


正则表达式应用的场景也非常多。常见的比如:搜索引擎的搜索、爬虫结果的匹配、文本数据的提取等等都会用到,所以掌握甚至精通正则表达式是一个硬性技能,非常必要。
正则表达式是一个特殊的字符序列,由普通字符和元字符组成。元字符能帮助你方便的检查一个字符串是否与某种模式匹配。
Python中则提供了强大的正则表达式处理模块,即 re 模块, 为Python的内置模块。
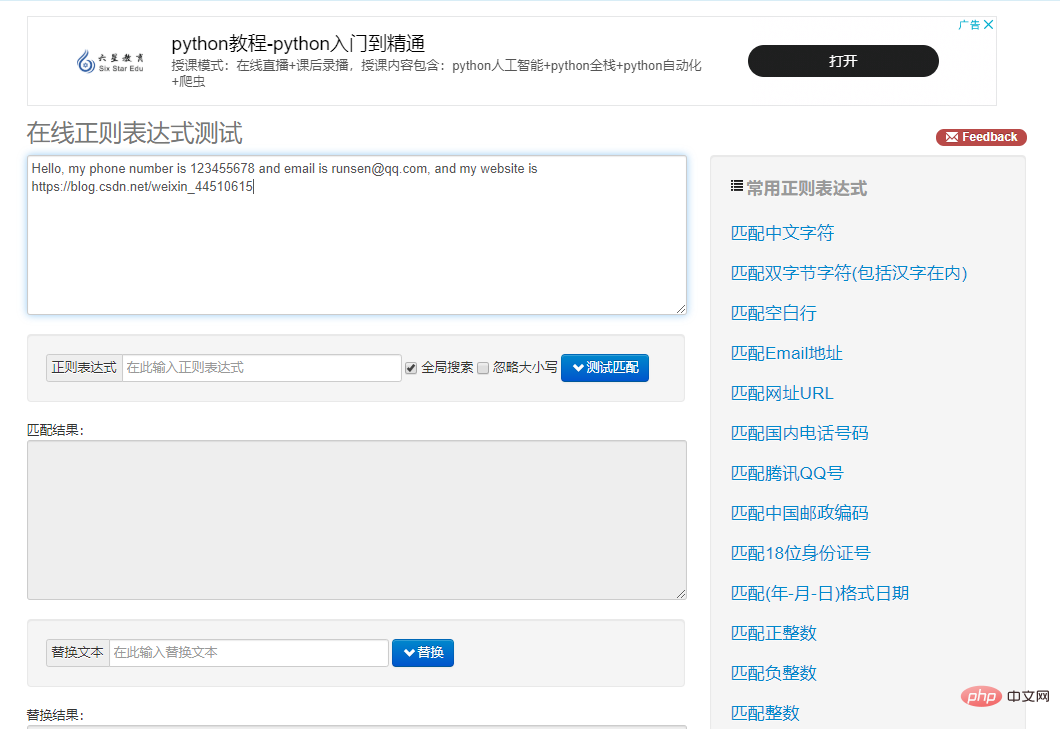
下面,我带大家来一个入门demo例子,代码如下:
import rereg_string = "hello9527python@wangcai.@!:xiaoqiang" reg = "hello"result = re.findall(reg,reg_string) print(result)复制代码
这里reg_string就是我们的普通字符,reg就是我们的元字符。
我们使用 re 模块中的findall函数,进行匹配,返回的结果是列表数据类型。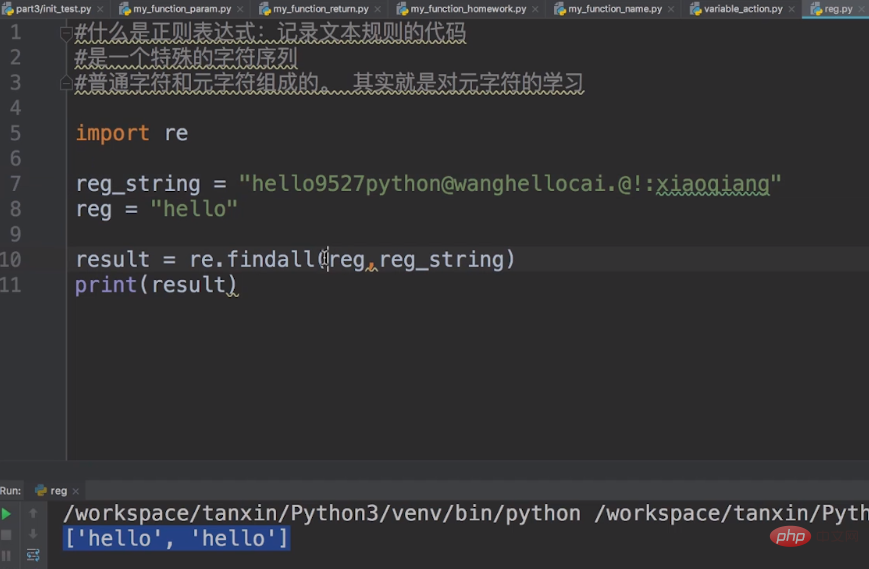
我们使用正则表达式,就是为了在很长的字符串中,找到我们需要的字符串片段。
Python中常见元字符及其含义如下:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \\\\w | 匹配数字字母下划线汉字 |
| \\\\s | 匹配任意空白符 |
| \\\\d | 匹配所有的数字 |
| \\\\b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的开始结束 |
| 下面,我们具体使用下Python中的常见的元字符。 |
我们还是使用上次的例子,这次我们需要在reg_string匹配出我们的数字,只需要将reg换成\\\\d,代码如下图所示。
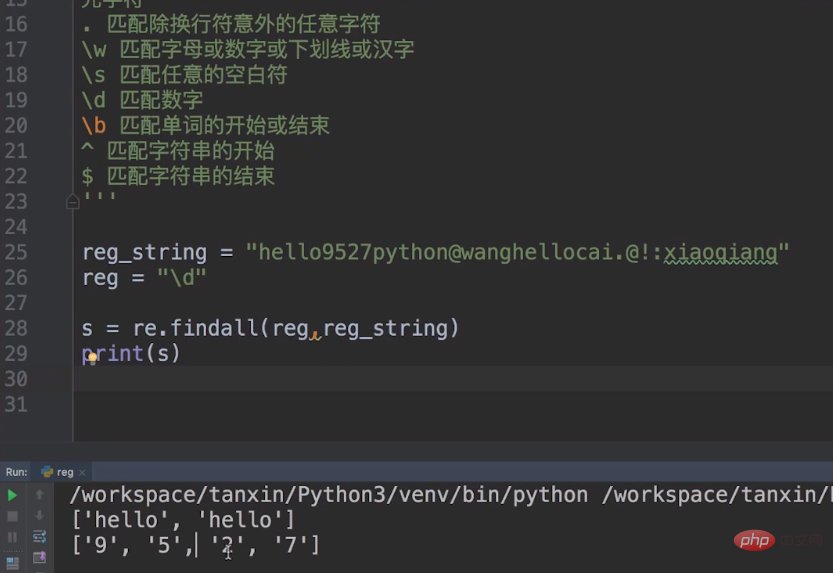 比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
如果,我们把reg换成\\\\w,代码如下图所示。
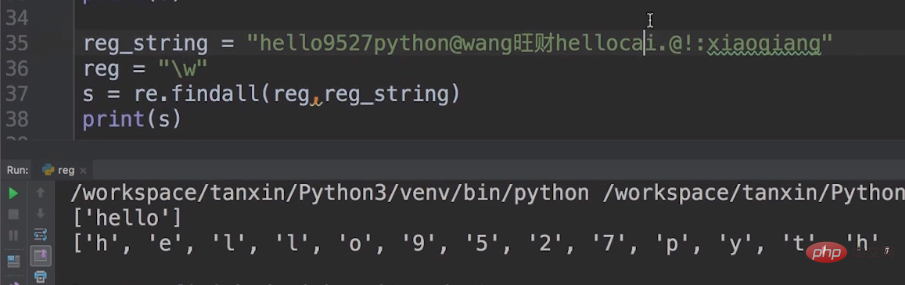
这样就是匹配数字字母下划线,包括我们的汉字。
Python中常见反义代码 及其含义如下:
| 反义代码 | 含义 |
|---|---|
| \\\\W | 匹配任意不是数字字母下划线汉字的字符 |
| \\\\S | 匹配任意不是空白符的字符 |
| \\\\D | 匹配非数字 |
| \\\\B | 匹配不是单词的开始或结束 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abcd] | 匹配除了abcd以外的任意字符 |
其实,记忆很简单,我们是不是知道\\\\d匹配数字,那么\\\\d的大写\\\\D就是匹配非数字,元字符[a]匹配a任意字符,那么[^a]就是匹配除了a以外的任意字符。
下面是具体例子
>>> import re>>> reg_string = "hello9527python@wangcai.@!:xiaoqiang" >>> reg = "\\\\D">>> re.findall(reg,reg_string) ['h', 'e', 'l', 'l', 'o', 'p', 'y', 't', 'h', 'o', 'n', '@', 'w', 'a', 'n', 'g', 'c', 'a', 'i', '.', '@', '!', ':', 'x', 'i', 'a', 'o', 'q', 'i', 'a', 'n', 'g'] >>> reg = "[^a-p]"['9', '5', '2', '7', 'y', 't', '@', 'w', '.', '@', '!', ':', 'x', 'q']复制代码
什么是限定符?就是限定我们匹配的个数的东西。
Python中常见限定符 及其含义如下:
| 限定符 | 含义 |
|---|---|
| * | 重复零次或多次 |
| + | 重复一次或多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n次到m次 {1,3} |
以前の reg_string を引き続き使用します。今回はメタキャラクターを \\\\d{4} に制限します。つまり、一致する数値は 4 でなければなりません。
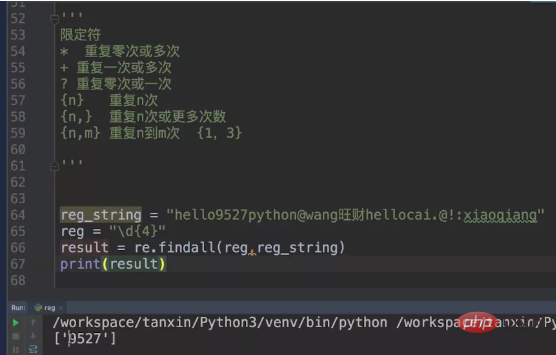
次に、難易度を上げて、文字と数字を 4 つに制限して一致させてみましょう。
このようにして、[0-9a-z]{4} をメタキャラクターとして使用できます。[0-9a-z] は、0 から 9 までの 10 個の数字と、a から z までの小文字の 26 を表します。文字。 [0-9a-z]{4} は数値を 4 に制限します。
出力を印刷しましょう。
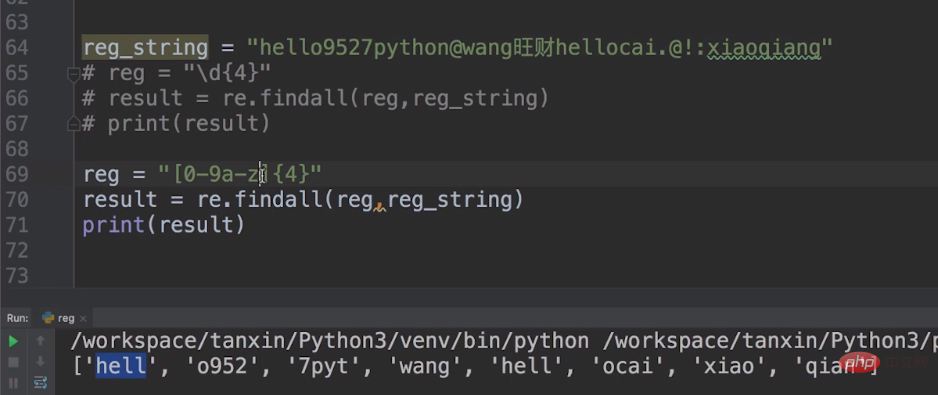
[0-9a-z] の範囲にない場合は、次の 4 つが [0-9a-z] に収まるまでスキップされます。範囲内で出力します。
インターネットでは、ホストには IP アドレスが 1 つだけあります。 IP アドレスは、TCP/IP 通信プロトコルで各コンピュータのアドレスを示すために使用され、通常は 192.168.1.100 のように 10 進数で表現されます。
ウィンドウ システムでは、ipconfig を通じて IP を確認できます。 Linux システムでは、ifconfig を通じて IP を表示できます。
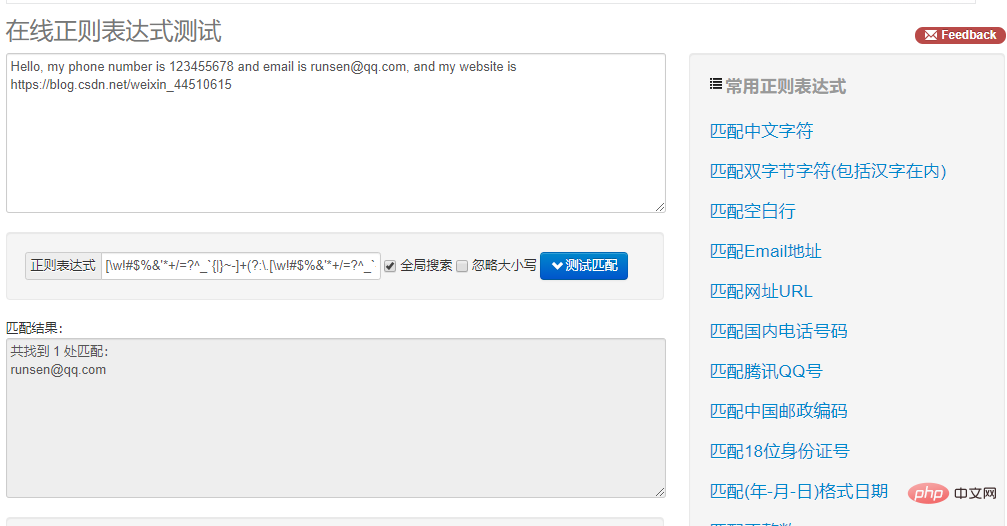
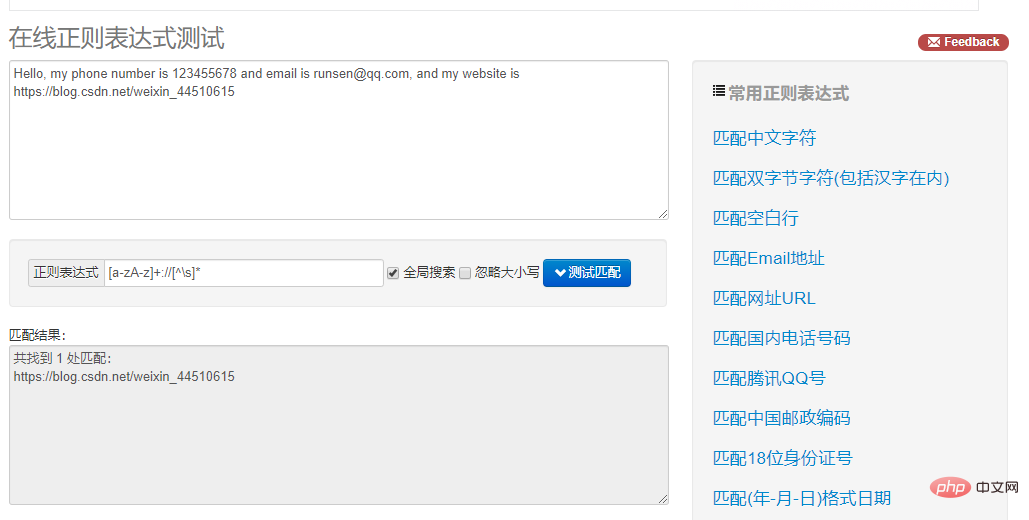
IP 文字列は次のようになります: ip = "this is ip:192.168.1.123 :172.138.2.15"
以下では正規表現の使用が必要です。 IP。
実際、私たちは主にメタキャラクターを書きます。例: reg = "\\\\d{3}.\\\\d .\\\\d .\\\\d ", 最初の数字は 3 桁で始まる必要があるため、 \\\\d{3} を設定して修正できます。
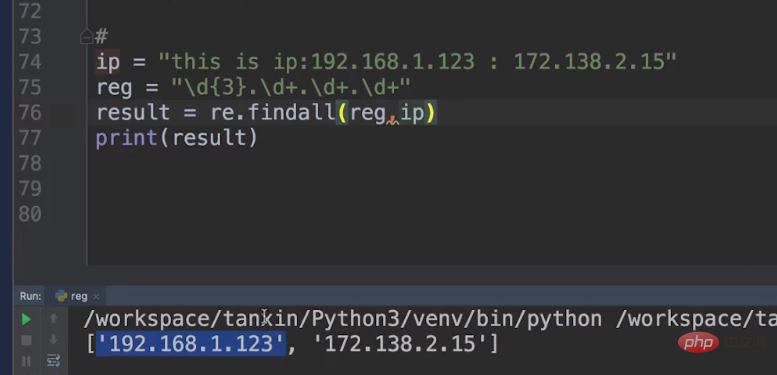 findall の使用に加えて、検索も使用できます。メタキャラクター
findall の使用に加えて、検索も使用できます。メタキャラクター reg = "(\\\\d{1,3}.){3}\\\ を置きます。 \d{1,3}"。
このメタキャラクターの \\\\d{1,3} は IP の最初の 3 桁を指定し、繰り返された後に {3} を追加します。 。 3回。 \\\\d{1,3} は、IP の最後の番号を指します。
しかし、search と findall には違いがあります。検索では最初のもののみに一致します。リストを使用して最初のものを削除する必要がありますが、findall はすべてに一致します。
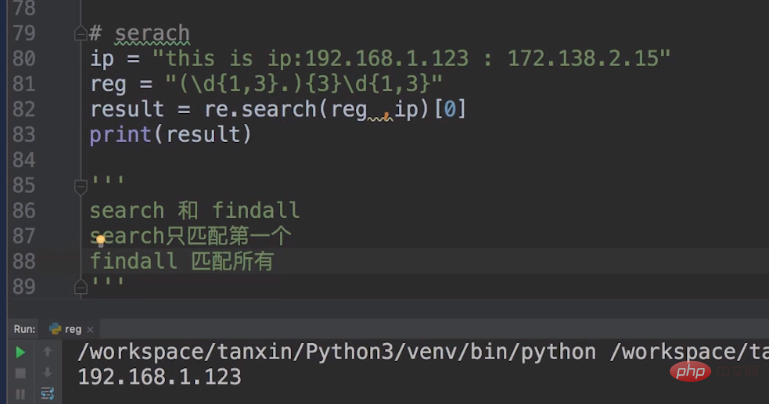
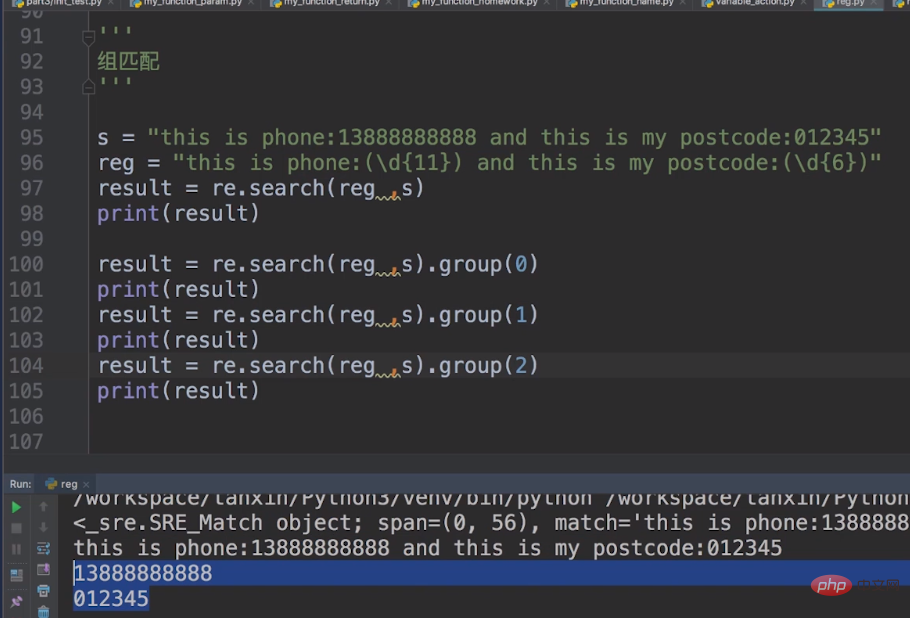
グループ マッチングとは何ですか? たとえば、ここに文字列がありますs = これは電話番号:13888888888 で、これは私の電話番号です。 postcode:012345、携帯電話番号と確認コードを照合してください。
2 つを一致させる必要があり、それぞれのメタキャラクターが異なるためです。したがって、グループマッチングが必要です。
正規表現内の括弧はグループの一致を示し、括弧内のパターンを使用してグループの内容を一致させることができます。
したがって、メタキャラクターは次のようになります: reg = これは電話番号:(\\\\d{11})、これは私の郵便番号:(\\\\d{6})
グループマッチングには検索を使うのが一般的ですが、前回はリストを使って検索する必要があると言いましたが、グループマッチングも同様ですが、ここではgroup()#を使います。 #方法。 group(1) は携帯電話番号を表し、group(2) は確認コードを表し、group(0) は携帯電話番号と確認を表します。コード. コードは下の図に示すとおりです。
これは re.I で、大文字と小文字を区別しないことを意味します。 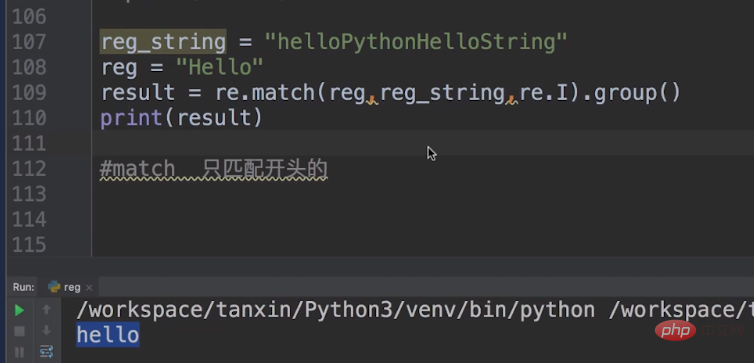
| 意味 | |
|---|---|
| ##重複ゼロまたは複数回 | |
| 1 回以上繰り返しました | |
| ゼロ回または 1 回繰り返します |
以上がPythonの正規表現を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

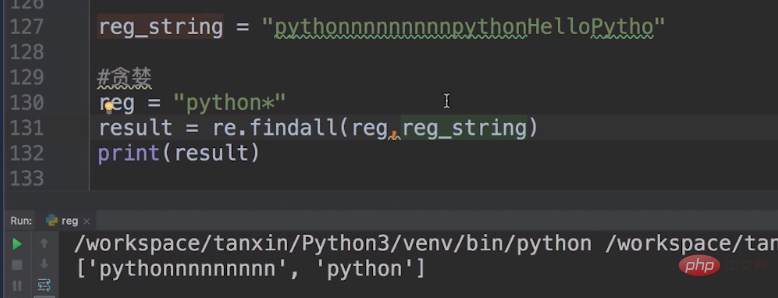
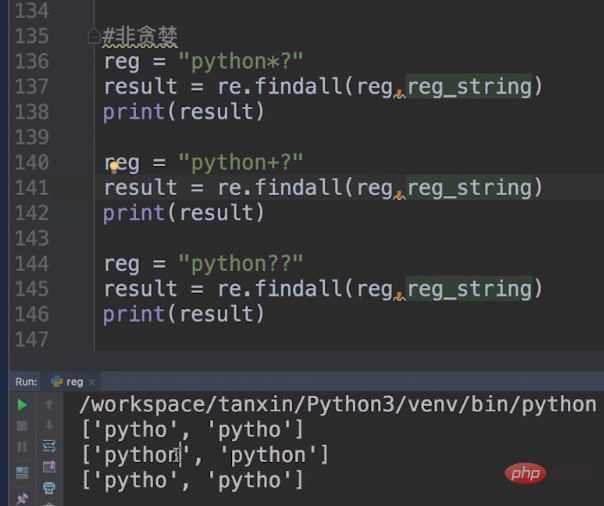 非贪婪模式下的
非贪婪模式下的
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



