

2020 年の新しい Java 基本面接の質問の概要


Java における ==、equals、および hashCode の違い
(その他のインタビュー質問の推奨事項: Java インタビューの質問と回答)
1, ==
Java のデータ型は 2 つのカテゴリに分類できます:
基本データ型 (プリミティブ データ型とも呼ばれます) byte、short、char、int、long、float、double、boolean を比較するには、二重等号 (==) を使用して、それらの値を比較します。
参照型 (クラス、インターフェイス、配列) (==) を使用して比較する場合、メモリ内の格納アドレスを比較するため、同じ新しいオブジェクトでない限り、比較結果は true になり、そうでない場合、比較結果は false になります。オブジェクトはヒープ上に配置され、オブジェクトの参照(アドレス)はスタック上に格納されます。まず、仮想マシンのメモリ マップとコードを確認します:
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}結果は次のようになります:
false
true

# s1 と s2 の両方に、対応するオブジェクトのアドレスが格納されます。したがって、s1== s2 を使用すると、2 つのオブジェクトのアドレス値が比較されます (つまり、参照が同じかどうか) が false になります。等号方向を呼び出すと、対応するアドレスの値が比較されるため、値は true になります。ここでは、equals() について詳しく説明する必要があります。
2.quals() メソッドの詳細説明
equals() メソッドは、他のオブジェクトがこのオブジェクトと等しいかどうかを判断するために使用されます。これは Object で定義されているため、どのオブジェクトにも equals() メソッドがあります。違いは、メソッドがオーバーライドされるかどうかです。
最初にソース コードを見てみましょう:
public boolean equals(Object obj) { return (this == obj);
}明らかに、Object は 2 つのオブジェクトのアドレス値の比較 (つまり、参照が同じかどうかの比較) を定義します。 。しかし、String での等しい () の呼び出しは、なぜアドレスではなくヒープ メモリ アドレスの値を比較するのでしょうか?ここが重要なポイントで、String、Math、Integer、Double などのカプセル化クラスがquals() メソッドを使用する場合、オブジェクト クラスのequals() メソッドはすでにカバーされています。文字列で書き換えられたequals()を見てください:
public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}書き換え後、これは内容の比較であり、以前のアドレスの比較ではなくなります。同様に、Math、Integer、Double などのクラスはすべて、内容を比較するためにquals() メソッドをオーバーライドします。もちろん、基本型は値の比較を実行します。
equals() メソッドがオーバーライドされると、hashCode() もオーバーライドされることに注意してください。一般的な hashCode() メソッドの実装によれば、等しいオブジェクトは等しいハッシュコードを持たなければなりません。なぜそうなるのでしょうか? ここでハッシュコードについて簡単に説明します。
3. hashcode() の簡単な説明
これは明らかに Java の ==、equals、hashCode の違いに関する質問ですが、なぜ突然 hashcode() に関連するのでしょうか。とても落ち込んでいるでしょう。分かりました。簡単な例を示しましょう。== または等しい場合に hashCode が関与する理由がわかるでしょう。
例: コレクションにオブジェクトが含まれているかどうかを調べたい場合、プログラムはどのように作成すればよいでしょうか? IndexOf メソッドを使用しない場合は、コレクションを走査して、思い当たるかどうかを比較してください。コレクションに 10,000 個の要素がある場合はどうなるでしょうか?そこで、効率を向上させるために、ハッシュ アルゴリズムが生まれました。中心的なアイデアは、コレクションをいくつかのストレージ領域 (バケットとして見ることができます) に分割することです。各オブジェクトはハッシュ コードを計算でき、ハッシュ コードに従ってグループ化できます。各グループは特定のストレージ領域に対応します。このようにして、オブジェクトはハッシュコードに従ってグループ化でき、そのハッシュコードは異なる記憶領域(異なる領域)に分割できます。
したがって、要素を比較するときは、実際には最初にハッシュコードが比較され、それらが等しい場合は、等しいメソッドが比較されます。
ハッシュコード図を見てください:

#オブジェクトには通常、キーと値があり、そのハッシュコード値は次のようになります。キーに基づいて計算されたキーは、上図に示すように、その hashCode 値に応じて異なる記憶領域に格納されます。ハッシュの競合が関係するため、複数の値を異なる領域に格納できます。単純: 2 つの異なるオブジェクトの hashCode が同じである場合、この現象はハッシュ競合と呼ばれます。簡単に言えば、hashCode は同じですが、equals は異なる値であることを意味します。 10,000要素を比較する場合、コレクション全体を走査する必要はなく、検索したいオブジェクトのキーのハッシュコードを計算し、そのハッシュコードに対応する記憶領域を見つけるだけで検索は終了します。

大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。
总结:
- hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
- equals重写的时候hashCode也跟着重写
- 两对象equals如果相等那么hashCode也一定相等,反之不一定。
2. int、char、long 各占多少字节数
byte 是 字节
bit 是 位
1 byte = 8 bit
char在java中是2个字节,java采用unicode,2个字节来表示一个字符
short 2个字节
int 4个字节
long 8个字节
float 4个字节
double 8个字节
3. int和Integer的区别
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
延伸: 关于Integer和int的比较
- 由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
- Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
- 非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
- 对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true
Integer i = 128; Integer j = 128; System.out.print(i == j); //false
对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <p>java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了</p><h2 id="java多态的理解">4. java多态的理解</h2><h3 id="多态概述">1.多态概述</h3><ol>
<li><p>多态是继封装、继承之后,面向对象的第三大特性。</p></li>
<li><p>多态现实意义理解:</p></li>
</ol>现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态。
Java作为面向对象的语言,同样可以描述一个事物的多种形态。如Student类继承了Person类,一个Student的对象便既是Student,又是Person。
多态体现为父类引用变量可以指向子类对象。
前提条件:必须有子父类关系。
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
- 多态的定义与使用格式
定义格式:父类类型 变量名=new 子类类型();
2.多态中成员的特点
- 多态成员变量:编译运行看左边
Fu f=new Zi();
System.out.println(f.num);//f是Fu中的值,只能取到父中的值
- 多态成员方法:编译看左边,运行看右边
Fu f1=new Zi();
System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。
3.instanceof关键字
作用:用来判断某个对象是否属于某种数据类型。
* 注意: 返回类型为布尔类型
使用案例:
Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的类型");
}else{
System.out.println("f1是Son的类型");
}4.多态的转型
多态的转型分为向上转型和向下转型两种
-
向上转型:多态本身就是向上转型过的过程
使用格式:父类类型 变量名=new 子类类型();
适用场景:当不需要面对子类类型时,通过提高扩展性,或者使用父类的功能就能完成相应的操作。
-
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用类型转为子类引用各类型
使用格式:子类类型 变量名=(子类类型)父类类型的变量;
适用场景:当要使用子类特有功能时。
5.多态案例:
例1:
package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//调用特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃饭");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好学习");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃樱桃");
}
public void teach(){
System.out.println("认真授课");
}
}答案:吃水煮肉片 好好学习
例2:
请问题目运行结果是什么?
package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}答案:A B
5. String、StringBuffer和StringBuilder区别
1、长度是否可变
- String 是被 final 修饰的,他的长度是不可变的,就算调用 String 的concat 方法,那也是把字符串拼接起来并重新创建一个对象,把拼接后的 String 的值赋给新创建的对象
- StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象,StringBuffer 与 StringBuilder 中的方法和功能完全是等价的。调用StringBuffer 的 append 方法,来改变 StringBuffer 的长度,并且,相比较于 StringBuffer,String 一旦发生长度变化,是非常耗费内存的!
2、执行效率
- 三者在执行速度方面的比较:StringBuilder > StringBuffer > String
3、应用场景
- 如果要操作少量的数据用 = String
- 单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
- 多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
StringBuffer和StringBuilder区别
1、是否线程安全
- StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问),StringBuffer是线程安全的。只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
2、应用场景
- 由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。
- 然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。 append方法与直接使用+串联相比,减少常量池的浪费。
6. 什么是内部类?内部类的作用
内部类的定义
将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。
内部类的作用:
成员内部类 成员内部类可以无条件访问外部类的所有成员属性和成员方法(包括private成员和静态成员)。 当成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。
局部内部类 局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
匿名内部类 匿名内部类就是没有名字的内部类
静态内部类 指被声明为static的内部类,他可以不依赖内部类而实例,而通常的内部类需要实例化外部类,从而实例化。静态内部类不可以有与外部类有相同的类名。不能访问外部类的普通成员变量,但是可以访问静态成员变量和静态方法(包括私有类型) 一个 静态内部类去掉static 就是成员内部类,他可以自由的引用外部类的属性和方法,无论是静态还是非静态。但是不可以有静态属性和方法
(学习视频推荐:java课程)
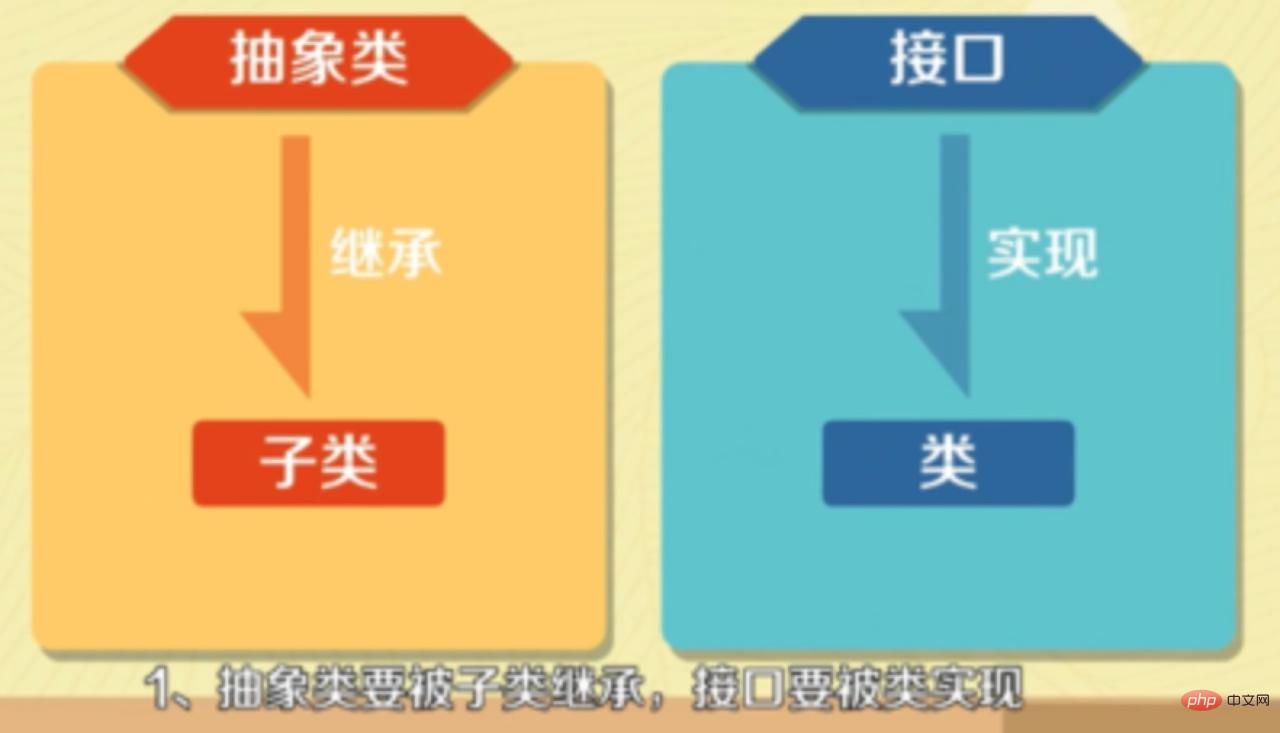
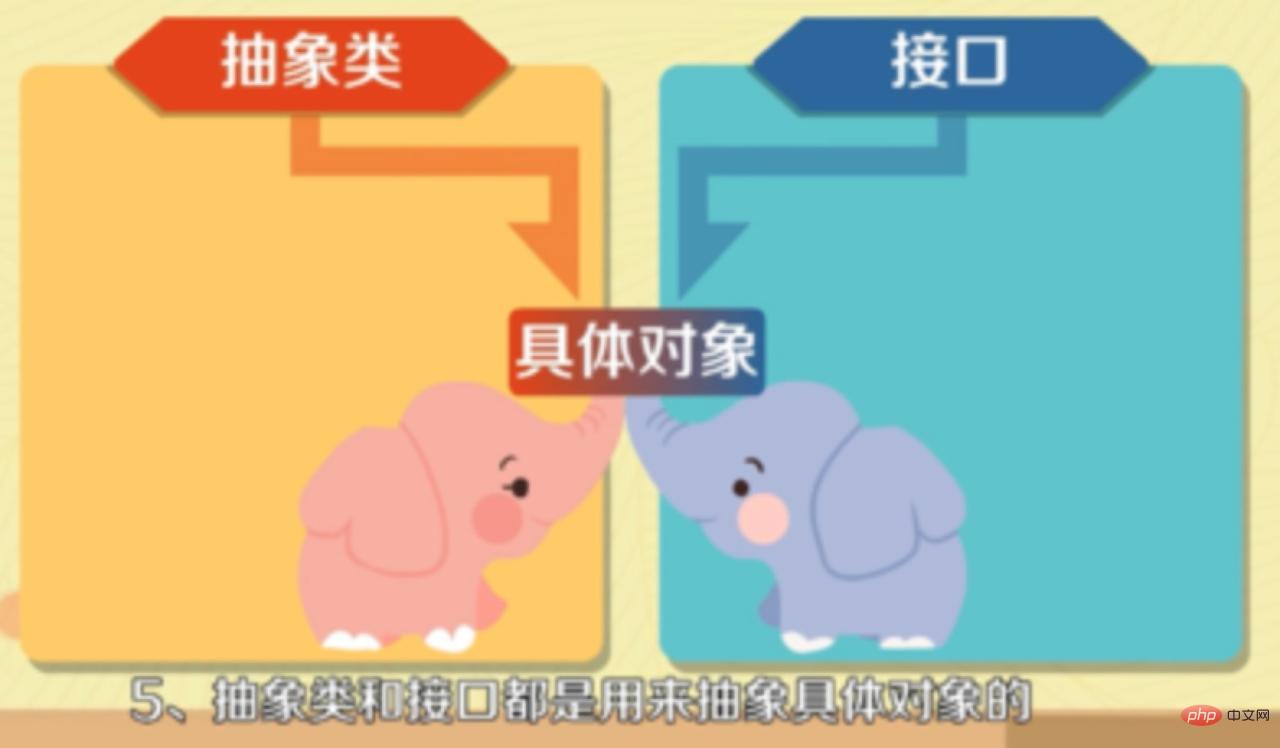
7. 抽象クラスとインターフェイスの違い
- 抽象クラスはサブクラスによって継承され、インターフェイスはクラスによって実装される必要があります。
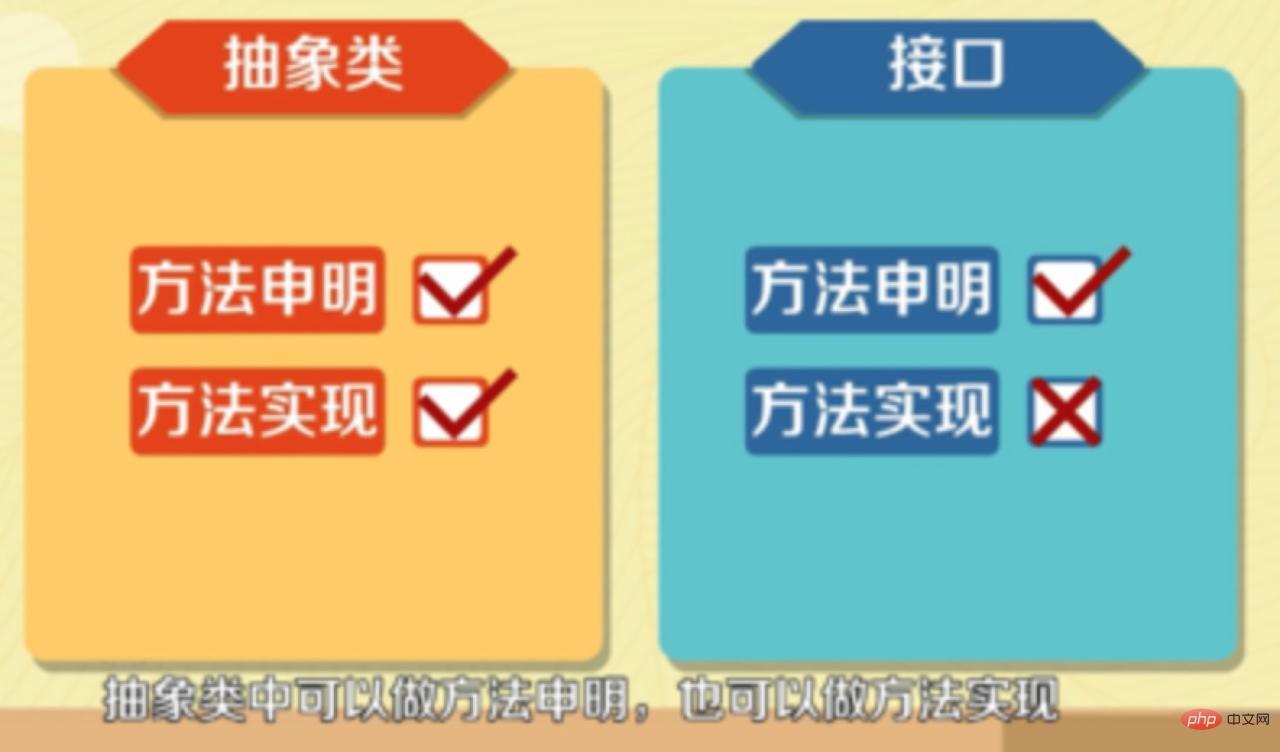
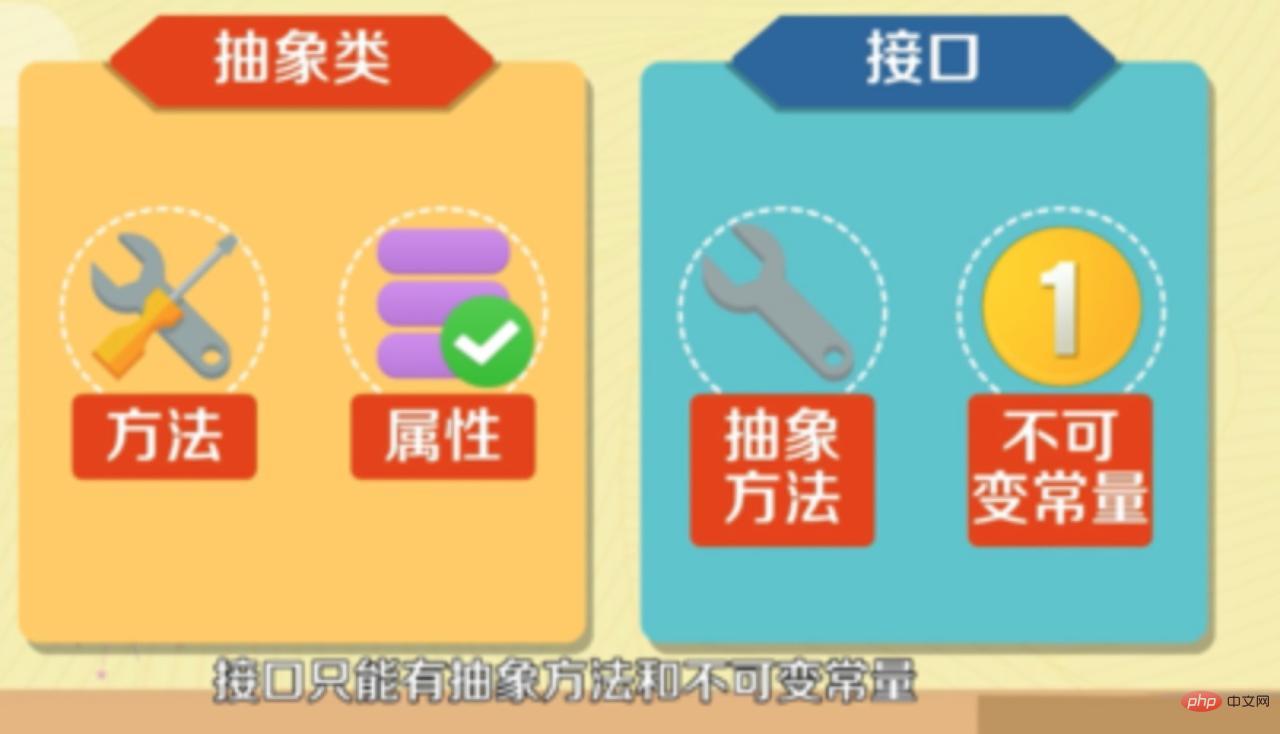
 #インターフェースはメソッド宣言のみを行うことができますが、抽象クラスはメソッド宣言とメソッド実装を行うことができます。
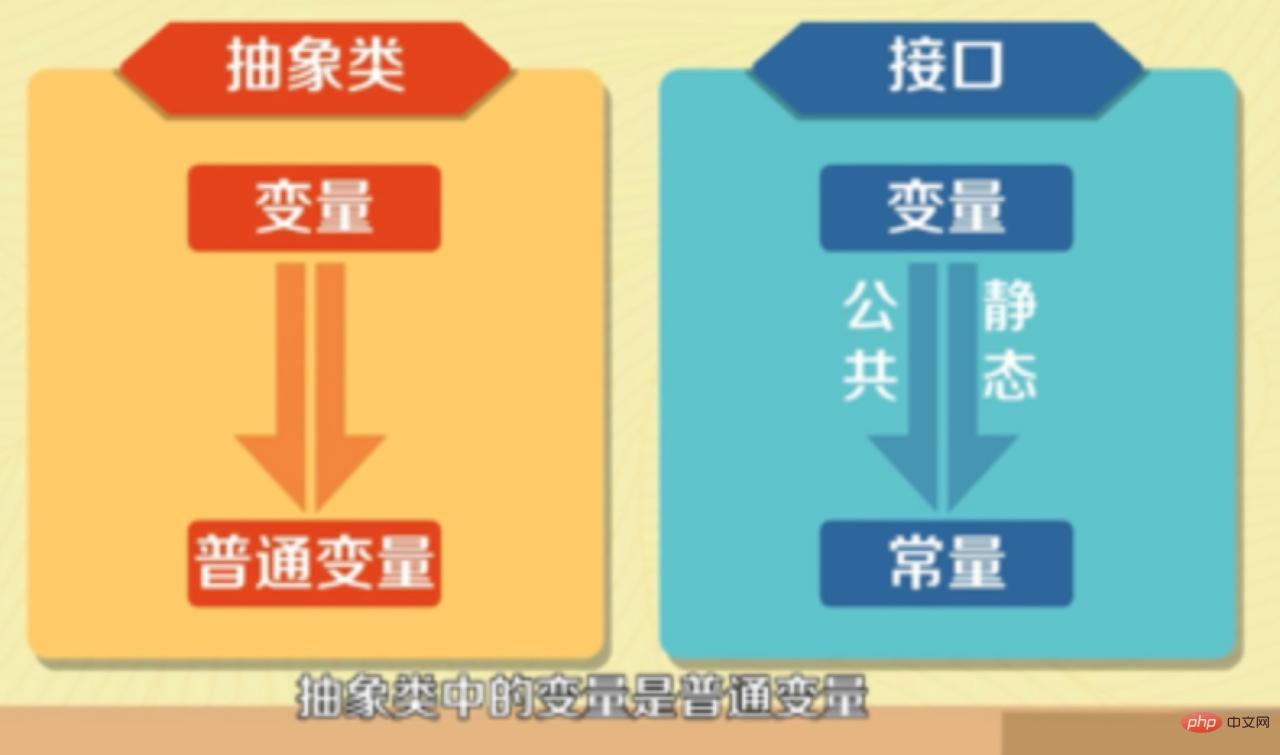
#インターフェースはメソッド宣言のみを行うことができますが、抽象クラスはメソッド宣言とメソッド実装を行うことができます。 - インターフェースで定義される変数はパブリック静的定数のみであり、抽象クラスの変数は通常の変数です。
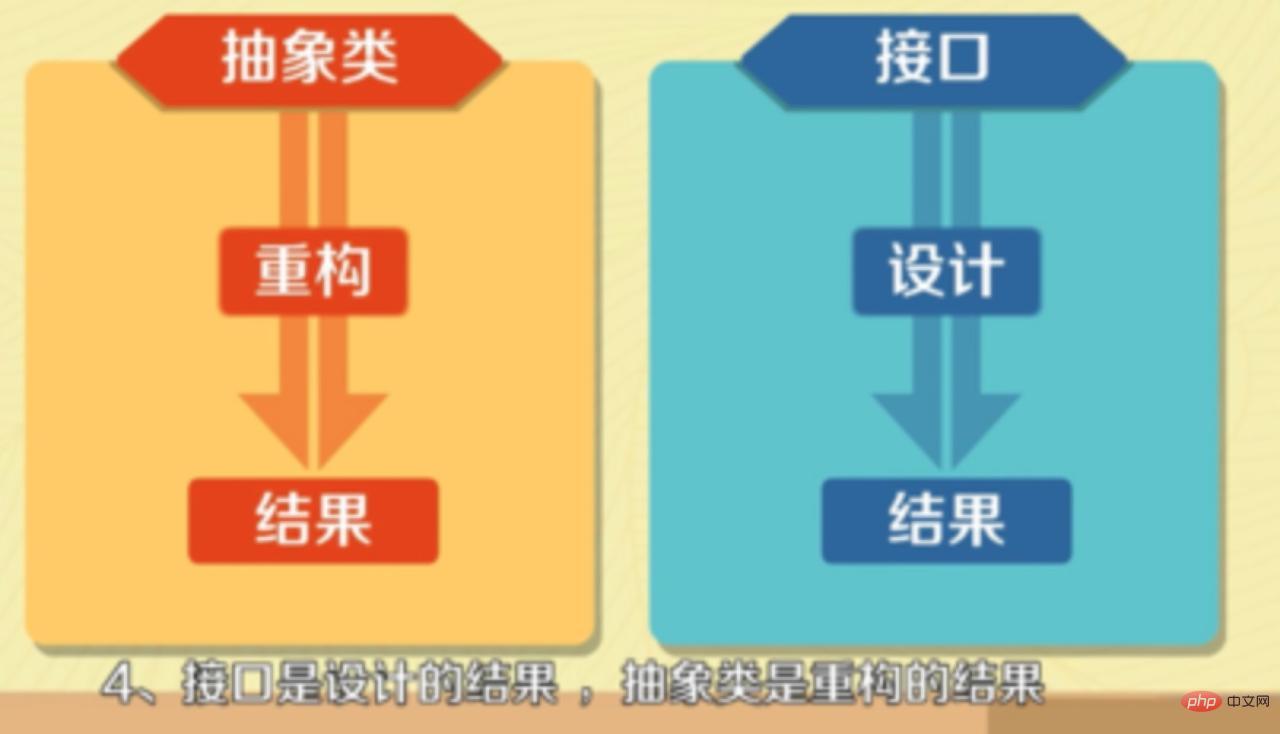
- インターフェースは設計の結果であり、抽象クラスはリファクタリングの結果です。
-
-
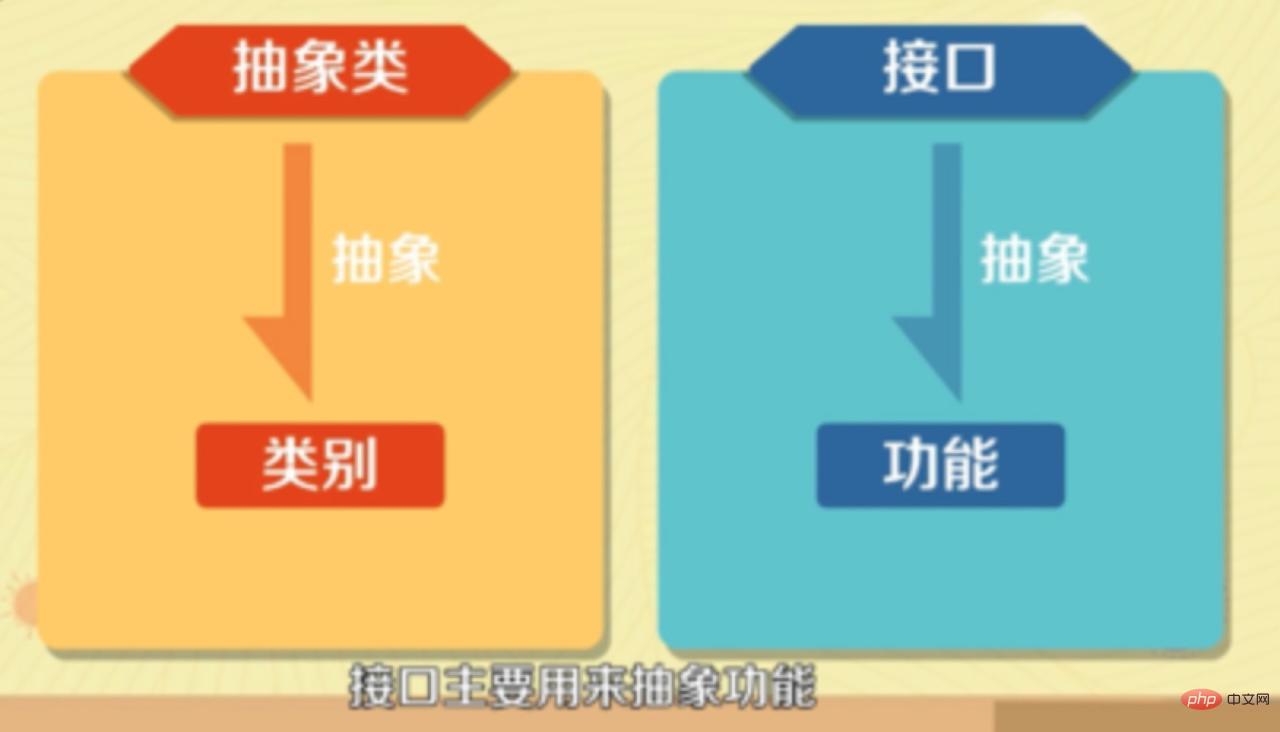
#抽象クラスは主にカテゴリを抽象化するために使用され、インターフェイスは主に関数を抽象化するために使用されます。 #8. 抽象クラスの意味 抽象クラス:
クラスに抽象メソッドが含まれる場合、そのクラスは、abstract キーワードを使用して抽象クラスとして宣言する必要があります。
サブクラスのパブリック型を提供します;
繰り返しのコンテンツ (メンバー変数とメソッド) をサブクラスにカプセル化します ;- は抽象メソッドを定義します。サブクラスの実装は異なりますが、このメソッドの定義は一貫しています。
- 9. 抽象クラスとインターフェイスのアプリケーション シナリオ
- 1. インターフェイスのアプリケーション シナリオ:
- クラスのグループを単一のクラスとして扱う必要があり、呼び出し元はインターフェイスを通じてのみこのクラスのグループにアクセスします。
- 特定の複数の関数を実装する必要がありますが、これらの関数はまったく関連していない可能性があります。
- 2. 抽象クラス (abstract.class) の適用場面:
- つまり、統一インターフェイスとインスタンス変数またはデフォルトメソッドの両方が必要な場合に使用できます。 。最も一般的なものは次のとおりです。
- 相互に調整されたメソッドのセットを指定します。その一部は共通で状態に依存せず、サブクラスが個別に実装する必要なく共有できますが、他のメソッドは各サブクラスがそのメソッドに従って実装する必要があります。特定の機能を実現するための独自の特定の状態
- 10. 抽象クラスはメソッドや属性を持たないことはできますか?
- #答えは「はい」です。
11. 接口的意义
- 定义接口的重要性:在Java编程,abstract class 和interface是支持抽象类定义的两种机制。正是由于这两种机制的存在,才使得Java成为面向对象的编程语言。
- 定义接口有利于代码的规范:对于一个大型项目而言,架构师往往会对一些主要的接口来进行定义,或者清理一些没有必要的接口。这样做的目的一方面是为了给开发人员一个清晰的指示,告诉他们哪些业务需要实现;同时也能防止由于开发人员随意命名而导致的命名不清晰和代码混乱,影响开发效率。
- 有利于对代码进行维护:比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。可是在不久将来,你突然发现现有的类已经不能够满足需要,然后你又要重新设计这个类,更糟糕是你可能要放弃这个类,那么其他地方可能有引用他,这样修改起来很麻烦。如果你一开始定义一个接口,把绘制功能放在接口里,然后定义类时实现这个接口,然后你只要用这个接口去引用实现它的类就行了,以后要换的话只不过是引用另一个类而已,这样就达到维护、拓展的方便性。
- 保证代码的安全和严密:一个好的程序一定符合高内聚低耦合的特征,那么实现低耦合,定义接口是一个很好的方法,能够让系统的功能较好地实现,而不涉及任何具体的实现细节。这样就比较安全、严密一些,这一思想一般在软件开发中较为常见。
12. Java泛型中的extends和super理解
在平时看源码的时候我们经常看到泛型,且经常会看到extends和super的使用,看过其他的文章里也有讲到上界通配符和下届通配符,总感觉讲的不够明白。这里备注一下,以免忘记。
- extends也成为上界通配符,就是指定上边界。即泛型中的类必须为当前类的子类或当前类。
- super也称为下届通配符,就是指定下边界。即泛型中的类必须为当前类或者其父类。
这两点不难理解,extends修饰的只能取,不能放,这是为什么呢? 先看一个列子:
public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List extends Fruit> list){
//报错,extends为上界通配符,只能取值,不能放.
//因为Fruit的子类不只有Apple还有Banana,这里不能确定具体的泛型到底是Apple还是Banana,所以放入任何一种类型都会报错
//list.add(new Apple());
//可以正常获取
Fruit fruit = list.get(1);
}
public void testSuper(List super Fruit> list){
//super为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲,
//无法确定Fruit的父类是否只有Food一个(Object是超级父类)
//因此放入Food的实例编译不通过
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}在testExtends方法中,因为泛型中用的是extends,在向list中存放元素的时候,我们并不能确定List中的元素的具体类型,即可能是Apple也可能是Banana。因此调用add方法时,不论传入new Apple()还是new Banana(),都会出现编译错误。
理解了extends之后,再看super就很容易理解了,即我们不能确定testSuper方法的参数中的泛型是Fruit的哪个父类,因此在调用get方法时只能返回Object类型。结合extends可见,在获取泛型元素时,使用extends获取到的是泛型中的上边界的类型(本例子中为Fruit),范围更小。
总结:在使用泛型时,存取元素时用super,获取元素时,用extends。
13. 父类的静态方法能否被子类重写
不能,父类的静态方法能够被子类继承,但是不能够被子类重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。
class Fruit{
static String color = "五颜六色";
static public void call() {
System.out.println("这是一个水果");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五颜六色
fruit.call(); //这是一个水果
}
}如代码所示,如果能够被重写,则输出的应该是这是一个香蕉。与此类似的是,静态变量也不能够被重写。如果想要调用父类的静态方法,应该使用类来调用。 那为什么会出现这种情况呢? 我们要从重写的定义来说:
重写指的是根据运行时对象的类型来决定调用哪个方法,而不是根据编译时的类型。
对于静态方法和静态变量来说,虽然在上述代码中使用对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。
静态属性和静态方法是否可以被继承
可以被继承,如果子类中有相同的静态方法和静态变量,那么父类的方法以及变量就会被覆盖。要想调用就就必须使用父类来调用。
class Fruit{
static String color = "五颜六色";
static String xingzhuang = "奇形怪状";
static public void call() {
System.out.println("这是一个水果");
}
static public void test() {
System.out.println("这是没有被子类覆盖的方法");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //这是没有被子类覆盖的方法
banana.call(); //调用Banana类中的call方法 这是一个香蕉
Fruit.call(); //调用Fruit类中的方法 这是一个水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪状 黄色
}
}从上述代码可以看出,子类中覆盖了父类的静态方法的话,调用的是子类的方法,这个时候要是还想调用父类的静态方法,应该是用父类直接调用。如果子类没有覆盖,则调用的是父类的方法。静态变量与此相似。
14. スレッドとプロセスの違い
- 定義: プロセスは、特定のデータ収集に対するプログラムの実行アクティビティであり、スレッドはプロセス内の実行パスです。 (プロセスは複数のスレッドを作成できます)
- 役割の側面: スレッド機構をサポートするシステムでは、プロセスはシステムリソース割り当ての単位であり、スレッドは CPU スケジューリングの単位です。
- リソース共有: プロセス間でリソースを共有することはできませんが、スレッドは、スレッドが配置されているプロセスのアドレス空間と他のリソースを共有します。同時に、スレッドは独自のスタック、スタック ポインター、プログラム カウンター、その他のレジスターも持ちます。
- 独立性の観点: プロセスには独自の独立したアドレス空間がありますが、スレッドにはありません。スレッドが存在するにはプロセスに依存する必要があります。
- オーバーヘッドの観点から。プロセス切り替えにはコストがかかります。スレッドは比較的小さいです。 (前述したように、スレッドの導入はコストの観点からも行われます。)
次の記事を読むことができます: juejin.im/post/684490…
15. 違いFinal、finally、finalize の間
- #final は、プロパティ、メソッド、クラスの宣言に使用されます。これは、それぞれ、プロパティが不変、メソッドがオーバーライドできない、クラスが継承できないことを意味します。
- finally は例外処理です。ステートメント構造の一部であり、常に実行されることを示します。
- finalize は Object クラスのメソッドです。リサイクルされたオブジェクトのこのメソッドは、ガベージ コレクターの実行時に呼び出されます。このメソッドをオーバーライドして、ガベージ コレクション中に他の機能を提供することができます。リソースのリサイクル (ファイルを閉じるなど)
方法 1: Serializable、渡されるクラスはオブジェクトを渡す Serializable インターフェイスを実装します。 方法 2: Parcelable。転送されるクラスは、オブジェクトを転送するための Parcelable インターフェイスを実装します。
Serializable (Java に付属): Serializable はシリアル化を意味し、オブジェクトを保存可能または送信可能な状態に変換することを意味します。シリアル化されたオブジェクトは、ネットワーク経由で送信したり、ローカルに保存したりできます。 Serializable はタグ付きインターフェイスです。つまり、Java はメソッドを実装せずにこのオブジェクトを効率的にシリアル化できます。
Parcelable (Android 固有): Android の Parcelable の本来の設計意図は、プログラム内の異なるコンポーネント間およびコンポーネント間の通信を容易にするために、Serializable が (リフレクションを使用して) 遅すぎるためです。さまざまな Android プログラム (AIDL) メモリ内にのみ存在するデータを効率的に転送するように設計されています。 Parcelableメソッドの実装原理は完全なオブジェクトを分解することであり、分解後の各部分はIntentがサポートするデータ型となることでオブジェクトを渡す機能を実現している。
効率と選択:Parcelable のパフォーマンスは Serializable よりも優れています。後者はリフレクション プロセス中に頻繁に GC を実行するため、メモリ間でデータを転送する場合は Parcelable を使用することをお勧めします。アクティビティ間のデータ転送など。 Serializable は簡単に保存できるようにデータを永続化できるため、ネットワーク経由でデータを保存または送信する必要がある場合は Serializable を選択してください。Parcelable は Android のバージョンによって異なる場合があるため、データの永続化に Parcelable を使用することはお勧めできません。 Parcelable は、外界が変化したときにデータの永続性を保証できないため、データをディスクに保存する場合には使用できません。 Serializable は効率が劣りますが、現時点では Serializable を使用することをお勧めします。 インテントを介して複雑なデータ型を渡す場合、2 つのインターフェイスのいずれかを最初に実装する必要があります。対応するメソッドは getSerializableExtra() と getParcelableExtra() です。 17. 静的プロパティと静的メソッドは継承できますか?書き換えることはできますか?なぜ?親クラスの静的プロパティとメソッドは、サブクラスに継承できます。
は、サブクラスによってオーバーライドできません。 :親クラスがサブクラスを指す オブジェクトを使用して静的メソッドまたは静的変数を呼び出す場合、親クラスのメソッドまたは変数が呼び出されます。サブクラスによってオーバーライドされません。
理由:
プログラムの実行開始以来、静的メソッドがメモリを割り当てているため、つまりハードコーディングされているためです。このメソッドを参照するすべてのオブジェクト (親クラスのオブジェクトまたはサブクラスのオブジェクト) は、メモリ内の同じデータ部分 (静的メソッド) を指します。 同じ名前の静的メソッドがサブクラスに定義されている場合、それはオーバーライドされず、メモリ上の別の静的メソッドがサブクラスに割り当てられる必要があり、書き換えなどは行われません。 18 .java の静的内部クラスの設計意図内部クラス内部クラスは、クラス内で定義されたクラスです。なぜ内部クラスがあるのでしょうか? Java では、クラスは単一継承であり、クラスは別の具象クラスまたは抽象クラス (複数のインターフェイスを実装できる) のみを継承できることがわかっています。この設計の目的は、多重継承において、複数の親クラスに重複した属性やメソッドがある場合、サブクラスの呼び出し結果があいまいになるため、単一継承を使用することです。内部クラスを使用する理由は、各内部クラスが独立して (インターフェース) 実装を継承できるため、外部クラスが (インターフェース) 実装を継承したかどうかに関係なく、内部クラスには影響を与えないためです。
私たちのプログラミングでは、インターフェイスを使用して解決するのが難しい問題が発生することがあります。このとき、内部クラスによって提供される機能を使用して、複数の具象クラスまたは抽象クラスを継承することで、これらのプログラムを解決できます。設計上の問題。インターフェイスは問題の一部を解決するだけであり、内部クラスは多重継承の解決策をより完全にするものであると言えます。
静的内部クラス
静的内部クラスについて説明する前に、まずメンバーの内部クラス (非静的内部クラス) について理解してください。
メンバー内部クラス
メンバー内部クラスは最も一般的な内部クラスでもあり、外部クラスのメンバーであるため、すべてのクラスに無制限にアクセスできます。外部クラス: メンバーの属性とメソッドはプライベートですが、外部クラスが内部クラスのメンバー属性とメソッドにアクセスしたい場合は、内部クラスのインスタンスを通じてアクセスする必要があります。
メンバーの内部クラスでは 2 つの点に注意する必要があります:
メンバーの内部クラスには静的変数とメソッドを含めることはできません。
-
メンバーの内部クラスは外部クラスにアタッチされるため、内部クラスは外部クラスが最初に作成された後にのみ作成できます。
静的内部クラス
静的内部クラスと非静的内部クラスの間には、最大の違いが 1 つあります。それは、非静的内部クラスはコンパイルされることです。コンパイル後、参照はそれが作成された外部の世界に対して暗黙的に保持されますが、静的な内部クラスは保持しません。
この参照がないことは、次のことを意味します。
その作成は周辺クラスに依存する必要はありません。
非静的メンバー変数や周辺クラスのメソッドは使用できません。
ローカル内部クラス
ローカル内部クラスは次のとおりです。メソッドとスコープ内にネストされているこのクラスの使用は、主に、より複雑な問題を適用して解決することです。解決策を支援するクラスを作成したいと考えていますが、それまでにこのクラスを公開したくないので、ローカルの内部クラスが生成されます。ローカル内部クラスはメンバー内部クラスと同様にコンパイルされますが、スコープが変わります。このメソッドおよび属性でのみ使用でき、メソッドおよび属性が削除されると無効になります。匿名内部クラス
- 匿名内部クラスにはアクセス修飾子がありません。
- new 匿名の内部クラス。このクラスは最初に存在する必要があります。
- メソッドの仮パラメータを匿名内部クラスで使用する必要がある場合、仮パラメータはfinalである必要があります。
- 匿名の内部クラスには明示的なコンストラクターがなく、コンパイラーは外部クラスを参照するコンストラクターを自動的に生成します。
以上が2020 年の新しい Java 基本面接の質問の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7720
7720
 15
1642
14
1396
52
1289
25
1233
29
15
1642
14
1396
52
1289
25
1233
29

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP and Python each have their own advantages, and the choice should be based on project requirements. 1.PHPは、シンプルな構文と高い実行効率を備えたWeb開発に適しています。 2。Pythonは、簡潔な構文とリッチライブラリを備えたデータサイエンスと機械学習に適しています。
 PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHPは、サーバー側で広く使用されているスクリプト言語で、特にWeb開発に適しています。 1.PHPは、HTMLを埋め込み、HTTP要求と応答を処理し、さまざまなデータベースをサポートできます。 2.PHPは、ダイナミックWebコンテンツ、プロセスフォームデータ、アクセスデータベースなどを生成するために使用され、強力なコミュニティサポートとオープンソースリソースを備えています。 3。PHPは解釈された言語であり、実行プロセスには語彙分析、文法分析、編集、実行が含まれます。 4.PHPは、ユーザー登録システムなどの高度なアプリケーションについてMySQLと組み合わせることができます。 5。PHPをデバッグするときは、error_reporting()やvar_dump()などの関数を使用できます。 6. PHPコードを最適化して、キャッシュメカニズムを使用し、データベースクエリを最適化し、組み込み関数を使用します。 7
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
