


まず、データベース テーブル、デモンストレーション用の MySQL テーブル、およびテーブル作成ステートメントを構築します。
CREATE TABLE `emp` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `empno` int(11) DEFAULT NULL COMMENT '雇员工号', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `mgr` varchar(255) DEFAULT NULL COMMENT '经理的工号', `hiredate` date DEFAULT NULL COMMENT '雇用日期', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', `deptno` int(11) DEFAULT NULL COMMENT '所属部门号', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='雇员表';CREATE TABLE `dept` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `deptno` int(11) DEFAULT NULL COMMENT '部门号', `dname` varchar(255) DEFAULT NULL COMMENT '部门名称', `loc` varchar(255) DEFAULT NULL COMMENT '地址', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='部门表';CREATE TABLE `salgrade` ( `id` int(11) NOT NULL COMMENT '主键', `grade` varchar(255) DEFAULT NULL COMMENT '等级', `lowsal` varchar(255) DEFAULT NULL COMMENT '最低工资', `hisal` varchar(255) DEFAULT NULL COMMENT '最高工资', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='工资等级表';CREATE TABLE `bonus` ( `id` int(11) NOT NULL COMMENT '主键', `ename` varchar(255) DEFAULT NULL COMMENT '雇员姓名', `job` varchar(255) DEFAULT NULL COMMENT '工作', `sal` double DEFAULT NULL COMMENT '工资', `comm` double DEFAULT NULL COMMENT '津贴', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='奖金表';复制代码
その後の実行計画、クエリの最適化、インデックスの最適化、その他のナレッジ ドリルは次のとおりです。上記の表に基づいて動作します。
SQL チューニングを実行するには、チューニング対象の SQL ステートメントがどのように実行されるかを理解し、高速化するために SQL ステートメントの具体的な実行プロセスを確認する必要があります。 SQL ステートメントの実行効率。
explain SQL ステートメントを使用すると、SQL クエリ ステートメントを実行するオプティマイザをシミュレートし、MySQL が SQL ステートメントをどのように処理するかを知ることができます。
説明については、公式Webサイトの紹介文をご覧ください。
mysql> explain select * from emp; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
フィールド id、select_type およびその他のフィールドの説明:
| 列 | 意味 | ||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id |
SELECT識別子) |
||||||||||||||||||||||||||||||||||
| select_type |
SELECT タイプ(SELECT タイプ) |
||||||||||||||||||||||||||||||||||
| テーブル出力行の場合 (行のテーブル名を出力) | |||||||||||||||||||||||||||||||||||
| 一致するパーティション (一致するパーティション) | |||||||||||||||||||||||||||||||||||
| 結合タイプ | |||||||||||||||||||||||||||||||||||
| 選択可能なインデックス (可能なインデックス選択) | |||||||||||||||||||||||||||||||||||
| 実際に選択されたインデックス | |||||||||||||||||||||||||||||||||||
| 選択されたキーの長さ (選択されたキーの長さ) | |||||||||||||||||||||||||||||||||||
| インデックスと比較された列 (インデックスと比較された列) | |||||||||||||||||||||||||||||||||||
| 行数の推定検査対象 | |||||||||||||||||||||||||||||||||||
| テーブル条件によってフィルタリングされた行の割合 (テーブル条件によってフィルタリングされた行の割合) | |||||||||||||||||||||||||||||||||||
select_type Value |
JSON Name | Meaning |
|---|---|---|
| SIMPLE | None | Simple SELECT (not using UNION or subqueries) |
| PRIMARY | None | Outermost SELECT |
| UNION | None | Second or later SELECT statement in a UNION |
| DEPENDENT UNION | dependent (true) | Second or later SELECT statement in a UNION, dependent on outer query |
| UNION RESULT | union_result | Result of a UNION. |
| SUBQUERY | None | First SELECT in subquery |
| DEPENDENT SUBQUERY | dependent (true) | First SELECT in subquery, dependent on outer query |
| DERIVED | None | Derived table |
| MATERIALIZED | materialized_from_subquery | Materialized subquery |
| UNCACHEABLE SUBQUERY | cacheable (false) | A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query |
| UNCACHEABLE UNION | cacheable (false) | The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY) |
SIMPLE 简单的查询,不包含子查询和unionmysql> explain select * from emp; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+| 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+复制代码
primary 查询中若包含任何复杂的子查询,最外层查询则被标记为Primaryunion 若第二个select出现在union之后,则被标记为unionmysql> explain select * from emp where deptno = 1001 union select * from emp where sal | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条语句的select_type包含了primary和union
dependent union 跟union类似,此处的depentent表示union或union all联合而成的结果会受外部表影响union result 从union表获取结果的selectdependent subquery subquery的子查询要受到外部表查询的影响mysql> explain select * from emp e where e.empno in ( select empno from emp where deptno = 1001 union select empno from emp where sal | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary | +----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+复制代码
这条SQL执行包含了PRIMARY、DEPENDENT SUBQUERY、DEPENDENT UNION和UNION RESULT
subquery 在select或者where列表中包含子查询举例:
mysql> explain select * from emp where sal > (select avg(sal) from emp) ; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 33.33 | Using where | | 2 | SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | NULL | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
DERIVED from子句中出现的子查询,也叫做派生表MATERIALIZED Materialized subquery?UNCACHEABLE SUBQUERY 表示使用子查询的结果不能被缓存例如:
mysql> explain select * from emp where empno = (select empno from emp where deptno=@@sort_buffer_size); +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| 1 | PRIMARY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 100.00 | Using where | | 2 | UNCACHEABLE SUBQUERY | emp | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where | +----+----------------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+复制代码
uncacheable union 表示union的查询结果不能被缓存table
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集。
- 如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别名
- 表名是derivedN的形式,表示使用了id为N的查询产生的衍生表
- 当有union result的时候,表名是union n1,n2等的形式,n1,n2表示参与union的id
type
type显示的是访问类型,访问类型表示我是以何种方式去访问我们的数据,最容易想到的是全表扫描,直接暴力的遍历一张表去寻找需要的数据,效率非常低下。
访问的类型有很多,效率从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情况下,得保证查询至少达到range级别,最好能达到ref
all 全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化通常,可以通过添加索引来避免ALL
index 全索引扫描这个比all的效率要好,主要有两种情况:range 表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描,适用的操作符: =, , >, >=, 官网上举例如下:
SELECT * FROM tbl_name WHERE key_column = 10;
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
index_subquery 利用索引来关联子查询,不再扫描全表value IN (SELECT key_column FROM single_table WHERE some_expr)
unique_subquery 该连接类型类似与index_subquery,使用的是唯一索引value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_merge 在查询过程中需要多个索引组合使用ref_or_null 对于某个字段既需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
fulltext 使用FULLTEXT索引执行joinref 使用了非唯一性索引进行数据的查找SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
eq_ref 使用唯一性索引进行数据查找SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
const 这个表至多有一个匹配行SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2;
例如:
mysql> explain select * from emp where id = 1; +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+| 1 | SIMPLE | emp | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL | +----+-------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+-------+复制代码
system 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现possible_keys
显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用

key
实际使用的索引,如果为null,则没有使用索引,查询中若使用了覆盖索引,则该索引和查询的select字段重叠

key_len
表示索引中使用的字节数,可以通过key_len计算查询中使用的索引长度,在不损失精度的情况下长度越短越好
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数
rows
根据表的统计信息及索引使用情况,大致估算出找出所需记录需要读取的行数,此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好

extra
包含额外的信息
using filesort 说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置using temporary 建立临时表来保存中间结果,查询完成之后把临时表删除using index 这个表示当前的查询是覆盖索引的,直接从索引中读取数据,而不用访问数据表。如果同时出现using where 表明索引被用来执行索引键值的查找,如果没有,表示索引被用来读取数据,而不是真的查找using where 使用where进行条件过滤using join buffer 使用连接缓存impossible where where语句的结果总是false想要了解索引的优化方式,必须要对索引的底层原理有所了解。
索引用于快速查找具有特定列值的行。
如果没有索引,MySQL必须从第一行开始,然后通读整个表以找到相关的行。
表越大花费的时间越多,如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
既然MySQL索引能帮助我们快速查询到数据,那么它的底层是怎么存储数据的呢?
hash
hash表的索引格式

データをハッシュ テーブルに保存するデメリット:
実際、MySQL ストレージ エンジンが memory の場合、インデックス データ構造はハッシュ テーブルを使用します。
バイナリ ツリー
バイナリ ツリーの構造は次のとおりです。
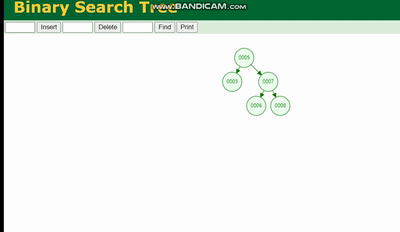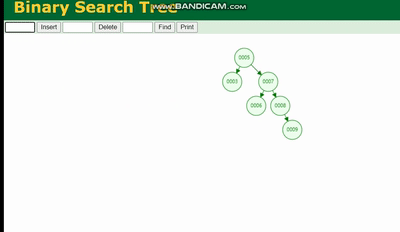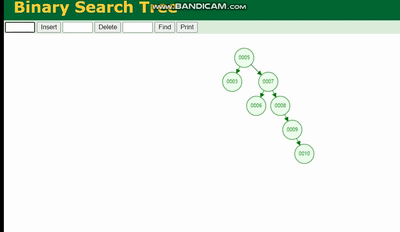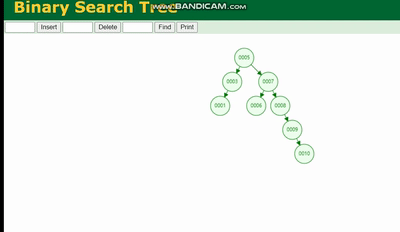
バイナリ ツリーは、ツリーの深さによるデータ損失 チルトでツリーの深さが深すぎると、IO 時間が増加し、データ読み取りの効率に影響します。
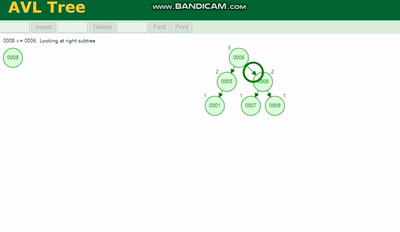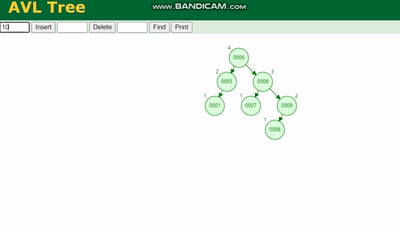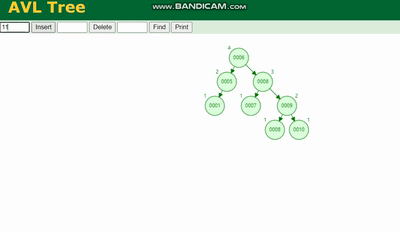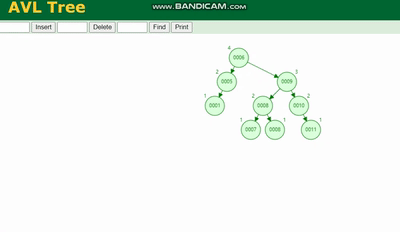
AVL ツリー 回転する必要があります。凡例を参照してください:
赤黒ツリー回転以外の操作 色変更関数 (回転を減らすため)、挿入速度は速いですが、クエリ効率が失われます。
バイナリ ツリー 、AVL ツリー 、赤黒ツリー はすべて深度によって引き起こされます。ツリーが深すぎるとIO回数が増加し、データの読み込み効率に影響します。
B ツリーを見てみましょう
B ツリーの特徴: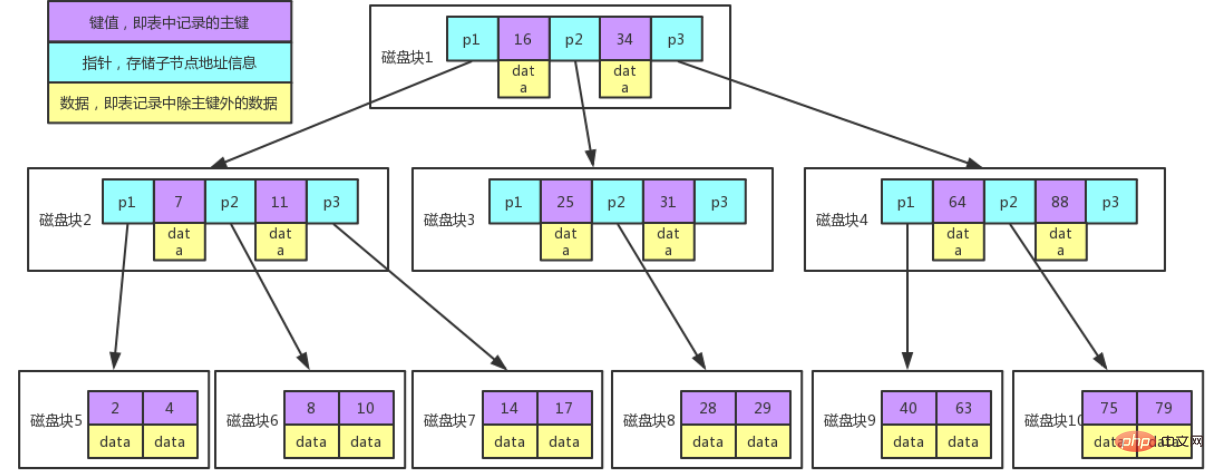
凡例の説明:
各ノードは 1 つのディスク ブロックを占有します。ノード上には 2 つの昇順キーと、サブツリーのルート ノードへの 3 つのポインターがあります。ポインターには、子ノードが配置されているディスク ブロックのアドレスが格納されます。 2 つのキーワードで区切られた 3 つの範囲は、3 つのポインタが指すサブツリーのデータの範囲に対応します。 ルート ノードを例にとると、キーワードは 16 と 34 です。P1 ポインタが指すサブツリーのデータ範囲は 16 未満で、P2 ポインタが指すサブツリーのデータ範囲は 16 です。 ~34、および P3 ポインタが指すデータ範囲 サブツリーのデータ範囲が 34 より大きい。 キーワード検索プロセス: 1. ルート ノードに基づいてディスク ブロック 1 を見つけ、メモリに読み込みます。 [ディスク I/O 操作 1 回目]2. 区間 (16,34) のキーワード 28 を比較し、ディスク ブロック 1 のポインタ P2 を見つけます。 3. P2 ポインタに従ってディスク ブロック 3 を見つけ、メモリに読み取ります。 [ディスク I/O 操作 2 回目]4. 区間 (25,31) のキーワード 28 を比較し、ディスク ブロック 3 のポインタ P2 を見つけます。 5. P2 ポインタに従ってディスク ブロック 8 を見つけ、それをメモリに読み取ります。 [ディスク I/O 操作 3 回目]6. ディスク ブロック 8 のキーワード リストでキーワード 28 を見つけます。 これから、B ツリー ストレージの欠点がわかります:に保存されます。誤解しないでください。実際、MySQL インデックスのストレージ構造はB ツリー
です。上記の分析後、 B ツリー は不適切であることを知ってください。
B ツリーは BTree に基づく最適化であり、次の変更が加えられています:
1. それぞれB ツリーのノードには、より多くのノードを含めることができます。これには 2 つの理由があります。1 つ目は、ツリーの高さを減らすためです。2 つ目は、データ範囲を複数の間隔に変更するためです。多いほど、データの取得が速くなります。 。
2. 非リーフ ノードはキーを保存し、リーフ ノードはキーとデータを保存します。
3. リーフ ノードの 2 つのポインターが (ディスクの先読み特性に合わせて) 相互に接続されており、シーケンシャル クエリのパフォーマンスが高くなります。
B ツリー ストレージ検索図:
注意:
在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。
因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
由于B+树叶子结点只存放data,根节点只存放key,那么我们计算一下,即使只有3层B+树,也能制成千万级别的数据。
假设有这样一个表如下,其中id是主键:
mysql> select * from stu; +------+---------+------+| id | name | age | +------+---------+------+| 1 | Jack Ma | 18 | | 2 | Pony | 19 | +------+---------+------+复制代码
我们对普通列建普通索引,这时候我们来查:
select * from stu where name='Pony';复制代码
由于name建了索引,查询时先找name的B+树,找到主键id后,再找主键id的B+树,从而找到整行记录。
这个最终会回到主键上来查找B+树,这个就是回表。
如果是这个查询:
mysql> select id from stu where name='Pony';复制代码
就没有回表了,因为直接找到主键id,返回就完了,不需要再找其他的了。
没有回表就叫覆盖索引。
再来以name和age两个字段建组合索引(name, age),然后有这样一个查询:
select * from stu where name=? and age=?复制代码
这时按照组合索引(name, age)查询,先匹配name,再匹配age,如果查询变成这样:
select * from stu where age=?复制代码
直接不按name查了,此时索引不会生效,也就是不会按照索引查询---这就是最左匹配原则。
加入我就要按age查,还要有索引来优化呢?可以这样做:
age字段单独建个索引可能也叫
谓词下推。。。
select t1.name,t2.name from t1 join t2 on t1.id=t2.id复制代码
t1有10条记录,t2有20条记录。
我们猜想一下,这个要么按这个方式执行:
先t1,t2按id合并(合并后20条),然后再查t1.name,t2.name
或者:
先把t1.name,t2.name找出来,再按照id关联
如果不使用索引条件下推优化的话,MySQL只能根据索引查询出t1,t2合并后的所有行,然后再依次比较是否符合全部条件。
当使用了索引条件下推优化技术后,可以通过索引中存储的数据判断当前索引对应的数据是否符合条件,只有符合条件的数据才将整行数据查询出来。
Explain 为了知道优化SQL语句的执行,需要查看SQL语句的具体执行过程,以加快SQL语句的执行效率。更多相关免费学习推荐:mysql教程(视频)
以上がMySQL実行プランの説明とインデックスデータ構造の推論の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



