

InnoDB のチェックポイント テクノロジーを理解する

mysql 教程 目録の大家は InnoDB のチェックポイント テクニックを熟知しています。

一句概要、チェックポイント テクニックつまり、ある時点で保存池内の点刷りを磁盘に戻す操作
評価された問題?
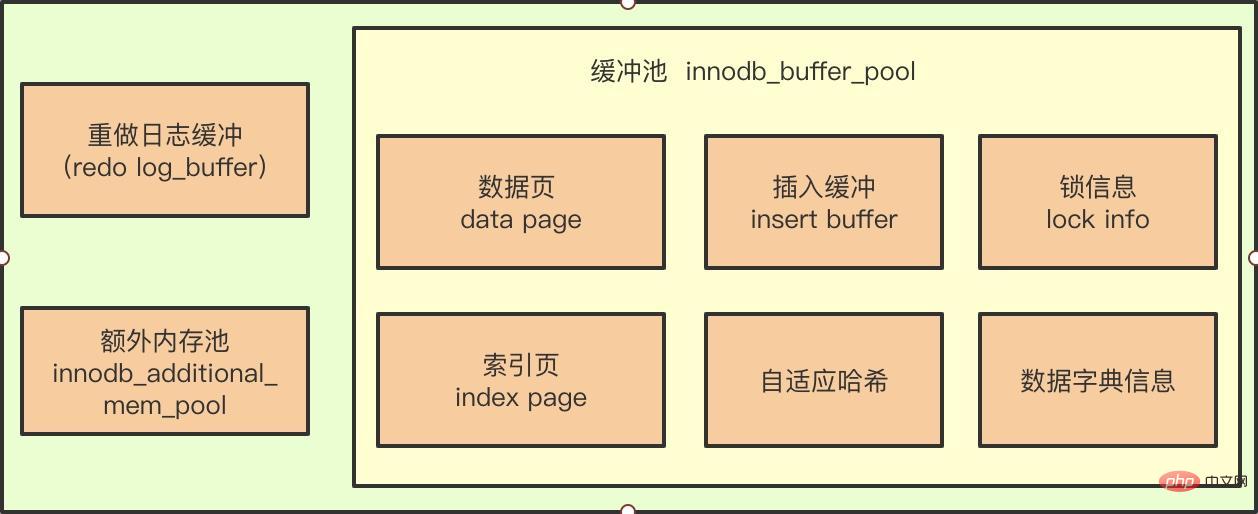
都知道缓冲セルの発生は、CPU とマグネティックの速度の間の混乱を認識するためであり、これにより、データの書き込み中にマグネティックス IO 操作を実行する必要がなくなりました。
#DML の例のように、データの更新または削除操作を実行すると、冷却セルのデータが磁場よりも新しいため、このときの設定が変更されます。 不管怎样、会議後の内部保存データは磁盘里に戻る必要があります、ここに就涉及几个问题:- 若每次一页発行变化、就将新页のバージョンが磁盘に新しく到着しました。那么この销は非常に大きいです
- 若熱量データが特定の場所に集中しており、那么データ プールのパフォーマンスは非常に差が得られます
- 結果的には、池将页の新しいバージョンの刷新が磁盘に到着したとき、完了机が発生しました、那么データ就は恢了できません
redo log
,每当有事务提交時,先書入redo log(重做日志),在修改缓冲池データ页,这样電気が発生した場合、システムは再実行後に操作を続行できます。WAL ポリシー機構の原理
障害が発生してメモリ データが失われた場合、InnoDB は再起動時に REDO ログを再生することでバッファ プール データ ページをクラッシュ前の状態に復元します。
チェックポイント
WAL戦略を使えば、座ってリラックスできるのは当然です。しかし、REDO ログで問題が再び発生します。アイドル状態で復元されます。REDO ログが大きすぎる場合、リカバリのコストも非常に高くなります。
- では、ダーティ ページのリフレッシュ パフォーマンスを解決するには、いつ、どのような状況で行う必要がありますか?ダーティ ページを更新する必要がありますか? 更新にはチェックポイント テクノロジが使用されます。
- チェックポイントの目的
1. データベースの復旧時間を短縮します
データベースがアイドル状態で復元されると、やり直しの必要がありません。すべてのログ情報。チェックポイント前のデータ ページがディスクにフラッシュ バックされているためです。チェックポイントの後に REDO ログを復元するだけです。2. バッファー プールが十分でない場合は、ダーティ ページをディスクにフラッシュします。
バッファー プールのスペースが不十分な場合、最も最近使用されていないページが、このページがダーティ ページである場合、チェックポイントにダーティ ページ、つまりページの新しいバージョンを強制的にフラッシュしてディスクに戻す必要があります。3. REDO ログが利用できない場合は、ダーティ ページを更新します
図に示すように、REDO ログは現在のデータベースが使用できないため、デザインはすべてリサイクルされるため、スペースは無限ではありません。
REDO ログがいっぱいになると、現時点ではシステムが更新を受け入れることができないため、すべての更新ステートメントがブロックされます。 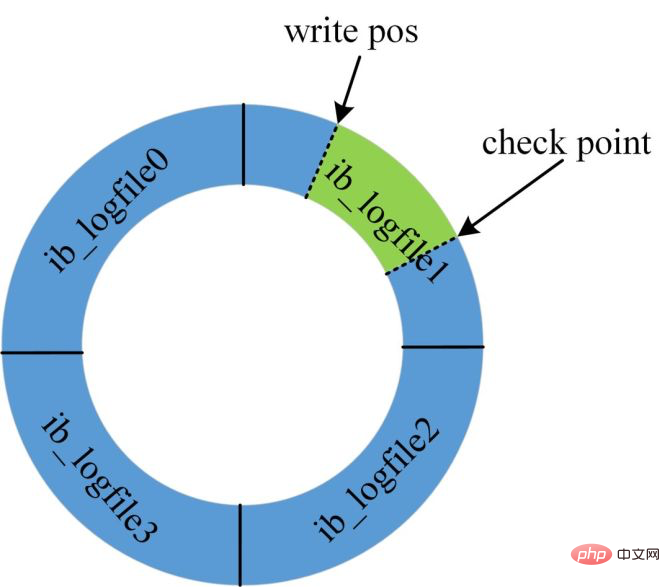
上記の問題に直面して、InnoDB ストレージ エンジンは内部的に 2 つのチェックポイントを提供します。
Sharp Checkpoint
データベースがシャットダウンされ、すべてのダーティ ページがディスクにフラッシュされます。これがデフォルトの動作方法です。パラメータ innodb_fast_shutdown=1- Fuzzy Checkpoint InnoDB ストレージ エンジン このモードを使用すると、すべてのダーティ ページをディスクにフラッシュするのではなく、一部のダーティ ページのみがフラッシュされます
-
#FuzzyCheckpoint で何が起こるか##
ほぼ毎秒または 10 秒ごとに、バッファ プール内のダーティ ページ リストから特定の割合のページをディスクにフラッシュします。
このプロセスは非同期です。つまり、InnoDB ストレージ エンジンはこの時点で他の操作を実行でき、ユーザー クエリ スレッドはブロックされません- FLUSH_LRU_LIST チェックポイント LRU リストでは一定数の空きページを使用できるようにする必要があるため、空きページが不足した場合は末尾からページが削除され、削除されたページにダーティ ページがある場合にこのチェックポイントが実行されます。 バージョン 5.6 以降、このチェックポイントは別のページ クリーナー スレッドに配置され、ユーザーはパラメータ innodb_lru_scan_ Depth を通じて LRU リスト内の使用可能なページの数を制御できます。デフォルト値は 1024
- 非同期/同期フラッシュ チェックポイント は、REDO ログ ファイルが利用できない状況を指します。現時点では、一部のページを強制的にディスクにフラッシュする必要があり、ダーティ ページはダーティ ページ リストから削除されました。選択された 5.6 バージョンはユーザー クエリをブロックしません
- ダーティ ページが多すぎるチェックポイント つまり、ダーティ ページの数が多すぎるため、InnoDB ストレージ エンジンがチェックポイントを強制します。 一般的な目的は、バッファ プール内に十分な使用可能なページがあることを確認することです。 パラメータ innodb_max_dirty_pages_pct で制御できます。たとえば、値は 75 で、バッファ プール内のダーティ ページが 75% を占めると、CheckPoint が強制的に実行されることを意味します。
-
#概要
CPU とディスクの間にギャップがあるため、バッファー プール データ ページはデータベース DML 操作を高速化するようです
- バッファ プールのダーティ ページのリフレッシュ パフォーマンスの問題のため、チェックポイントテクノロジーの登場
- InnoDB 実行効率を向上させるために、すべての DML 操作は永続化のためにディスクと対話しません。代わりに、最初に先行書き込みログを使用して REDO ログを書き込み、内容の永続性を確保します。 トランザクションで変更されたバッファ プールのダーティ ページの場合、ディスクは非同期でフラッシュされ、メモリ空きページと REDO ログの可用性はチェックポイント テクノロジによって保証されます。
#その他の関連する無料学習の推奨事項:
(ビデオ)
以上がInnoDB のチェックポイント テクノロジーを理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7540
7540
 15
1381
52
83
11
21
86
15
1381
52
83
11
21
86

 mysql innodbとは何ですか
Apr 14, 2023 am 10:19 AM
mysql innodbとは何ですか
Apr 14, 2023 am 10:19 AM
InnoDB は、MySQL のデータベース エンジンの 1 つです。現在、MySQL のデフォルトのストレージ エンジンであり、MySQL AB によるバイナリ リリースの標準の 1 つです。InnoDB は、二重トラック認証システムを採用しており、1 つは GPL 認証、もう 1 つは独自のソフトウェアです認可。 InnoDB は、トランザクション データベースに推奨されるエンジンであり、トランザクション セキュリティ テーブル (ACID) をサポートしています。InnoDB は、同時実行性を最大限にサポートできる行レベルのロックをサポートしています。行レベルのロックは、ストレージ エンジン層によって実装されます。
 MySQL がバイナリ コンテンツから InnoDB 行フォーマットを認識する方法
Jun 03, 2023 am 09:55 AM
MySQL がバイナリ コンテンツから InnoDB 行フォーマットを認識する方法
Jun 03, 2023 am 09:55 AM
InnoDB はディスク上のテーブルにデータを保存するストレージ エンジンであるため、シャットダウンして再起動した後でもデータは残ります。データ処理の実際のプロセスはメモリ内で発生するため、ディスク内のデータをメモリにロードする必要があります。書き込みまたは変更要求を処理している場合は、メモリ内の内容もディスクに更新する必要があります。また、ディスクへの読み取りおよび書き込みの速度は非常に遅いことがわかっており、これはメモリ内での読み取りおよび書き込みとは数桁異なります。したがって、テーブルから特定のレコードを取得したい場合、InnoDB ストレージ エンジンは読み取りを行う必要がありますか?ディスクからレコードを 1 つずつ取り出しますか? InnoDB で採用されている方法は、データを複数のページに分割し、ページをディスクとメモリ間の対話の基本単位として使用することです。InnoDB のページのサイズは通常 16 です。
 mysql innodb例外を処理する方法
Apr 17, 2023 pm 09:01 PM
mysql innodb例外を処理する方法
Apr 17, 2023 pm 09:01 PM
1. mysql をロールバックして再インストールします。このデータを他の場所からインポートする手間を避けるために、まず現在のライブラリ (/var/lib/mysql/location) のデータベース ファイルのバックアップを作成します。次に、Perconaserver 5.7 パッケージをアンインストールし、元の 5.1.71 パッケージを再インストールし、mysql サービスを開始すると、Unknown/unsupportedtabletype:innodb というプロンプトが表示され、正常に開始できませんでした。 11050912:04:27InnoDB:バッファプールの初期化中、サイズ=384.0M11050912:04:27InnoDB:完了
 MySQL ストレージ エンジンの選択の比較: InnoDB、MyISAM、およびメモリのパフォーマンス インデックスの評価
Jul 26, 2023 am 11:25 AM
MySQL ストレージ エンジンの選択の比較: InnoDB、MyISAM、およびメモリのパフォーマンス インデックスの評価
Jul 26, 2023 am 11:25 AM
MySQL ストレージ エンジンの選択の比較: InnoDB、MyISAM、およびメモリのパフォーマンス インデックスの評価 はじめに: MySQL データベースでは、ストレージ エンジンの選択がシステム パフォーマンスとデータの整合性において重要な役割を果たします。 MySQL はさまざまなストレージ エンジンを提供します。最も一般的に使用されるエンジンには、InnoDB、MyISAM、Memory などがあります。この記事では、これら 3 つのストレージ エンジンのパフォーマンス指標を評価し、コード例を通じて比較します。 1. InnoDB エンジン InnoDB は私のものです
 MySQL の innoDB でのファントム読み取りを解決する方法
May 27, 2023 pm 03:34 PM
MySQL の innoDB でのファントム読み取りを解決する方法
May 27, 2023 pm 03:34 PM
1. MySQL トランザクション分離レベル これら 4 つの分離レベルでは、複数のトランザクションの同時実行性の競合がある場合、ダーティ リード、非反復読み取り、ファントム読み取りの問題が発生する可能性があり、innoDB は反復可能読み取り分離レベル モードでこれらの問題を解決します。ファントム リーディングの説明、2. ファントム リーディングとは? ファントム リーディングとは、図に示すように、同じトランザクション内で同じ範囲を前後 2 回クエリしたときに得られる結果が矛盾することを意味します。 . この時点では、条件を満たすデータは 1 つだけです。2 番目のトランザクションでは、データの行を挿入して送信します。最初のトランザクションが再度クエリを実行すると、取得される結果は、前のトランザクションの結果より 1 つ多くなります。最初のクエリ。データ。最初のトランザクションの最初と 2 番目のクエリは両方とも同じであることに注意してください
 INNODBフルテキスト検索機能を説明します。
Apr 02, 2025 pm 06:09 PM
INNODBフルテキスト検索機能を説明します。
Apr 02, 2025 pm 06:09 PM
INNODBのフルテキスト検索機能は非常に強力であり、データベースクエリの効率と大量のテキストデータを処理する能力を大幅に改善できます。 1)INNODBは、倒立インデックスを介してフルテキスト検索を実装し、基本的および高度な検索クエリをサポートします。 2)一致を使用してキーワードを使用して、ブールモードとフレーズ検索を検索、サポートします。 3)最適化方法には、単語セグメンテーションテクノロジーの使用、インデックスの定期的な再構築、およびパフォーマンスと精度を改善するためのキャッシュサイズの調整が含まれます。
 MyISAM および InnoDB ストレージ エンジンを使用して MySQL のパフォーマンスを最適化する方法
May 11, 2023 pm 06:51 PM
MyISAM および InnoDB ストレージ エンジンを使用して MySQL のパフォーマンスを最適化する方法
May 11, 2023 pm 06:51 PM
MySQL は広く使用されているデータベース管理システムであり、ストレージ エンジンが異なればデータベースのパフォーマンスに与える影響も異なります。 MyISAM と InnoDB は、MySQL で最もよく使用される 2 つのストレージ エンジンですが、これらには異なる特性があり、不適切に使用するとデータベースのパフォーマンスに影響を与える可能性があります。この記事では、これら 2 つのストレージ エンジンを使用して MySQL のパフォーマンスを最適化する方法を紹介します。 1. MyISAM ストレージ エンジン MyISAM は、MySQL で最も一般的に使用されるストレージ エンジンであり、その利点は高速であり、ストレージ スペースが小さいことです。 MyISA
 MySQL ストレージ エンジンの読み取りパフォーマンスを向上させるためのヒントと戦略: MyISAM と InnoDB の比較分析
Jul 26, 2023 am 10:01 AM
MySQL ストレージ エンジンの読み取りパフォーマンスを向上させるためのヒントと戦略: MyISAM と InnoDB の比較分析
Jul 26, 2023 am 10:01 AM
MySQL ストレージ エンジンの読み取りパフォーマンスを向上させるためのヒントと戦略: MyISAM と InnoDB の比較分析 はじめに: MySQL は、最も一般的に使用されているオープン ソース リレーショナル データベース管理システムの 1 つで、主に大量の構造化データの保存と管理に使用されます。ほとんどのアプリケーションでは読み取り操作が主な操作であるため、アプリケーションではデータベースの読み取りパフォーマンスが非常に重要になることがよくあります。この記事では、MySQL ストレージ エンジンの読み取りパフォーマンスを向上させる方法に焦点を当て、一般的に使用される 2 つのストレージ エンジンである MyISAM と InnoDB の比較分析に焦点を当てます。
