
java Basic Tutorial コラムでは、今日の RocketMQ に関する知識を詳しく紹介します。

ブログを書くのは久しぶりです。ブログを書かない理由は数え切れないほどありますが、結局のところ、やはり「怠惰」です。今日はやっと怠け者のガンを治す薬を飲み、ブログを書くことにしました。何を紹介しようか? いろいろ考えた結果、RocketMQ を紹介することにします。結局、30 個以上のブログを書いてきましたが、まだ MQ についてまともなブログを書いたことはありません。このブログは比較的基本的なものであり、ソース コードの分析は含まれておらず、リテラシーだけが含まれています。
ある視点から見ると、マイクロサービスが MQ の活発な開発を促進したと思います。本来、システムには N 個の複数のモジュールがあり、すべてのモジュールは強く結合されています。マイクロサービスでは、モジュールはシステムであり、システムは間違いなく対話する必要があります。対話には 3 つの一般的な方法があります。1 つは RPC、1 つは HTTP、もう 1 つは MQ です。
当初、ビジネスは N のステップに分割されており、最終結果をユーザーに返す前に段階的に処理する必要がありましたが、MQ では最も重要な部分が実現されました。が最初に処理され、その後 MQ にメッセージを送信し、ユーザーに直接 OK を返します。以降の手順については、バックグラウンドでゆっくりと処理しましょう。これはユーザー エクスペリエンスを向上させるための成果物です。
特定のインターフェイスに対するリクエストの数が突然急増すると、必然的にアプリケーション サーバーとデータベース サーバーに多大な負荷がかかります。バックグラウンドでゆっくりと処理されるため、どれだけのリクエストが来るかを気にする必要はありません。
RocketMQ は Java で書かれており、Alibaba のオープン ソース メッセージ ミドルウェアであり、Kafka の利点の多くを吸収しています。 Kafka も人気のあるメッセージ ミドルウェアですが、Kafka は Scala で書かれているため、Java プログラマーがソース コードを読むのには適していません。また、Java プログラマーがカスタマイズされた開発を行うのにも適していません。 Kafka に触れたことのある友人は、Kafka を使いこなすのが簡単ではないことを知っています。比較的言えば、RocketMQ ははるかに単純であり、RocketMQ は Alibaba の恩恵を受けており、N Double 11 のテストを経験しています。国内のインターネット企業により適しています。なので国内でも使われており、RocketMQの会社はたくさんあります。
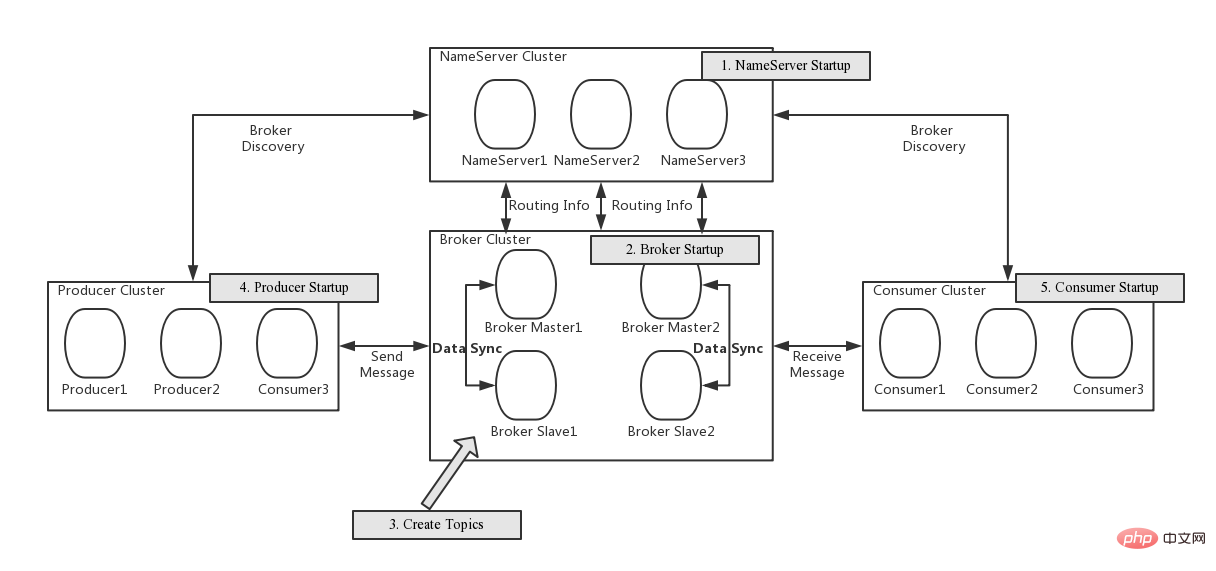 画像は gitee.com/mirrors/roc からのものです...
画像は gitee.com/mirrors/roc からのものです...
RocketMQ には 4 つの主要コンポーネントがあることがわかります。 :
ProducerGroup と ConsumerGroup に分かれていますが、ConsumerGroup に注目します。ConsumerGroup には複数の Consumer が含まれます。
クラスター消費モードでは、ConsumerGroup の下のコンシューマが一緒にトピックを消費し、各コンシューマは N 個のキューに割り当てられますが、キューは 1 つのコンシューマによってのみ消費されます。異なる ConsumerGroup は同じ A トピックを消費でき、メッセージは、このトピックにサブスクライブされているすべての ConsumerGroups によって消費されます。
クラスタリング (クラスター消費) とブロードキャスト (ブロードキャスト消費) の 2 つの消費モードがあります。
他の MQ とは異なり、他の MQ はメッセージ送信時にクラスター消費またはブロードキャスト消費を指定しますが、RocketMQ はクラスター消費またはブロードキャスト消費をコンシューマ側で設定します。
デフォルトはクラスター消費モードです。このモードでは、ConsumerGroup のすべての Consumer が共同でトピックからのメッセージを消費し、各 Consumer は N からのメッセージを消費する責任があります。 (N は 1、またはキューに割り当てられていない 0 の場合もあります)、キューは 1 つのコンシューマによってのみ消費されます。 Consumer が死亡した場合、ConsumerGroup の下にある他の Consumer が引き継ぎ、消費を続けます。
クラスター消費モードでは、消費の進行状況はボーカー側で維持され、ストレージ パスは ${ROCKET_HOME}/store/config/consumerOffset.json です (次に示すように)。図: 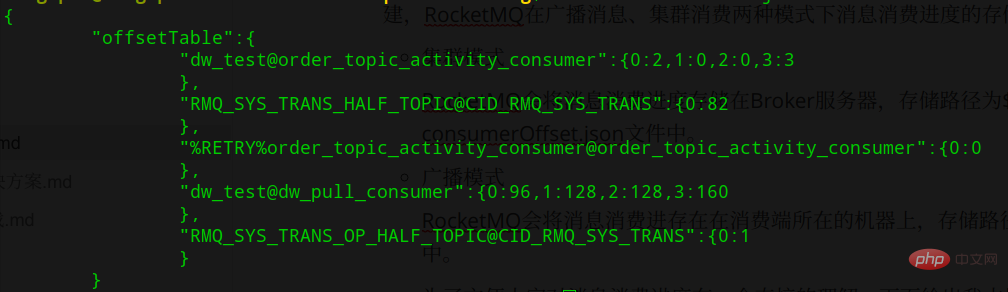 Use
UsetopicName@consumerGroupName は Key、消費の進行状況は Value です。Value の形式は queueId:offset で、複数の ConsumerGroup がある場合、消費の進行状況が各 ConsumerGroup の進行状況は異なるため、分離する必要があります。
ブロードキャスト消費メッセージは、ConsumerGroup 内のすべての Consumer に送信されます。
ブロードキャスト消費モードでは、消費の進行状況はコンシューマ側で維持されます。
クラスター消費モードでは、ConsumerGroup の下のすべての Consumer が共同で Topic メッセージを消費することがわかっています。 N 個のキューからのメッセージを消費する責任がありますが、どのように割り当てられるのでしょうか?これには、消費キューのロード アルゴリズムが関係します。
RocketMQ は多数のコンシューマー キュー ロード アルゴリズムを提供します。その中で最もよく使用される 2 つのアルゴリズムは、AllocateMessageQueueAveragely と AllocateMessageQueueAveragelyByCircle です。これら 2 つのアルゴリズムの違いを見てみましょう。
トピックには、q0 ~ q15 で表される 16 個のキューと、c0 ~ c2 で表される 3 つのコンシューマがあるとします。
AllocateMessageQueueAveragely を使用してキュー負荷アルゴリズムを使用した結果は次のとおりです。
AllocateMessageQueueAveragelyByCircle を使用してキュー負荷アルゴリズムを使用した結果は次のとおりです。
ConsumerGroup 下のすべての Consumer が一緒にトピック メッセージを消費します、各コンシューマは N 個のキュー メッセージを消費する責任がありますが、1 つのキューを N 個のコンシューマが同時に消費することはできません。これは何を意味しますか?
賢明な方なら、トピックにキューが 4 つとコンシューマが 5 つしかない場合、1 つのコンシューマはどのキューにも割り当てられないと考えたはずです。そのため、RocketMQ では、トピックの下のキューの数は次のようになります。コンシューマの最大数を直接決定します。つまり、コンシューマを追加するだけでは消費速度を上げることはできません。
トピックを作成する際にはキューの数を十分に考慮することが推奨されますが、実際の状況は満足できない場合が多く、キューの数が変わらなくてもコンシューマの数は変化します。コンシューマがオンラインまたはオフラインになったとき、コンシューマが電話を切ったとき、または新しいコンシューマが追加されたときなどに、変化が発生します。キューの拡大と縮小、およびコンシューマの拡大と縮小により、リバランスが行われます。つまり、消費キューがコンシューマに再分配されます。
RocketMQ では、コンシューマーはトピック キューの数を定期的にクエリします。コンシューマーの数が変化すると、リバランスがトリガーされます。
リバランスは RocketMQ によって内部的に実装されるため、プログラマは気にする必要はありません。
一般的に、MQ にはメッセージを取得する 2 つの方法があります:
プルでもプッシュでも、コンシューマは常にブローカーと対話します。対話方法には通常、短い接続、長い接続、ポーリングが含まれます。
RocketMQ はプルとプッシュの両方をサポートしているように見えますが、実際にはプッシュもプルを使用して実装されています。
これは RocketMQ の設計の独創的な部分で、短い接続でも長い接続でもポーリングでもなく、長いポーリングです。
コンシューマはメッセージをプルするリクエストを開始します。これは 2 つの状況に分けられます:
RocketMQ はトランザクション メッセージをサポートします。プロデューサーがトランザクション メッセージをブローカーに送信した後、ブローカーはシステム トピック: RMQ_SYS_TRANS_HALF_TOPIC## にメッセージを保存します。 #、Consumer This メッセージを消費できないようにします。
RMQ_SYS_TRANS_HALF_TOPIC メッセージを消費し、プロデューサーへのレビューを開始します。レビューには、送信済み、ロールバック、不明の 3 つのステータスがあります。
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。
実際の開発では同期方式が一般的ですが、RocketMQ のパフォーマンスを向上させたい場合は、Borker 側のパラメータ、特にディスク ブラッシング戦略とレプリケーション戦略を変更することが一般的です。
メッセージ送信時に、MessageQueueSelector を使用すると、メッセージ送信の再試行機構が無効になります。
メッセージ送信に対する応答は、次の 4 つになる可能性があります:
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}复制代码最初の状況を除き、他の状況は問題があります。メッセージが失われないようにするには、次のことが必要です。プロデューサー パラメーターを設定するには: RetryAnotherBrokerWhenNotStoreOK が true です。
メッセージの送信に失敗した場合でも、再試行時にメッセージがボーカーに送信されるため、送信が失敗する可能性が高くなります。 RockteMQ の特徴は再試行時間であり、自動的にこの Borker を回避し、他の Borker を選択しますが、これまでのところ、非同期送信はそれほどスマートではなく、1 つの Borker でのみ再試行されるため、同期送信方法を選択することを強くお勧めします。
RocketMQ は 2 つの障害回避メカニズムを提供します。パラメータ SendLatencyFaultEnable を使用して制御します。
遅延バックオフ メカニズムは非常に便利であるように見えますが、一般的に言えば、Borker 側がビジー状態であるため、Borker が利用できなくなったり、ネットワークが利用できなくなったりします。遅延バックオフのメカニズムがオンになっている場合、当初利用可能だったボーカーが一定期間回避され、他のボーカーが忙しくなり、状況がさらに悪化する可能性があります。
Consumer には、消費できる並列度を表す 2 つのパラメーターがあります。つまり、ConsumeThreadMin、## です。 # ConsumeThreadMax、コンシューマ側に蓄積されたメッセージが比較的少ない場合、コンシューマ スレッドの数は ConsumeThreadMin であるようです。コンシューマ側に蓄積されたメッセージがさらに多い場合、新しいスレッドが作成されます。コンシューマ スレッドの数が ConsumeThreadMax になるまで、消費のために自動的に開かれます。 Consumer は内部でスレッド プールを保持し、無制限のキューを使用します。つまり、ConsumeThreadMax パラメータは無効であるため、実際の開発では、ConsumeThreadMin, ConsumeThreadMax は、多くの場合、同じ値に設定されます。
%RETRY% ConsumerGroup というトピック名で再試行キューを設定し、送信する必要がある再試行キューを保存します。 ConsumerGroup に送信されます。再試行メッセージですが、再試行には一定の遅延時間が必要です。RocketMQ は、最初にトピック名 SCHEDULE_TOPIC_XXXX で遅延キューに再試行メッセージを保存することによって再試行メッセージを処理し、次にバックグラウンドでスケジュールされたタスクが以下に従って遅延されます。 %RETRY% ConsumerGroup の再試行キューに再保存します。
関連する無料学習の推奨事項: Java 基本チュートリアル
以上がついにここに...RocketMQ リテラシーの章の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



