[] args) { int index = 3;
index = index++;
System.out.println(index);
}
}复制代码上記のビジネス ロジックを次のように単純化します。このようなモデルの場合、結果は当然のことながら 3 です。
説明
次に、javap を実行して、JVM バイトコードがどのように解釈されるかを見てみましょう:
javap -c Test2
Compiled from "Test2.java"public class com.showyool.blog_4.Test2 { public com.showyool.blog_4.Test2();
Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code: 0: iconst_3 1: istore_1 2: iload_1 3: iinc 1, 1
6: istore_1 7: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
10: iload_1 11: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
14: return}复制代码ここで、JVM バイトコード命令について簡単に説明します (後で説明を書きます)機会があれば詳しく説明します)
まず、ここにはオペランド スタックとローカル変数テーブルという 2 つの概念があることを知っておく必要があります。これら 2 つは、仮想マシンのスタック フレーム内のデータ構造です。
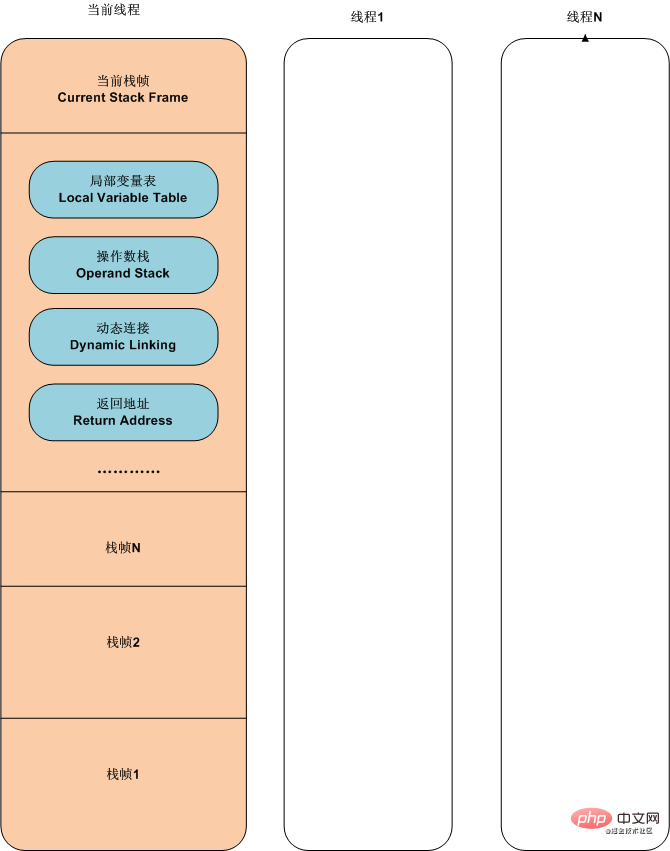
# オペランド スタックの機能はスタックにデータを格納し、データを計算することであり、ローカル変数はtable は変数に何らかの情報を格納するためのものです。
次に、上記の命令を見てみましょう:
0: iconst_3 (最初に定数 3 をスタックにプッシュします)
1: istore_1 (出栈操作,将值赋给第一个参数,也就是将3赋值给index)
2: iload_1 (将第一个参数的值压入栈,也就是将3入栈,此时栈顶的值为3)
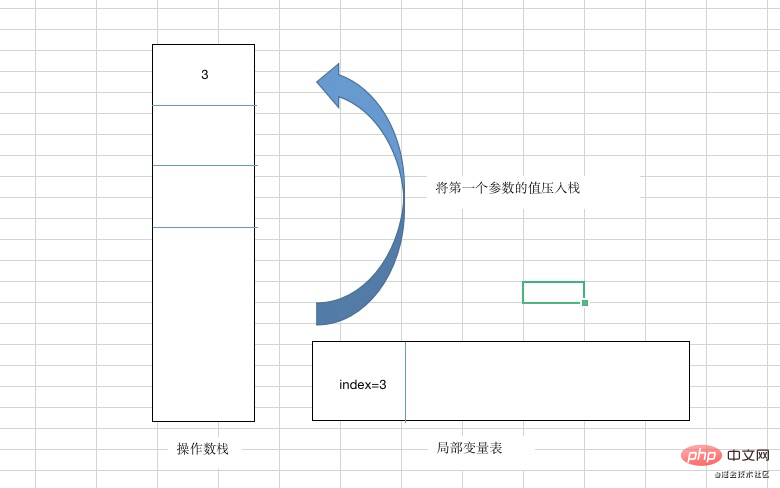
3: iinc 1, 1 (将第一个参数的值进行自增操作,那么此时index的值是4)

6: istore_1 (出栈操作,将值赋给第一个参数,也就是将3赋值给index)
也就是说index这个参数的值是经历了index->3->4->3,所以这样一轮操作之后,index又回到了一开始赋值的值。
延伸一下
这样一来,我们发现,问题其实出在最后一步,在进行运算之后,又将原先栈中记录的值重新赋给变量,覆盖掉了 如果我们这样写:
public class Test2 { public static void main(String[] args) { int index = 3;
index++;
System.out.println(index);
}
}
Compiled from "Test2.java"public class com.showyool.blog_4.Test2 { public com.showyool.blog_4.Test2();
Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code: 0: iconst_3 1: istore_1 2: iinc 1, 1
5: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
8: iload_1 9: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
12: return}复制代码可以发现,这里就没有最后一步的istore_1,那么在iinc之后,index的值就变成我们预想的4。
还有一种情况,我们来看看:
public class Test2 { public static void main(String[] args) { int index = 3;
index = index + 2;
System.out.println(index);
}
}
Compiled from "Test2.java"public class com.showyool.blog_4.Test2 { public com.showyool.blog_4.Test2();
Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code: 0: iconst_3 1: istore_1 2: iload_1 3: iconst_2 4: iadd 5: istore_1 6: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
9: iload_1 10: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
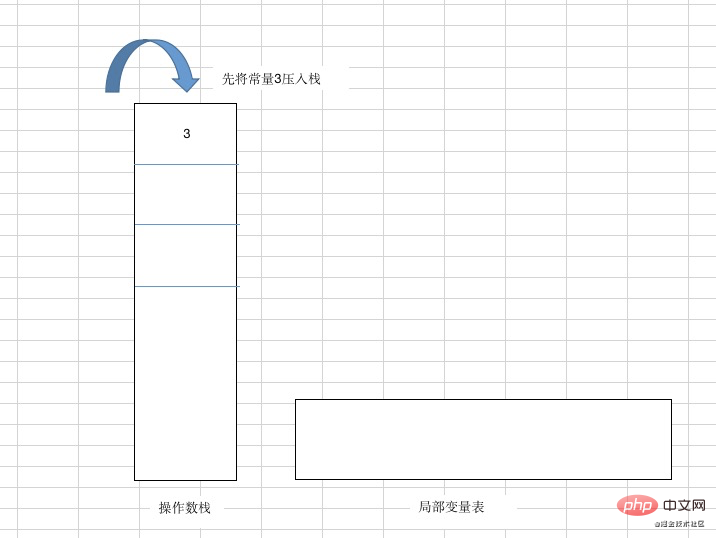
13: return}复制代码0: iconst_3 (先将常量3压入栈)
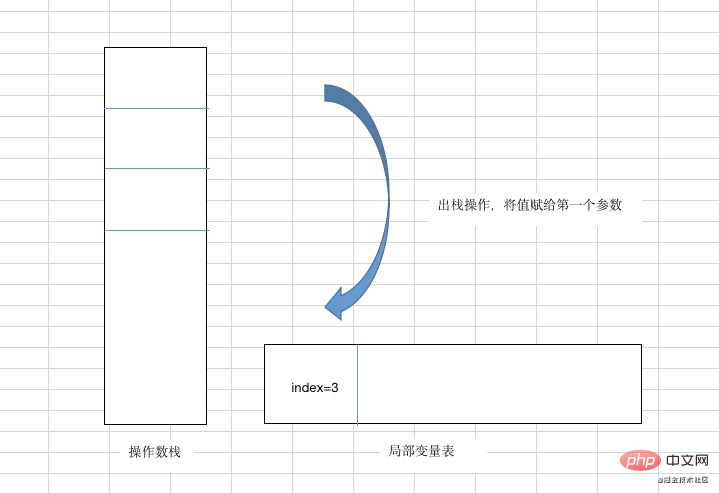
1: istore_1 (出栈操作,将值赋给第一个参数,也就是将3赋值给index)
2: iload_1 (将第一个参数的值压入栈,也就是将3入栈,此时栈顶的值为3)
3: iconst_2 (将常量2压入栈, 此时栈顶的值为2,2在3之上)
4: iadd (将栈顶的两个数进行相加,并将结果压入栈。2+3=5,此时栈顶的值为5)
5: istore_1 (出栈操作,将值赋给第一个参数,也就是将5赋值给index)
看到这里各位观众老爷肯定会有这么一个疑惑,为什么这里的iadd加法操作之后,会影响栈里面的数据,而先前说的iinc不是在栈里面操作?好的吧,我们可以看看JVM虚拟机规范当中,它是这么描述的:
指令iinc对给定的局部变量做自增操作,这条指令是少数几个执行过程中完全不修改操作数栈的指令。它接收两个操作数: 第1个局部变量表的位置,第2个位累加数。比如常见的i++,就会产生这条指令
看到这里,我们知道,对于一般的加法操作之后复制没啥问题,但是使用i++之后,那么此时栈顶的数还是之前的旧值,如果此刻进行赋值就会回到原来的旧值,因为它并没有修改栈里面的数据。所以先前那个bug,只需要进行自增不赋值就可以修复了。

最後に
ご覧いただきありがとうございます。上記は、このバグに対処する私のプロセス全体です。これは単なる小さなバグですが、この小さなバグにも学習し、検討する価値があります。今後も私が見つけたバグやナレッジ ポイントを共有していきたいと思います。私の記事がお役に立てば、皆さんも幸いです。 関連する無料学習の推奨事項:
Java 基本チュートリアル
以上がi++ に起因するバグを解決するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7548
7548
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
