

MySQLの結合機能が弱すぎるのでしょうか?

Todaymysql チュートリアル コラムでは join 関数を紹介します。

MySQL の結合については、多くの「逸話」をご存知かと思いますが、たとえば、2 つのテーブルの結合には、大きなテーブルを駆動するために小さなテーブルが必要です。 Alibaba の開発者仕様では、次の 3 つが禁止されています。 複数のテーブルの結合操作については、MySQL の結合機能は非常に弱いなどです。これらの規範や発言は、正しい場合もあれば間違っている場合もあり、正しい場合もあれば間違っている場合もあります。明確に理解するには、結合について深く理解する必要があります。
次に、MySQL の結合操作を包括的に見てみましょう。
テキスト
毎日のデータベース クエリでは、複数のテーブルを結合して、複数のテーブルのマージされたデータを一度に取得する必要がよくあります。これには、データベースで結合を使用する必要があります。 Join は、2 つのデータ セットをマージするためのデータ フィールドでの非常に一般的な操作です。これについて詳しく知っていれば、MySQL、Oracle、PostgreSQL、Spark のすべてがこの操作をサポートしていることがわかります。この記事の主役はMySQLであり、以下特に説明がない場合はMySQLのjoinを主体として説明します。 Oracle、PostgreSQL、Spark は、それらを打ち負かす大ボスと見なすことができ、アルゴリズムの最適化と結合の実装は MySQL よりも優れています。
MySQL の結合には多くのルールがあります。注意しないと、不適切な結合ステートメントによって特定のテーブルに対してフル テーブル クエリが発生するだけでなく、データベースのキャッシュにも影響を与える可能性があります。ほとんどのホットデータが置き換えられ、データベース全体のパフォーマンスが低下します。
したがって、業界は、小さなテーブルが大きなテーブルを駆動することや、3 つ以上のテーブルの結合操作を禁止することなど、MySQL 結合に関する多くの規範や原則をまとめました。以下では、MySQL の結合アルゴリズムを順番に紹介し、Oracle および Spark の結合実装と比較し、上記の仕様または原則が形成される理由についての答えを散りばめます。
結合操作の実装には、おそらくさらに 3 つの一般的なアルゴリズムがあります: Nested Loop Join (ループ ネスト結合)、Hash Join (ハッシュ結合)、Sort Merge Join (ソート マージ結合)# # #、それぞれメリット、デメリット、適用条件がありますので、次に順番に紹介していきます。
MySQL でのネストされたループ結合の実装ネストされたループ結合はドライバー テーブルをスキャンします。レコードが読み取られるたびに、関連するインデックスに基づいて、対応するデータが駆動テーブル内でクエリされます。結合のフィールドです。これは、接続するデータのサブセットが小さいシナリオに適しており、MySQL 結合の唯一のアルゴリズム実装でもあります。 MySQL のネスト ループ結合アルゴリズムには、インデックス ネスト ループ結合とブロック ネスト ループ結合という 2 つのバリエーションがあります。 インデックスのネストループ結合アルゴリズム次に、関連するテーブルの構造とデータを初期化しましょうCREATE TABLE `t1` ( `id` int(11) NOT NULL, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `a` (`a`) ) ENGINE=InnoDB; delimiter ;; # 定义存储过程来初始化t1 create procedure init_data() begin declare i int; set i=1; while(i上記のコマンドからわかるように、両方のテーブルにはプライマリキー インデックス ID とインデックス a がある場合、フィールド b にはインデックスがありません。ストアド プロシージャ init_data は、10,000 行のデータをテーブル t1 に挿入し、500 行のデータをテーブル t2 に挿入します。 <p></p>MySQL オプティマイザーがテーブルをドライバー テーブルとして選択し、分析された SQL ステートメントの実行プロセスに影響を与えるのを防ぐために、straight_join を直接使用して、MySQL がクエリに固定接続テーブル順序を使用できるようにします。次のステートメントでは、t1 はドライバー テーブル、t2 は駆動テーブルです。 <p></p><pre class="brush:php;toolbar:false">select * from t2 straight_join t1 on (t2.a=t1.a);复制代码
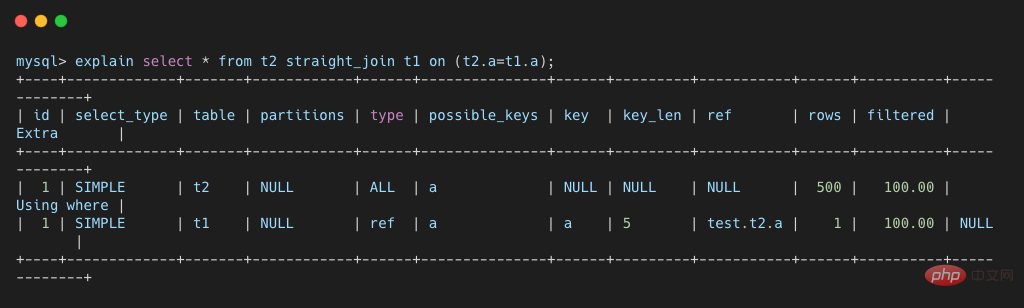
- t2 テーブルからデータ L1 の行を読み取ります;
- L1 のフィールドを使用して、t1 テーブルを条件としてクエリします;
- t1 の条件を満たすデータを取得する 条件付き行は L1 と対応する行を形成し、結果セットの一部になります;
- t2 テーブルがスキャンされるまで繰り返し実行されます。
2log2M です。明らかに、N はスキャンされる行の数に大きな影響を与えるため、この場合は小さなテーブルを駆動テーブルとして使用する必要があります。
もちろん、これらすべての前提は、結合の関連フィールドが a であり、t1 テーブルの a フィールドにインデックスがあるということです。如果没有索引时,再用上图的执行流程时,每次到 t1 去匹配的时候,就要做一次全表扫描。这也导致整个过程的时间复杂度编程了 N * M,这是不可接受的。所以,当没有索引时,MySQL 使用 Block Nested-Loop Join 算法。
Block Nested-Loop Join
Block Nested-Loop Join的算法,简称 MySQLの結合機能が弱すぎるのでしょうか?,它是 MySQL 在被驱动表上无可用索引时使用的 join 算法,其具体流程如下所示:
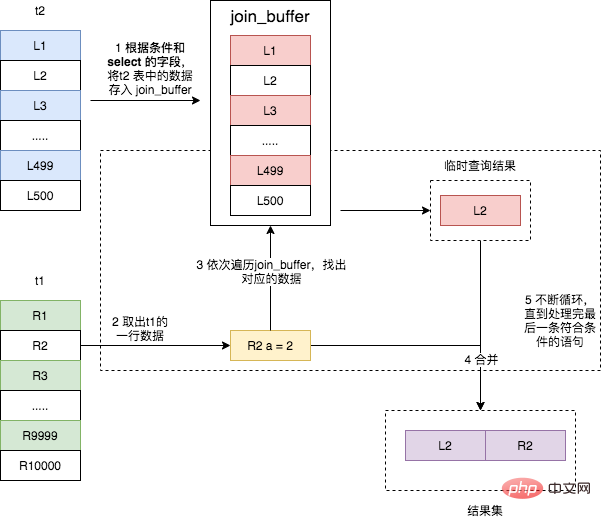
- 把表 t2 的数据读取当前线程的 join_buffer 中,在本篇文章的示例 SQL 没有在 t2 上做任何条件过滤,所以就是讲 t2 整张表 放入内存中;
- 扫描表 t1,每取出一行数据,就跟 join_buffer 中的数据进行对比,满足 join 条件的,则放入结果集。
比如下面这条 SQL
select * from t2 straight_join t1 on (t2.b=t1.b);复制代码
这条语句的 explain 结果如下所示。可以看出
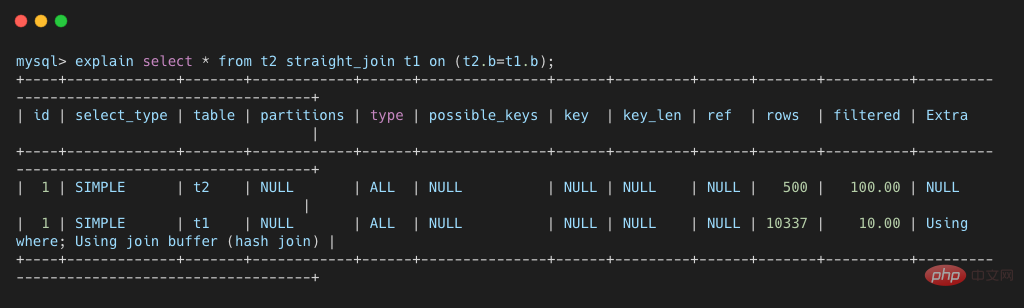
可以看出,这次 join 过程对 t1 和 t2 都做了一次全表扫描,并且将表 t2 中的 500 条数据全部放入内存 join_buffer 中,并且对于表 t1 中的每一行数据,都要去 join_buffer 中遍历一遍,都要做 500 次对比,所以一共要进行 500 * 10000 次内存对比操作,具体流程如下图所示。
主要注意的是,第一步中,并不是将表 t2 中的所有数据都放入 join_buffer,而是根据具体的 SQL 语句,而放入不同行的数据和不同的字段。比如下面这条 join 语句则只会将表 t2 中符合 b >= 100 的数据的 b 字段存入 join_buffer。
select t2.b,t1.b from t2 straight_join t1 on (t2.b=t1.b) where t2.b >= 100;复制代码
join_buffer 并不是无限大的,由 join_buffer_size 控制,默认值为 256K。当要存入的数据过大时,就只有分段存储了,整个执行过程就变成了:
- 扫描表 t2,将符合条件的数据行存入 join_buffer,因为其大小有限,存到100行时满了,则执行第二步;
- 扫描表 t1,每取出一行数据,就跟 join_buffer 中的数据进行对比,满足 join 条件的,则放入结果集;
- 清空 join_buffer;
- 再次执行第一步,直到全部数据被扫描完,由于 t2 表中有 500行数据,所以一共重复了 5次
这个流程体现了该算法名称中 Block 的由来,分块去执行 join 操作。因为表 t2 的数据被分成了 5 次存入 join_buffer,导致表 t1 要被全表扫描 5次。
| 全部存入 | 分5次存入 | |
|---|---|---|
| 内存操作 | 10000 * 500 | 10000 * (100 + 100 + 100 + 100 + 100) |
| 扫描行数 | 10000 + 500 | 10000 * 5 + 500 |
上に示したように、join_buffer にすべて格納できるテーブルデータと比較すると、メモリ判定数は変化せず、2 つのテーブルの行数の積、10000 * 500 になりますが、駆動されるテーブルは複数回スキャンされます。保存されるたびに駆動テーブルが再度スキャンされ、最終的な実行効率に影響します。
上記の 2 つのアルゴリズムに基づいて、次の結論を導き出すことができます。これは、インターネット上のほとんどの MySQL join ステートメントの標準でもあります。
駆動テーブルにインデックスが存在します。つまり、インデックス ネストループ結合アルゴリズムを使用できる場合、結合操作を使用できます。
インデックス ネストループ結合アルゴリズムであっても、ブロック ネストループ結合であっても、小さなテーブルを駆動テーブルとして使用する必要があります。
上記 2 つの結合アルゴリズム の時間計算量は少なくとも であるため、関係するテーブル内の行数と一次関係もあります。 、そしてそれは多くのメモリスペースを必要とするので、Alibabaの開発者の仕様が3つを超えるテーブルの結合操作を厳しく禁止していることは理解できます。
ただし、上記の 2 つのアルゴリズムは結合アルゴリズムの 1 つにすぎません。ハッシュ結合やソート マージ結合など、より効率的な結合アルゴリズムもあります。残念ながら、これら 2 つのアルゴリズムは現在、MySQL のメインストリーム バージョンでは利用できませんが、Oracle、PostgreSQL、Spark はすべてサポートしています。これが、MySQL に関するオンラインの苦情が非常に少ない理由でもあります。(MySQL 8.0 バージョンはハッシュ結合をサポートしています。ただし、現在 8.0 でサポートされています。まだ主流のバージョンではありません)。
実際、Alibaba の開発者仕様では、Oracle から MySQL に移行する場合、MySQL の結合操作のパフォーマンスが低すぎて、3 つを超えるテーブルの結合操作を禁止できないと規定されていました。
ハッシュ結合アルゴリズム
ハッシュ結合は、ドライバー テーブルをスキャンし、結合の関連フィールドを使用してメモリ内にハッシュ テーブルを作成し、次に駆動テーブルをスキャンして、データの各行を読み取ります。ハッシュ テーブルからのデータ 対応するデータを検索します。これは、大規模なデータ セット接続操作の一般的な方法です。ドライバー テーブルのデータ量が少なく、メモリに配置できるシナリオに適しています。インデックスのない 大きなテーブルに使用できますおよび並列クエリで最高のパフォーマンスを実現します。残念ながら、これは a.id = where b.a_id などの等結合シナリオにのみ適用されます。
これは依然として上記 2 つのテーブルの結合ステートメントであり、その実行プロセスは次のとおりです。
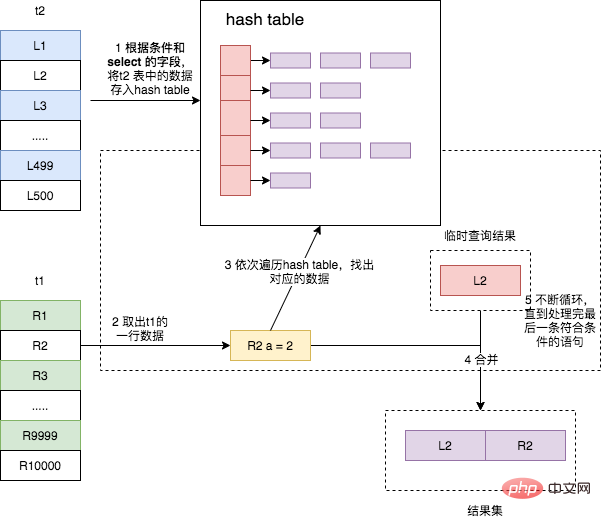
- から修飾されたデータを取り出します。ドライバー テーブル t2、および各行の結合フィールドの値がハッシュ化され、メモリ内のハッシュ テーブルに格納されます;
- ドリブン テーブル t1 を走査し、条件を満たすデータの各行が取り出されます、そして結合フィールドの値もハッシュされます。結果をメモリ内のハッシュ テーブルに取得して、一致するものを見つけます。見つかった場合は、結果セットの一部になります。
このアルゴリズムは、順序なしの結合バッファーがハッシュ テーブルのハッシュ テーブルに変更され、データが一致しないことを除けば、ブロック ネストループ結合に似ていることがわかります。結合バッファー内のすべてのデータを走査する必要はなくなり、ハッシュを直接使用して、O(1) に近い時間計算量で一致する行 を取得します。これにより、2 つのテーブルの結合速度が大幅に向上します。
ただし、ハッシュの特性により、このアルゴリズムは同等の接続シナリオにのみ適用でき、他の接続シナリオでは使用できません。
ソートマージ結合アルゴリズム
ソートマージ結合は、まず、結合の関連フィールドに従って 2 つのテーブルをソートします (フィールドにインデックスがある場合など、すでにソートされている場合は、再度並べ替える必要はありません)、2 つのテーブルに対してマージ操作を実行します。 2 つのテーブルがソートされている場合、ソート・マージ結合を実行するときに再度ソートする必要はなく、この場合、マージ結合のパフォーマンスはハッシュ結合よりも優れています。マージ結合は、等価でない結合 (>、=、 は含まれません) に適用できます。
接続されたフィールドに既にインデックスがある場合、つまり並べ替えられている場合は、結合操作を直接実行できますが、接続されたフィールドにインデックスがない場合は注意してください。 、その実行プロセスは次のようになります。
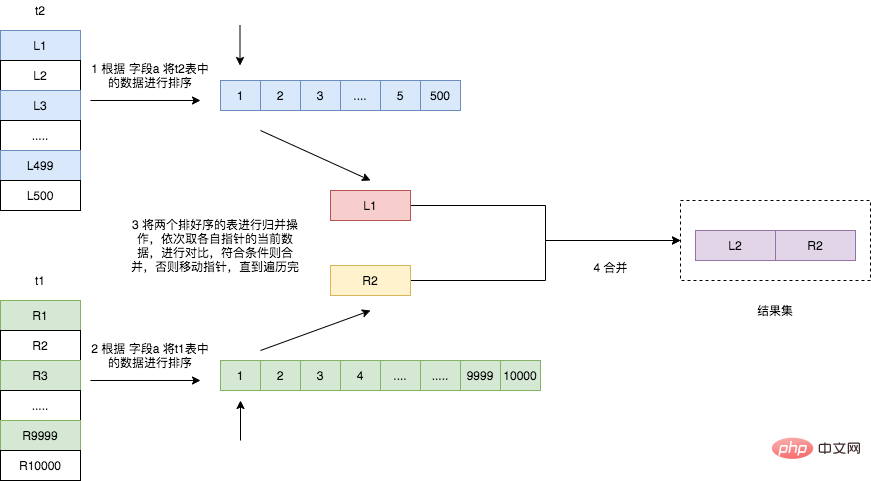
- テーブル t2 を走査し、条件を満たすデータを読み取り、接続フィールド a の値に従って並べ替えます。
- Traverse table t1, 条件を満たすデータを読み取り、接続フィールド a の値に従って並べ替えます;
- 並べ替えられた 2 つのデータを結合して結果セットを取得します。
ソート マージ結合アルゴリズムの主な時間消費は 2 つのテーブルの並べ替え操作であるため、2 つのテーブルが接続フィールドに従って並べ替えられている場合、アルゴリズムはハッシュよりもさらに高速になります。結合アルゴリズム。場合によっては、このアルゴリズムは、Nested Loop Join アルゴリズムよりも高速です。
ここで、上記 3 つのアルゴリズムの違い、メリット、デメリットをまとめてみましょう。
| ハッシュ結合 | ソートされたマージ結合 | ||
|---|---|---|---|
| すべての条件に適用されます | 等価接続 (=) | 等価または非等価接続 ( >, =、'を除く | |
| CPU、ディスク I/O | メモリ、一時領域 | メモリ、一時領域 | |
| 選択性の高いインデックスや限定的なインデックスがある場合の検索効率は比較的高い値であり、最初の検索結果をすぐに返すことができます。 | インデックスが不足している場合、またはインデックスの条件があいまいな場合は、ネスト ループよりもハッシュ結合の方が効果的です。通常、マージ結合よりも高速です。データ ウェアハウス環境では、テーブルのレコード数が多い場合に効率が高くなります。 | インデックスが不足している場合やインデックスの条件があいまいな場合は、ネスト ループよりもソート マージ ジョインの方が効果的です。接続フィールドにインデックスがあるか、事前にソートされている場合、ハッシュ結合よりも高速で、より多くの接続条件をサポートします。 | |
| インデックスやインデックスがない場合の効率テーブル レコードの数が多い 低い | ハッシュ テーブルの構築には大量のメモリが必要で、最初の結果が返されるのが遅い | すべてのテーブルを並べ替える必要があります。最適なスループットを実現するように設計されており、すべての結果が見つかるまでデータは返されません | |
| はい (インデックスなしは非効率的です) | No | No |
- 1 つのデータベース操作、使用結合操作、順序テーブル、およびユーザー テーブル結合を実行し、ユーザー名とともに返します。
- 2 つのデータベース操作、2 つのクエリ、1 回目は注文情報と user_id を取得、2 回目は取得user_id に基づいて名前を付け、コード プログラムを使用して情報をマージします。
- 冗長なユーザー名を使用するか、ES などの非リレーショナル データベースから読み取ります。
#その他の関連する無料学習の推奨事項:mysql チュートリアル(ビデオ)
以上がMySQLの結合機能が弱すぎるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7720
7720
 15
1642
14
1396
52
1289
25
1233
29
15
1642
14
1396
52
1289
25
1233
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
 Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは、Webアプリケーションを簡単に構築するためのPHPフレームワークです。次のような強力な機能を提供します。インストール:Laravel CLIを作曲家にグローバルにインストールし、プロジェクトディレクトリにアプリケーションを作成します。ルーティング:ルート/web.phpのURLとハンドラーの関係を定義します。ビュー:リソース/ビューでビューを作成して、アプリケーションのインターフェイスをレンダリングします。データベース統合:MySQLなどのデータベースとのすぐ外側の統合を提供し、移行を使用してテーブルを作成および変更します。モデルとコントローラー:モデルはデータベースエンティティを表し、コントローラーはHTTP要求を処理します。
