

swoole コルーチンに 3 回尋ねられたとき、私は泣きそうになりました。

#swoole チュートリアルコルーチンに関連する面接の質問の紹介
推奨 (無料): 
swoole チュートリアル
#プロセスとは何ですか? プロセスはアプリケーションの起動インスタンスです。独立したファイル リソース、データ リソース、およびメモリ空間。 スレッドとは何ですか? スレッドはプロセスに属し、プログラムの実行者です。プロセスには少なくとも 1 つのメイン スレッドが含まれており、さらに多くの子スレッドを持つこともできます。スレッドには 2 つのスケジューリング戦略があり、1 つはタイムシェアリング スケジューリング、もう 1 つはプリエンプティブ スケジューリングです。 私の公式ペンギン グループコルーチンとは何ですか? コルーチンは軽量のスレッドであり、コルーチンもスレッドに属し、コルーチンはスレッド内で実行されます。コルーチンのスケジューリングはユーザーが手動で切り替えるため、ユーザースペーススレッドとも呼ばれます。コルーチンの作成、切り替え、一時停止、破棄はすべてメモリ操作であり、消費量は非常に少なくなります。コルーチンのスケジューリング戦略は、協調スケジューリングです。 Swoole コルーチンの原理- Swoole4 シングルスレッドでマルチプロセスであるため、同じプロセスで同時に実行されるコルーチンは 1 つだけです。 。
- Swoole サーバーはデータを受信し、ワーカー プロセスで onReceive コールバックをトリガーして Ctrip を生成します。 Swoole はリクエストごとに対応する Ctrip を作成します。コルーチン内にサブコルーチンを作成することもできます。
- コルーチンの基礎となる実装はシングルスレッドであるため、同時に動作するコルーチンは 1 つだけであり、コルーチンの実行はシリアルです。
- そのため、マルチタスクとマルチコルーチンを実行すると、1 つのコルーチンが実行されていると、他のコルーチンは動作を停止します。現在のコルーチンは、ブロッキング IO 操作を実行するとハングし、基礎となるスケジューラーがイベント ループに入ります。 IO 完了イベントが発生すると、基礎となるスケジューラーはイベントに対応するコルーチンの実行を再開します。 。したがって、コルーチンには IO 時間が消費されず、同時実行性の高い IO シナリオに非常に適しています。 (以下に示すように)
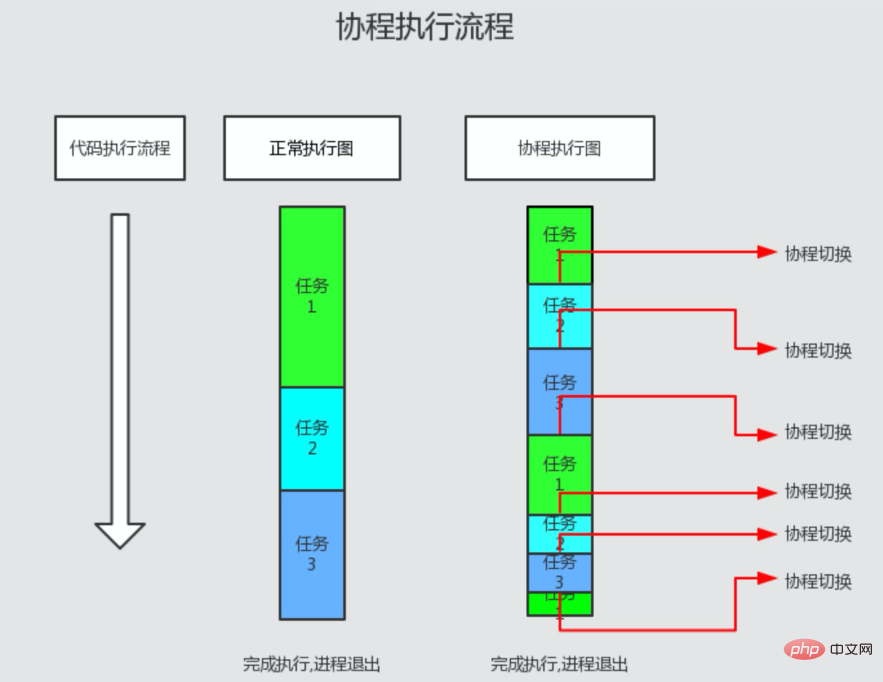
- コルーチンには IO がなく、待機中です。通常の実行の場合、PHP コードは実行フローの切り替えを引き起こしません
- コルーチンが IO に遭遇すると、待機し、すぐに制御を切り替えます。IO が完了すると、実行フローは切り替えられます。
- コルーチンと並列コルーチンは、前のコルーチンと同じロジックで順番に実行されます
- コルーチンのネストされた実行プロセスIO が発生するまで外側から内側へ層ごとに入力され、外側のコルーチンに切り替わります。親コルーチンは子コルーチンの終了を待ちません
go(function () {
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});go() は \Co::create()## の略称です。 #、コルーチンの作成に使用され、コールバック内でコールバックをパラメーターとして受け入れます コードは、この新しく作成されたコルーチンで実行されます。 備考:
は # に省略できます。 ##\Co上記コード 実行結果:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello go1 hello main hello go2
- は go()
- に遭遇し、現在のプロセスにコルーチンが生成されます。プロセス、
heelo go1
プロセスはコードの実行を継続し、がコルーチンに出力され、コルーチンが終了しますhello main - を出力します。
コルーチンを生成し、コルーチン内で # を出力します。 ##heelo go2 、コルーチンが終了します -
このコードを実行すると、システムが新しいプロセスを開始します。この文が理解できない場合は、次のコードを使用できます:// co.php<?phpsleep (100);
ログイン後にコピー実行し、
を使用してシステム内のプロセスを表示します:
root@b98940b00a9b /v/w/c/p/swoole# php co.php &⏎ root@b98940b00a9b /v/w/c/p/swoole# ps auxPID USER TIME COMMAND 1 root 0:00 php -a 10 root 0:00 sh 19 root 0:01 fish 749 root 0:00 php co.php 760 root 0:00 ps aux ⏎
少し変更を加えてコルーチンのスケジューリングを体験してみましょう: <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">use Co;go(function () {
Co::sleep(1); // 只新增了一行代码
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});</pre><div class="contentsignin">ログイン後にコピー</div></div>
関数 function は
sleep()## に似ています。 # ですが、IO 待ちをシミュレートしています (IO については後で詳しく説明します)。実行結果は次のとおりです:root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go2 hello go1
なぜ順次実行されないのですか? 実際の実行プロセス: #このコードを実行すると、システムは新しいプロセスを開始しますencountersgo()
、現在のプロセスでコルーチンが生成されます- コルーチンは IO ブロックに遭遇します (ここにあります) Co::sleep()
- シミュレートされた IO 待機)、コルーチンは制御を放棄し、コルーチンに入ります。プロセス スケジューリング キュー
プロセスは下向きに実行を続け、hello main## を出力します。 -
# 次のコルーチンを実行し、出力hello go2 -
前のコルーチンの準備が完了し、実行を続行し、出力hello go1 -
この時点で、コルーチンと swoole のプロセスの関係、およびコルーチンのスケジュール設定がすでに確認できています。今すぐプログラムを変更しましょう:
go(function () {
Co::sleep(1);
echo "hello go1 \n";});echo "hello main \n";go(function () {
Co::sleep(1);
echo "hello go2 \n";});<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main
hello go1
hello go2
⏎</pre><div class="contentsignin">ログイン後にコピー</div></div>
<h2 id="协程快在哪-减少IO阻塞导致的性能损失">协程快在哪? 减少IO阻塞导致的性能损失</h2>
<p>大家可能听到使用协程的最多的理由, 可能就是 协程快. 那看起来和平时写得差不多的代码, 为什么就要快一些呢? 一个常见的理由是, 可以创建很多个协程来执行任务, 所以快. 这种说法是对的, 不过还停留在表面.</p>
<p>首先, 一般的计算机任务分为 2 种:</p>
<ul>
<li>CPU密集型, 比如加减乘除等科学计算</li>
<li>
<li>IO 密集型, 比如网络请求, 文件读写等</li>
</ul>
<p>其次, 高性能相关的 2 个概念:</p>
<ul>
<li>并行: 同一个时刻, 同一个 CPU 只能执行同一个任务, 要同时执行多个任务, 就需要有多个 CPU 才行</li>
<li>
<li>并发: 由于 CPU 切换任务非常快, 快到人类可以感知的极限, 就会有很多任务 同时执行 的错觉</li>
</ul>
<p>了解了这些, 我们再来看协程, 协程适合的是 IO 密集型 应用, 因为协程在 IO阻塞 时会自动调度, 减少IO阻塞导致的时间损失.</p>
<p>我们可以对比下面三段代码:</p>
<ul><li>普通版: 执行 4 个任务</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main
real 0m 4.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><div class="contentsignin">ログイン後にコピー</div></div></pre>
<ul><li>单个协程版:</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;go(function () use ($n) {
for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s
user 0m 0.00s
sys 0m 0.02s
⏎</pre><div class="contentsignin">ログイン後にコピー</div></div></pre>
<ul><li>多协程版: 见证奇迹的时刻</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965245.5491: hello 01528965245.5498: hello 31528965245.5502: hello 21528965245.5506: hello 1real 0m 1.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><div class="contentsignin">ログイン後にコピー</div></div><p>为什么时间有这么大的差异呢:</p></pre>
<ul>
<li><p>普通写法, 会遇到 IO阻塞 导致的性能损失</p></li>
<li><p>单协程: 尽管 IO阻塞 引发了协程调度, 但当前只有一个协程, 调度之后还是执行当前协程</p></li>
<li><p>多协程: 真正发挥出了协程的优势, 遇到 IO阻塞 时发生调度, IO就绪时恢复运行</p></li>
</ul>
<p>我们将多协程版稍微修改一下:</p>
<ul><li>多协程版2: CPU密集型</li></ul>
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965743.4327: hello 01528965744.4331: hello 11528965745.4337: hello 21528965746.4342: hello 3hello main
real 0m 4.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><div class="contentsignin">ログイン後にコピー</div></div><p>只是将 <code>Co::sleep() 改成了 sleep(), 时间又和普通版差不多了. 因为:
sleep()可以看做是 CPU密集型任务, 不会引起协程的调度Co::sleep()模拟的是 IO密集型任务, 会引发协程的调度
这也是为什么, 协程适合 IO密集型 的应用.
再来一组对比的例子: 使用 redis
// 同步版, redis使用时会有 IO 阻塞$cnt = 2000;for ($i = 0; $i connect('redis');
$redis->auth('123');
$key = $redis->get('key');}// 单协程版: 只有一个协程, 并没有使用到协程调度减少 IO 阻塞go(function () use ($cnt) {
for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
}});// 多协程版, 真正使用到协程调度带来的 IO 阻塞时的调度for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
});}性能对比:
# 多协程版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 0.54s user 0m 0.04s sys 0m 0.23s ⏎# 同步版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 1.48s user 0m 0.17s sys 0m 0.57s ⏎
swoole 协程和 go 协程对比: 单进程 vs 多线程
接触过 go 协程的 coder, 初始接触 swoole 的协程会有点 懵, 比如对比下面的代码:
package main
import (
"fmt"
"time")func main() {
go func() {
fmt.Println("hello go")
}()
fmt.Println("hello main")
time.Sleep(time.Second)}> 14:11 src $ go run test.go hello main hello go
刚写 go 协程的 coder, 在写这个代码的时候会被告知不要忘了 time.Sleep(time.Second), 否则看不到输出 hello go, 其次, hello go与 hello main 的顺序也和 swoole 中的协程不一样.
原因就在于 swoole 和 go 中, 实现协程调度的模型不同.
上面 go 代码的执行过程:
- 运行 go 代码, 系统启动一个新进程
- 查找
package main, 然后执行其中的func mian() - 遇到协程, 交给协程调度器执行
- 继续向下执行, 输出
hello main - 如果不添加
time.Sleep(time.Second), main 函数执行完, 程序结束, 进程退出, 导致调度中的协程也终止
go 中的协程, 使用的 MPG 模型:
- M 指的是 Machine, 一个M直接关联了一个内核线程
- P 指的是 processor, 代表了M所需的上下文环境, 也是处理用户级代码逻辑的处理器
- G 指的是 Goroutine, 其实本质上也是一种轻量级的线程
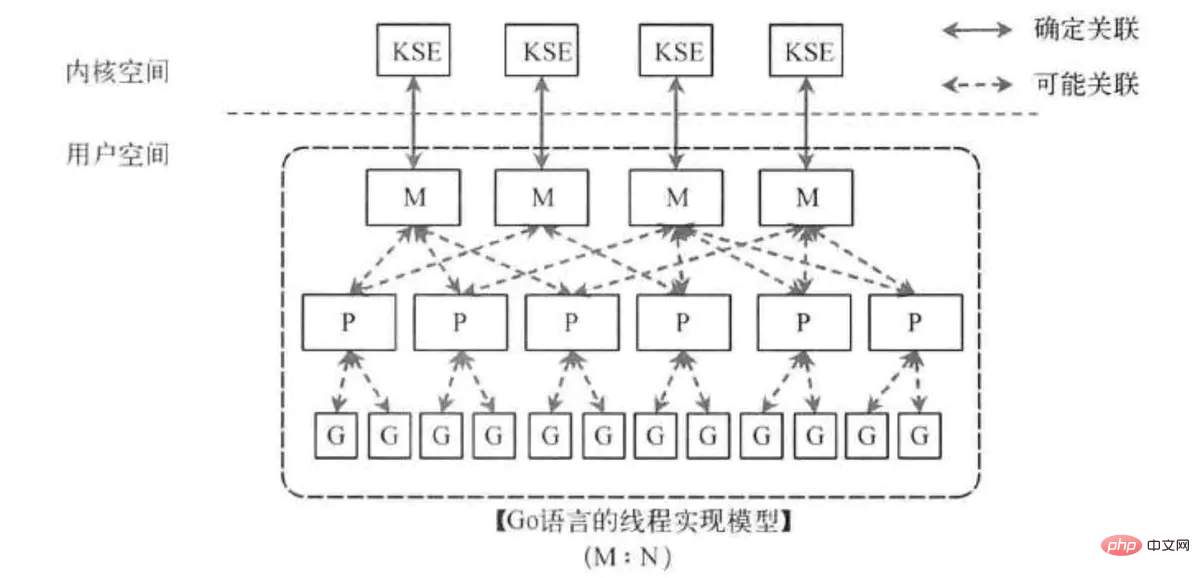
而 swoole 中的协程调度使用 单进程模型, 所有协程都是在当前进程中进行调度, 单进程的好处也很明显 – 简单 / 不用加锁 / 性能也高.
无论是 go 的 MPG模型, 还是 swoole 的 单进程模型, 都是对 CSP理论 的实现.
以上がswoole コルーチンに 3 回尋ねられたとき、私は泣きそうになりました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7503
7503
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Swooleのメモリプールを使用してメモリの断片化を減らすにはどうすればよいですか?
Mar 17, 2025 pm 01:23 PM
Swooleのメモリプールを使用してメモリの断片化を減らすにはどうすればよいですか?
Mar 17, 2025 pm 01:23 PM
この記事では、Swooleのメモリプールを使用して、効率的なメモリ管理と構成によりメモリの断片化を減らすことについて説明します。主な焦点は、プール内のメモリの有効化、サイジング、再利用です。
 カスタムモジュールでSwooleを拡張するにはどうすればよいですか?
Mar 18, 2025 pm 03:57 PM
カスタムモジュールでSwooleを拡張するにはどうすればよいですか?
Mar 18, 2025 pm 03:57 PM
記事では、スウールをカスタムモジュールで拡張し、手順を詳細に、ベストプラクティスを詳細にし、トラブルシューティングで説明します。主な焦点は、機能と統合を強化することです。
 Swooleのプロセス分離を構成するにはどうすればよいですか?
Mar 18, 2025 pm 03:55 PM
Swooleのプロセス分離を構成するにはどうすればよいですか?
Mar 18, 2025 pm 03:55 PM
記事では、Swooleのプロセス分離の構成、安定性とセキュリティの改善などの利点、トラブルシューティング方法について説明します。
 Swooleの非同期I/O機能を使用するにはどうすればよいですか?
Mar 18, 2025 pm 03:56 PM
Swooleの非同期I/O機能を使用するにはどうすればよいですか?
Mar 18, 2025 pm 03:56 PM
この記事では、高性能アプリケーション用のPHPでSwooleの非同期I/O機能を使用することについて説明します。インストール、サーバーのセットアップ、および最適化戦略をカバーします。ワードカウント:159
 Swoole Open-Sourceプロジェクトに貢献するにはどうすればよいですか?
Mar 18, 2025 pm 03:58 PM
Swoole Open-Sourceプロジェクトに貢献するにはどうすればよいですか?
Mar 18, 2025 pm 03:58 PM
この記事では、バグの報告、機能の送信、コーディング、ドキュメントの改善など、スウールプロジェクトに貢献する方法の概要を説明しています。それは、初心者が貢献を開始するために必要なスキルとステップについて議論し、プレスを見つける方法は
 Swooleの反応器モデルはフードの下でどのように機能しますか?
Mar 18, 2025 pm 03:54 PM
Swooleの反応器モデルはフードの下でどのように機能しますか?
Mar 18, 2025 pm 03:54 PM
Swooleの原子炉モデルは、イベント駆動型の非ブロッキングI/Oアーキテクチャを使用して、高電流シナリオを効率的に管理し、さまざまなテクニックを通じてパフォーマンスを最適化します。(159文字)
 Swooleの組み込みWebsocketクライアントの主な機能は何ですか?
Mar 14, 2025 pm 12:25 PM
Swooleの組み込みWebsocketクライアントの主な機能は何ですか?
Mar 14, 2025 pm 12:25 PM
SwooleのWebSocketクライアントは、高性能、ASYNC I/O、およびSSL/TLSなどのセキュリティ機能とのリアルタイム通信を強化します。スケーラビリティと効率的なデータストリーミングをサポートします。
 Swooleを使用してマイクロサービスアーキテクチャを構築するにはどうすればよいですか?
Mar 17, 2025 pm 01:18 PM
Swooleを使用してマイクロサービスアーキテクチャを構築するにはどうすればよいですか?
Mar 17, 2025 pm 01:18 PM
記事では、マイクロサービスにSwooleを使用し、非同期I/OおよびCoroutinesを介した設計、実装、パフォーマンスの向上に焦点を当てています。ワードカウント:159
