

遅い SQL 最適化の実践を記録する

sql チュートリアルSQL 遅いクエリの最適化の紹介

# 推奨 (無料): sql チュートリアル
1. 既存の問題
SQL の後クエリの最適化が遅いため、システムで次のタイプの問題が見つかりました:
1.未建索引:整张表没有建索引;2.索引未命中:有索引,但是部分查询条件下索引未命中;3.搜索了额外的非必要字段,导致回表;4.排序,聚合导致慢查询;5.相同内容多次查询数据库;6.未消限制搜索范围或者限制的搜索范围在预期之外,导致全部扫描;
#2。解決策
1.优化索引,增加或者修改当前的索引; 2.重写sql;3.利用redis缓存,减少查询次数;4.增加条件,避免非必要查询;5.增加条件,减少查询范围;
3. 症例分析
(1) 医薬品検索インターフェイス
完全な SQL ステートメントは付録にあります。便宜上、読書と脱感作、いくつかの一般的な分野は中国語です。 ここでは主に、SQL ステートメントを取得した後の分析プロセス全体、ロジックを考え、調整を行って最終的な解決策について説明します。 参考にしていただければ幸いです。より良い提案ができることを願っています。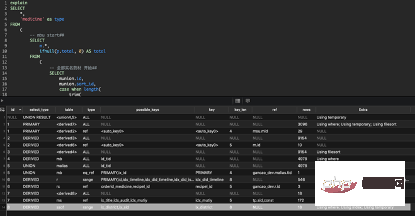
#1. SQL
- (1) 14-8
①説明8,DERIVED,ssof,range,"ix_district,ix_供应商id",ix_district,8,NULL,18,Using where; Using index; Using temporary
ログイン後にコピー
8,DERIVED,ssof,range,"ix_district,ix_供应商id",ix_district,8,NULL,18,Using where; Using index; Using temporary
②SQLSELECT DISTINCT (ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22, 24, 25, 26, 27, 31, 33) AND ssof.药方剂型id IN (1)
ログイン後にコピー
SELECT DISTINCT (ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22, 24, 25, 26, 27, 31, 33) AND ssof.药方剂型id IN (1)
③インデックスPRIMARY KEY (`id`), UNIQUE KEY `ix_district` ( `药库id`, `药方剂型id`, `供应商id` ) USING BTREE,KEY `ix_供应商id` (`供应商id`) USING BTREE
ログイン後にコピー
PRIMARY KEY (`id`), UNIQUE KEY `ix_district` ( `药库id`, `药方剂型id`, `供应商id` ) USING BTREE,KEY `ix_供应商id` (`供应商id`) USING BTREE
④分析
インデックスは一時テーブルの作成に使用されます。ここでのインデックスは完全にカバーされていますが、テーブルを返す操作がまだ残っています。 理由は、in が使用されており、テーブルが返されるためです。 mysql によって in が等しくなるように自動的に最適化できる場合、テーブルは返されません。最適化できない場合は、表に戻ります。 distinct のため、一時テーブルを回避できません。 inを同時に使用する場合は注意が必要で、inの値の数が比較的多い場合は数万個にもなります。たとえ区別性が高くても、インデックスの失敗につながり、複数のバッチ クエリが必要になります。2. 12-7
- (1)説明
7,DERIVED,<derived8>,ALL,NULL,NULL,NULL,NULL,18,Using temporary; Using filesort
- (2)SQL
INNER JOIN (上面14-8临时表) tp ON tp.供应商id= ms.供应商id
- ( 3) インデックス
- (4) 分析
3. 13-7
- (1)説明
7,DERIVED,ms,ref,"ix_title,idx_audit,idx_mutiy",idx_mutiy,5,"tp.供应商id,const",172,NULL
- (2)SQL
SELECT ms.药材表id, max(ms.audit) AS audit, max(ms.price) AS price, max(ms.market_price) AS market_price,max(ms.is_granule) AS is_granule,max(ms.is_decoct) AS is_decoct, max(ms.is_slice) AS is_slice,max(ms.is_cream) AS is_cream, max(ms.is_extract) AS is_extract,max(ms.is_cream_granule) AS is_cream_granule, max(ms.is_extract_granule) AS is_extract_granule,max(ms.is_drychip) AS is_drychip, max(ms.is_pill) AS is_pill,max(ms.is_powder) AS is_powder, max(ms.is_bolus) AS is_bolus FROM 供应商药材表 AS ms INNER JOIN ( SELECT DISTINCT (ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22, 24, 25, 26, 27, 31, 33 ) AND ssof.药方剂型id IN (1) ) tp ON tp.供应商id= ms.供应商id WHERE ms.audit = 1 GROUP BY ms.药材表id
- ( 3) インデックス
KEY `idx_mutiy` (`供应商id`, `audit`, `药材表id`)
- (4) 分析
4.10-6
- (1)説明
6,DERIVED,r,range,"PRIMARY,id,idx_timeline,idx_did_timeline,idx_did_isdel_statuspay_timecreate_payorderid,idx_did_statuspay_ischecked_isdel",idx_did_timeline,8,NULL,546,Using where; Using index; Using temporary; Using filesort
- (2)SQL
SELECT count(*) AS total, rc.i AS m药材表id FROM 处方药材表 AS rc INNER JOIN 药方表AS r ON r.id = rc.药方表_id WHERE r.did = 40 AND r.timeline > 1576115196 AND rc.type_id in (1, 3) GROUP BY rc.i
- (3) インデックス
KEY `idx_did_timeline` (`did`, `timeline`),
- (4) 分析
(1)説明
6,DERIVED,rc,ref,"orderid_药材表,药方表_id",药方表_id,5,r.id,3,Using where
- (2)SQL
- 同上
KEY `idx_药方表_id` (`药方表_id`, `type_id`) USING BTREE,
- (4) 分析
- インデックスの順序は問題ありませんが、がまだ残っているため、テーブルが返されます。
- (1)Explain
5,UNION,malias,ALL,id_tid,NULL,NULL,NULL,4978,Using where
- (2)Sql
SELECT mb.id, mb.sort_id, mb.title, mb.py, mb.unit, mb.weight, mb.tid, mb.amount_max, mb.poisonous, mb.is_auxiliary, mb.is_auxiliary_free, mb.is_difficult_powder, mb.brief, mb.is_fixed_recipe, ASE WHEN malias.py = 'GC' THEN malias.title ELSE CASE WHEN malias.title = 'GC' THEN malias.title ELSE '' END END AS atitle, alias.py AS apy, CASE WHEN malias.py = 'GC' THEN 2 ELSE CASE WHEN malias.title = 'GC' THEN 2 ELSE 1 END END AS ttid FROM 药材表 AS mb LEFT JOIN 药材表 AS malias ON malias.tid = mb.id WHERE alias.title LIKE '%GC%' OR malias.py LIKE '%GC%'
- (3)索引
KEY `id_tid` (`tid`) USING BTREE,
- (4)分析
因为like是左右like,无法建立索引,所以只能建tid。Type是all,遍历全表以找到匹配的行,左右表大小一样,估算的找到所需的记录所需要读取的行数有4978。这个因为是like的缘故,无法优化,这个语句并没有走索引,药材表 AS mb FORCE INDEX (id_tid) 改为强制索引,读取的行数减少了700行。
7.9-5
- (1)Explain
5,UNION,mb,eq_ref,"PRIMARY,ix_id",PRIMARY,4,malias.tid,1,NULL
- (2)Sql
同上
- (3)索引
PRIMARY KEY (`id`) USING BTREE,
- (4)分析
走了主键索引,行数也少,通过。
8.7-4
- (1)Explain
4,DERIVED,mb,ALL,id_tid,NULL,NULL,NULL,4978,Using where
-
(2)Sql
SELECT mb.id, mb.sort_id, mb.title, mb.py, mb.unit, mb.weight, mb.tid, mb.amount_max, mb.poisonous, mb.is_auxiliary, mb.is_auxiliary_free, mb.is_difficult_powder, mb.brief, mb.is_fixed_recipe, '' AS atitle, '' AS apy, CASE WHEN mb.py = 'GC' THEN 3 ELSE CASE WHEN mb.title = 'GC' THEN 3 ELSE 1 END END AS ttid FROM 药材表 AS mb WHERE mb.tid = 0 AND ( mb.title LIKE '%GC%' OR mb.py LIKE '%GC%' )
ログイン後にコピー (3)索引
KEY `id_tid` (`tid`) USING BTREE,
-
(4)分析
tidint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘真名药品的id’,
他也是like,这个没法优化。
9.6-3
- (1)Explain
3,DERIVED,<derived4>,ALL,NULL,NULL,NULL,NULL,9154,Using filesort
-
(2)Sql
UNION ALL
(3)索引
无
- (4)分析
就是把真名搜索结果和别人搜索结果合并。避免用or连接,加快速度 形成一个munion的表,初步完成药材搜索,接下去就是排序。
这一个进行了2次查询,然后用union连接,可以考虑合并为一次查询。用case when进行区分,计算出权重。
这边是一个优化点。
10.4-2
- (1)Explain
2,DERIVED,<derived3>,ALL,NULL,NULL,NULL,NULL,9154,NULL
-
(2)Sql
SELECT munion.id, munion.sort_id, case when length( trim( group_concat(munion.atitle SEPARATOR ' ') ) )> 0 then concat( munion.title, '(', trim( group_concat(munion.atitle SEPARATOR ' ') ), ')' ) else munion.title end as title, munion.py, munion.unit, munion.weight, munion.tid, munion.amount_max, munion.poisonous, munion.is_auxiliary, munion.is_auxiliary_free, munion.is_difficult_powder, munion.brief, munion.is_fixed_recipe, -- trim( group_concat( munion.atitle SEPARATOR ' ' ) ) AS atitle, ## -- trim( group_concat(munion.apy SEPARATOR ' ') ) AS apy, ## max(ttid) * 100000 + id AS ttid FROM munion <derived4> GROUP BY id -- 全部实名药材 结束##ログイン後にコピー (3)索引
无
- (4)分析
这里全部在临时表中搜索了。
11.5-2
- (1)Explain
2,DERIVED,<derived6>,ref,<auto_key0>,<auto_key0>,5,m.id,10,NULL
- (2)Sql
Select fields from 全部实名药材表 as m LEFT JOIN ( 个人使用药材统计表 ) p ON m.id = p.m药材表id
- (3)索引
无
- (4)分析
2张虚拟表left join
使用了优化器为派生表生成的索引
这边比较浪费性能,每次查询,都要对医生历史开方记录进行统计,并且统计还是几张大表计算后的结果。但是如果只是sql优化,这边暂时无法优化。
12.2-1
- (1)Explain
1,PRIMARY,<derived7>,ALL,NULL,NULL,NULL,NULL,3096,Using where; Using temporary; Using filesort
(2)Sql
(3)索引
(4)分析
临时表操作
13.3-1
- (1)Explain
1,PRIMARY,<derived2>,ref,<auto_key0>,<auto_key0>,4,msu.药材表id,29,NULL
(2)Sql
(3)索引
(4)分析
临时表操作
14.null
- (1)Explain
NULL,UNION RESULT,"<union4,5>",ALL,NULL,NULL,NULL,NULL,NULL,Using temporary
(2)Sql
(3)索引
(4)分析
临时表
(二)优化sql
上面我们只做索引的优化,遵循的原则是:
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
查询优化神器 - explain命令
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows。
化基本步骤:
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高;2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询);3.order by limit 形式的sql语句让排序的表优先查;4.了解业务方使用场景;5.加索引时参照建索引的几大原则;6.观察结果,不符合预期继续从0分析;
上面已经详细的分析了每一个步骤,根据上面的sql,去除union操作, 增加索引。可以看出,优化后虽然有所改善。但是距离我们的希望还有很大距离,但是光做sql优化,感觉也没有多少改进空间,所以决定从其他方面解决。
(三)拆分sql
由于速度还是不领人满意,尤其是个人用药情况统计,其实没必要每次都全部统计一次,再要优化,只靠修改索引应该是不行的了,所以考虑使用缓存。
接下来是修改php代码,把全部sql语句拆分,然后再组装。
- (1)搜索真名,别名(缓存)
SELECT mb.id, mb.sort_id, mb.title, mb.py, mb.unit, mb.weight, mb.tid, mb.amount_max, mb.poisonous, mb.is_auxiliary, mb.is_auxiliary_free, mb.is_difficult_powder, mb.brief, mb.is_fixed_recipe, IFNULL(group_concat(malias.title),'') atitle, IFNULL(group_concat(malias.py),'') apy FROM 药材表 AS mb LEFT JOIN 药材表 AS malias ON malias.tid = mb.id WHERE mb.tid = 0 AND ( malias.title LIKE '%GC%' OR malias.py LIKE '%GC%' or mb.title LIKE '%GC%' OR mb.py LIKE '%GC%' ) group by mb.id

- (2)如果命中有药材
①排序
真名在前,别名在后,完全匹配在前,部分匹配在后
//对搜索结果进行处理,增加权重
②对供应商药材搜索
SELECT ms.药材表id, max( ms.audit ) AS audit, max( ms.price ) AS price, max( ms.market_price ) AS market_price, max( ms.is_granule ) AS is_granule, max( ms.is_decoct ) AS is_decoct, max( ms.is_slice ) AS is_slice, max( ms.is_cream ) AS is_cream, max( ms.is_extract ) AS is_extract, max( ms.is_cream_granule) AS is_cream_granule, max( ms.is_extract_granule) AS is_extract_granule, max( ms.is_drychip ) AS is_drychip, max( ms.is_pill ) AS is_pill, max( ms.is_powder ) AS is_powder, max( ms.is_bolus ) AS is_bolus FROM 供应商药材表 AS ms WHERE ms.audit = 1 AND ms.供应商idin ( SELECT DISTINCT ( ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1,2,8,9,10,11,12,13,14,15,17,22,24,25,26,27,31,33 ) AND ssof.药方剂型id IN (1) ) AND ms.药材表id IN ( 78,205,206,207,208,209,334,356,397,416,584,652,988,3001,3200,3248,3521,3522,3599,3610,3624,4395,4396,4397,4398,4399,4400,4401,4402,4403,4404,4405,4406,4407,4408,5704,5705,5706,5739,5740,5741,5742,5743,6265,6266,6267,6268,6514,6515,6516,6517,6518,6742,6743 ) AND ms.is_slice = 1 GROUP BY ms.药材表id

③拿医生历史开方药材用量数据(缓存)
SELECT count( * ) AS total, rc.i AS 药材表id FROM 处方药材表 AS rc INNER JOIN 药方表AS r ON r.id = rc.药方表_id WHERE r.did = 40 AND r.timeline > 1576116927 AND rc.type_id in (1,3) GROUP BY rc.i

④ 装配及排序微调



- (3)小结
运行速度,对于开方量不是特别多的医生来说,两者速度都是0.1秒左右.但是如果碰到开方量大的医生,优化后的sql速度比较稳定,能始终维持在0.1秒左右,优化前的sql速度会超过0.2秒.速度提升约一倍以上。
最后对搜索结果和未优化前的搜索结果进行比对,结果数量和顺序完全一致.本次优化结束。
四、附录:
SELECT sql_no_cache
*FROM
(
-- mbu start## SELECT
m.*,
ifnull(p.total, 0) AS total FROM
(
--全部实名药材
开始
##SELECT
munion.id,
munion.sort_id,
case when length(
trim(
group_concat(munion.atitle SEPARATOR ' ')
)
)> 0 then concat(
munion.title,
'(',
trim(
group_concat(munion.atitle SEPARATOR ' ')
),
')'
) else munion.title end as title,
munion.py,
munion.unit,
munion.weight,
munion.tid,
munion.amount_max,
munion.poisonous,
munion.is_auxiliary,
munion.is_auxiliary_free,
munion.is_difficult_powder,
munion.brief,
munion.is_fixed_recipe,
-- trim( group_concat( munion.atitle SEPARATOR ' ' ) ) AS atitle,## -- trim( group_concat( munion.apy SEPARATOR ' ' ) ) AS apy,## max(ttid) * 100000 + id AS ttid FROM
(
-- #union start
联合查找,得到全部药材
## (
SELECT
mb.id,
mb.sort_id,
mb.title,
mb.py,
mb.unit,
mb.weight,
mb.tid,
mb.amount_max,
mb.poisonous,
mb.is_auxiliary,
mb.is_auxiliary_free,
mb.is_difficult_powder,
mb.brief,
mb.is_fixed_recipe,
'' AS atitle,
'' AS apy,
CASE WHEN mb.py = 'GC' THEN 3 ELSE CASE WHEN mb.title = 'GC' THEN 3 ELSE 1 END END AS ttid FROM
药材表 AS mb WHERE
mb.tid = 0
AND (
mb.title LIKE '%GC%'
OR mb.py LIKE '%GC%'
)
) --真名药材
结束
## UNION ALL
(
SELECT
mb.id,
mb.sort_id,
mb.title,
mb.py,
mb.unit,
mb.weight,
mb.tid,
mb.amount_max,
mb.poisonous,
mb.is_auxiliary,
mb.is_auxiliary_free,
mb.is_difficult_powder,
mb.brief,
mb.is_fixed_recipe,
CASE WHEN malias.py = 'GC' THEN malias.title ELSE CASE WHEN malias.title = 'GC' THEN malias.title ELSE '' END END AS atitle,
malias.py AS apy,
CASE WHEN malias.py = 'GC' THEN 2 ELSE CASE WHEN malias.title = 'GC' THEN 2 ELSE 1 END END AS ttid FROM
药材表 AS mb LEFT JOIN 药材表 AS malias ON malias.tid = mb.id WHERE
malias.title LIKE '%GC%'
OR malias.py LIKE '%GC%'
) --其他药材结束
## -- #union end## ) munion GROUP BY
id --全部实名药材
结束
## ) m LEFT JOIN (
--个人使用药材统计
开始
## SELECT
count(*) AS total,
rc.i AS m药材表id FROM
处方药材表 AS rc INNER JOIN 药方表AS r ON r.id = rc.药方表_id WHERE
r.did = 40
AND r.timeline > 1576115196
AND rc.type_id in (1, 3)
GROUP BY
rc.i --个人使用药材统计
结束
## ) p ON m.id = p.m药材表id -- mbu end ## ) mbu INNER JOIN (
-- msu start
供应商药材筛选
## SELECT
ms.药材表id,
max(ms.audit) AS audit,
max(ms.price) AS price,
max(ms.market_price) AS market_price,
max(ms.is_granule) AS is_granule,
max(ms.is_decoct) AS is_decoct,
max(ms.is_slice) AS is_slice,
max(ms.is_cream) AS is_cream,
max(ms.is_extract) AS is_extract,
max(ms.is_cream_granule) AS is_cream_granule,
max(ms.is_extract_granule) AS is_extract_granule,
max(ms.is_drychip) AS is_drychip,
max(ms.is_pill) AS is_pill,
max(ms.is_powder) AS is_powder,
max(ms.is_bolus) AS is_bolus FROM
供应商药材表 AS ms INNER JOIN (
SELECT
DISTINCT (ssof.供应商id) AS 供应商id FROM
药库供应商关系表 AS ssof WHERE
ssof.药库id IN (
1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22,
24, 25, 26, 27, 31, 33
)
AND ssof.药方剂型id IN (1)
) tp ON tp.供应商id= ms.供应商id WHERE
ms.audit = 1
GROUP BY
ms.药材表id -- msu end ## ) msu ON mbu.id = msu.药材表idWHERE
msu.药材表id > 0
AND msu.is_slice = 1order by
total desc,
ttid desc相关免费学习推荐:mysql视频教程
以上が遅い SQL 最適化の実践を記録するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 (2024 年時点の最新の LTS リリース) で導入された主な変更の 1 つは、「MySQL Native Password」プラグインがデフォルトで有効ではなくなったことです。さらに、MySQL 9.0 ではこのプラグインが完全に削除されています。 この変更は PHP および他のアプリに影響します
 PHPがMySQLに接続された後、ページは空白です。無効なDIE()関数の理由は何ですか?
Apr 01, 2025 pm 03:03 PM
PHPがMySQLに接続された後、ページは空白です。無効なDIE()関数の理由は何ですか?
Apr 01, 2025 pm 03:03 PM
PHPがMySQLに接続した後、ページは空白になり、DIE()関数が失敗する理由。 PHPとMySQLデータベースの間の接続を学習するとき、あなたはしばしばいくつかの混乱することに遭遇します...

 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 PCとモバイル側で同じページを共有し、キャッシュの問題を処理する方法は?
Apr 01, 2025 pm 01:57 PM
PCとモバイル側で同じページを共有し、キャッシュの問題を処理する方法は?
Apr 01, 2025 pm 01:57 PM
PCとモバイル側で同じページを共有し、キャッシュの問題を処理する方法は? Nginxでは、Baotaの背景を使用して構築されたPHP MySQL環境、PCサイドの作成方法と...
 PHPの楽観的なロックとトランザクション控除残高が組み合わされて失敗しました:バランスが並行性の状況で正しく控除されるようにする方法は?
Mar 31, 2025 pm 11:42 PM
PHPの楽観的なロックとトランザクション控除残高が組み合わされて失敗しました:バランスが並行性の状況で正しく控除されるようにする方法は?
Mar 31, 2025 pm 11:42 PM
この記事のPHPの楽観的ロックおよびトランザクションと組み合わせて残高を控除する問題の詳細な説明では、PHP、楽観的ロック、データベーストランザクションのみを使用したバランス控除を詳細に分析します...
 Redis Exporter サービスを使用した Redis ドロップレットの監視
Jan 06, 2025 am 10:19 AM
Redis Exporter サービスを使用した Redis ドロップレットの監視
Jan 06, 2025 am 10:19 AM
Redis データベースを効果的に監視することは、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために不可欠です。 Redis Exporter Service は、Prometheus を使用して Redis データベースを監視するように設計された堅牢なユーティリティです。 このチュートリアルでは、Redis Exporter Service の完全なセットアップと構成について説明し、監視ソリューションをシームレスに確立できるようにします。このチュートリアルに従うことで、Redis データベースのパフォーマンス メトリクスを効果的に監視するための完全に運用可能な監視セットアップを実現できます。
 Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
「DebianStrings」は標準的な用語ではなく、その特定の意味はまだ不明です。この記事は、ブラウザの互換性について直接コメントすることはできません。ただし、「DebianStrings」がDebianシステムで実行されているWebアプリケーションを指す場合、そのブラウザの互換性はアプリケーション自体の技術アーキテクチャに依存します。ほとんどの最新のWebアプリケーションは、クロスブラウザーの互換性に取り組んでいます。これは、次のWeb標準と、適切に互換性のあるフロントエンドテクノロジー(HTML、CSS、JavaScriptなど)およびバックエンドテクノロジー(PHP、Python、Node.jsなど)を使用することに依存しています。アプリケーションが複数のブラウザと互換性があることを確認するには、開発者がクロスブラウザーテストを実施し、応答性を使用する必要があることがよくあります
