
Java 基本チュートリアルこのコラムでは、何兆ものデータを移行する方法を紹介します。

興業の『西遊記』には、次のような非常に有名なセリフがあります。 「目の前の関係を大切にせず、それを失ったとき後悔しました。世界で最もつらいことは、これです。神が私にもう一度チャンスを与えてくれるなら、私はどんな女の子にも三言言います。愛しています。もし私が持っているなら」この愛にタイムリミットを付けて、一万年であってほしい!」開発者の目には、この感情はデータベースのデータと同じです。一万年続いてほしいと願っています。会社が発展し続け、ビジネスが変化し続けるにつれて、データに対する要件も常に変化しています。次のような状況が考えられます:
実際の事業開発では、状況に応じて移行計画を立てていきますが、次にデータの移行方法について説明します。
データ移行は一夜にして完了するものではありません。各データ移行には長い時間がかかり、1 週間または数か月かかる場合があります。一般的に、データを移行します。プロセスは基本的に次のとおりです。下の写真: 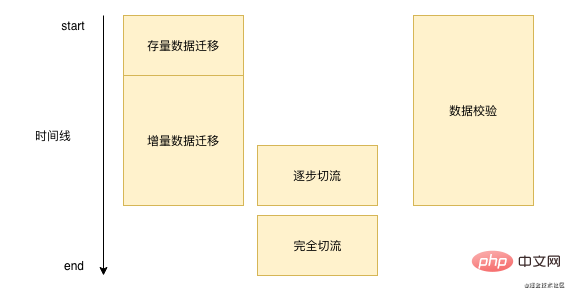 '
まず、データベース内の既存のデータをバッチ移行する必要があります。次に、新しいデータを処理する必要があります。元のデータベースを書き込んだ後、データのこの部分を新しいストレージにリアルタイムで書き込む必要があります。プロセス中にデータを継続的に検証します。基本的な問題が深刻でないことを確認したら、ストリームの切断操作を実行します。ストリームが完全に切断された後は、データ検証と増分データ移行を実行する必要はなくなります。
'
まず、データベース内の既存のデータをバッチ移行する必要があります。次に、新しいデータを処理する必要があります。元のデータベースを書き込んだ後、データのこの部分を新しいストレージにリアルタイムで書き込む必要があります。プロセス中にデータを継続的に検証します。基本的な問題が深刻でないことを確認したら、ストリームの切断操作を実行します。ストリームが完全に切断された後は、データ検証と増分データ移行を実行する必要はなくなります。
まず、株式データの移行方法について説明します。オープンソース コミュニティで株式データの移行を検索したところ、簡単に実行できる方法は存在しないことがわかりました。現在、Alibaba The Cloud の DTS は既存のデータ移行を提供しており、DTS は同種データ ソースと異種データ ソース間の移行をサポートしており、基本的に Mysql、Orcale、SQL Server などの業界で一般的なデータベースをサポートしています。 DTS は、前に説明した最初の 2 つのシナリオに適しています。1 つはサブデータベースのシナリオです。Alibaba Cloud の DRDS を使用している場合は、DTS を通じてデータを DRDS に直接移行できます。もう 1 つは異種データのシナリオです。 Redis、ES、DTS のいずれであっても、すべて直接移行をサポートしています。
それでは、DTS ストックを移行するにはどうすればよいでしょうか?実際、これは比較的単純で、おそらく次の手順で構成されます。
select * from table_name where id > curId and id < curId + 10000;复制代码
もちろん、実際の移行プロセスでは Alibaba Cloud を使用しない可能性があります。または 3 番目のシナリオでは、データベース フィールド間で多くの変換を行う必要があり、DTS がそれをサポートしていない場合、DTS のアプローチを模倣できます。セグメント内のバッチでデータを読み取ることでデータを移行します。ここで注意する必要があるのは、データをバッチで移行する場合、オンライン操作の通常の動作に影響を与えないようにセグメントのサイズと頻度を制御する必要があるということです。
既存データの移行ソリューションは比較的限られていますが、増分データ移行方法が全盛です。一般的に、次の方法があります。
非常に多くの方法があるため、どれを使用すればよいでしょうか?個人的にはbinlogを監視する方法がおすすめです binlogを監視することで開発コストが削減されます コンシューマロジックを実装するだけでデータの整合性が確保できます 監視されたbinlogなので以前の二重書き込みの心配がありませんビジネス上の問題。
上記のすべてのソリューションは、その多くが成熟したクラウド サービス (dts) またはミドルウェア (canal) ですが、ある程度のデータ損失を引き起こす可能性があります。データ損失は全体的に比較的まれですが、しかし、トラブルシューティングは非常に難しく、dts または canal が誤って揺れたり、データ受信時に誤ってデータが失われた可能性があります。移行プロセス中にデータが失われるのを防ぐ方法はないため、他の方法でデータを修正する必要があります。
一般的に、データを移行するときはデータ検証のステップが必要ですが、チームごとに異なるデータ検証ソリューションを選択する場合があります。
もちろん、実際の開発プロセスでは次の点にも注意する必要があります。
データ検証に基本的にエラーがない場合、移行プログラムが比較的安定していることを意味し、新しいデータを直接使用できますか?もちろんそんなことはあり得ません、一斉に切り替えるとうまくいけばいいのですが、何か問題が起きれば全ユーザーに影響が出てしまいます。
したがって、次にグレースケールを実行する必要があります。これはストリームの切断です。異なるビジネス フロー カットのディメンションは異なります。ユーザー ディメンション フロー カットの場合、通常は userId のモジュロ方式を使用してフローをカットします。テナントまたはマーチャント ディメンション ビジネスの場合は、テナント ID のモジュロを取る必要があります。カット方法流れ。このトラフィック削減には、どの時間帯にどれだけのトラフィックを解放するか、トラフィック削減計画を立てる必要があり、トラフィックを削減するときは、トラフィックが比較的少ない時間帯を選択する必要があります。ログを詳細に観察し、問題をできるだけ早く修正します トラフィックを解放するプロセスは、低速から高速へのプロセスです。たとえば、最初は 1% で継続的に重畳します。その後、10 を直接使用します。 % または 20% ですぐに音量を上げます。なぜなら、問題があったとしても、トラフィックが少ないときに発見されることが多く、トラフィックが少ない状態で問題がなければ、すぐにボリュームを増やすことができるからです。
データの移行プロセスでは、主キー ID に特別な注意を払う必要があります。上記の二重書き込みソリューションでは、次のことも述べられています。主キーIDを手動で二重書きする必要がある ID生成順序エラーを防ぐために指定します。
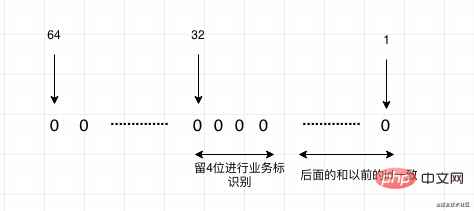
サブデータベースとテーブルが原因で移行する場合は、将来の主キー ID を自動インクリメント ID にすることはできないことを考慮する必要があり、分散 ID を使用する必要があります。ここでより推奨されるのは次のとおりです。 Meituan のオープンソース リーフです。2 つのモードをサポートしています。1 つはスノーフレーク アルゴリズムが増加傾向にありますが、すべての ID は Long 型であり、ID として Long をサポートする一部のアプリケーションに適しています。設定した基本 ID に基づいて上から増加し続ける数値セグメント モードもあります。そして基本的にすべてメモリ生成を使用し、パフォーマンスも非常に高速です。
もちろん、システムを移行する必要がある状況はまだありますが、以前のシステムの主キー ID が新しいシステムにすでに存在しているため、ID をマッピングする必要があります。システムを移行する際に、将来どのシステムを移行するかがわかっている場合、たとえば、システムAの現在のデータが1億から1億で、システムBのデータも1億である場合、予約方式を使用できます。ここで、2 つのシステム A と B を新しいシステムにマージする必要があります。その後、バッファーをわずかに見積もることができます。たとえば、システム A に 1 億から 1 億 5,000 万を残し、A をマッピングする必要がないようにします。 、システム B は 1 億 5,000 万から 3 億です。その後、古いシステム ID に変換すると、1 億 5,000 万を引く必要があります。最終的に、新しいシステムの新しい ID は 3 億から増加します。 しかし、システム内に計画された予約セグメントがない場合はどうなるでしょうか?これは次の 2 つの方法で行うことができます:
最後に、このルーチンを簡単にまとめましょう。実際には 4 つのステップです。注意すべき点は、ストック、増分、検証、およびカット. ストリーム、最後にIDに注目してください。どんなにデータ量が多くても、基本的にはこの手順で移行すれば大きな問題はありません。この記事が今後のデータ移行作業に役立つことを願っています。
この記事が役に立ったと思われる場合は、ご注目と転送が私にとって最大のサポートです。O(∩_∩)O:
#関連する無料学習の推奨事項: Java 基本チュートリアル
以上が数兆のデータをどのように移行する必要があるかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



