

Java ログ レベル、重複記録、ログ損失の問題を理解する

java 基本チュートリアルこのコラムでは、Java ログ レベルなどの問題の解決方法を紹介します

#関連する無料学習の推奨事項:1 ログ エラーの一般的な原因1.1 多くのログ フレームワークがある異なるクラス ライブラリは異なるログ フレームワークを使用する場合があり、互換性は異なります。問題1.2 構成が複雑でエラーが発生しやすい
##ログ構成ファイルは通常、非常に複雑です。多くの学生は、構成ファイルを他のプロジェクトやオンライン ブログから直接コピーすることに慣れていますが、そうではありません。それらを変更する方法を注意深く検討してください。一般的なエラーは、ログの重複、同期ログのパフォーマンス、非同期ログの構成ミスで発生します。
1.3 ログ自体にいくつかの誤解があります
たとえば、ログの内容を取得するコストが考慮されていない、ログ レベルが無差別に使用されているなどです。
2 SLF4J
Logback、Log4j、Log4j2、commons-logging、JDK 独自の java.util.logging などはすべて Java システムのログ フレームワークであり、実際にはたくさんあります。異なるクラス ライブラリでは、異なるロギング フレームワークの使用を選択することもできます。その結果、ログの一元管理が非常に困難になります。
SLF4J (Simple Logging Facade For Java) は、この問題を解決するための統合ログ ファサード API を提供します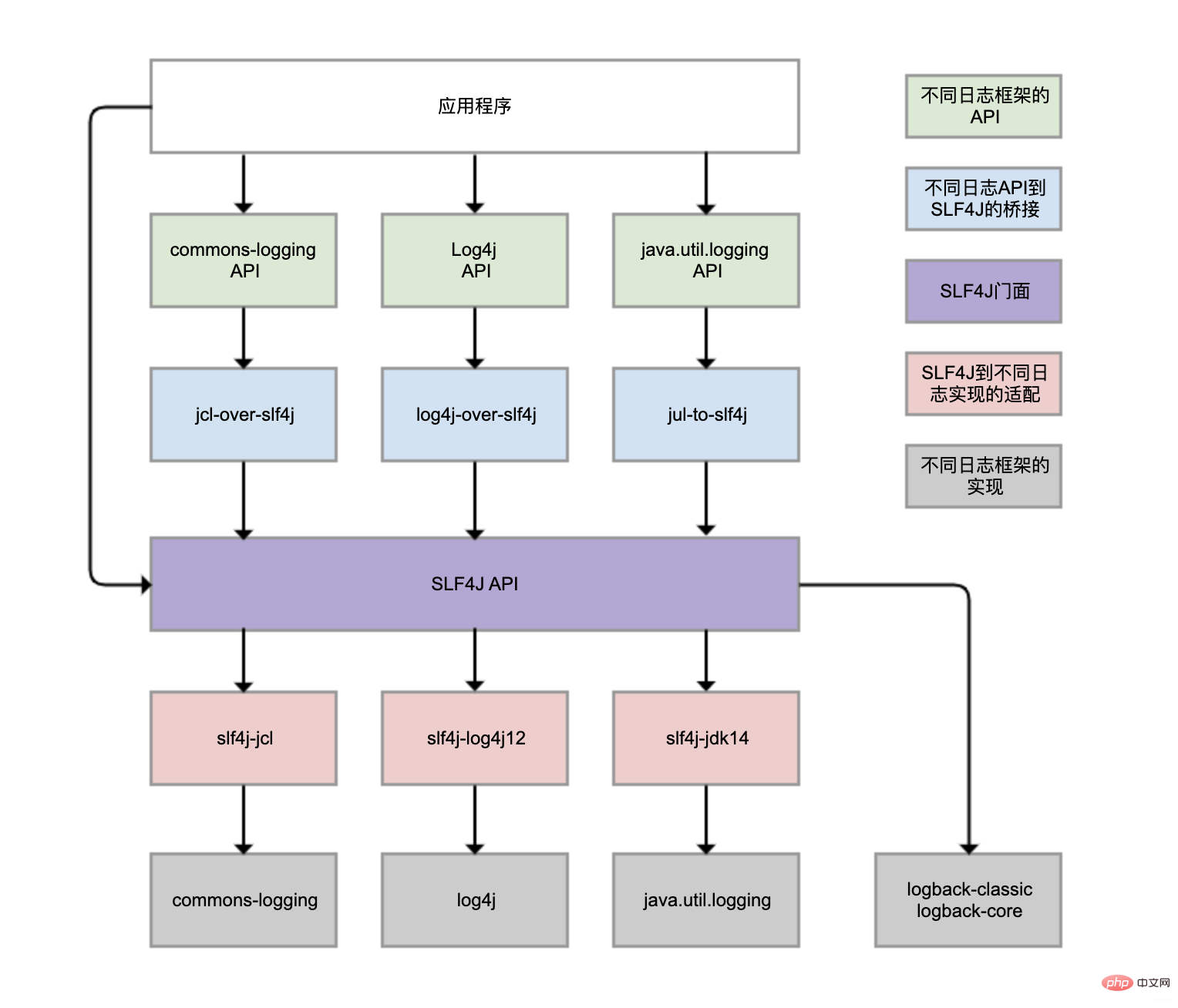
- ブリッジ機能を実装し、青色の部分はさまざまなロギング フレームワーク API (緑色の部分) を SLF4J API にブリッジします。このようにして、さまざまなログ API を使用してプログラムでログを記録する場合でも、最終的には SLF4J ファサード API にブリッジできます。
- Adaptation 関数 (赤色の部分) は、SLF4J API と実際のログ フレームワーク (灰色の部分) のバインディングを実現できます。 SLF4J は単なるロギング標準ですが、実際のロギング フレームワークが必要です。ロギング フレームワーク自体は SLF4J API を実装していないため、事前変換が必要です。 Logback は SLF4J API 標準に従って実装されているため、変換のためにモジュールをバインドする必要はありません。
を使用して SLF4J への Log4j ブリッジングを実装できますが、slf4j-log4j12 を使用して Log4j への SLF4J 適応を実装することもできます。列は描画されますが、それらを同時に使用することはできません。そうしないと、無限ループが発生します。 jclやjulも同様です。 図には 4 つの灰色のログ実装フレームワークがありますが、日常業務で最も一般的に使用されているのは Logback と Log4j であり、両方とも同じ人物によって開発されました。 Logback は Log4j の改良版と考えることができ、より推奨されており、基本的には主流です。
Spring Boot のロギング フレームワークも Logback です。では、なぜ Logback パッケージを手動で導入せずに Logback を直接使用できるのでしょうか?
spring-boot-starter モジュールの依存関係
spring-boot-starter-loggingモジュールspring-boot-starter-logging
自動的に導入されるモジュールlogback -classic (SLF4J および Logback ロギング フレームワークを含む) および SLF4J 用のいくつかのアダプター。このうち、log4j-to-slf4j は Log4j2 API を SLF4J にブリッジするために使用され、jul-to-slf4j は java.util.logging API を SLF4J にブリッジするために使用されます。 3 ログの重複記録
ログの重複記録は、ログの閲覧や統計作業に無用な手間をもたらすだけでなく、ディスクやログ収集システムへの負担も増大します。
ロガー設定の継承関係によりログ記録が繰り返されることになる
- デバッグ、情報、警告、およびエラー ログの記録を実装するメソッドを定義する
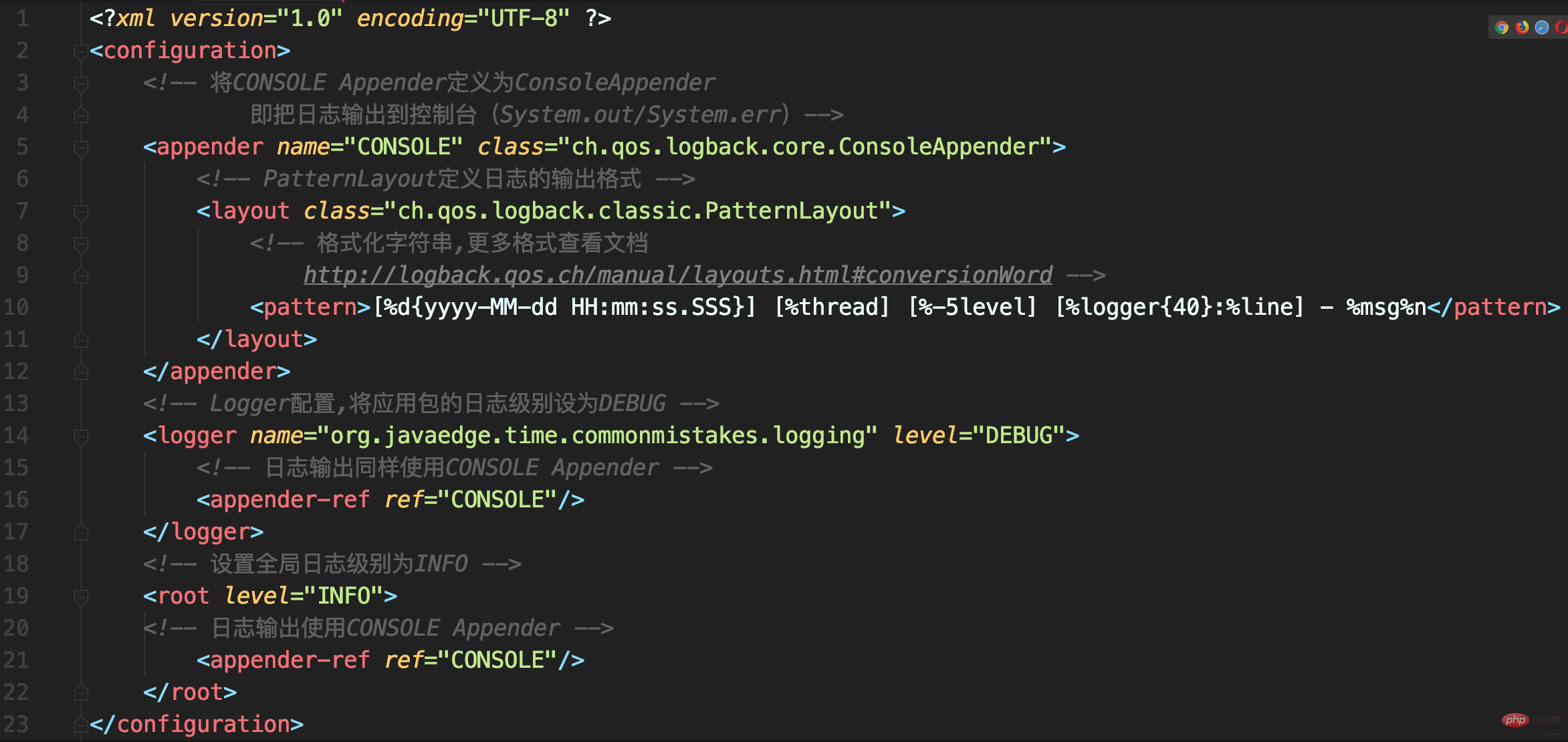
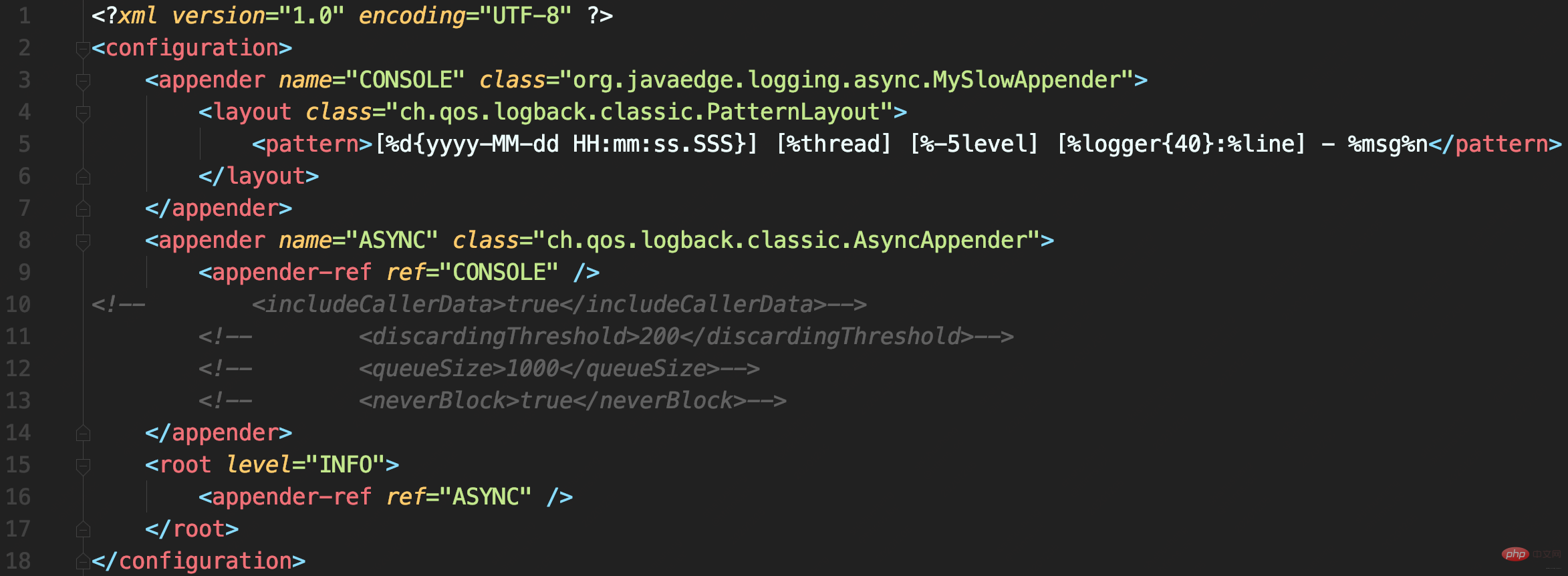
 ログバック構成
ログバック構成- 構成に問題はありませんが、メソッドの実行後に重複したログ レコードが表示されます
- 分析
- CONSOLE のアペンダーは、定義された
<logger>
とという 2 つのロガーに同時にマウントされます。 <root>、定義された<logger>は<root>から継承されるため、同じログがロガーを通じて記録され、ルート レコードなので、アプリケーション パッケージの下のログに重複したレコードが存在します。 このような構成の本来の目的は何でしょうか?

<logger>
: <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false"><logger name="org.javaedge.time.commonmistakes.logging" level="DEBUG"/></pre><div class="contentsignin">ログイン後にコピー</div></div> にマウントされているアペンダーを削除するだけです。
をカスタマイズする場合は、さまざまなアペンダーにログ出力する必要があります。 たとえば、
- 他のフレームワーク ログはコンソールに出力されます
- は、
の additivity 属性を false に設定できるため、## の Appender# は#<root> は継承されません。##<h2 id="LevelFilter-の構成が間違っているとログが重複する可能性があります">LevelFilter の構成が間違っているとログが重複する可能性があります</h2>
<ul>
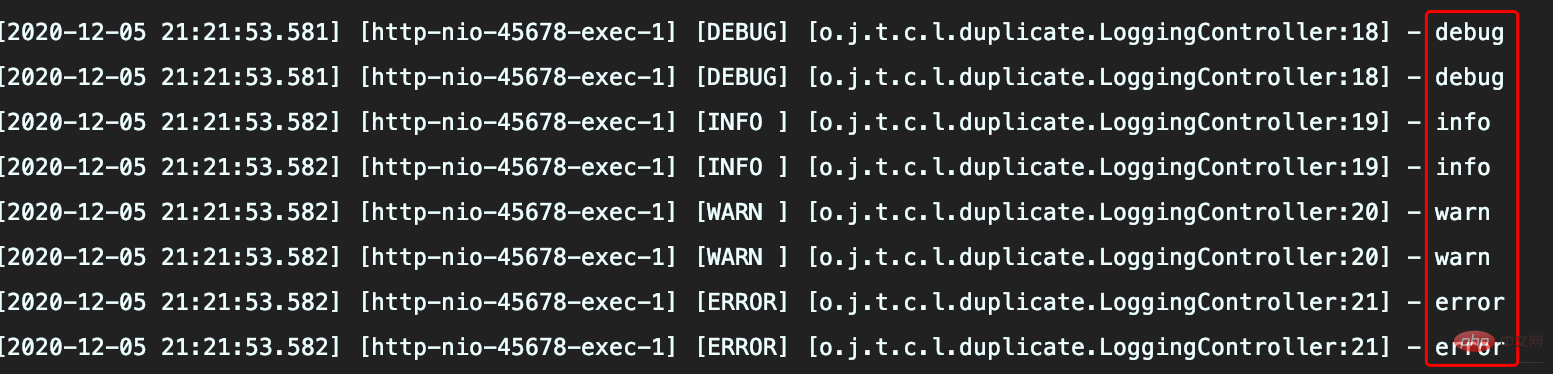
<li><p>ログをコンソールに記録する際、ログ レコードは異なるレベルに従って 2 つのファイルに記録されます<br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/627f5fcc448ae824438e604a1b26cad8-5.png" class="lazy" alt=""></p></li>
<li><p>実行結果</p></li>
<li>## info.log ファイルには、INFO、WARN、ERROR の 3 レベルのログが含まれていますが、これは予期したものではありません<p><br><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/627f5fcc448ae824438e604a1b26cad8-6.png" class="lazy" alt=""></p> </li>
<li>error.log には警告レベルとエラー レベルのログが含まれており、ログ収集が繰り返される結果になります<p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/052/41ca1a236e0def682612de6fc2bd1d35-7.png" class="lazy" alt=""></p>
</li>##事故責任<li> 一部の企業では自動化された ELK を使用していますログを収集するソリューション , ログはコンソールとファイルに同時に出力されます. 開発者はローカルでテストする場合、ファイルに記録されたログを気にする必要はありません. テスト環境や本番環境では、開発者はサーバーへのアクセス権を持っていないため、元のログ ファイルで繰り返される問題を見つけるのは困難です。 <p><br></p>#ログが繰り返されるのはなぜですか? </li>
</ul>ThresholdFilter ソース コード分析<p></p>
<h3 id="ログ-レベル-構成レベル">ログ レベル ≥ 構成レベル </h3> の場合、<ul>NEUTRAL<li> が返され、フィルター チェーン上の次のフィルターの呼び出しが継続されます。 <code> それ以外の場合は、DENY を返し、ログの記録を直接拒否します。
この場合、
 ThresholdFilter# を設定します。 ## から
ThresholdFilter# を設定します。 ## から WARN および ERROR レベルのログを記録できます。 LevelFilter は、ログ レベルを比較し、それに応じて処理するために使用されます。
一致がある場合、
onMatchで定義された処理メソッドが呼び出されます。デフォルトでは、処理のために次のフィルターに渡されます (デフォルト値は、 AbstractMatcherFilter 基本クラス)
- それ以外の場合は、
- onMismatch で定義された処理メソッドを呼び出します。デフォルトでは、次のフィルター
- # にも渡されます。
ThresholdFilter 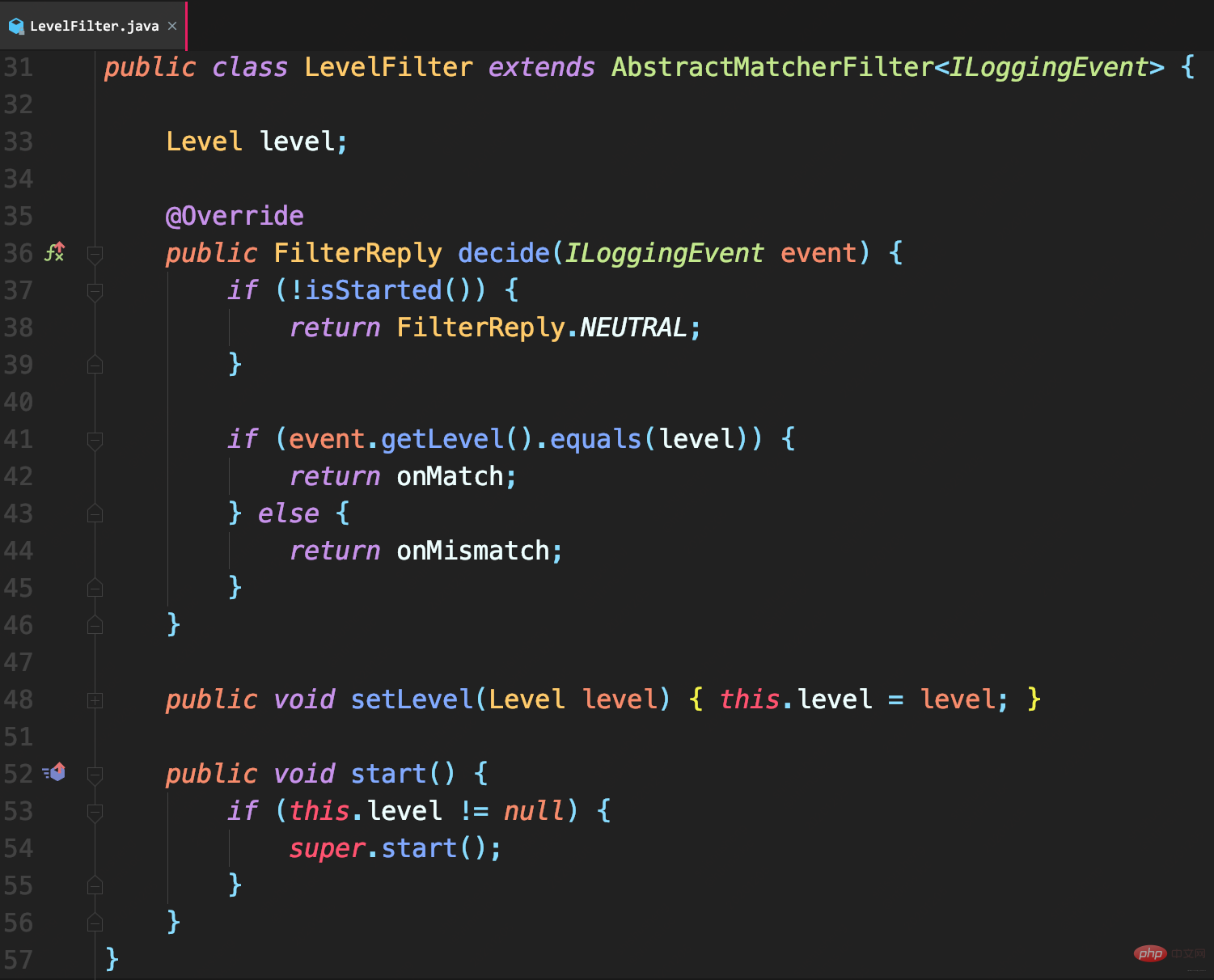 は異なり、
は異なり、
LevelFilter
。 onMatch 属性と onMismatch 属性が構成されていないため、フィルターは失敗し、INFO 以上のレベルのログが記録されます。 訂正LevelFilter の onMatch 属性を ACCEPT に設定すると、INFO レベルのログを受信します。onMismatch 属性を DENY に設定すると、INFO レベル以外はログに記録されません。
この方法では、
_info.log ファイルには INFO レベルのログのみが含まれ、重複したログは存在しません。 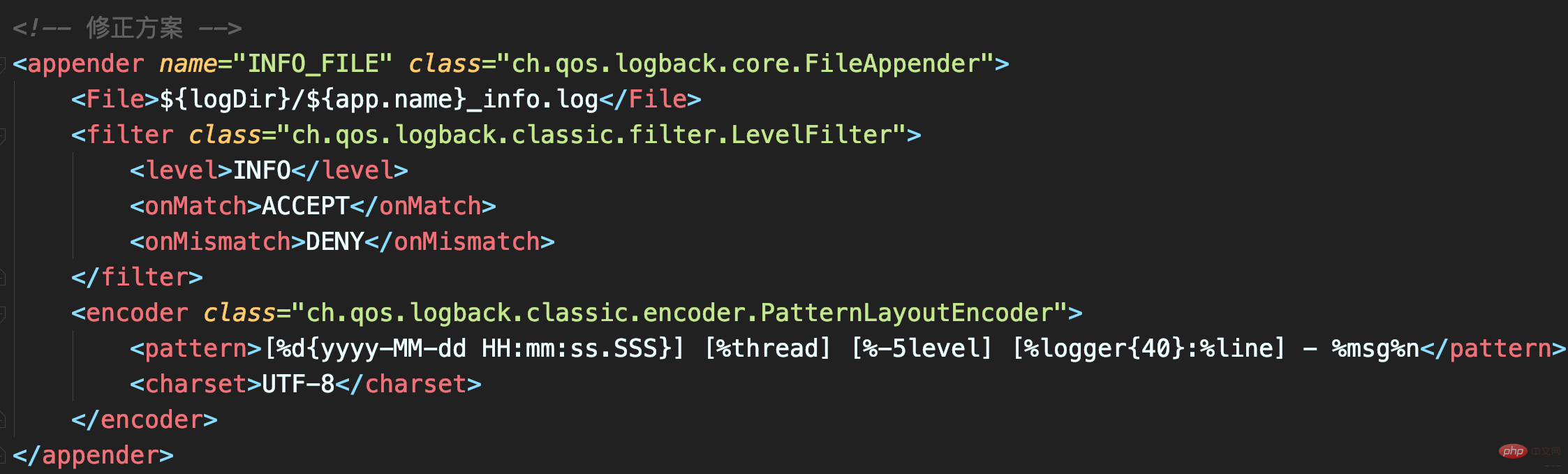 4 非同期ログによりパフォーマンスは向上しますか?
4 非同期ログによりパフォーマンスは向上しますか?
ログをファイルに正しく出力する方法がわかったら、ログがシステム パフォーマンスのボトルネックにならないようにする方法を検討する必要があります。これにより、ディスク(メカニカルディスクなど)のIO性能が悪く、ログ容量が大きい場合にログをどのように記録するかという問題を解決できます。 次のログ構成を定義します。合計 2 つのアペンダーがあります:
FILE はすべてのログを記録するために使用される FileAppender です;
CONSOLE は時間とともにレコードを記録するために使用される ConsoleAppender ですフラグ付きログ。大量のログをファイルに出力すると、ログファイルが非常に大きくなり、パフォーマンステストの結果も混在すると、そのログを見つけるのが困難になります。したがって、ここでは EvaluatorFilter を使用してタグに従ってログをフィルタリングし、フィルタリングされたログを個別にコンソールに出力します。この場合、テスト結果を出力するログにはタイムマークが付加されます。
タグと EvaluatorFilter を一緒に使用して、タグでログをフィルタリングします。 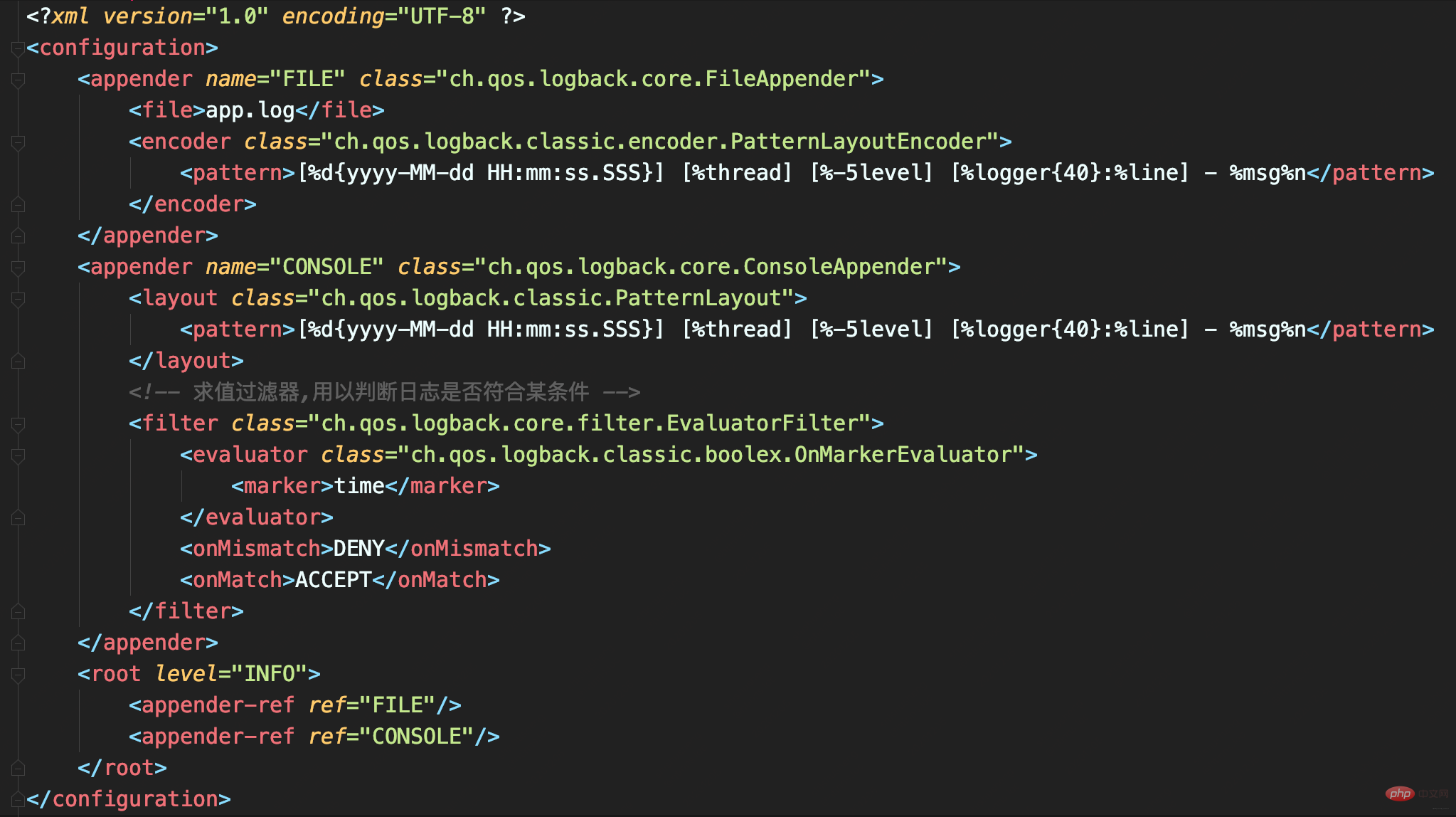
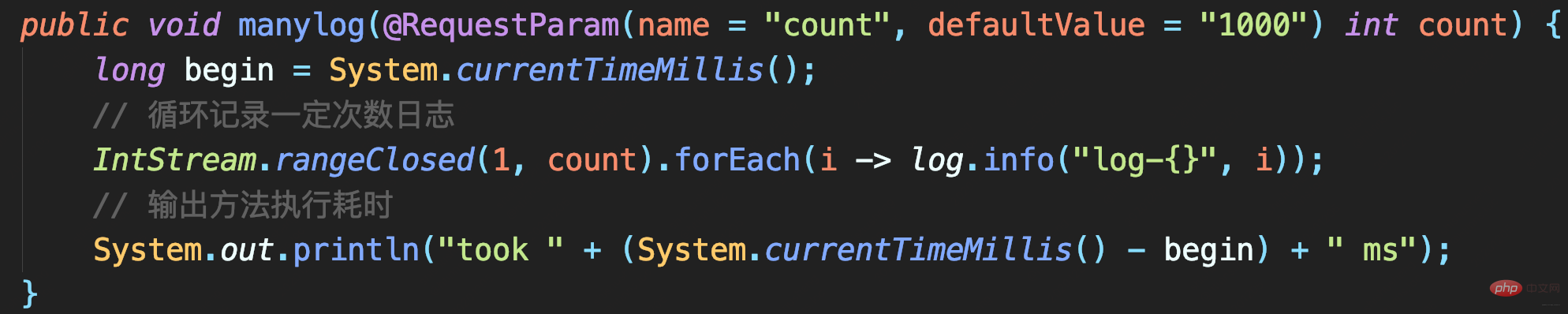
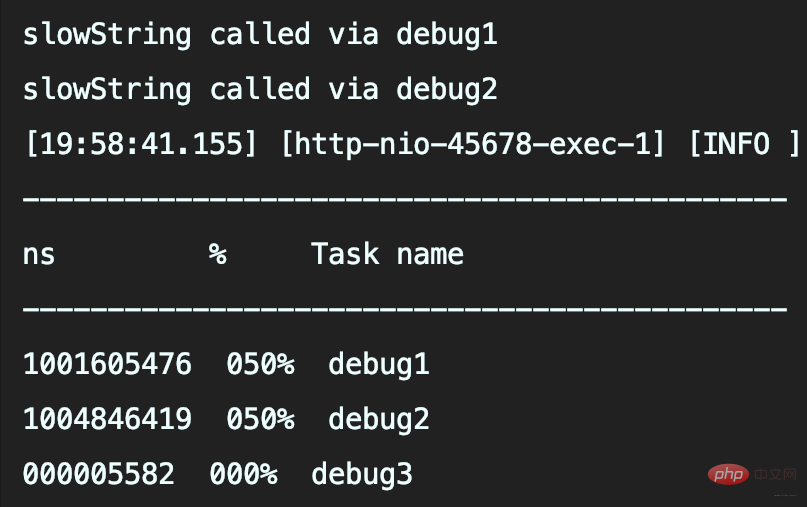
テスト コード: 指定された数の大きなログを記録します。各ログには 1MB のシミュレートされたデータが含まれます。最後に、時間のマークが付いたメソッドの実行に時間がかかるログが記録されます:プログラムを実行すると、1,000 件のログと 10,000 件のログ呼び出しの記録にかかる時間が、それぞれ 5.1 秒と 39 秒であることがわかります。
-
#ファイルログを記録するだけのコードの場合、これには時間がかかりすぎます。
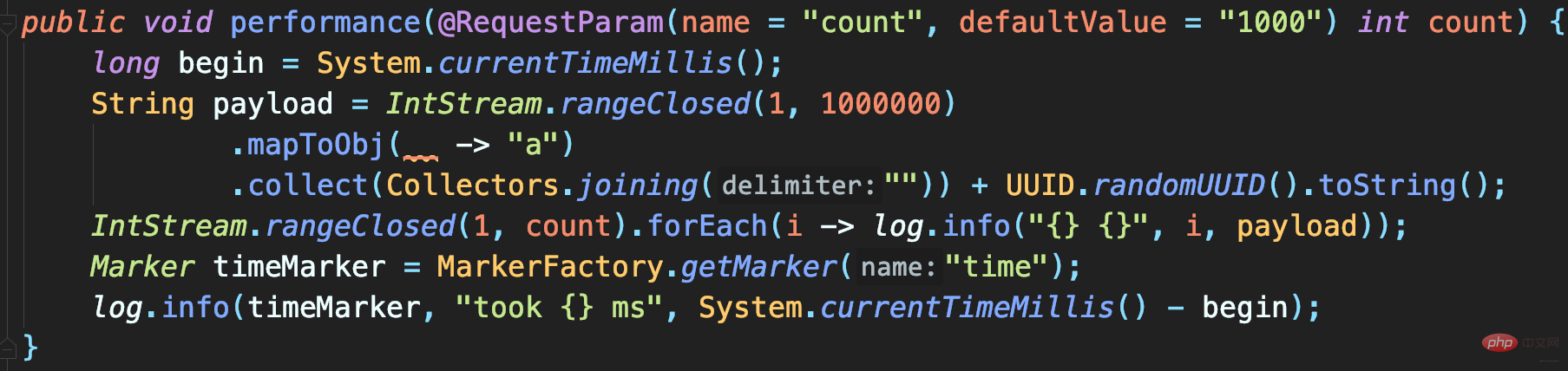 #ファイルログを記録するだけのコードの場合、これには時間がかかりすぎます。
#ファイルログを記録するだけのコードの場合、これには時間がかかりすぎます。
FileAppender は OutputStreamAppender を継承します

所以日志大量写入才会旷日持久。如何才能实现大量日志写入时,不会过多影响业务逻辑执行耗时而影响吞吐量呢?
AsyncAppender
使用Logback的AsyncAppender
即可实现异步日志记录。AsyncAppender类似装饰模式,在不改变类原有基本功能情况下为其增添新功能。这便可把AsyncAppender附加在其他Appender,将其变为异步。
定义一个异步Appender ASYNCFILE,包装之前的同步文件日志记录的FileAppender, 即可实现异步记录日志到文件
- 记录1000次日志和10000次日志的调用耗时,分别是537毫秒和1019毫秒


异步日志真的如此高性能?并不,因为这并没有记录下所有日志。
AsyncAppender异步日志坑
- 记录异步日志撑爆内存
- 记录异步日志出现日志丢失
- 记录异步日志出现阻塞。
案例
模拟慢日志记录场景:
首先,自定义一个继承自ConsoleAppender的MySlowAppender,作为记录到控制台的输出器,写入日志时休眠1秒。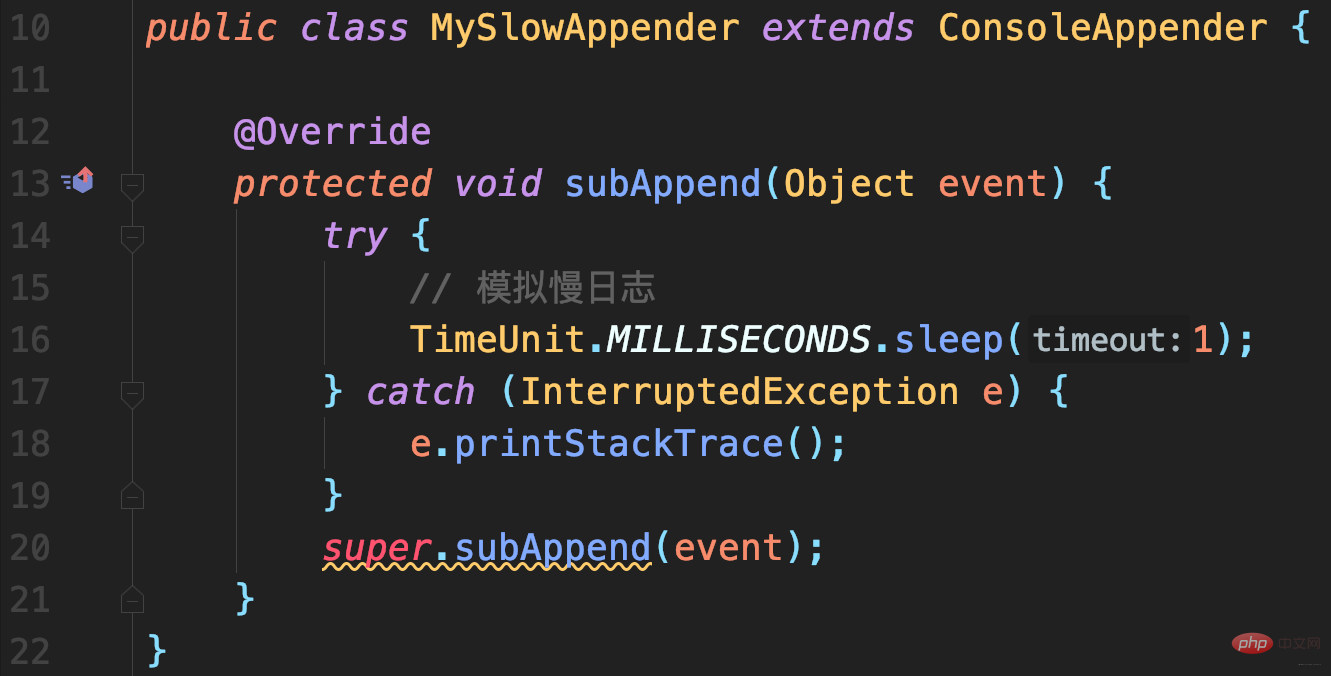
配置文件中使用AsyncAppender,将MySlowAppender包装为异步日志记录
测试代码
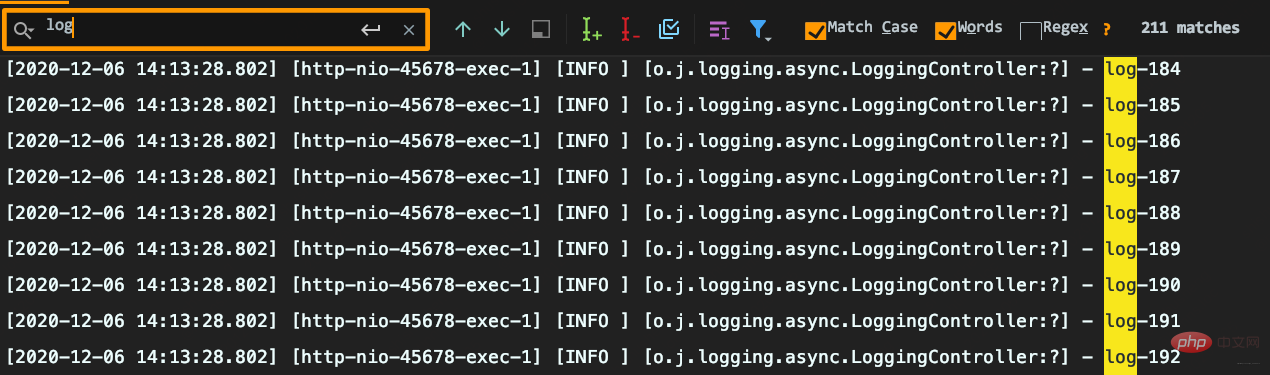
耗时很短但出现日志丢失:要记录1000条日志,最终控制台只能搜索到215条日志,而且日志行号变问号。
原因分析
AsyncAppender提供了一些配置参数,而当前没用对。
源码解析
- includeCallerData
默认false:方法行号、方法名等信息不显示 - queueSize
控制阻塞队列大小,使用的ArrayBlockingQueue阻塞队列,默认容量256:内存中最多保存256条日志 - discardingThreshold
丢弃日志的阈值,为防止队列满后发生阻塞。默认队列剩余容量 < 队列长度的20%,就会丢弃TRACE、DEBUG和INFO级日志 - neverBlock
控制队列满时,加入的数据是否直接丢弃,不会阻塞等待,默认是false- 队列满时:offer不阻塞,而put会阻塞
- neverBlock为true时,使用offer
public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {
// 是否收集调用方数据
boolean includeCallerData = false;
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
// 丢弃 ≤ INFO级日志
return level.toInt() <= Level.INFO_INT;
}
protected void preprocess(ILoggingEvent eventObject) {
eventObject.prepareForDeferredProcessing();
if (includeCallerData)
eventObject.getCallerData();
}}public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
// 阻塞队列:实现异步日志的核心
BlockingQueue<E> blockingQueue;
// 默认队列大小
public static final int DEFAULT_QUEUE_SIZE = 256;
int queueSize = DEFAULT_QUEUE_SIZE;
static final int UNDEFINED = -1;
int discardingThreshold = UNDEFINED;
// 当队列满时:加入数据时是否直接丢弃,不会阻塞等待
boolean neverBlock = false;
@Override
public void start() {
...
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
if (discardingThreshold == UNDEFINED)
//默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
discardingThreshold = queueSize / 5;
...
}
@Override
protected void append(E eventObject) {
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
return;
}
preprocess(eventObject);
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
private void put(E eventObject) {
if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
//以阻塞方式添加数据到队列
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}}默认队列大小256,达到80%后开始丢弃<=INFO级日志后,即可理解日志中为什么只有两百多条INFO日志了。
queueSize 过大
可能导致OOM
queueSize 较小
默认值256就已经算很小了,且discardingThreshold设置为大于0(或为默认值),队列剩余容量少于discardingThreshold的配置就会丢弃<=INFO日志。这里的坑点有两个:
- 因为discardingThreshold,所以设置queueSize时容易踩坑。
比如本案例最大日志并发1000,即便置queueSize为1000,同样会导致日志丢失 - discardingThreshold参数容易有歧义,它
不是百分比,而是日志条数。对于总容量10000队列,若希望队列剩余容量少于1000时丢弃,需配置为1000
neverBlock 默认false
意味总可能会出现阻塞。
- 若discardingThreshold = 0,那么队列满时再有日志写入就会阻塞
- 若discardingThreshold != 0,也只丢弃≤INFO级日志,出现大量错误日志时,还是会阻塞
queueSize、discardingThreshold和neverBlock三参密不可分,务必按业务需求设置:
- 若优先绝对性能,设置
neverBlock = true,永不阻塞 - 若优先绝不丢数据,设置
discardingThreshold = 0,即使≤INFO级日志也不会丢。但最好把queueSize设置大一点,毕竟默认的queueSize显然太小,太容易阻塞。 - 若兼顾,可丢弃不重要日志,把queueSize设置大点,再设置合理的discardingThreshold
以上日志配置最常见两个误区
ログ記録自体の誤解を見てみましょう。
ログ プレースホルダーを使用すると、ログ レベルを決定する必要がなくなります?
SLF4J の {} プレースホルダー構文は、ログが実際に記録されるときにのみ実際のパラメーターを取得するため、次の問題が解決されます。ログ データ取得に関するパフォーマンスの問題。 ### これは正しいです?
- 検証コード: 結果が返るまでに 1 秒かかります
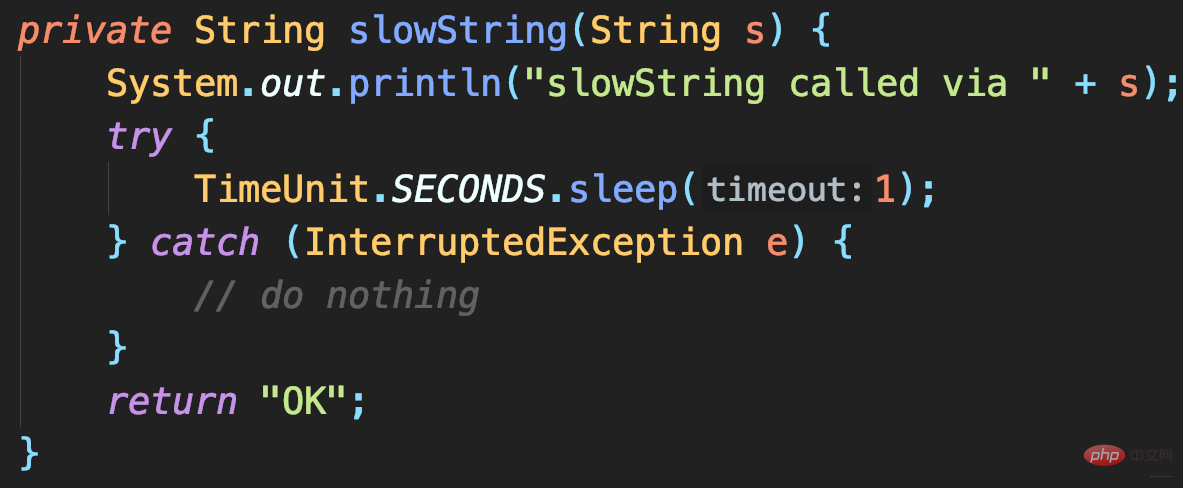
テストする 3 つのメソッド:
- 文字列を連結してslowStringを記録するプレースホルダー メソッドを使用してslowStringを記録するまず、ログ レベルが DEBUG 有効かどうかを確認します。
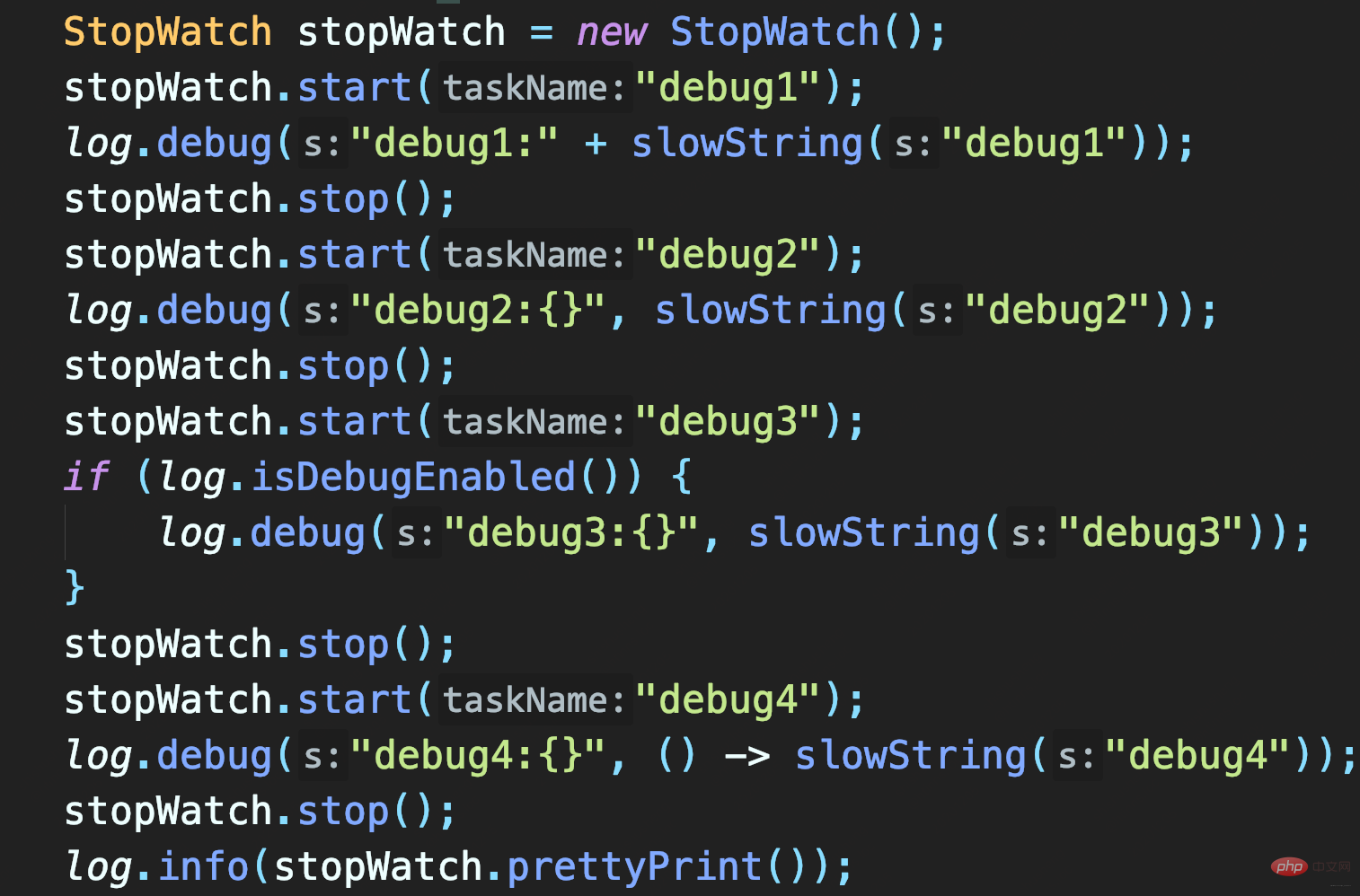
Log パラメータ object.toString( ) と 文字列の連結 には時間がかかります。
この場合、ログ レベルが事前に決定されていない限り、slowString を呼び出す必要があります。 したがって、
{} プレースホルダー を使用しても、パラメーター値の取得が遅れてログ データ取得のパフォーマンスの問題を解決できません。
Lombok の @Slf4j アノテーション を **@Log4j2** アノテーションに置き換えて、ラムダ式パラメーターのメソッドを提供する必要があります。 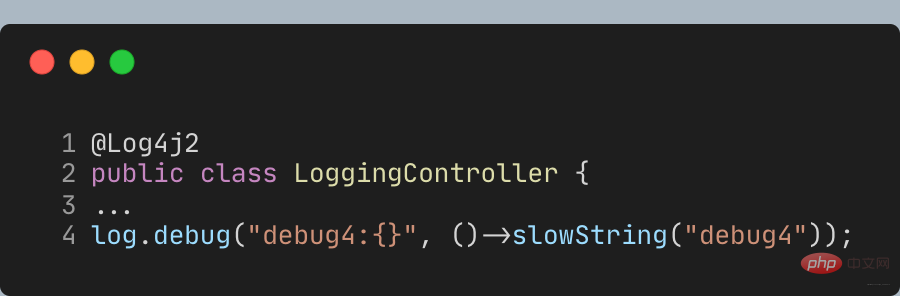 ## 次のようにデバッグを呼び出します。署名
## 次のようにデバッグを呼び出します。署名
、パラメータは実際にログを取得する必要があるまで遅延されます: 


 したがって、debug4 は、slowString メソッドを呼び出しません。
したがって、debug4 は、slowString メソッドを呼び出しません。
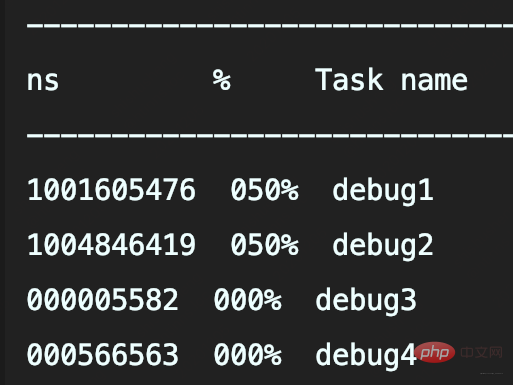 に置き換えるだけです。 #Log4j2 API
に置き換えるだけです。 #Log4j2 API
Logback を介して行われます。これは SLF4J 適応の利点です。 概要
SLF4J は Java ロギング フレームワークを統合します。 SLF4J を使用する場合、そのブリッジ API とバインディングを理解することが重要です。プログラムの起動時に SLF4J エラー メッセージが表示される場合は、設定に問題がある可能性があります。Maven の dependency:tree コマンドを使用して依存関係を整理できます。
- 非同期ログは、時間とスペースを交換することでパフォーマンスの問題を解決します。ただし、スペースには限りがあるので、スペースがいっぱいになった場合は、ブロックして待つか、ログを破棄することを検討する必要があります。重要なログを破棄したくない場合は、ブロック待機を選択します。ログによってプログラムがブロックされないようにしたい場合は、ログを破棄する必要があります。
- ログ フレームワークによって提供されるパラメーター化されたログ記録方法は、ログ レベルの判断を完全に置き換えることはできません。ログの量が大きく、ログ パラメーターの取得コストも高い場合は、ログを作成せずにログ パラメーターを取得するのに時間がかかることを避けるために、ログ レベルを決定する必要があります。
以上がJava ログ レベル、重複記録、ログ損失の問題を理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7566
7566
 15
1386
52
87
11
28
104
15
1386
52
87
11
28
104


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
