

notepad++ 正規表現置換文字列について

次の notepad のチュートリアル コラムでは、メモ帳で文字列を正規表現に置き換える方法を紹介します。

式はクエリ文字列であり、一般文字といくつかの特殊文字が含まれています。特殊文字を使用すると、文字列の検索機能が拡張されます。正規表現は検索の役割で使用されます。文字列の置換も無視できないため、作業効率が大幅に向上します。
EditPlus の検索、置換、ファイル内検索では、次の正規表現がサポートされています:
表达式 说明 /t 制表符. /n 新行. . 匹配任意字符. | 匹配表达式左边和右边的字符. 例如, "ab|bc" 匹配 "ab" 或者 "bc". [] 匹配列表之中的任何单个字符. 例如, "[ab]" 匹配 "a" 或者 "b". "[0-9]" 匹配任意数字. [^] 匹配列表之外的任何单个字符. 例如, "[^ab]" 匹配 "a" 和 "b" 以外的字符. "[^0-9]" 匹配任意非数字字符. * 其左边的字符被匹配任意次(0次,或者多次). 例如 "be*" 匹配 "b", "be" 或者 "bee". + 其左边的字符被匹配至少一次(1次,或者多次). 例如 "be+" 匹配 "be" 或者 "bee" 但是不匹配 "b". ? 其左边的字符被匹配0次或者1次. 例如 "be?" 匹配 "b" 或者 "be" 但是不匹配 "bee". ^ 其右边的表达式被匹配在一行的开始. 例如 "^A" 仅仅匹配以 "A" 开头的行. $ 其左边的表达式被匹配在一行的结尾. 例如 "e$" 仅仅匹配以 "e" 结尾的行. () 影响表达式匹配的顺序,并且用作表达式的分组标记. / 转义字符. 如果你要使用 "/" 本身, 则应该使用 "//".
例:
原始串 str[1]abc[991]; str[2]abc[992]; str[11]abc[993]; str[22]abc[994]; str[111]abc[995]; str[222]abc[996]; str[1111]abc[997]; str[2222]abc[999];
目标串: abc[1]; abc[2]; abc[11]; abc[22]; abc[111]; abc[222]; abc[1111]; abc[2222];
処理:
検索文字列: str / [([0-9] )/]abc/[[0-9] /]
置換文字列: abc[/1] 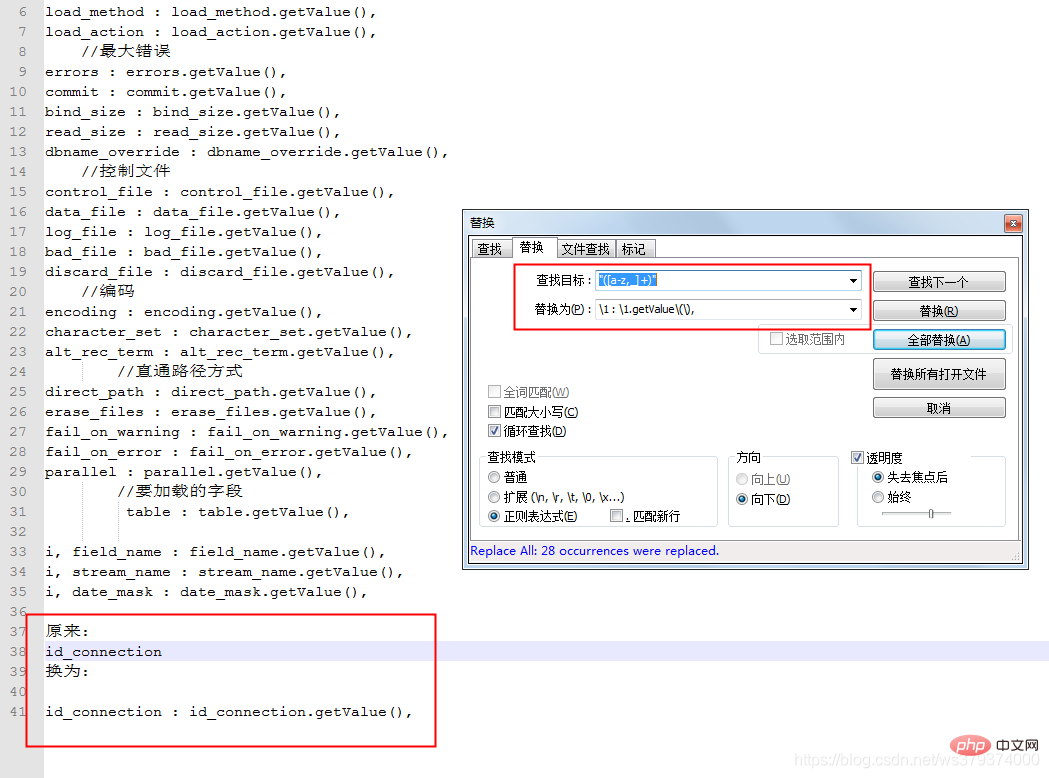
1. が含まれます。 「hello word」
#^.*hello word.*$2 の行「hello word」^hello word.*$## で始まる行#3.「hello word」で終わる行
.*hello word$
## は次のように置き換えられます: 
ターゲットを検索\n([a-zA-Z0-9])
【1】正規表現の応用 - 指定内容を行末まで置き換える
原文は以下の2行です
abc aaaaa
123 abc 444
毎回そうなるといいですね「abc」に遭遇しました。次に、「abc」とそれに続く行末までの内容を「abc efg」として置き換えます。
つまり、上記のテキストは最終的に次のように置き換えられます。
abc efg
123 abc efg
解決策:
①「置換」ダイアログボックスで、検索内容に「abc.*」と入力します。
②「正規表現」にもチェックを入れ、「すべて置換」ボタンをクリックします。
このうち、記号の意味は次のとおりです。
" ." = 任意の文字に一致
"*" = 0 回以上一致
注: 実際には正規表現の置換です。ここでは、純粋に正規表現自体の観点から、提起されたいくつかの問題をまとめています。何千もの特殊なケースが派生する可能性があります。
[2] 正規表現アプリケーション - 数値の置換
asdadas123asdasdas456asdasdasd789asdasd
を次のように置き換えたいと考えています:
asdadas[123]asdasdas[456]asdasdasd[789]asdasd
を置き換えますダイアログ ボックスで、[正規表現] チェックボックスをオンにします。
検索内容に引用符なしで「[0-9][0-9][0-9]」と入力します。
「: に置き換えます」を入力します。 [/0/1/2]" (引用符なし)
範囲は操作対象の範囲であり、[置換] を選択します。
実際、これは正規表現の特殊なケースでもあります。「[0-9]」は 0 から 9 までの特殊なケースに一致することを意味し、「[a-z]」は a から z までの特殊なケースに一致することを意味します。 .
「[0-9]」は 3 つの連続する数字を表すために上で繰り返し使用されています
「/0」は最初の「[0-9]」に対応するプロトタイプを表し、「/1」は 2 番目の数字を表します「[0-9]」に対応するプロトタイプなど
「[」、「]」は単純な文字で、「other/0/1/2 Other」と入力した場合に「[」または「]」を追加することを示します。 " の場合、置換結果は次のようになります。
asdadas other 123 other asdasdas other 456 other asdasdasd other 789 other asdasd
機能拡張 (jiuk2k による):
検索内容が "[0-9][0- 9] の場合][0-9]" は、1 または 123 または 12345 または... に対応する "[0-9]*[0-9]" に変更されます。
ニーズに応じてカスタマイズできます
関連する内容が多いので、自分でカスタマイズすることも可能です 正規表現の構文を参照してよく勉強してください
[3] 正規表現の応用 - 各行末の指定文字を削除します
これらの文字は、
例:
12345 1265345
2345
各行の末尾の「345」を削除する必要があります
これは、次のような使用法ともみなされます。正規表現. 実際、正規表現を注意深く見れば比較的単純なはずですが、この質問が提起されたということは、正規表現を理解するプロセスがあることを意味します。解決策は次のとおりです。
解決策:
置換ダイアログボックスで、「正規表現」チェックボックスをオンにします。
検索内容に「345$」と入力します。
ここで、「$」は行末から一致することを意味します。
から一致する場合行頭の場合は「^」を使用することもできますが、EditPlus には行頭の文字を簡単に削除できる別の機能があります。 文字列
a. 操作対象の行を選択します
b . 編集-フォーマット-行コメントの削除
c. ポップアップダイアログボックスにクリアする行の最初の文字を入力し、確定します
[4] 正規表現 数式の応用 - 複数行を半角に置換括弧
何百もの Web ページに次のコードが含まれています:
/n
置換ダイアログ ボックスで [正規表現] オプションを有効にすると、置換が完了しました
[5] 正規表現のアプリケーション- 空白行の削除
EditPlusを起動し、処理対象のテキスト型ファイルを開きます。
① 「検索」メニューの「置換」コマンドを選択すると、テキスト置換ダイアログボックスが表示されます。 「正規表現」チェックボックスを選択して、検索と置換に正規表現を使用することを示します。次に、「置換範囲」で「現在のファイル」を選択し、現在のファイルに対する操作を指示します。
②. 「コンテンツの検索」コンボボックスの右側にあるボタンをクリックすると、ドロップダウンメニューが表示されます。
③. 次の操作では、検索する空行を表す正規表現を追加します。 (ヒント: 空白行にはスペース文字、タブ文字、および復帰文字のみが含まれ、これら 3 つの記号のいずれかで行が始まり、復帰文字で終わる必要があります。空白行を見つける鍵は、次の表現を構築することです。空白行、正規表現)。
「検索」に正規表現「^[ /t]*/n」を直接入力します。/t の前には空白文字が必要です。
(1) 「行頭から一致」を選択すると、「内容の検索」コンボボックスに文字「^」が表示され、検索する文字列が行頭で出現する必要があることを示します。文章。
(2) 「範囲内の文字」を選択すると、「^」の後に括弧「[]」が追加され、現在の挿入ポイントは括弧内になります。括弧は正規表現で表現されており、本文中の文字が括弧内の文字と一致すれば検索条件を満たします。
(3) スペースバーを押してスペース文字を追加します。空白文字は空行の構成要素です。
(4)選擇“製表符”,並新增代表製表符的“/t”。
(5)移動遊標,將目前插入點移到“]”之後,然後選擇“匹配 0 次或更多”,該操作會添加星號字元“*”。星號表示,其前面的括號「[]」內的空格符或製表符,在一行中出現0個或多個。
(6)選擇“換行符號”,插入“/n”,表示回車符。
④、「替換為」組合方塊保持空,表示刪除查找到的內容。按一下「取代」按鈕逐一刪除空白行,或按一下「全部取代」按鈕刪除全部空白(注意:EditPlus有時存在「全部替換」不能一次完全刪除空白行的問題,可能是程式BUG,需要多按幾次按鈕)。
1.在漢化的時候,是否常常碰到這樣的語句需要翻譯:
Code:
“Error adding the post!”;
“Error adding the comment!”;
# “Error adding the user!”;
如果有很多類似的檔案一個一個翻譯顯然很累而且感覺很無聊。
其實可以這樣處理,在Editplus裡面用取代功能,在取代對話方塊選取「正規表示式」核取方塊:
尋找原始檔案:
Code:
「Error adding ([^ !|"|;]*)
替換成:
Code:
「在增加/1時發生錯誤
這樣替換之後發生了什麼?結果是:
# Code:
“在增加the post時發生錯誤!”;
“在增加the comment時發生錯誤!”;
“在增加the user時發生錯誤!”;
ok,接下來你會怎麼做?當然再替換一次把the post、the comment、the user替換成你要翻譯的詞。得到最後的結果:
Code:
“在增加帖子時發生錯誤!”;
“在增加註解時發生錯誤!”;
“在增加使用者時發生錯誤!”;
2.要提取的單字在中間,例如:
Code: can not be deleted because can not be added because can not be updating because
可以用这种方式:
在Editplus里面用 替换 功能,在替换对话框选中“正则表达式”复选框:
查找原文件:
Code:
can not be ([^ ]*) because
替换成:
Code:
无法被/1因为
这样替换之后发生了什么?结果是:
Code:
无法被deleted因为
无法被added因为
无法被updating因为
其余步骤如上。
在汉化量很大而且句式比较单调的情况下对效率的提高很明显!
解释一下:([^!|"|;]*) 的意思是 不等于 ! 和 ” 和 ; 中的任何一个,意思就是这3个字符之外的所有字符将被选中(替换区域);
/1 即被选中的替换区域所在的新位置(复制到这个新位置)。
3.经常手工清理一行一行地删除文本文件里面的空白行,其实可以交给Editplus更好的完成,在Editplus里面用替换功能,在替换对话框选中 “正则表达式”复选框:
查找原文件:
Code:
^[ /t]*/n
替换部分为空就可以删除空白行了,执行一下看看:)
abandon[2''b9nd2n]v.抛弃,放弃
abandonment[2''b9nd2nm2nt]n.放弃
abbreviation[2bri:vi''ei62n]n.缩写
abeyance[2''bei2ns]n.缓办,中止
abide[2''baid]v.遵守
ability[2''biliti]n.能力
able[''eibl]adj.有能力的,能干的
abnormal[9b''n0:m2l]adj.反常的,变态的
aboard[2''b0:d]adv.船(车)上
1.
查找: (^[a-zA-Z0-0/-]+)(/[*.*/]+)(.*)
替换: @@@@@”/1″,”/2″,”/3″,
效果:
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
@@@@@”abide”,”[2''baid]“,”v.遵守”,
@@@@@”ability”,”[2''biliti]“,”n.能力”,
@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,
@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,
2.
查找: /n
替换:
注: 要次替换内容为空
效果:
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃 ”,@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃 ”,@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写 ”,@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,@@@@@”abide”,”[2''baid]“,”v.遵守 ”,@@@@@”ability”,”[2''biliti]“,”n.能力”,@@@@@”able”,”[''eibl]“,”adj.有能力的,能 干的 ”,@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的 ”,@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,@@@@@”abolish”,”[2''b0li6]“,”v.废 除,取消”,@@@@@”abolition”,”[9b2''li62n]“,”n.废除,取消”
3.
查找: @@@@@
替换: /n
效果:
“abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
“abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
“abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
“abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
“abide”,”[2''baid]“,”v.遵守”,
“ability”,”[2''biliti]“,”n.能力”,
“able”,”[''eibl]“,”adj.有能力的,能干的”,
“abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
“aboard”,”[2''b0:d]“,”adv.船(车)上”,
“abolish”,”[2''b0li6]“,”v.废除,取消”,
4. 任务完成
一、删除空行(不包括有空格类符号的空行)
1、\r\n转义符替换
按ctrl+h,跳出搜索替换框,把查找模式定义为扩展(\n,\r...)
查找目标:\r\n\r\n
替换为:\r\n
有编程基础的读者应该知道是什么意思了。
2、Textfx插件
先选中要删部分文本内容,如果是整个文件那就全选Ctrl+A,然后使用Notepad++自带的Textfx插件,在长长的列表中找到Delete Blank Lines,点击即可。
注意Notepad 的正規表示式與轉義符等之間不相容,所以限制較大,不可以直接用正規表示式取代。
二、刪除有空格的空白行
1、先刪除空格,後刪除空白行
如何刪除只有空格行的空格?
在選單編輯中找到Blank Operations(行編輯),點選移除行尾空白,再用上面的方法刪除空白行。
2、使用正規表示式刪除空格行空格
取代中查找模式選擇正規表示式^ $,替換為空(就是什麼都不填),再用上面的方法刪除空白行。
以上がnotepad++ 正規表現置換文字列についての詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1655
1655
 14
1414
52
1307
25
1253
29
1227
24
14
1414
52
1307
25
1253
29
1227
24

 notepad++で大きなファイルを開く方法
Apr 08, 2024 am 09:45 AM
notepad++で大きなファイルを開く方法
Apr 08, 2024 am 09:45 AM
Notepad++ を使用して大きなファイルを開くにはどうすればよいですか? Notepad++ を起動し、[ファイル] > [開く] をクリックし、ファイル ブラウザで大きなファイルを選択します。発生する可能性のある一般的な問題: ファイルの読み込みの遅さ、「ファイルが大きすぎます」エラー、メモリ不足、ファイルの破損。パフォーマンスを最適化する方法: プラグインを無効にする、設定を調整する、マルチスレッドを使用する。
 notepad++ のインストールにはどのコンポーネントを選択する必要がありますか?
Apr 08, 2024 am 10:48 AM
notepad++ のインストールにはどのコンポーネントを選択する必要がありますか?
Apr 08, 2024 am 10:48 AM
Notepad++ コンポーネントをインストールするときは、次の必須コンポーネントを選択することをお勧めします: NppExec、Compare、Multi-Edit、Spell Checker、XML Tools。オートコンプリート、列エディター、DSpellCheck、Hex エディター、プラグイン マネージャーなど、特定の機能を強化するためにオプションのコンポーネントを使用できます。コンポーネントをインストールする前に、頻繁に使用される機能を特定し、互換性と安定性を考慮してください。不要な混乱を避けるために、必要なコンポーネントのみをインストールしてください。
 notepad++の用途は何ですか?
Apr 08, 2024 am 11:03 AM
notepad++の用途は何ですか?
Apr 08, 2024 am 11:03 AM
Notepad++ は、プログラミング、Web 開発、テキスト操作に広く使用されている無料のオープン ソース テキスト エディタです。その主な用途は次のとおりです: テキストの編集と表示: プレーン テキスト ファイルの作成、編集、表示、タブと構文の強調表示のサポート。プログラミング: 複数のプログラミング言語の構文の強調表示、コードの折りたたみ、オートコンプリートをサポートし、デバッガーとバージョン管理プラグインを統合します。 Web 開発: Web ページの作成と編集を容易にするために、HTML、CSS、および JavaScript の構文ハイライト、コード検証、オートコンプリートを提供します。その他の用途: テキスト処理、スクリプト作成、ドキュメント編集用。
 メモ帳のフォントサイズを調整する方法
Apr 08, 2024 am 10:21 AM
メモ帳のフォントサイズを調整する方法
Apr 08, 2024 am 10:21 AM
次の手順に従って、メモ帳でフォント サイズを調整できます: 1. メモ帳を開きます; 2. [書式] メニューに移動します; 3. [フォント] オプションを選択します; 4. [フォント] ウィンドウで、[サイズ] を使用します。フィールドでフォント サイズを調整します; 5. [OK] ボタンをクリックして変更を適用します。
 メモ帳のテキストエディタでデータを条件でフィルタリングする方法
Apr 08, 2024 am 10:33 AM
メモ帳のテキストエディタでデータを条件でフィルタリングする方法
Apr 08, 2024 am 10:33 AM
正規表現を使用して、Notepad++ は条件によってデータをフィルタリングできます: 1. ファイルを開いて「検索」ウィンドウを使用します; 2. 「正規表現」モードを選択します; 3. 正規表現を入力して条件を定義します (「foo」を含む行の検索など) ":ふー。
 notepad++ は Perl コードをどのように実行しますか
Apr 08, 2024 am 10:18 AM
notepad++ は Perl コードをどのように実行しますか
Apr 08, 2024 am 10:18 AM
Notepad++ で Perl コードを実行するには、次の手順に従います。 Perl インタープリタをインストールします。 Notepad++ を設定し、言語設定で Perl を選択し、Perl 実行可能ファイルへのパスを入力します。 Perlコードを書きます。 NppExec プラグインで Perl インタープリターを選択し、コードを実行します。 「コンソール」メニューバーで出力を確認します。
 notepad++でC言語を実行する方法
Apr 08, 2024 am 10:06 AM
notepad++でC言語を実行する方法
Apr 08, 2024 am 10:06 AM
Notepad++ 自体は C 言語プログラムを実行できず、コードをコンパイルして実行するには外部コンパイラが必要です。外部コンパイラを使用するには、次の手順に従ってセットアップします: 1. C 言語コンパイラをダウンロードしてインストールします; 2. Notepad++ でカスタム ツールを作成し、コンパイラの実行可能ファイルのパスとパラメータを構成します; 3. C 言語プログラムを選択し、.c ファイル拡張子を付けて保存します。 4. C 言語プログラム ファイルを選択し、[実行] メニューからコンパイルするカスタム ツールを選択します。 5. コンパイル結果を表示し、コンパイル エラーまたは成功メッセージを出力します。 。コンパイルが成功すると、実行可能ファイルが生成されます。
 notepad++を中国語に変更する方法
Apr 08, 2024 am 10:42 AM
notepad++を中国語に変更する方法
Apr 08, 2024 am 10:42 AM
Notepad++ はデフォルトでは中国語インターフェイスを提供しません。切り替え手順は次のとおりです: 中国語言語パックをダウンロードし、プロンプトが表示されたらインストールを完了します。Notepad++ を再起動して「環境設定」ウィンドウに入り、「言語」タブで「簡体字中国語」を選択します。 「OK」をクリックします。
