


InnoDB エンジンには、パフォーマンスと信頼性の向上をもたらすいくつかの重要な機能があります:
今日のトピックは バッファの挿入 (挿入) Buffer) 、InnoDB エンジンの基礎となるデータは構造化された B ツリーに格納されており、インデックスには集約インデックスと非クラスター化インデックスがあるためです。
データを挿入すると、必然的にインデックスが変更されます。言うまでもなく、クラスター化インデックスは通常、昇順になります。非クラスター化インデックスは必ずしもデータではなく、その離散的な性質により、挿入中に構造が継続的に変更され、その結果、挿入パフォーマンスが低下します。
そこで、ノンクラスタード インデックスの挿入パフォーマンスの問題を解決するために、InnoDB エンジンは挿入バッファを作成しました。
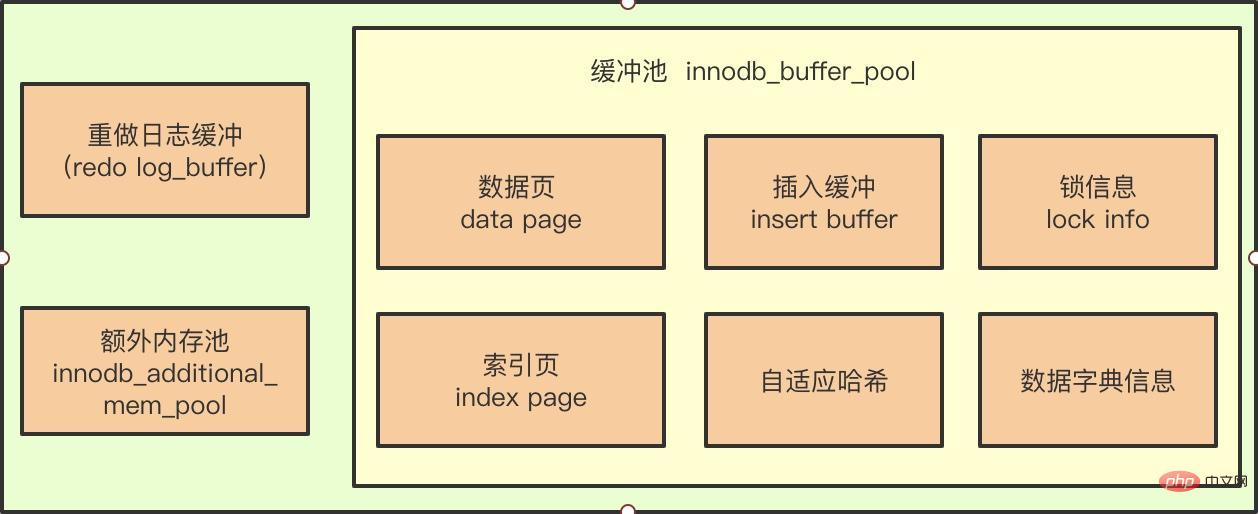
#上の図を見ると、挿入バッファは InnoDB バッファ プールのコンポーネントであると思われるかもしれません。
**重要なポイント: **実際には、これは真か偽です。InnoDB バッファ プールには挿入バッファの情報が含まれていますが、挿入バッファは実際にはデータ ページ (共有テーブル) と同様に物理的に存在します。空間内に B ツリー) の形式で存在します)。
最初にいくつかの点について説明します。
テーブルには 1 つのみを持つことができます。主キー インデックス。これは、その物理ストレージが B ツリーであるためです。 (クラスター化インデックスのリーフ ノードに保存されているデータを忘れないでください。データのコピーは 1 つだけです。)
非クラスター化インデックスのリーフ ノードには、クラスタ化インデックスの主キーが保存されます。クラスター化インデックス
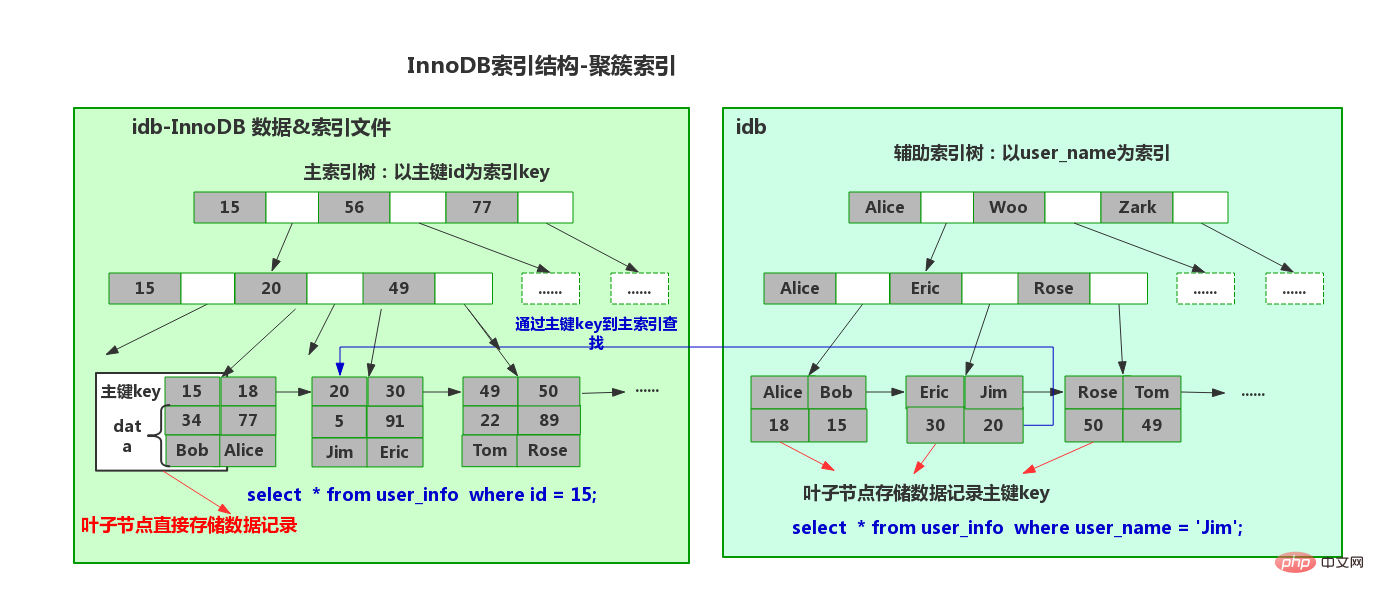
#まず、InnoDB ストレージ内にあることがわかります。エンジンでは、主キーは行の一意の識別子です (つまり、クラスター化インデックスがよく使用されます)。通常、主キーに従ってデータを増分挿入するため、クラスター化インデックスはシーケンシャルであり、ディスクからのランダムな読み取りは必要ありません。
例: テーブル:
CREATE TABLE test( id INT AUTO_INCREMENT, name VARCHAR(30), PRIMARY KEY(id) );复制代码
上記のように、次の特性を持つ主キー ID を作成しました。
CREATE TABLE test( id INT AUTO_INCREMENT, name VARCHAR(30), PRIMARY KEY(id), KEY(name) );复制代码
挿入バッファを使用して挿入する方法を見てみましょう:
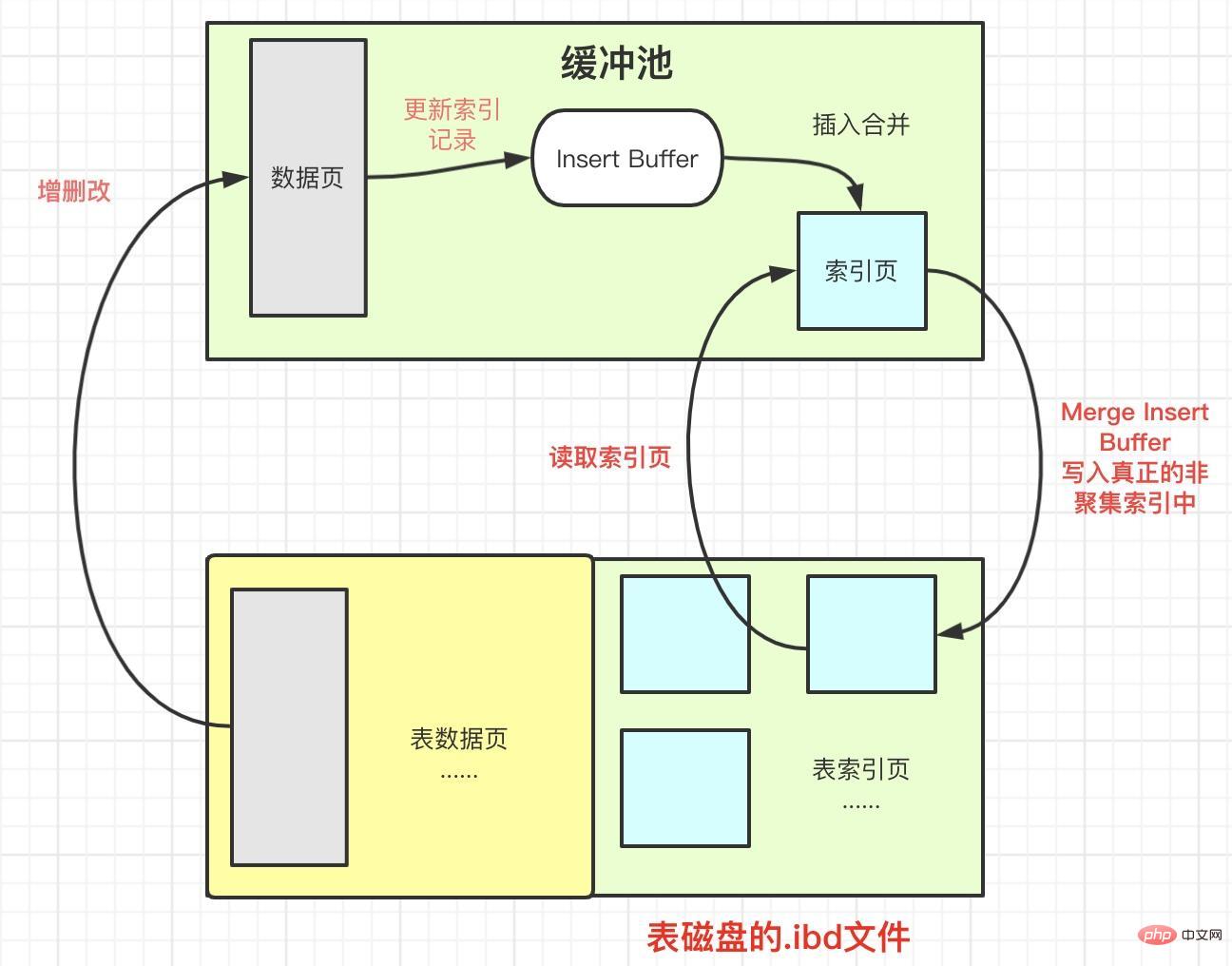
只有满足上面两个必要条件时,InnoDB存储引擎才会使用Insert Buffer来提高插入性能。
那为什么必须满足上面两个条件呢?
第一点索引是非聚集索引就不用说了,人家聚集索引本来就是顺序的也不需要你
第二点必须不是唯一(unique)的,因为在写入Insert Buffer时,数据库并不会去判断插入记录的唯一性。如果再去查找肯定又是离散读取的情况了,这样InsertBuffer就失去了意义。
我们可以使用命令SHOW ENGINE INNODB STATUS来查看Insert Buffer的信息:
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 7545, free list len 3790, seg size 11336, 8075308 inserts,7540969 merged sec, 2246304 merges ...复制代码
使用命令后,我们会看到很多信息,这里我们只看下INSERT BUFFER 的:
seg size 代表当前Insert Buffer的大小 11336*16KB
free listlen 代表了空闲列表的长度
size 代表了已经合并记录页的数量
Inserts 代表了插入的记录数
merged recs 代表了合并的插入记录数量
merges 代表合并的次数,也就是实际读取页的次数
merges:merged recs大约为1∶3,代表了Insert Buffer 将对于非聚集索引页的离散IO逻辑请求大约降低了2/3
说了这么多针对于Insert Buffer的好处,但目前Insert Buffer也存在一个问题:
即在写密集的情况下,插入缓冲会占用过多的缓冲池内存(innodb_buffer_pool),默认最大可以占用到1/2的缓冲池内存。
占用了过大的缓冲池必然会对其他缓冲池操作带来影响
MySQL5.5之前的版本中其实都叫做Insert Buffer,之后优化为 Change Buffer 可以看做是 Insert Buffer 的升级版。
插入缓冲( Insert Buffer)这个其实只针对 INSERT 操作做了缓冲,而Change Buffer 对INSERT、DELETE、UPDATE都进行了缓冲,所以可以统称为写缓冲,其可以分为:
Insert Buffer
Delete Buffer
Purgebuffer
Insert Buffer到底是个什么?
其实Insert Buffer的数据结构就是一棵B+树。
在MySQL 4.1之前的版本中每张表有一棵Insert Buffer B+树
目前版本是全局只有一棵Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer
这棵B+树存放在共享表空间ibdata1中
以下几种情况下 Insert Buffer会写入真正非聚集索引,也就是所说的Merge Insert Buffer
一句话概括下:
Insert Buffer 就是用于提升非聚集索引页的插入性能的,其数据结构类似于数据页的一个B+树,物理存储在共享表空间ibdata1中 。
相关免费学习推荐:mysql视频教程
以上が重要な知識ポイントの紹介: InnoDB の挿入バッファーの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



