|
TIMESTAMP によって表示される値はタイム ゾーンによって異なります。つまり、タイム ゾーンが異なるとクエリされる値も異なります。上記の違いに加えて、TIMESTAMP には特別な属性もあり、挿入および更新中に最初の TIMESTAMP 列の値が指定されていない場合、この列の値は現在時刻に設定されます。
開発プロセスでは TIMESTAMP を使用するようにしてください。主な理由は、スペース サイズが DATETIME の半分に過ぎず、スペース効率が高いためです。
秒単位で正確な日付と時刻を保存したい場合はどうすればよいでしょうか? MySQL にはそれが提供されていないため、BIGINT を使用してマイクロレベルのタイムスタンプを保存するか、DOUBLE を使用して秒後の小数部分を保存できます。
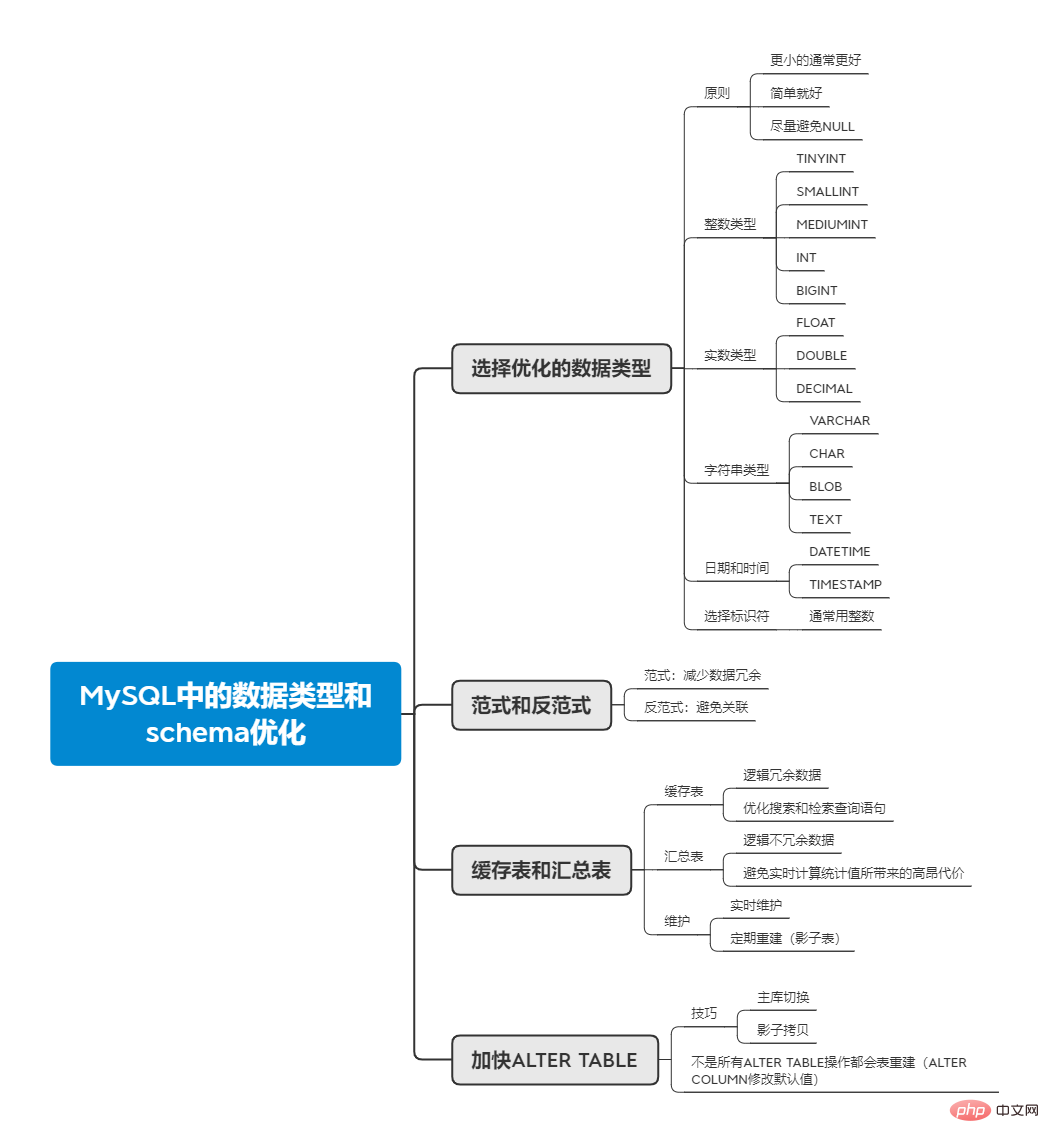
1.5 識別子の選択
一般に、整数は単純で計算が速く、AUTO_INCREMENT を使用できるため、識別子としては最適な選択です。
2. パラダイムとアンチパラダイム
簡単に言えば、パラダイムとは、データ テーブルのテーブル構造が準拠する特定の設計標準のレベルです。第 1 正規形では属性は分離不可能であり、現在の RDBMS システムで構築されるテーブルはすべて第 1 正規形に準拠しています。第 2 正規形は、コード (主キーとして理解できる) に対する非主属性の部分的な依存を排除します。第 3 正規形は、コードに対する非主属性の推移的な依存を排除します。具体的な紹介については、Zhihu でこの回答を読むことができます (https://www.zhihu.com/question/24696366/answer/29189700)
StrictNormalized データベース、各ファクト データ#データの冗長性はありません これにより、次のような利点が得られます:
- 更新操作の高速化、
- 変更するデータの削減。
- テーブルが小さくなり、メモリに収まりやすくなり、操作が高速に実行されます。
- DISTINCT または GROUP BY の必要性が少なくなります。
ただし、データはさまざまなテーブルに分散しているため、クエリを実行するときにテーブルを関連付ける必要があります。 アンチパラダイムの利点は、を関連付ける必要がなく、データが冗長的に保存されることです。
実際のアプリケーションでは、完全な正規化や完全な非正規化は発生しません。多くの場合、パラダイムと非正規化を混合する必要があります。。多くの場合、部分的に正規化されたスキーマを使用することが最善です。 ■選択。データベース設計に関しては、インターネットでこの文章を目にしましたが、それを実感できます。
データベース設計は 3 つの領域に分割する必要があります:
最初の領域: データベース設計を始めたばかりで、パラダイムの重要性はまだ深く理解されていません。このときに現れるアンチパラダイムのデザインは、一般的に問題を引き起こします。
2 番目の領域: 問題に遭遇して解決すると、パラダイムの本当の利点が徐々に理解できるようになり、冗長性が低く、効率の高いデータベースを迅速に設計できるようになります。
第 3 の領域: N 年間のトレーニングを経ると、パラダイムの限界が必ずわかります。このとき、パラダイムを壊し、より合理的なアンチパラダイム部分を設計します。
パラダイムは武道の動きのようなもので、初心者がその動きに従わないと恥をかいて死ぬだけです。結局のところ、トリックはマスターによって要約されたエッセンスです。武道が上達し、動きに習熟すると、必ずその動きの限界に気づき、それを忘れるか、独自の動きを生み出すことになります。
一生懸命働いてあと数年耐えさえすれば、いつでも 2 番目の状態に到達でき、そのパラダイムが古典であると常に感じるでしょう。このとき、パラダイムに頼りすぎず、パラダイムの限界を素早く打ち破ることができる人が、当然エキスパートとなります。
4. キャッシュ テーブルとサマリー テーブル
上記のアンチパラダイムと冗長データをテーブルに保存することに加えて、完全に独立したサマリー テーブルまたはキャッシュを作成することもできます。検索のニーズを満たすテーブル。
キャッシュ テーブルは、スキーマ内の他のテーブルから取得できるデータ、つまり論理的に冗長なデータを格納するテーブルを指します。 サマリー テーブルは、GROUP BY およびその他のステートメントを使用してデータを集計することによって計算された非冗長データのストレージを指します。
キャッシュ テーブルは、 検索および取得クエリ ステートメントを最適化するために使用できます。ここで使用できるテクニックには、キャッシュ テーブルにさまざまなストレージ エンジンを使用することが含まれます。たとえば、メイン テーブルは InnoDB を使用します。一方、キャッシュ テーブルは MyISAM を使用してインデックス フットプリントを小さくできます。キャッシュ テーブルを Lucene などの特殊な検索システムに配置することもできます。
サマリー テーブルは、統計値をリアルタイムで計算するための高コストを回避するためのものです。コストは 2 つの側面から発生します。1 つは、テーブル内のほとんどのデータが必要であることです。もう 1 つは、特定のインデックスを作成することです。インデックスは UPDATE 操作に影響します。たとえば、過去 24 時間の WeChat モーメントの数をクエリするには、テーブル全体を 1 時間ごとにスキャンし、統計の後にレコードを概要テーブルに書き込むことができます。クエリを実行する場合は、概要の最新の 24 レコードをクエリするだけで済みます。すべてではなくテーブル 各クエリ中に、テーブル全体が統計のためにスキャンされます。
キャッシュ テーブルとサマリー テーブルを使用する場合、ニーズに応じて データをリアルタイムで維持するか それとも 定期的に再構築する かを決定する必要があります。リアルタイムのメンテナンスと比較して、定期的な再構築により、より多くのリソースが節約され、テーブルの断片化が少なくなります。再構築中も、操作中にデータが利用可能であることを確認する必要があり、これは「shadow table」を通じて実現する必要があります。実テーブルの背後にシャドウ テーブルを作成し、データを入力した後、アトミックな名前変更操作によってシャドウ テーブルと元のテーブルを切り替えます。
5. ALTER TABLE オペレーションの高速化
MySQL が ALTER TABLE オペレーションを実行するとき、多くの場合、新しいテーブルを作成し、古いテーブルからデータを取得して新しいテーブルに挿入します。古いテーブル: テーブルが大きい場合、これには長い時間がかかり、MySQL サービスの中断が発生します。サービスの中断を避けるために、通常は 2 つの手法 :
- サービスを提供しないマシンで ALTER TABLE 操作を実行し、メイン ライブラリと通信します。サービスを提供する Switch;
- 「シャドウ コピー」では、元のテーブルとは関係のない新しいテーブルを作成し、データ移行の完了後に名前変更操作を実行します。
ただし、すべての ALTER TABLE 操作でテーブルが再構築されるわけではありません。たとえば、フィールドのデフォルト値を変更する場合、MODIFY COLUMN を使用するとテーブルが再構築され、ALTER COLUMN を使用するとテーブルが再構築されます。 will テーブルの再構築は実行されず、操作は非常に高速です。これは、ALTER COLUMN がデフォルト値を変更する場合、テーブルを再構築せずに、既存のテーブル (フィールドのデフォルト値を格納する) の .frm ファイルを直接変更するためです。
#その他の関連する無料学習の推奨事項: mysql チュートリアル(ビデオ)
|


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



