

MySQL の驚くべき暗黙的変換を見てみましょう

Mysql チュートリアルのコラムでは、関連する暗黙的変換を紹介します

その他の関連する無料学習 推奨: mysql チュートリアル #(ビデオ)
1. 問題の説明
root@mysqldb 22:12: [xucl]> show create table t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`id` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
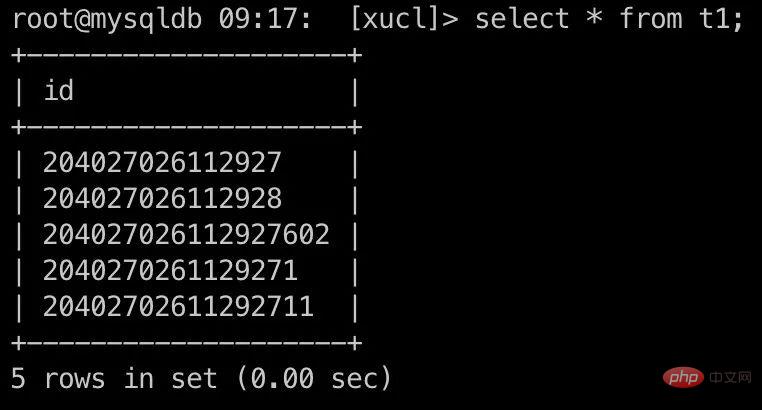
root@mysqldb 22:19: [xucl]> select * from t1;
+--------------------+
| id |
+--------------------+
| 204027026112927605 |
| 204027026112927603 |
| 2040270261129276 |
| 2040270261129275 |
| 100 |
| 101 |
+--------------------+
6 rows in set (0.00 sec)奇妙な現象:
root@mysqldb 22:19: [xucl]> select * from t1 where id=204027026112927603; +--------------------+ | id | +--------------------+ | 204027026112927605 | | 204027026112927603 | +--------------------+ 2 rows in set (0.00 sec)

#何だ、小切手は明らかに 204027026112927603 なのに、なぜ 204027026112927605 も出てくるのでしょう
2. ソースコードの説明
スタック呼び出し関係は次のとおりです:
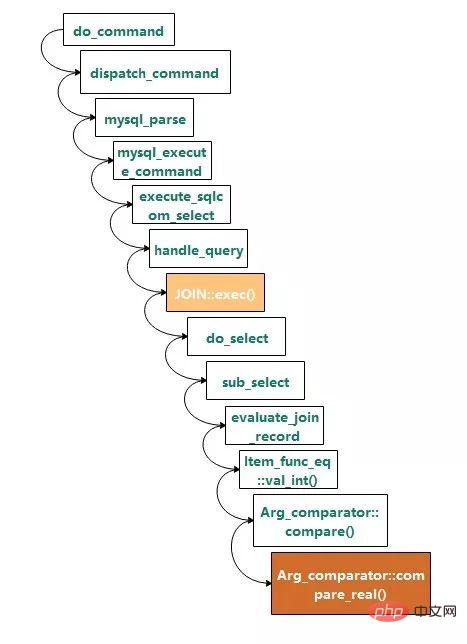
JOIN::exec( ) は実行のエントリポイント、 Arg_comparator::compare_real() は等価性判定の関数で、その定義は次のとおりです
int Arg_comparator::compare_real()
{
/*
Fix yet another manifestation of Bug#2338. 'Volatile' will instruct
gcc to flush double values out of 80-bit Intel FPU registers before
performing the comparison.
*/
volatile double val1, val2;
val1= (*a)->val_real();
if (!(*a)->null_value)
{
val2= (*b)->val_real();
if (!(*b)->null_value)
{
if (set_null)
owner->null_value= 0;
if (val1 < val2) return -1;
if (val1 == val2) return 0;
return 1;
}
}
if (set_null)
owner->null_value= 1;
return -1;
}比較手順は図のとおりです。下図、一行ずつ読み込む val1にはt1テーブルのidカラムが配置されており、定数204027026112927603がキャッシュに存在し、その型がdouble(2.0402702611292762E 17)なので、ここでval2に値を渡すと、val2=2.0402702611292762となります。 E17.
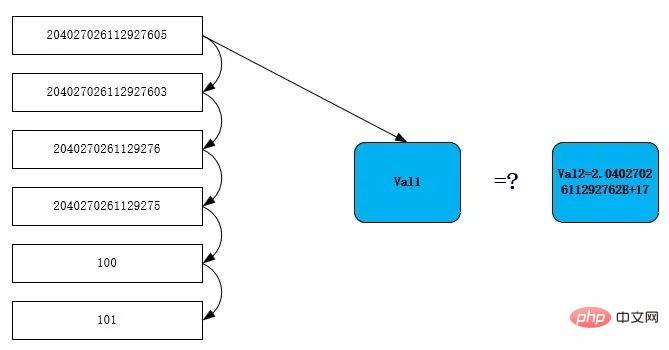
最初の行をスキャンすると、204027026112927605 をドゥール換算した値は 2.0402702611292762e17 となり、方程式が成立し、条件を満たす行と判断されます。理由 204027026112927603 は、

ドゥール型に変換された文字列型の数値がオーバーフローするかどうかを検出する方法?ここでテストした後、数値が 16 桁を超えた場合にも一致します。の場合、「The double type is selected inaccurate」に変換されます。たとえば、20402702611292711 は、20402702611292712 (図の val1)

MySQL 文字列変換 double への定義関数は次のとおりです:
{
char buf[DTOA_BUFF_SIZE];
double res;
DBUG_ASSERT(end != NULL && ((str != NULL && *end != NULL) ||
(str == NULL && *end == NULL)) &&
error != NULL);
res= my_strtod_int(str, end, error, buf, sizeof(buf));
return (*error == 0) ? res : (res < 0 ? -DBL_MAX : DBL_MAX);
}実際の変換関数 my_strtod_int は dtoa.c にあります (複雑すぎます。コメント)
/*
strtod for IEEE--arithmetic machines.
This strtod returns a nearest machine number to the input decimal
string (or sets errno to EOVERFLOW). Ties are broken by the IEEE round-even
rule.
Inspired loosely by William D. Clinger's paper "How to Read Floating
Point Numbers Accurately" [Proc. ACM SIGPLAN '90, pp. 92-101].
Modifications:
1. We only require IEEE (not IEEE double-extended).
2. We get by with floating-point arithmetic in a case that
Clinger missed -- when we're computing d * 10^n
for a small integer d and the integer n is not too
much larger than 22 (the maximum integer k for which
we can represent 10^k exactly), we may be able to
compute (d*10^k) * 10^(e-k) with just one roundoff.
3. Rather than a bit-at-a-time adjustment of the binary
result in the hard case, we use floating-point
arithmetic to determine the adjustment to within
one bit; only in really hard cases do we need to
compute a second residual.
4. Because of 3., we don't need a large table of powers of 10
for ten-to-e (just some small tables, e.g. of 10^k
for 0 <= k <= 22).
*/この場合、オーバーフローなしのテストの結果
root@mysqldb 23:30: [xucl]> select * from t1 where id=2040270261129276; +------------------+ | id | +------------------+ | 2040270261129276 | +------------------+ 1 row in set (0.00 sec) root@mysqldb 23:30: [xucl]> select * from t1 where id=101; +------+ | id | +------+ | 101 | +------+ 1 row in set (0.00 sec)
は期待どおりであり、この場合、正しい記述方法は
root@mysqldb 22:19: [xucl]> select * from t1 where id='204027026112927603'; +--------------------+ | id | +--------------------+ | 204027026112927603 | +--------------------+ 1 row in set (0.01 sec)
# 3. 結論
暗黙的な型変換を避ける 暗黙的な変換の種類には主にフィールド型の不一致、複数の型を含むパラメータ、文字セットの不一致などが含まれます。
暗黙的な型変換により、インデックスが使用できなくなったり、クエリ結果が不正確になったりする可能性があるため、慎重にスクリーニングする必要があります。使用する場合は、
フィールドを定義するときに、数値型を int または bigint として定義することをお勧めします。テーブルが関連付けられている場合、関連付けられたフィールドは維持される必要があります。同じ型、文字セット、および照合ルール
- #最後に、暗黙的な型変換に関する手順を公式 Web サイトから投稿してください
#えー
以上がMySQL の驚くべき暗黙的変換を見てみましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7401
7401
 15
1630
14
1358
52
1268
25
1217
29
15
1630
14
1358
52
1268
25
1217
29

 PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL データベースをバックアップおよび復元するには、次の手順を実行します。 データベースをバックアップします。 mysqldump コマンドを使用して、データベースを SQL ファイルにダンプします。データベースの復元: mysql コマンドを使用して、SQL ファイルからデータベースを復元します。
 PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
MySQL クエリのパフォーマンスは、検索時間を線形の複雑さから対数の複雑さまで短縮するインデックスを構築することで最適化できます。 PreparedStatement を使用して SQL インジェクションを防止し、クエリのパフォーマンスを向上させます。クエリ結果を制限し、サーバーによって処理されるデータ量を削減します。適切な結合タイプの使用、インデックスの作成、サブクエリの使用の検討など、結合クエリを最適化します。クエリを分析してボトルネックを特定し、キャッシュを使用してデータベースの負荷を軽減し、オーバーヘッドを最小限に抑えます。
 PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
MySQLテーブルにデータを挿入するにはどうすればよいですか?データベースに接続する: mysqli を使用してデータベースへの接続を確立します。 SQL クエリを準備します。挿入する列と値を指定する INSERT ステートメントを作成します。クエリの実行: query() メソッドを使用して挿入クエリを実行します。成功すると、確認メッセージが出力されます。
 PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するには、次の手順が必要です。 データベースに接続します。データベースが存在しない場合は作成します。データベースを選択します。テーブルを作成します。クエリを実行します。接続を閉じます。
 PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するには: PDO または MySQLi 拡張機能を使用して、MySQL データベースに接続します。ストアド プロシージャを呼び出すステートメントを準備します。ストアド プロシージャを実行します。結果セットを処理します (ストアド プロシージャが結果を返す場合)。データベース接続を閉じます。
 MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 (2024 年時点の最新の LTS リリース) で導入された主な変更の 1 つは、「MySQL Native Password」プラグインがデフォルトで有効ではなくなったことです。さらに、MySQL 9.0 ではこのプラグインが完全に削除されています。 この変更は PHP および他のアプリに影響します
 Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracle データベースと MySQL はどちらもリレーショナル モデルに基づいたデータベースですが、Oracle は互換性、スケーラビリティ、データ型、セキュリティの点で優れており、MySQL は速度と柔軟性に重点を置いており、小規模から中規模のデータ セットに適しています。 ① Oracle は幅広いデータ型を提供し、② 高度なセキュリティ機能を提供し、③ エンタープライズレベルのアプリケーションに適しています。① MySQL は NoSQL データ型をサポートし、② セキュリティ対策が少なく、③ 小規模から中規模のアプリケーションに適しています。
 C言語でboolを使う方法
May 09, 2024 pm 01:00 PM
C言語でboolを使う方法
May 09, 2024 pm 01:00 PM
C言語のbool型はtrue/falseを表し、値は1(true)か0(false)になります。 bool is_true = true; を使用してブール変数を宣言および初期化することも、true/false キーワードを使用することもできます。ブール変数では、論理 NOT、AND、OR、および XOR 演算を使用できます。ブール式は条件ステートメントとループで使用されます。 bool 型は暗黙的に int 型 (1: true、0: false) に変換できます。また、int 型は暗黙的に bool 型 (0 以外: true、0: false) に変換できます。
