

ビッグデータ学習向けの高度な MYSQL

# 無料の学習に関する推奨事項: mysql ビデオ チュートリアル
記事ディレクトリ
- 1 パフォーマンスに影響するいくつかの側面
- 1.1 ハードウェア側面
- 1.2 サーバー システム
- 1.3 データベース ストレージ エンジン選択
- 1.4 データベースパラメータの構成
- 1.5 データベース構造設計とSQL文(重要なポイント)
2 ハードウェア面- 2.1 CPU リソースと使用可能なメモリ サイズ
-
- 2.1.1 CPU の選択方法
- 2.1.2 メモリ
-
- 2.1.2.1 一般的に使用される MySQL ストレージ エンジン
- 2.1.2.2 ヒント
- 2.1.2.3 メモリの選択方法
- 2.2.1 従来のマシンのハードディスクの使用
- 2.2.2 RAID を使用して従来のマシンのハードディスクのパフォーマンスを強化する
- 2.2.2.1 RAID とは
- 2.2.2.2 RAID レベル
- 2.2.2.2.1 RAID 0
- 2.2.2.2.2 RAID 1
- 2.2.2.2.3 RAID 5 - 共通 RAID グループ
- 2.2.2.2.4 RAID 10 - 共通 RAID グループ
- 2.2.2.3 RAID レベルの選択
- 2.2.3 ソリッドステート ストレージ SSD および PCIe カードの使用
- ##2.2.4.1 ネットワーク ストレージの使用シナリオ
- 2.2.4.2 ネットワーク パフォーマンスの制限
- 2.2.4.3 ネットワークのパフォーマンスへの影響
- 2.3 概要
3 オペレーティング システムのパフォーマンスへの影響
3.1 CentOS システムのパラメーターの最適化- 4 ファイル システムがパフォーマンスに及ぼす影響
- 5 MySQL アーキテクチャ
- 1 パフォーマンスに影響を与えるいくつかの側面
1.1 ハードウェアの側面
通常、パーソナル コンピュータの動作が遅いのは、コンピュータのハードウェアの問題 (通常は CPU、メモリ、ディスク IO、など、この問題はサーバーでも発生します。1.2 サーバーシステム
一般にパソコンのオペレーティングシステムは Windows ですが、Windows システムのバージョンが異なればパフォーマンスが異なったり、特定のパラメータの設定により性能が異なったりすることがあります。性能の違い。これはサーバーシステムでも同様であり、パラメータ設定はサーバーのパフォーマンスにも影響します。1.3 データベース ストレージ エンジンの選択
MySQL にはプラグイン ストレージ エンジンがあり、さまざまなビジネス ニーズに応じてさまざまなストレージ エンジンを選択できます。ストレージ エンジンが異なれば、特性も異なります。
MyISAM: トランザクションとテーブル レベルのロックはサポートされません。
InnoDB: トランザクション レベルのストレージ エンジン。行レベルのロックとトランザクション ACID 機能を完全にサポートします。
- 1.4 データベース パラメータの構成
1.5 データベース構造設計と SQL ステートメント (キーポイント)
データベース構造を設計するときは、データベース上でどのような SQL ステートメントを実行するかを考慮する必要があります。 、テーブル構造をクエリして更新するこの方法でのみ、要件を満たすテーブル構造を設計できます。遅いクエリの場合、これがパフォーマンス低下の主な原因であり、データベース テーブル構造の不合理な設計が原因です。このタイプの SQL は、プロジェクトがオンラインになるとデータベース テーブル構造を変更するのが難しいため、最適化が最も困難です。 したがって、データベースのパフォーマンスの最適化に重点を置くのは次のとおりです。
データベース テーブル構造の設計
SQL ステートメントの準備と最適化
以下は各側面の詳細な説明です。
2 ハードウェアの側面
2.1 CPU リソースと利用可能なメモリ サイズ
2.1.1 CPU の選択方法
通常、CPU を選択するとき、CPU の周波数とコア数の両方ができるだけ高いことを望みますが、コストやさまざまな要因により、CPU のみを選択せざるを得なくなることがよくあります。それらの中の一つ。では、最適なソリューションをどのように選択すればよいのでしょうか?したがって、CPU を購入する際には、次のようないくつかの問題に注意する必要があります。- アプリケーションは CPU に負荷をかけていますか?
- アプリケーションが CPU を大量に使用する場合、SQL 処理を高速化するには、明らかに more CPU ではなく、better CPU が必要です。
- 現在の MySQL では、duoCPU は同じ SQL の同時処理をサポートしていません。
- システムの同時実行性はどれくらいですか?
- システムがより多くのスループットを必要とする場合、CPU の数が多いほど良いです。 CPU が 40 個あると仮定すると、同時に 40 個の SQL を処理できますか?
- データベース処理能力の測定: QPS、同時に処理される SQL の数を指します。ただし、この指標は 1 秒間に処理される SQL の数ですが、前のポイントで説明した同時処理はナノ秒の次元です。
- MySQL は通常、Web アプリケーションで使用され、同時実行の量が比較的大きいことが多く、このとき、CPU 周波数よりも CPU の数が重要です。
- 私たちが使用する MySQL のバージョン
- バージョン 5.0 より前の MySQL はマルチコア CPU を十分にサポートしておらず、システムに対する制限は非常に深刻でした。現在の 5.6 および 5.7 バージョンでは、マルチコア CPU のサポートが大幅に改善されました。したがって、より良いパフォーマンスを実現するには、最新バージョンの MySQL を使用することをお勧めします。
- 32 ビットまたは 64 ビットの CPU を選択しますか?
- 現在、サーバー CPU はデフォルトですべて 64 ビット アーキテクチャですが、システムの 64 ビット システム上に 32 ビット サーバー バージョンがインストールされているかどうかを注意して確認してください。これはサーバーのパフォーマンスに重大な影響を与えます。 。
2.1.2 メモリ
メモリのサイズは、データベースのパフォーマンスに直接影響します。現在、メモリはディスクよりもはるかに効率的です。したがって、データをメモリにキャッシュすると、サーバーのパフォーマンスが大幅に向上します。
2.1.2.1 一般的に使用される MySQL ストレージ エンジン
一般的に使用されるストレージ エンジンは、MyISAM と InnoDB の 2 つです。
MyISAM:
インデックスはメモリに保存され、データはハード ディスクに保存されます。 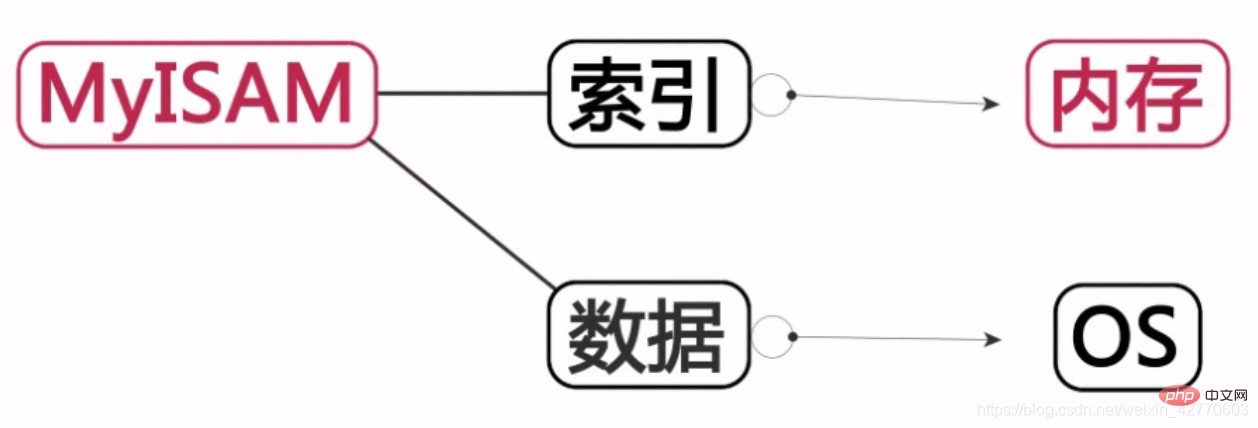
InnoDB:
インデックスとデータはメモリに保存されるため、データベースの運用効率が向上します。 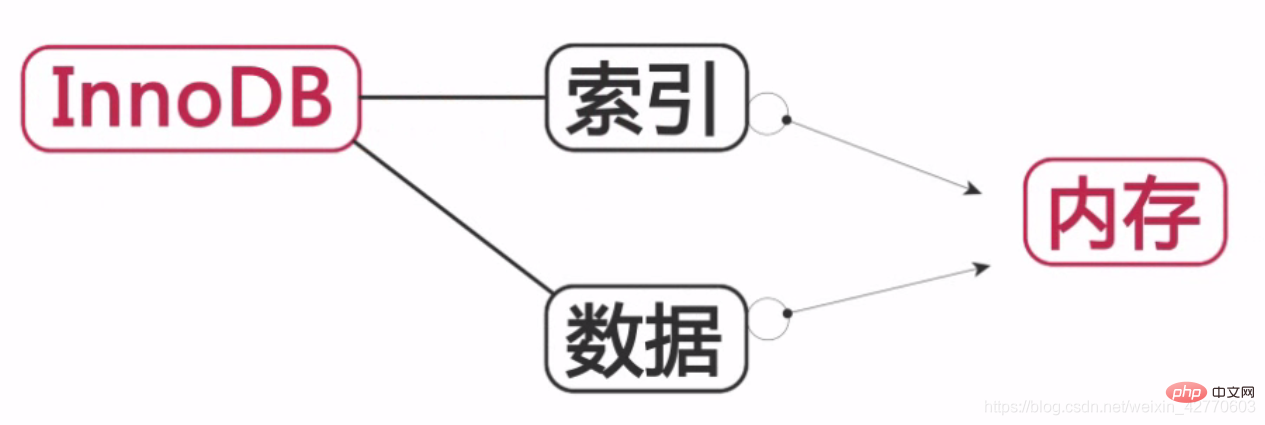
2.1.2.2 ヒント
- メモリは多いほど優れていますが、システム パフォーマンスへの影響は限定的です。
データベース内のデータが 100G の場合、128G 程度のメモリを選択すると最大のパフォーマンスが得られますが、このときすべてのデータがホットデータであればメモリにキャッシュされます。ただし、より大きなメモリを選択すると、オペレーティング システムなどの他のサービスのパフォーマンスも向上するため、短期的にはメモリのアップグレードを検討する必要はありません。 - メモリ キャッシュ書き込み操作の場合、データベースへの負荷を軽減するために書き込みを遅らせることができます。
メモリはすでに読み取り操作を適切にサポートしており、書き込み操作もメモリ内で完了できます。最終的には、データをディスクに書き込む必要があります。ディスクへの書き込み操作を避けることはできませんが、遅延させることはできます。書き込み操作を実行し、複数の書き込みを 1 つの書き込みにマージして、データベースへの負荷を軽減します。データベースには同様の機能があり、複数の書き込み操作をキャッシュ プール内の 1 つにマージし、最終的にディスクに書き込むことができます。
2.1.2.3 メモリの選択方法
マザーボードが最大周波数をサポートできるメモリを使用するようにしてください。
購入アップグレードを行うには、各チャネルのメモリが同じブランド、粒子サイズ、周波数、電圧、検証テクノロジ、およびモデルである必要があります。 - データベースのサイズに基づいてメモリを選択します。
2.2 ディスク構成と選択
メモリはデータベースのパフォーマンスに大きな役割を果たしますが、パフォーマンスに対する IO サブシステムの影響を無視することはできません。現在、一般的に次の 4 種類のディスク オプションを使用しています。2.2.1 従来のマシンのハード ドライブの使用
特徴: 大容量のストレージ スペース、低価格、ほとんどの使用されている、最も一般的な、読み取りと書き込みが遅い- 従来のマシンのハードディスクを選択するにはどうすればよいですか?
- 伝送速度
- アクセス時間
- スピンドル速度
- 物理的サイズ
##2.2.2.1 RAID
RAID とはディスク冗長性 Redundant Arrays of Independent Disks の略で、簡単に言うと、RAID の機能は、複数の小さな容量のディスクを組み合わせて、より大きな容量のディスクのグループにし、データの冗長性を提供してデータの整合性を確保することです。
#2.2.2.2 RAID レベル
##2.2.2.2.1 RAID 0
RAID 0 は最も初期の RAID モードであり、データ ストライピングとも呼ばれます。コンポーネント ディスク アレイの中で 最も単純な形式であり、2 台以上のハードディスクのみが必要で、低コスト であり、ディスク全体のパフォーマンスとスループットを向上させることができます。 RAID 0 は冗長性やエラー回復機能 を提供しませんが、実装コストは最も低くなります。ただし、データの回復と信頼性の要素を考慮すると、RAID 0 が最も高価な構成になります。これは、RAID 0 には冗長性がなく、データ損傷の可能性が単一ディスクの場合よりも高いためです。どのディスクでもデータが損傷するとデータが失われるためです。たとえば、3 つのディスクで構成される RAID 0 は、1 つのハードディスクよりも損傷する可能性が 3 倍高くなります。 したがって、RAID 0 は、いつでも他のデータベースからクローンを作成できるスタンバイ データベースや、一度だけ使用する必要があるデータベースなど、単一のデータが失われることがない状況に適しています。 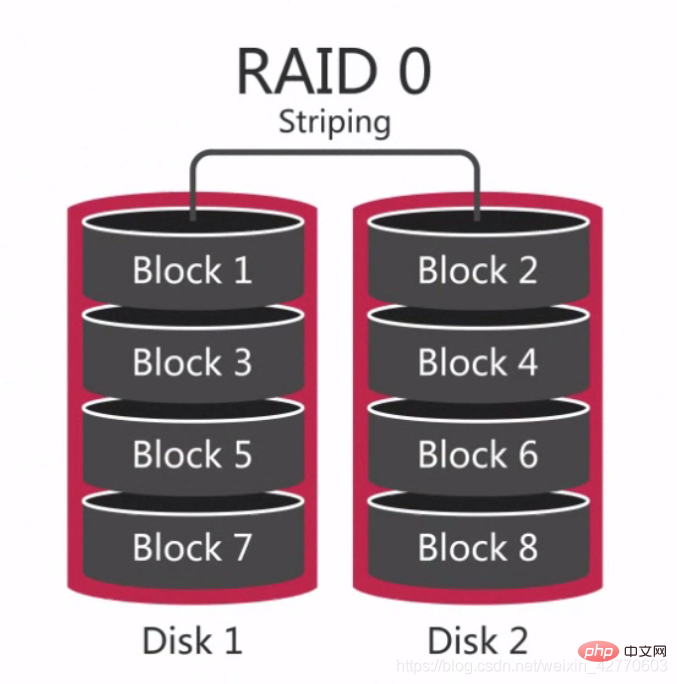 簡単に言えば、RAID 0 は、ハードディスクを直列に接続して、次のような大きなディスクを形成することです。
簡単に言えば、RAID 0 は、ハードディスクを直列に接続して、次のような大きなディスクを形成することです。 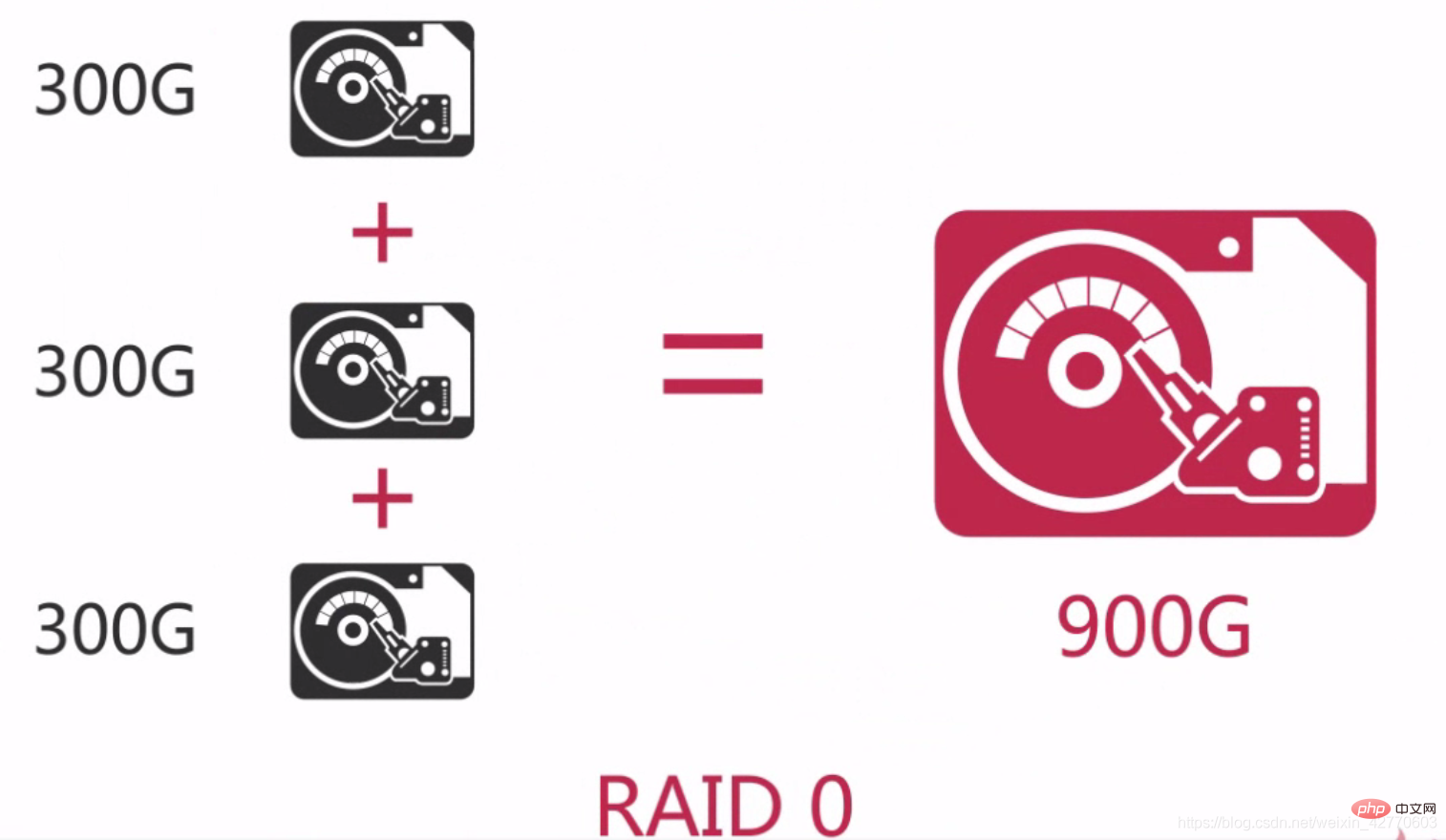 また、同時プロセスでは、同等のディスクに達することができます。単一ハードドライブの 3 倍のパフォーマンス。
また、同時プロセスでは、同等のディスクに達することができます。単一ハードドライブの 3 倍のパフォーマンス。
ディスク ミラーリング とも呼ばれ、その原理は、あるディスクのデータを別のディスクにミラーリングすることです。 1 つのディスクへの書き込み中に、パフォーマンスに影響を与えることなくシステムの信頼性と修復可能性を最大限に確保するために、イメージ ファイルが別の制限されたディスクに生成されます。 RAID 0 との違いは、中央に等号が描かれていることです。両方のディスク上のデータは同じであり、優れた冗長性機能を備えていますが、その分コストが増加します。ディスク障害が発生した場合、正常に実行できますが、障害が発生したディスクを交換する必要があり、そうしないとシステムがクラッシュします。
新しいディスクを交換すると、データの同期に時間がかかり、データ アクセスには影響しませんが、システムのパフォーマンスが低下します。 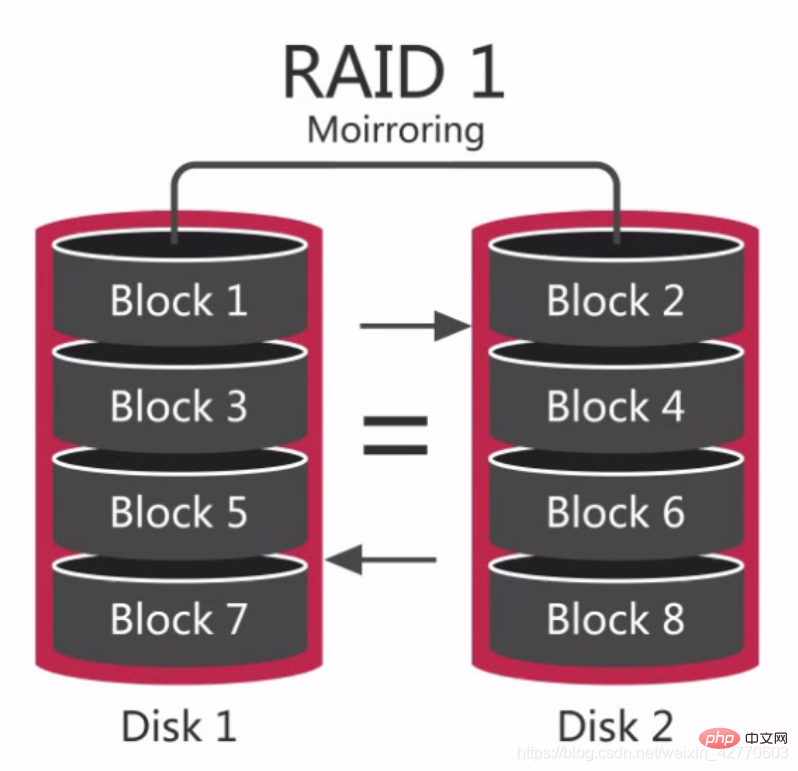 RAID 1 は、多くの場合、良好な
RAID 1 は、多くの場合、良好な
read
パフォーマンスを提供し、異なるディスク間でデータを冗長化できるため、データの冗長性が非常に優れています。 RAID 1 は RAID 0 よりも読み取りに優れているため、ログや同様のタスクの保存に適しています。
2.2.2.2.3 RAID 5 - 共通 RAID グループ
データは分散パリティ ブロックを通じて複数のディスク
に分散されているため、ディスク データに障害が発生した場合でもパリティ ブロックから再構築できます。ただし、2 つのディスクに障害が発生した場合、ボリューム全体のデータを回復することはできません。 各ディスクにはそれぞれ Dp、Cp、Bp、Ap があることがわかります。いずれかのディスクに問題がある場合は、データとパリティ値に基づいてディスクを再計算できます。他の 3 つのディスクのデータ。
RAID 0 および RAID 1 の場合、アレイ構成全体に必要な容量は 1 台のディスクのみであるため、これは最も経済的な冗長構成です。 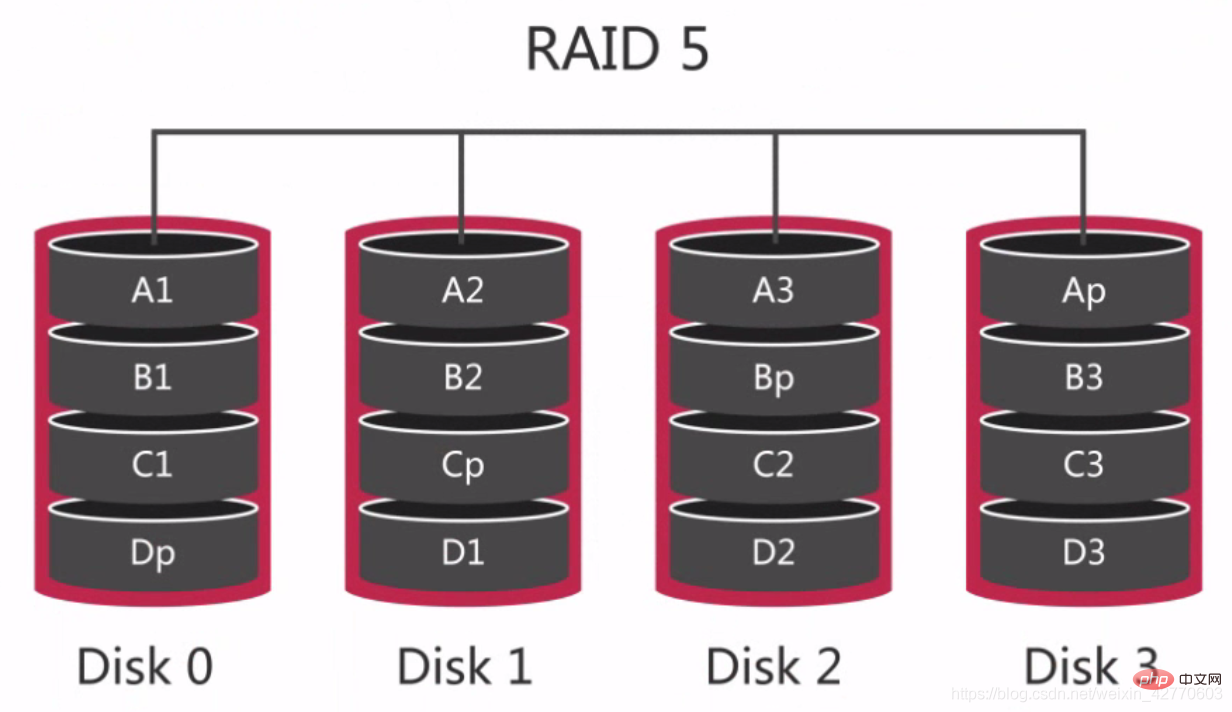 RAID 5 では、保存されたパリティ桁の値を計算するために各書き込みで 2 回の読み取りとディスク間での 2 回の書き込みが必要になるため、書き込みが遅くなります。ただし、ランダム読み取りとシーケンシャル読み取りはどちらも高速です。これは、パリティ ビットを計算する必要がないためです。したがって、RAID 5 は読み取り指向のデータベース サービスに適しています。
RAID 5 では、保存されたパリティ桁の値を計算するために各書き込みで 2 回の読み取りとディスク間での 2 回の書き込みが必要になるため、書き込みが遅くなります。ただし、ランダム読み取りとシーケンシャル読み取りはどちらも高速です。これは、パリティ ビットを計算する必要がないためです。したがって、RAID 5 は読み取り指向のデータベース サービスに適しています。
RAID 5 で発生する最大の問題は、ディスクに障害が発生した場合です。データを他のディスクに再割り当てする必要があり、ディスクのパフォーマンスに重大な影響を与えるため、次のような場合には RAID 5 を使用するのが最適です。再読。
2.2.2.2.4 RAID 10 - 一般的に使用される RAID グループ
RAID 10 では、1 台のハードディスクが破損すると、読み取りおよび書き込みプロセス中に 2 つの隣接するディスクが同時に読み取られる可能性があるため、パフォーマンスに重大な影響を及ぼします。が破損すると、単一のディスクからのみ読み取りが可能になるため、最悪の場合、パフォーマンスが 50% 低下します。
2.2.2.3 RAID レベルの選択
| レベル | 特徴 | 冗長化の有無 | 番号ディスク数 | #Read | Write |
|---|---|---|---|---|---|
| 安価、高速、危険 | No | N | fast | fast | |
| 高速読み取り、シンプルそして安全 | はい | 2 | 高速 | 低速 | |
| セキュリティとコストのトレードオフ | has | N 1 | fast | 最も遅いディスクに応じて | |
| 高価、高速、安全 | Have | 2N | fast | fast |
 SAN の特性:
SAN の特性: 
 注: このファイルへの変更を有効にするには、再起動する必要があります。
注: このファイルへの変更を有効にするには、再起動する必要があります。 




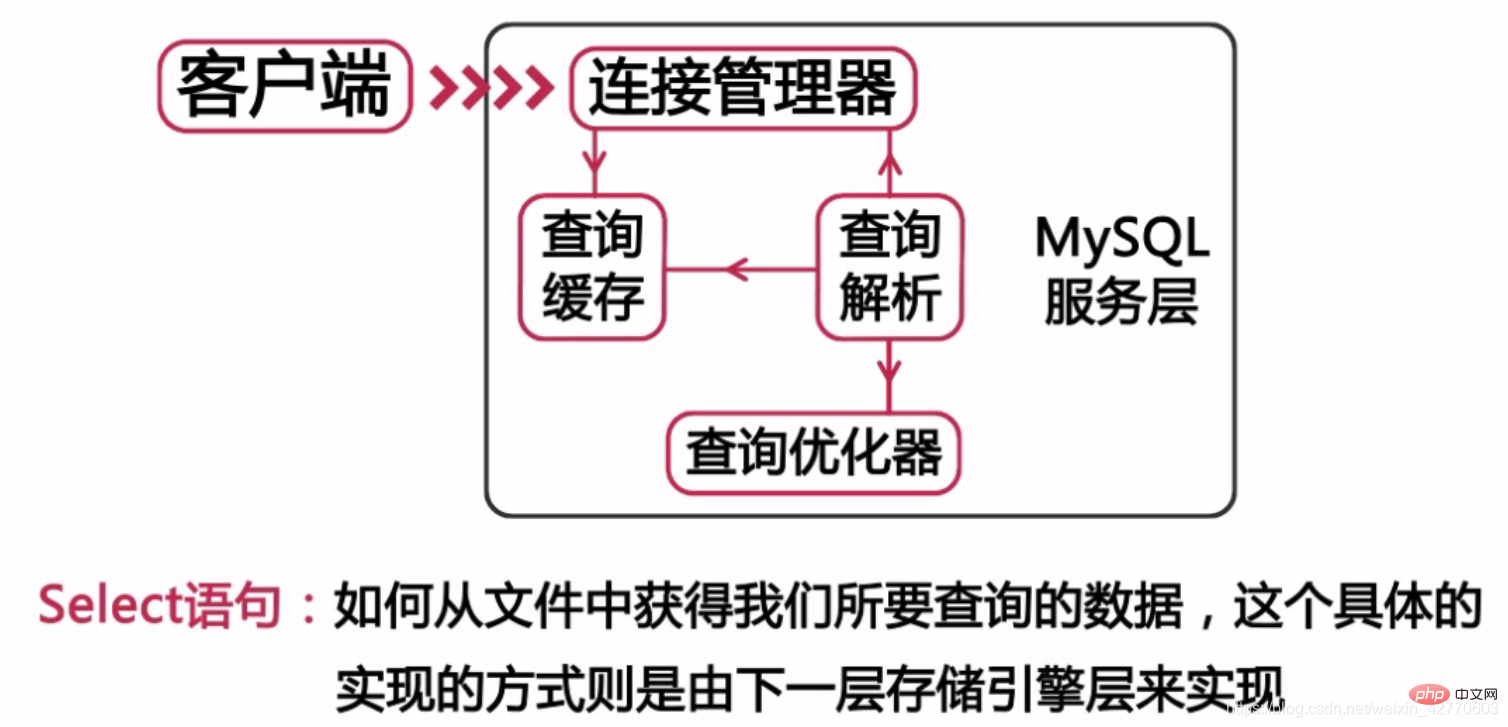 一般的に使用される DDL または DML ステートメントは、このレイヤーで定義されます。ただし、1 つだけ覚えておく必要があるのは、この層はサービス層とも呼ばれるため、すべてのクロスストレージ エンジン機能はこの層に実装されるということです。
一般的に使用される DDL または DML ステートメントは、このレイヤーで定義されます。ただし、1 つだけ覚えておく必要があるのは、この層はサービス層とも呼ばれるため、すべてのクロスストレージ エンジン機能はこの層に実装されるということです。 
以上がビッグデータ学習向けの高度な MYSQLの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7652
7652
 15
1393
52
91
11
37
110
15
1393
52
91
11
37
110

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
