


すべての良い習慣は財産です この記事は、SQL 後悔の薬、SQL パフォーマンスの最適化、および SQL 仕様の優雅さの 3 つの方向に分かれています。 SQL の 21 の良い習慣を共有して作成します。読んでいただきありがとうございます。これからも頑張ってください~
日常生活で SQL を開発および作成するときは、できる限り SQL を作成するようにしてください。これは良い習慣です。SQL を作成した後は、インデックスが使用されているかどうかに特に注意しながら、Explain を使用して SQL を分析します。
explain select * from user where userid =10086 or age =18;复制代码

delete または update ステートメントを実行するときに、追加してみてください次のような制限 次の SQL を例に挙げます。
delete from euser where age > 30 limit 200;复制代码
制限を追加すると、次のような主な利点があるためです。
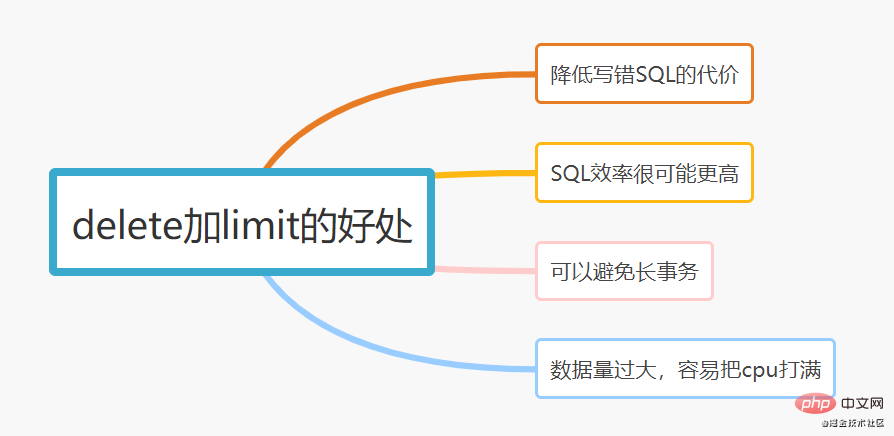
肯定的な例:
CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';复制代码
反例:
CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `balance` int(11) DEFAULT NULL, `create_time` datetime NOT NULL , `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8;复制代码
SELECT stu.name, sum(stu.score) FROM Student stu WHERE stu.classNo = '1班' GROUP BY stu.name复制代码
SELECT stu.name, sum(stu.score) from Student stu WHERE stu.classNo = '1班' group by stu.name.复制代码
insert into Student values ('666','捡田螺的小男孩','100');复制代码insert into Student(student_id,name,score) values ('666','捡田螺的小男孩','100');复制代码CREATE TABLE `account` ( `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';复制代码
CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id', `name` varchar(255) DEFAULT NULL COMMENT '账户名', `balance` int(11) DEFAULT NULL COMMENT '余额', `create_time` datetime NOT NULL COMMENT '创建时间', `update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';复制代码

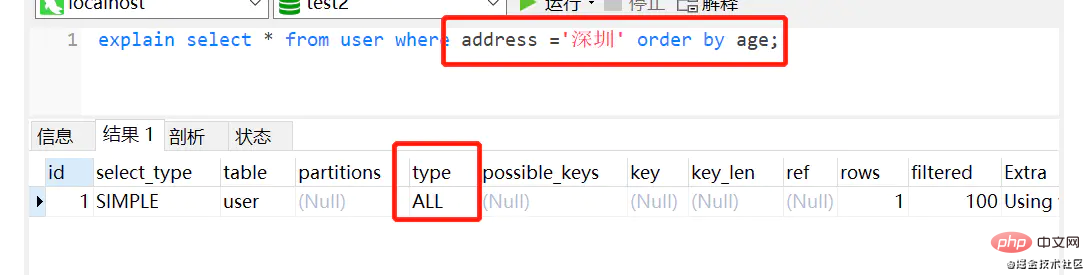
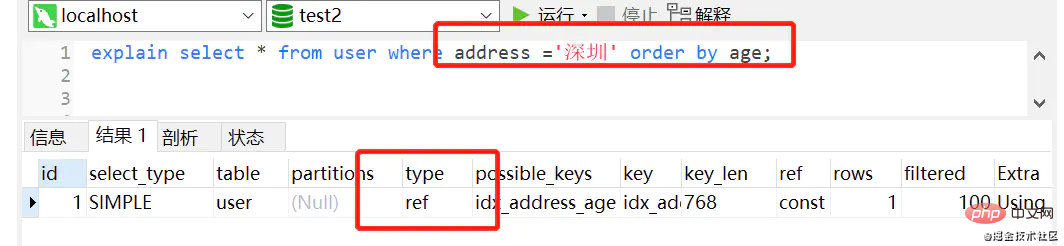
select * from user where address ='深圳' order by age ;复制代码
添加索引 alter table user add index idx_address_age (address,age)复制代码
後悔の薬を一口飲むこともできます~
反例:
//userid 是varchar字符串类型 select * from user where userid =123;复制代码

正例:
select * from user where userid ='123';复制代码
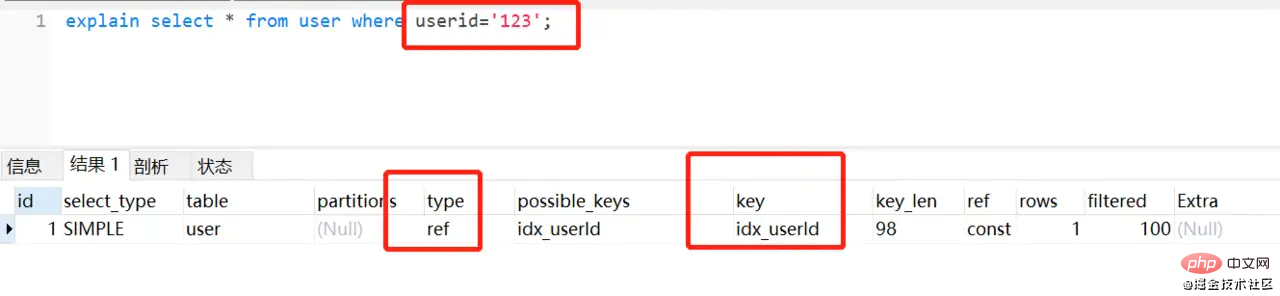
理由:
尤其在操作生产的数据时,遇到修改或者删除的SQL,先加个where查询一下,确认OK之后,再执行update或者delete操作
反例:
select * from employee;复制代码
正例:
select id,name from employee;复制代码
理由:
Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能更好,所以呢,没有特殊要求(即Innodb无法满足的功能如:列存储,存储空间数据等)的情况下,所有表必须使用Innodb存储引擎
统一使用UTF8编码
如果是存储表情的,可以考虑 utf8mb4
反例:
`deptName` char(100) DEFAULT NULL COMMENT '部门名称'复制代码
正例:
`deptName` varchar(100) DEFAULT NULL COMMENT '部门名称'复制代码
理由:
这个点,是阿里开发手册中,Mysql的规约。你的字段,尤其是表示枚举状态时,如果含义被修改了,或者状态追加时,为了后面更好维护,需要即时更新字段的注释。
正例:
begin; update account set balance =1000000 where name ='捡田螺的小男孩'; commit;复制代码
反例:
update account set balance =1000000 where name ='捡田螺的小男孩';复制代码
说明: pk_ 即 primary key;uk _ 即 unique key;idx _ 即 index 的简称。
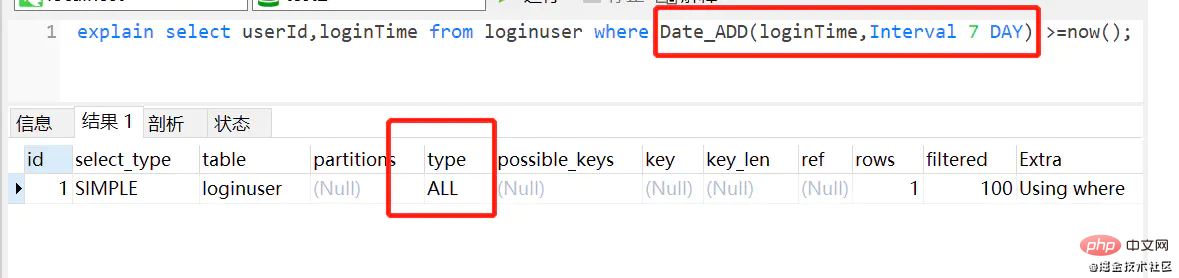
假设loginTime加了索引
反例:
select userId,loginTime from loginuser where Date_ADD(loginTime,Interval 7 DAY) >=now();复制代码
正例:
explain select userId,loginTime from loginuser where loginTime >= Date_ADD(NOW(),INTERVAL - 7 DAY);复制代码
理由:
反例:
delete from account limit 100000;复制代码
正例:
for each(200次)
{
delete from account limit 500;
}复制代码理由:
相关免费学习推荐:mysql视频教程
以上がMysql で SQL を書くための 21 の良い習慣を身につけるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



