

mysql チュートリアル コラムでは、今日のインデックス関連の知識を紹介します。

MySQL シリーズの 2 番目の記事では、インデックス タイプ、データ モデル、インデックス実行プロセス、左端のプレフィックス原則など、MySQL のインデックス作成に関するいくつかの問題について主に説明します。 、インデックスの失敗とインデックスのプッシュダウンなど。
私が初めてインデックスについて学んだのは、2 年生のデータベース原理コースでした。クエリ ステートメントが非常に遅い場合は、特定のフィールドにインデックスを追加することでクエリの効率を向上させることができます# ##。
もう 1 つの非常に古典的な例があります: データベースを辞書、インデックスをディレクトリと考えることができます。辞書のディレクトリを使用して単語をクエリすると、インデックスの役割が反映されます。 。 1. インデックスの種類MySQL では、インデックスのロジックやフィールドの特性に基づいて、インデックスは通常のインデックス、一意のインデックス、主キー インデックス、 Union インデックスとプレフィックス インデックス。さらに、フルテキスト インデックスがあり、逆インデックスを確立することで、フィールドが含まれているかどうかを判断する問題を解決します。
転置インデックスは、全文検索対象の文書または文書グループ内の単語の格納場所のマッピングを保存するために使用されます。転置インデックスを通じて、次の内容を含む文書のリストを迅速に取得できます。この言葉をもとにしたこの言葉。
キーワードで検索する場合、全文インデックスが便利です。
これは比較的単純な B ツリーです。
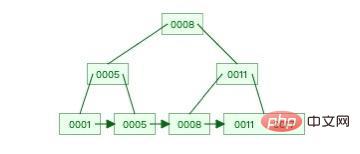
画像ソース: Data Structure Visualizations
上記のサンプル画像からも、この B ツリーの下部にあることがわかります。リーフ ノードはすべての要素を順番に保存しますが、非リーフ ノードはインデックス列の値のみを保存します。
InnoDB では、BTree に基づくインデックス モデルが最も一般的に使用されますが、ここでは InnoDB の BTree インデックスの構造を示す実際の例を示します。
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(36) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `nameIndex`(`name`) USING BTREE ) ENGINE = InnoDB;-- 插入数据insert into user1(id,name,age) values (1,'one',21),(2,'two',22),(3,'three',23),(4,'four',24),(5,'five',25);复制代码
このテーブルには 2 つのフィールドしかありません。主キー ID と名前フィールドです。また、インデックス列として名前フィールドを持つ BTree インデックスが確立されます。
主キー ID フィールドに基づくインデックスは主キー インデックスとも呼ばれ、そのインデックス ツリー構造は次のとおりです: インデックス ツリーの非リーフ ステージには主キー ID の値が格納され、その値はリーフ ノードに格納されるのは、次の図に示すように、主キー id に対応するデータ行全体です。主キー インデックスのリーフ ノードには、対応する主キー ID が格納されます。 データ行全体である主キー インデックスは、クラスター化インデックスとも呼ばれます。
名前フィールドを列として持つインデックス ツリーでは、非リーフ ノードもインデックス列の値を格納し、リーフ ステージに格納される値は 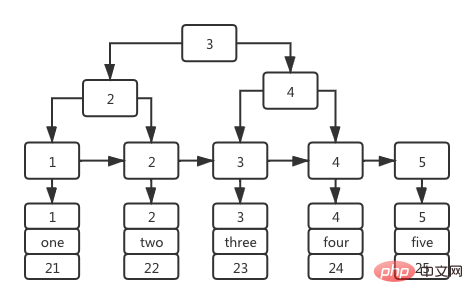 主キーの値です。 id
主キーの値です。 id
3.3 インデックス実行プロセス
まず、ユーザー テーブルの id=1 のデータ行をクエリする次の SQL 文を見てください。 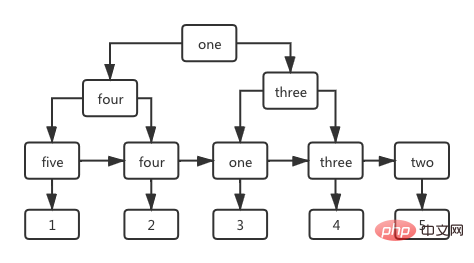
select * from user where id=1;复制代码
select * from user where name='one';复制代码
その後、ストレージ エンジンは、name='one'
を満たさない最初のレコードが見つかるまでインデックス ツリーの検索を続け、最終的にヒットしたすべてのレコードをクライアントに返します。 。 通常のインデックス からクエリされた主キー ID 値に基づいて、主キー インデックス内のデータ行全体をクエリするプロセスを と呼び、テーブル リターンと呼びます。
3.3.2 インデックスのカバー
前の table return の質問に次のような記述があることに気づいたかどうかわかりませんが、「クエリ ステートメントで主キーをクエリする必要がある場合」 ID とインデックス列 "... 以外のフィールド" このシナリオでは、テーブルを返すことによって他のクエリ フィールドを取得する必要があります。言い換えれば、クエリ ステートメントで主キー ID とインデックス列のフィールドのみをクエリする必要がある場合、テーブルを返す必要はありません。 このプロセスを分析してみましょう。まず、結合インデックスを作成します。alter table user add index name_age ('name','age');复制代码結合インデックス インデックス ツリーの子ノードの順序は次のとおりです。ソートするには、
order by name, age と似ており、通常のインデックスと同様に、そのインデックスに対応する値が主キーの値になります。 
select name,age from user where name='one';复制代码
上面这条 SQL 是查询所有 name='one' 记录的 name 和 age 字段,理想的执行计划应该是搜索刚刚建立的联合索引。
与普通索引一样,存储引擎会搜索联合索引,由于联合索引的顺序是先按照 name 再按照 age 进行排序的,所以当找到第一个 name 不是 one 的索引时,才会停止搜索。
而由于 SQL 语句查询的只是 name 和 age 字段,恰好存储引擎命中查询条件时得到的数据正是 name, age 和 id 字段,已经包含了客户端需要的字段了,所以就不需要再回表了。
我们把只需要在一棵索引树上就可以得到查询语句所需要的所有字段的索引成为覆盖索引,覆盖索引无须进行回表操作,速度会更快一些,所以我们在进行 SQL 优化时可以考虑使用覆盖索引来优化。
上面所举的例子都是使用索引的情况,事实上在项目中复杂的查询语句中,也可能存在不使用索引的情况。首先我们要知道,MySQL 在执行 SQL 语句的时候一张表只会选择一棵索引树进行搜索,所以一般在建立索引时需要尽可能覆盖所有的查询条件,建立联合索引。
而对于联合索引,MySQL 会遵循最左前缀原则:查询条件与联合索引的最左列或最左连续多列一致,那么就可以使用该索引。
为了详细说明最左前缀原则,同时说明最左前缀原则的一些特殊情况。
即便我们根据最左前缀的原则创建了联合索引,还是会有一些特殊的场景会导致索引失效,下面举例说明。
假设有一张 table 表,它有一个联合索引,索引列为 a,b,c 这三个字段,这三个字段的长度均为10。
CREATE TABLE `demo` ( `a` varchar(1) DEFAULT NULL, `b` varchar(1) DEFAULT NULL, `c` varchar(1) DEFAULT NULL, INDEX `abc_index`(`a`, `b`, `c`) USING BTREE ) ENGINE = InnoDB;复制代码
第一种情况是查询条件与索引字段全部一致,并且用的是等值查询,如:
select * from demo where a='1' and b='1' and c='1';select * from demo where c='1' and a='1' and b='1';复制代码
输出上述两条 SQL 的执行计划来看它们使用索引的情况。
mysql> explain select * from demo where a='1' and b='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where c='1' and a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 18 | const,const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)复制代码
第一条 SQL 很显然能够用到联合索引。
从执行计划中可以看到,第二条 SQL 与第一条 SQL 使用的索引以及索引长度是一致的,都是使用 abc_index 索引,索引长度为 18 个字节。
按理说查询条件与索引的顺序不一致,应该不会用到索引,但是由于 MySQL 有优化器存在,它会把第二条 SQL 优化成第一条 SQL 的样子,所以第二条 SQL 也使用到了联合索引 abc_index。
综上所述,全字段匹配且为等值查询的情况下,查询条件的顺序不一致也能使用到联合索引。
第二种情况是查询条件与索引字段部分保持一致,这里就需要遵循最左前缀的原则,如:
select * from demo where a='1' and b='1';select * from demo where a='1' and c='1';复制代码
上述的两条查询语句分别对应三个索引字段只用到两个字段的情况,它们的执行计划是:
mysql> explain select * from demo where a='1' and b='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 12 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------------+------+----------+-------------+1 row in set, 1 warning (0.00 sec) mysql> explain select * from demo where a='1' and c='1'; +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | ref | abc_index | abc_index | 6 | const | 1 | 100.00 | Using where; Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从它们的执行计划可以看到,这两条查询语句都使用到了 abc_index 索引,不同的是,它们使用到索引的长度分别是:12、6 字节。
在这里需要额外提一下索引长度的计算方式,对于本例中声明为 varchar(1) 类型的 a 字段,它的索引长度= 1 * (3) + 1 + 2 = 6。
所以这两条查询语句使用索引的情况是:
由此可见:最左前缀原则要求,查询条件必须是从索引最左列开始的连续几列。
第三种情况是查询条件用的是范围查询(,!=,=,between,like)时,如:
select * from demo where a='1' and b!='1' and c='1';复制代码
这两条查询语句的执行计划是:
mysql> EXPLAIN select * from demo where a='1' and b!='1' and c='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 12 | NULL | 2 | 10.00 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+--------------------------+1 row in set, 1 warning (0.00 sec)复制代码
从执行计划可以看到,第一条 SQL 使用了联合索引,且索引长度为 12 字节,即用到了 a,b 两个字段;第二条 SQL 也使用了联合索引,索引长度为 6 字节,仅使用了联合索引中的 a 字段。
综上所述,在全字段匹配且为范围查询的情况下,也能使用联合索引,但只能使用到联合索引中第一个出现范围查询条件的字段。
需要注意的是:
第四种情况是查询条件中带有函数或特殊表达式的,比如:
select * from demo where id + 1 = 2;select * from demo where concat(a, '1') = '11';复制代码
可能由于数据的原因(空表),我输出的执行计划是使用了联合索引的,但是事实上,在查询条件中,等式不等式左侧的字段包含表达式或函数时,该字段是不会用到索引的。
至于原因,是因为使用函数或表达式的情况下,索引字段本身的值已不具备有序性。
上文中已经罗列了联合索引的实际结构、最左前缀原则以及索引失效的场景,这里再说一下索引下推这个重要的优化规则。
select * from demo where a > '1' and b='1'; mysql> explain select * from demo where a > '1' and b='1'; +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+| 1 | SIMPLE | demo | NULL | range | abc_index | abc_index | 6 | NULL | 1 | 10.00 | Using index condition | +----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)复制代码
上面这条查询语句,从它的执行计划也可以看出,它使用的索引长度为 6 个字节,只用到了第一个字段。
所以 MySQL 在查询过程中,只会对第一个字段 a 进行 a > '1' 的条件判断,当满足条件后,存储引擎并不会进行 b=1 的判断, 而是通过回表拿到整个数据行之后再进行判断。
这好像很蠢,就算索引只用到了第一个字段,但明明索引树中就有 b 字段的数据,为什么不直接进行判断呢?
听上去好像是个 bug,其实在未使用索引下推之前整个查询逻辑是:由存储引擎检索索引树,就算索引树中存在 b 字段的值,但由于这条查询语句的执行计划使用了联合索引但没有用到 b 字段,所以也无法进行 b 字段的条件判断,当存储引擎拿到满足条件(a>'1')的数据后,再由 MySQL 服务器进行条件判断。
在 MySQL5.6 版本中对这样的情况进行优化,引入索引下推技术:在搜索索引树的过程中,就算没能用到联合索引的其他字段,也能优先对查询条件中包含且索引也包含的字段进行判断,减少回表次数,提高查询效率。
在使用索引下推优化之后,b 字段作为联合索引列,又存在于查询条件中,同时又没有在搜索索引树时被使用到,MySQL 服务器会把查询条件中关于 b 字段的部分也传给存储引擎,存储引擎会在搜索索引树命中数据之后再进行 b 字段查询条件的判断,满足的才会加入结果集。
Ps: 执行计划中 Extra 字段的值包含 Using index condition 就代表使用到了索引下推。
更多相关免费学习推荐:mysql教程(视频)
以上がMySQL についての私の理解パート 2: インデックスの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



