

最後に、MySQL インデックスは B+tree を使用する必要があり、それが非常に高速であることを理解しました。

mysql チュートリアル 列では、インデックスを理解するための B ツリーを紹介します。

無料の推奨事項: mysql チュートリアル(ビデオ)
はじめに
遅い SQL に遭遇し、それを最適化する必要がある場合、すぐにどのような最適化方法を思いつくでしょうか?
ほとんどの人の最初の反応は、インデックスの追加でしょう。ほとんどの場合、index で SQL ステートメントにクエリを追加できます。効率は次のとおりです。数 桁 改善されました。
インデックスの本質: レコードを迅速に検索するために使用される データ構造。
一般的に使用されるインデックスデータ構造:
- バイナリ ツリー
- 赤黒ツリー
- ハッシュ テーブル
-
B-tree(B ツリーは B マイナス ツリーとは呼ばれません) B ツリー
データ構造グラフィカルWebサイト: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
インデックス クエリ
誰もが知っているselect * from t where Col = 88 このような SQL ステートメントがインデックスを使用せずに検索される場合、通常の検索は full table scan: テーブルの最初の行から開始して行ごとに検索します。各行の col フィールドの値を 88 と比較すると、これは明らかに非常に非効率的です。
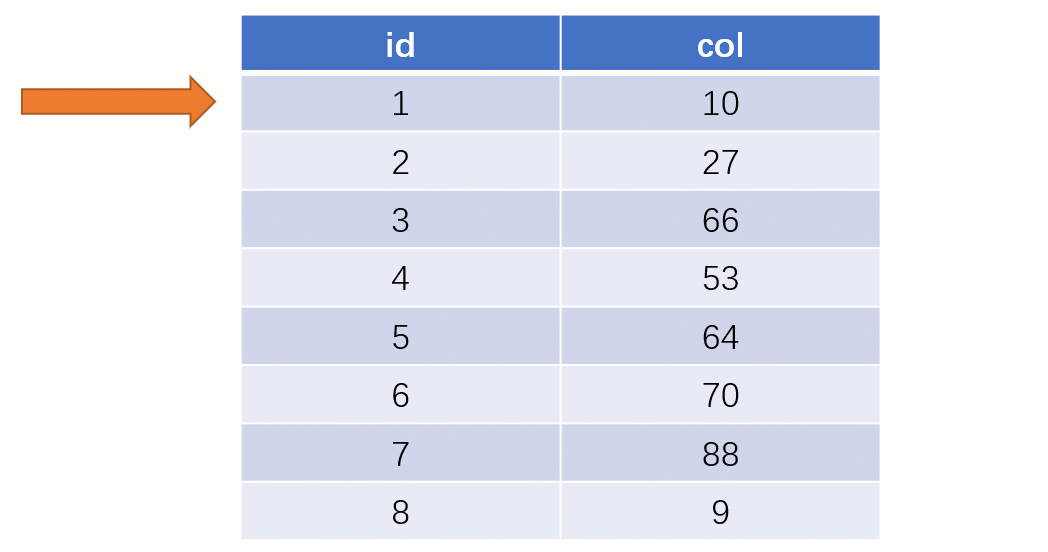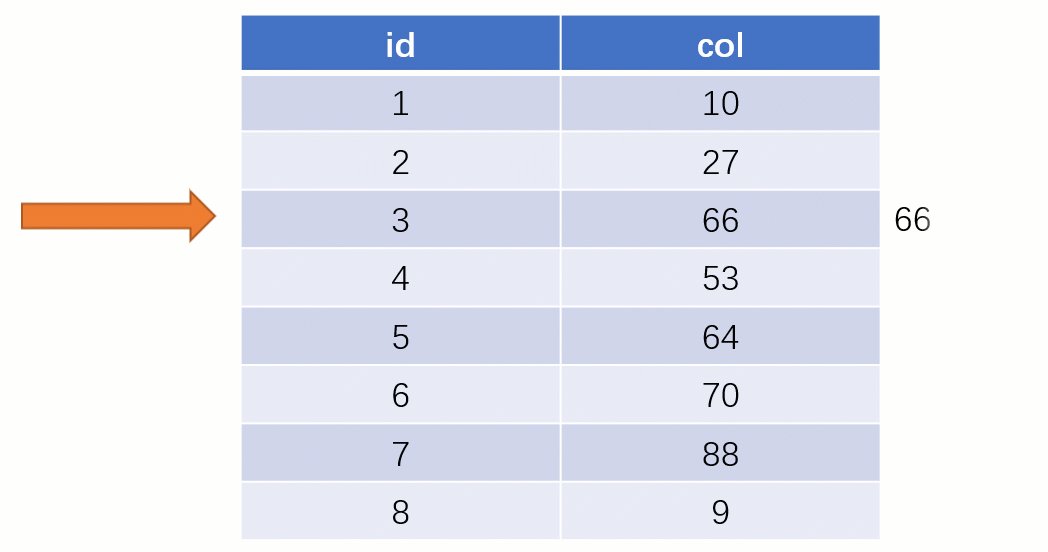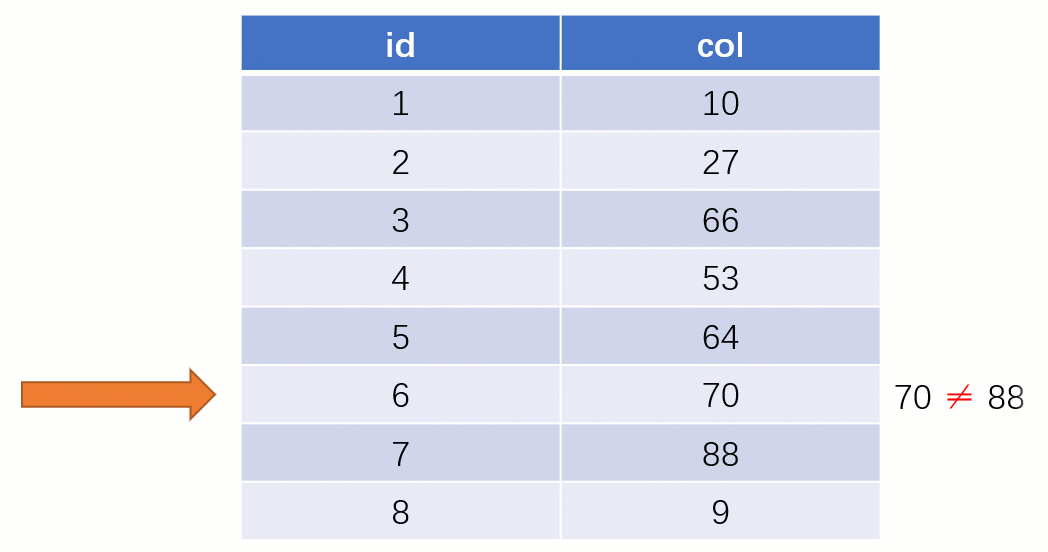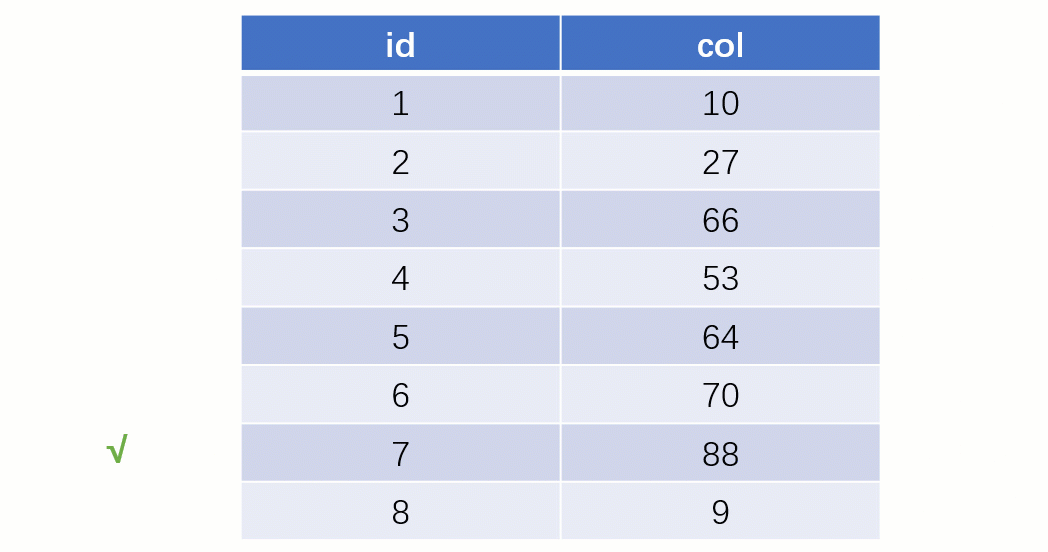
また、インデックスを使用する場合、クエリ プロセスは完全に異なります (インデックス列の格納に バランス バイナリ ツリー データ構造が使用されていると仮定します) )
このときのバイナリツリーの格納構造 (Key - Value): Key はインデックスフィールドのデータ、Value はインデックスが配置されている行のディスクファイルアドレスです。
最終的に 88 が見つかったら、その値に対応するディスク ファイル アドレスを取り出し、ディスクに直接アクセスしてこのデータ行を見つけます。フルテーブルスキャンよりもはるかに高速になります。
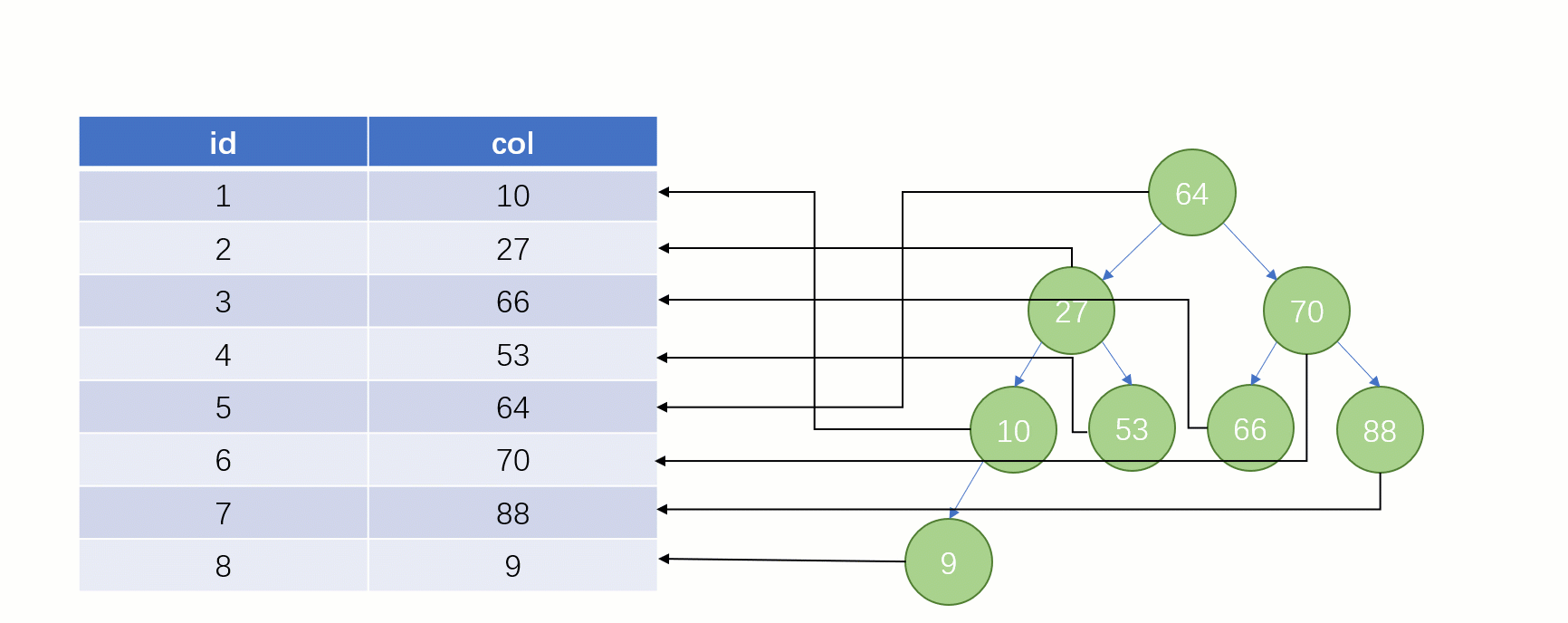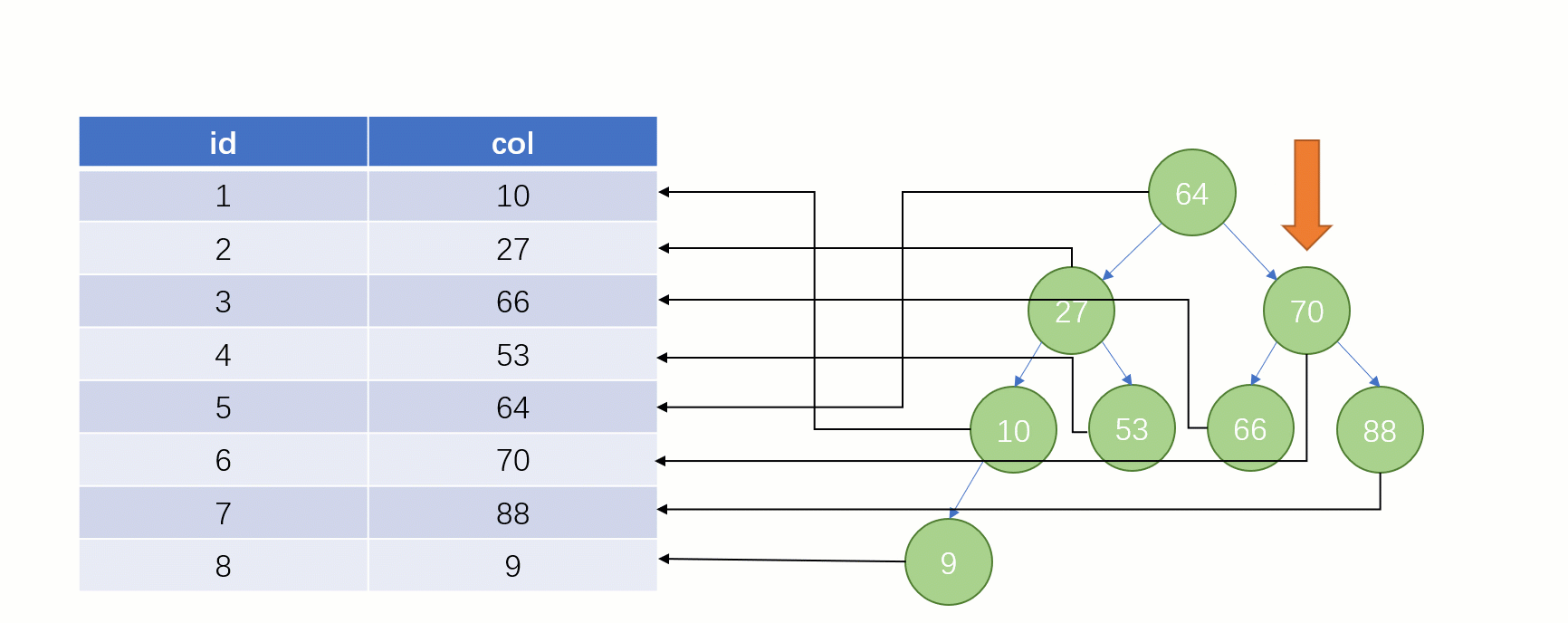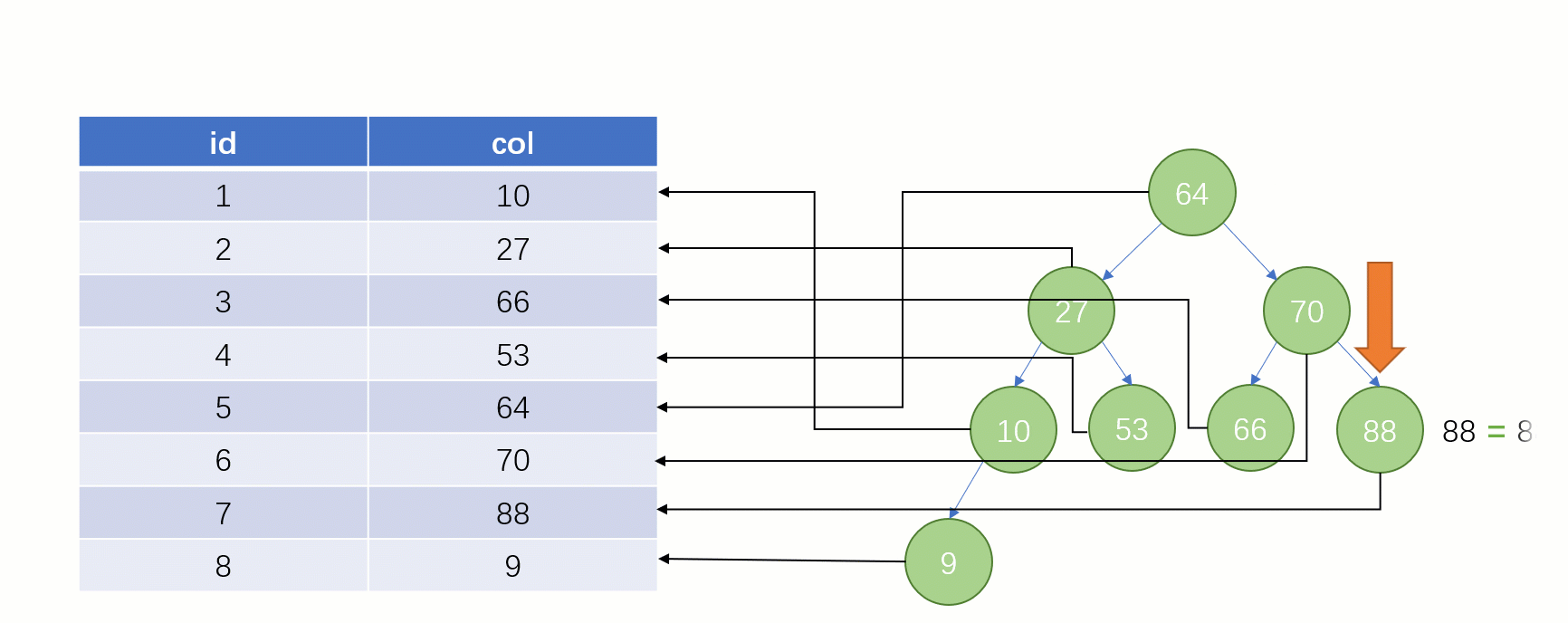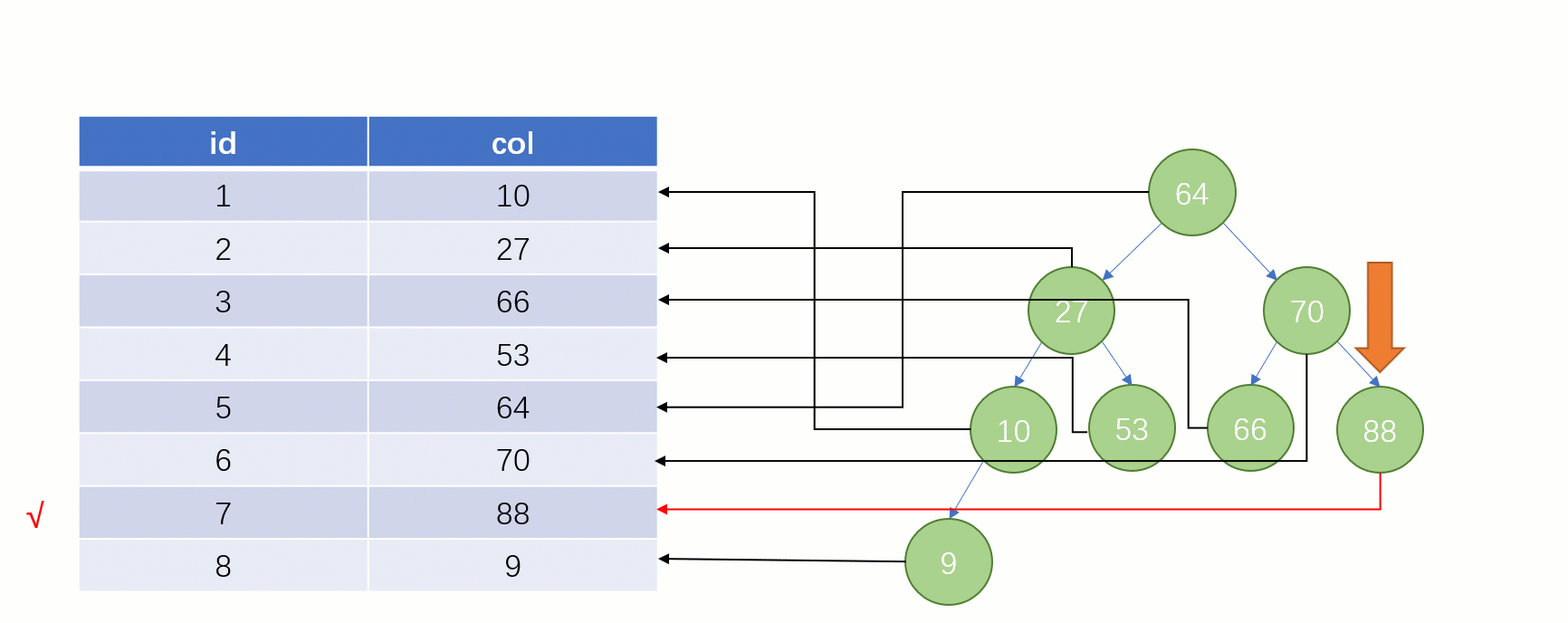
しかし実際には MySQL 最下層はインデックス データの保存に バイナリ ツリーを使用しません。 Bツリー(Bツリー)を使用します。
バイナリ ツリーを使用しない理由
通常のバイナリ ツリーを使用して id インデックス列を記録すると仮定すると、レコードの列。
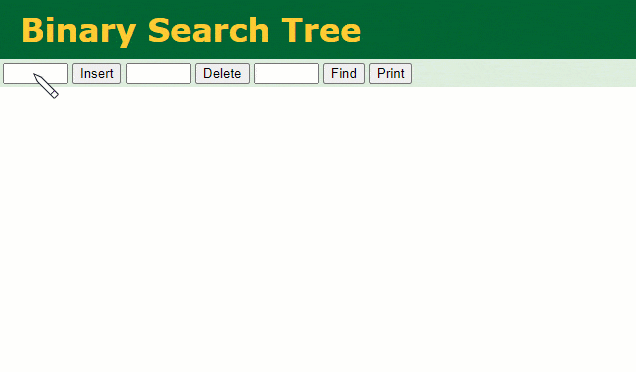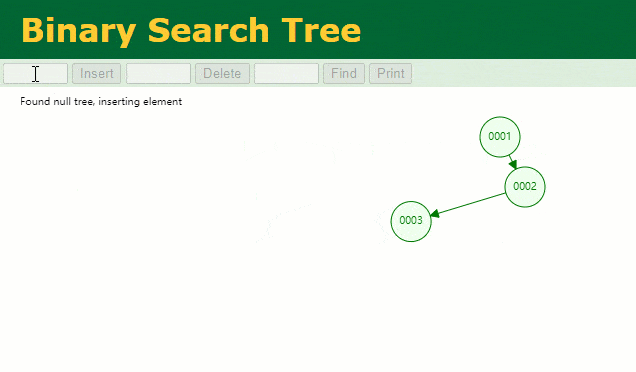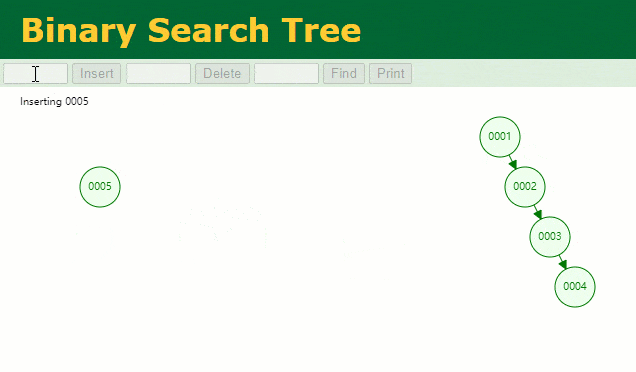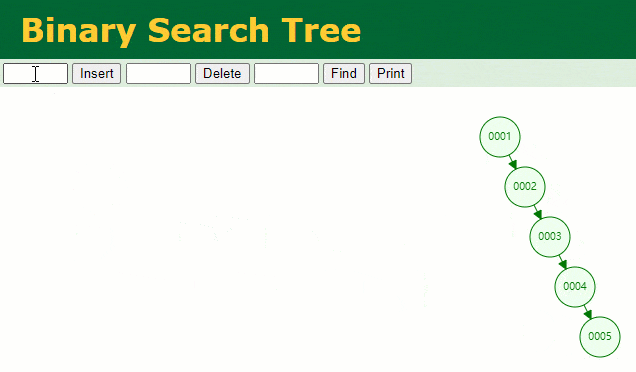
このとき、id = 7 のデータを探したい場合、検索処理は次のようになります。
 この時点では、行
この時点では、行
7 回検索しましたが、これはテーブル全体のスキャンとあまり変わりません。明らかに、バイナリ ツリーは実際には、この 増加する データ列のインデックスとして 不適切なデータ構造です。 ハッシュ テーブルを使用しない理由
ハッシュ テーブル: 高速検索のためのデータ構造、検索の時間計算量は O(1)
ハッシュ関数: 変換a 任意のタイプのキーを int タイプの添字に変換できます。インデックス列を記録すると仮定して、レコードの行を同時にハッシュ テーブルのインデックス フィールドを保守します。ハッシュ テーブルを使用して
id
現時点では、 id = 7
id = 7
1 回のみ検索されており、非常に効率的です。
しかし、 MySQL
MySQL
ハッシュ テーブルを使用していません。 は 範囲クエリ に適用されないためです。 赤黒ツリーを使用しない理由赤黒ツリーは特殊な AVL ツリー (バランス バイナリ ツリー) であり、挿入および削除操作中の特定の操作を通じて維持されます。二分探索ツリーのバランス;
この時点で赤黒ツリー レコード id インデックス列が使用されると仮定すると、レコードの行を挿入する間、赤黒ツリー インデックス フィールドを維持する必要があります。

挿入プロセス中に、ツリーの左右のサブツリー間の高さの差が 1 より大きい場合、通常のバイナリ ツリーとは異なることがわかります。 スピン オペレーションを実行して、ツリーのバランスを保ちます。
このとき、id = 7 のツリーノードは 3 回しか検索されず、いわゆる通常の二分木よりも高速です。
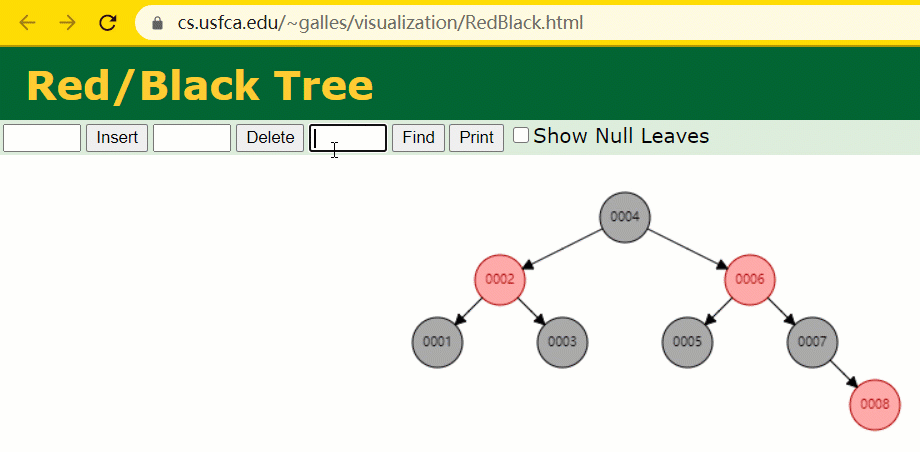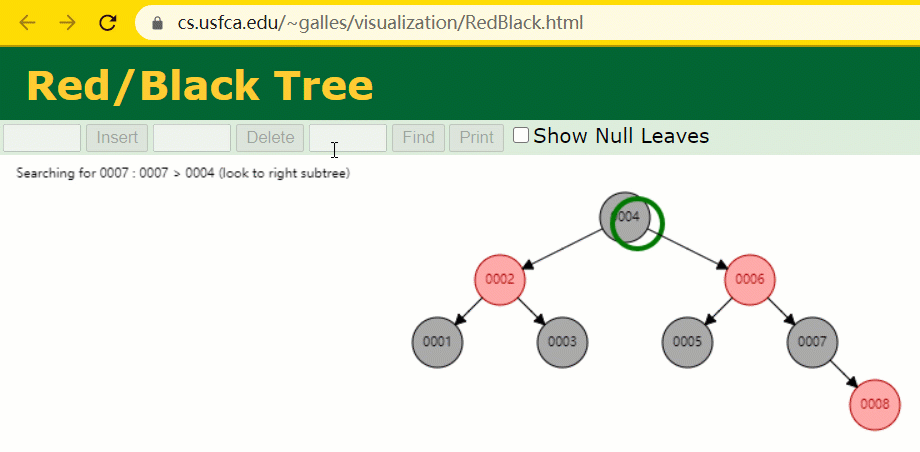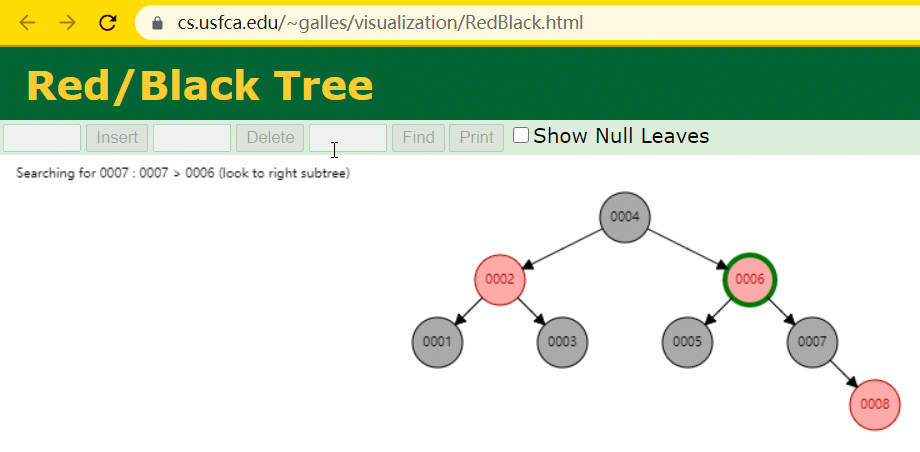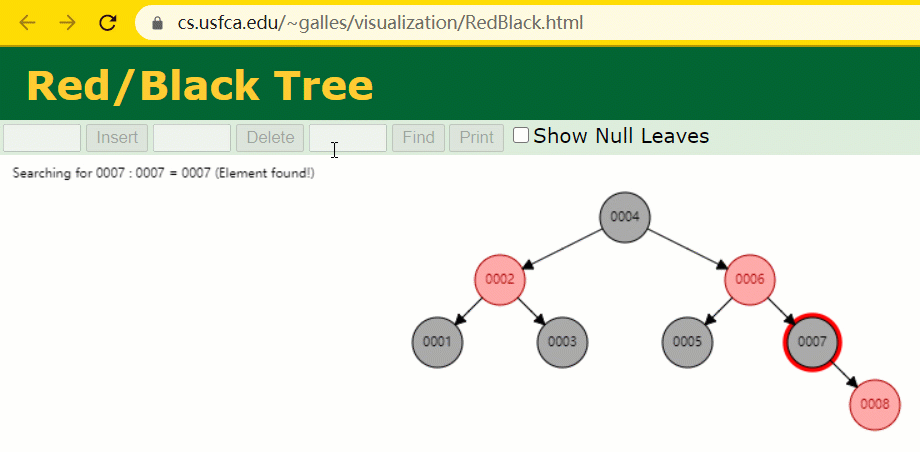
しかし、MySQL のインデックスは、正確な位置決めと範囲クエリに優れた をまだ使用していません red-黒い木###。 MySQL
B ツリー
赤黒ツリーの唯一の欠点は、木の高さが制御できないことです。そのため、
エントリ ポイントはの木の高さは です。 現在、ノードは 1 つの要素を格納するためにのみ割り当てられています。高さを制御したい場合は、より大きなスペースをノードに割り当て、 で複数の要素を水平方向に格納できるようにすることができます
今回は高さが制御可能です。このような変革のプロセスを経て、B-tree になりました。
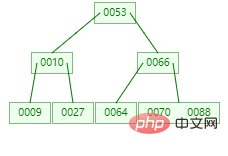 B-tree
B-tree
B-tree の説明に degree
Order: ノードの子ノードの最大数。 (通常は m で表されます)
キーワード: データ インデックス。m 次 B ツリー
は、平衡型 m 方向探索ツリーです。これは空のツリーであるか、次の特性を満たす可能性があります:
ルート ノードとリーフ ノードを除き、他の各ノードには少なくとも ## があります。
#⌈##m
-
⌈
名前の意味 (本題から外れます、リラックスしてください) 以下は Wikipedia からの抜粋です
- ルドルフ バイエル (ルドルフ・バイエルとエド・M・マクレイトは、ボーイング研究所で働いていた1972年に
Bツリー
を発明しましたが、Bが(もしあれば)どのような意味を表しているのかについては説明していませんでした。
B ツリー
の本来の意味を説明していません。バランスが取れていて、幅が広く、茂みのあるものが適していると感じるかもしれません。文字Bはボーイングを表していると主張する人もいた。ただし、彼のスポンサーシップにより、B-tree はバイエル ツリーと考える方が適切であると思われます。
Donald Knuth は、1980 年 5 月に発表された「ディスク ストレージと B ツリーに関する CS144C 教室講義」というタイトルの論文でB ツリー について推測しました。名前の解釈では、B がボーイングまたは B を意味する可能性があることを示唆しています。バイエル社の名前。
B ツリー の検索は、実際には二分木と非常によく似ています。
B-tree 上の各ノードには k 個のキーワードと (k 1) 個の分岐があります。
B-tree
は複数の分岐によって決定する必要があります。B-tree
- 最初にノードを見つけます。
B ツリーは通常ディスクに保存されているため、この手順では ディスク IO 操作が必要です。 - キーを見つけますつまり、ノードが見つかると、ノード がメモリ に読み込まれ、逐次検索または二分探索によってキーワードが検索されます。キーワードが見つからない場合は、サイズを判断して適切なブランチを見つけて検索を続ける必要があります。



B-tree の比較数とディスク IO 数は実際には比較数とそれほど変わらないことがわかりました。バイナリツリー、違いはないようですが、どのようなメリットがあるのでしょうか。
B-tree は、1 つのノードに多数の キーワード (順序によって数が決まります) を格納することができ、同じ数の キーワードを格納できます。 B-tree で生成されるノードはバイナリ ツリーのノードに比べてはるかに少なく、ノード数の差はディスク IO の数に相当します。一定の数値に達すると、パフォーマンスの差が顕著になります。
B-tree がキーワードを挿入したい場合、葉ノードを直接見つけて操作を実行します。
- 挿入する
- keyword に従って、挿入するリーフ ノードを見つけます。 ノードの子ノードの最大数 (順序) は次のとおりです。 m であるため、現在のノード
- 内のキーワード の数が (m - 1) 未満であるかどうかを判断する必要があります。
- はい: 直接挿入
- いいえ:
- ノード分割が発生します。ノードは、ノードの中央のキーワードと中央のキーワードに基づいて左右の部分に分割されますが配置されている場合は、親ノードに移動するだけです。
B ツリー に挿入する必要があります。 3: 72
- 挿入するリーフ ノードを見つけます

- ノード分割: である必要があります。 [70,88] 同じディスク ブロック上ですが、ノードに 3 つのキーワードがある場合、そのノードには 4 つの子ノードがある可能性があり、定義した制限の最大次数 3 を超えるため、この時点で
split## を実行する必要があります。 time #: 真ん中のキーワードを境界としてノードを2つに分割し、新しいノードを生成し、真ん中のキーワードを親ノードまで移動します。


ヒント: 真ん中のキーワードが 2 つある場合、通常は左側のキーワードが使用されます。分割。 削除
削除操作は、検索と挿入よりも面倒です。削除するキーワードがリーフ ノードに存在する場合と存在しない可能性があり、削除によって
B が発生する可能性があるためです。 -tree はバランスが崩れており、ツリー全体のバランスを維持するにはマージや回転などの操作が必要です。 任意のツリー (レベル 5) を例として取り上げます
以上が最後に、MySQL インデックスは B+tree を使用する必要があり、それが非常に高速であることを理解しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1385
52
84
11
28
99
15
1385
52
84
11
28
99

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築には、DBMSの選択が必要です。 DBMSのインストール。データベースの作成。テーブルの作成;データの挿入;データの取得。データの更新。データの削除。ユーザーの管理。データベースのバックアップ。
