

MySQL データベースとは何かを知ろう (3)

無料学習の推奨事項: mysql ビデオ チュートリアル
# #ディレクトリ
- ##ファジークエリ
- ##テーブルの制約
- ##テーブル間の関連付け
- # #多対 1 の関連付け
- #多対多の関連付け #1 対 1 の関連付け
- ファジークエリ
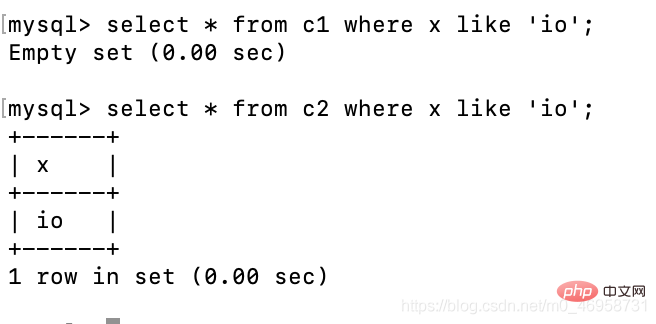
create table c1(x char(10));create table c2(x varchar(10));insert c1 values('io');insert c2 values('io');select * from c1 where x like 'io';select * from c2 where x like 'io';
ファジー クエリの方が正確です。この方法でクエリを実行するには、クエリを実行する前に、このフィールドの内容全体を入力する必要があります。データはここに char 型で格納されており、長さは 10 未満であるため、スペースがそれを補うために使用されるため、クエリを実行するときはスペースを含める必要があります。
 提供されたクエリ メソッドを使用することもできます。ファジークエリでは、% は 0 個以上の任意の文字を意味します。
提供されたクエリ メソッドを使用することもできます。ファジークエリでは、% は 0 個以上の任意の文字を意味します。
select * from c1 where x like 'io%';
 2 番目の数字が o であることだけがわかっていて、最初と最後がわからない場合は、_ を使用して任意の 1 文字を表し、% を使用して次のことを行うことができます。次の文字と一致します
2 番目の数字が o であることだけがわかっていて、最初と最後がわからない場合は、_ を使用して任意の 1 文字を表し、% を使用して次のことを行うことができます。次の文字と一致します
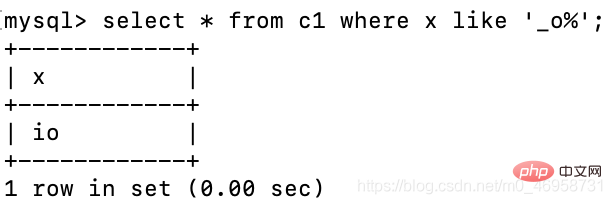
select * from c1 where x like '_o%';

SQL ファジー クエリの構文は "SELECT columns FROM table WHERE column LIKE ';pattern';" です。
 SQL には 4 つのマッチング モードが用意されています。
SQL には 4 つのマッチング モードが用意されています。
 % は 0 個以上の任意の bai 文字を表します。次のステートメント:
% は 0 個以上の任意の bai 文字を表します。次のステートメント:
SELECT * FROM user WHERE name LIKE ';%三%';
では、「Zhang San」、「Three-legged Cat」、「Tang Sanzang」などの名前が入力されます。
SELECT * FROM user WHERE name LIKE ';
三';制約とデータ型 幅は次のとおりです。同じであり、すべてオプションのパラメータです名前が 3 文字で中央の文字が「三」である「Tang Sanzang」のみを検索します;
- SELECT * FROM user WHERE name LIKE ';三__';
[ ] は次のいずれかを表します括弧内にリストされた文字 (正規表現と同様)。ステートメント:
名前が 3 文字で最初の文字が「三」である「三本足の猫」のみを検索します;
- SELECT * FROM user WHERE name LIKE ';[张李王]三';
[^ ] は、括弧内にリストされていない単一の文字を表します。ステートメント:
では、(「Zhang Li Wang San」ではなく) 「Zhang San」、「Li San」、「Wang San」が検索されます。 "); [ ] に一連の文字 (01234、abcde など) が含まれる場合、「0-4」、「a-e」と省略できます SELECT * FROM user WHERE name LIKE '; old [1 -9]';
は "Old 1"、"Old 2"、...、"Old 9" を検索します。
"-" 文字を検索したい場合は、それを最初に入力してください。 ';Zhang San [-1-9]';
- SELECT * FROM user WHERE name LIKE ';[^Zhang Liwang]三';
#テーブル制約
は、姓が「Zhang」、「Li」、「Wang」ではない「Zhao San」、「Sun」を検索します。 Three" など;
SELECT * FROM user WHERE name LIKE ';老[^1-4]';
「old 1」から「old 4」を除外して「old 5」、「old」を検索します6"、...、「古い 9」。
はじめに:
関数: データの整合性と一貫性を確保するために使用されます
- 主に次のように分かれています:
-
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录FOREIGN KEY (FK) 标识该字段为该表的外键NOT NULL 标识该字段不能为空UNIQUE KEY (UK) 标识该字段的值是唯一的AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)DEFAULT 为该字段设置默认值UNSIGNED 无符号 ZEROFILL 使用0填充
ログイン後にコピーnot null: リテラルの意味は、設定後、値が挿入されるたびにフィールドに値を設定する必要があるということです。
default: フィールドに値が設定されていない場合は、その値を使用します「デフォルト後のデフォルト値」で定義しました UNIQUE KEY: フィールドがこの制約を設定した後、設定される値は、テーブル全体でこのフィールドに対して 1 つの (一意の) 値のみを持つことができます
PRIMARY KEY : 主キーは、innodb ストレージ エンジンがデータを整理するための基礎です。Innodb では、これをインデックス構成テーブルと呼びます。テーブルには主キーが 1 つだけ存在する必要があります。
AUTO_INCREMENT: 設定後、このフィールドは値がテーブルに挿入されるたびに自動的に数値ずつ増加しますが、このフィールドは整数型である必要がありますが、主キーも必要です
FOREIGN KEY: このテーブルのフィールドを別のテーブルのフィールドに関連付ける外部キー
関連付けの後、このフィールドの値は次のとおりでなければなりません関連するフィールドの値に対応します。我们创建表,通常会有一个id字段作为索引标识作用,并且会将它设置为主键和自增。
实例:
create table test(
id int primary key auto_increment,
identity varchar(18) not null unique key, --身份证必须唯一
gender varchar(18) default '男');insert test(identity) values('123456789012345678');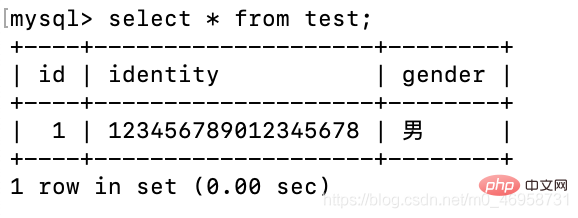
当身份字段插入相同值,则会报错,因为字段设置了唯一值
insert test(identity,gender) values('0123456789012345678','女');
我们会发现,id不对劲啊,那是因为笔者之前进行两次插入值操作,但是值并没有成功插入进去,但是这个自增却受到了影响.
这个时候,我们进行两部操作就可以解决这个问题。
alter table test drop id;alter table test add id int primary key auto_increment first;
删除id字段,再重新设置。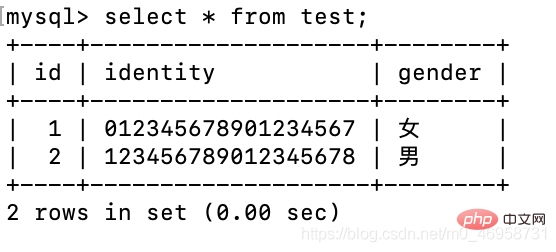
很神奇是不是,这个MySQL的底层机制。vary 良心
还需要注意的是:我们使用delete删除一条记录时,并不会影响自增
delete from test where id = 2;insert test(identity,gender) values('111111111111111111','男');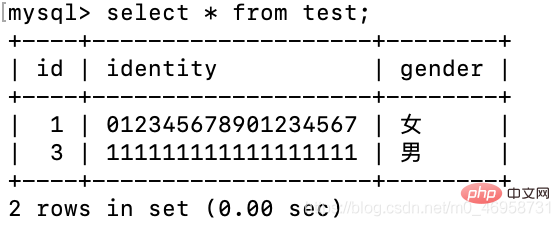
关于这个操作,如果我们只是删除单条记录的话,可以使用上序提供的方法还调整自增的值,而如果是删除整个表记录的话,使用以下方法:
truncate test;
效果演示:delete删除整个表记录
效果演示:truncate删除整个表记录
联合主键
确保设置为主键的某几个字段的数据相同
主键的一个目的就是确定数据的唯一性,它跟唯一约束的区别就是,唯一约束可以有一个NULL值,但是主键不能有NULL值,再说联合主键,联合主键就是说,当一个字段可能存在重复值,无法确定这条数据的唯一性时,再加上一个字,两个字段联合起来确定这条数据的唯一性。比如你提到的id和name为联合主键,在插入数据时,当id相同,name不同,或者id不同,name相同时数据是允许被插入的,但是当id和name都相同时,数据是不允许被插入的。
实例:
create table test( id int, name varchar(10), primary key(id,name)); insert test values(1,1);

如果再次插入两个主键相同的数据,则会报错
只要设置主键的两个字段,在一条记录内,数据不完全相同就没有问题。
外键的话,我们在表之间的关联进行演示
表之间的关联
我们这里先介绍表之间的关联,后面再学习联表查询
通过某一个字段,或者通过某一张表,将多个表关联起来。
我们一张表处理好不行吗,为什么要关联,像这样?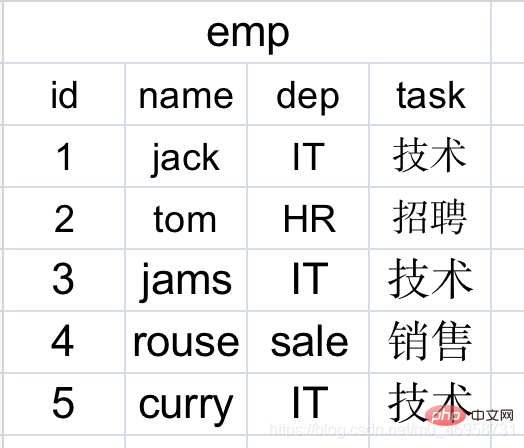
有没有发现一个问题,有些员工它们对应的是相同部门,一张表就重复了很多次记录,随着员工数量的增加,就会出现越来越多个重复记录,相对更占用空间了。
那么我们需要将部门单独使用一张表,再将员工这个使用一个字段关联到另一个表内,我们可以使用外键,也可以不使用外键,先来演示外键的好处吧
多对一关联
如:多个员工对应一个部门。
员工表,先别急着创建,请向下看
create table emp( id int primary key auto_increment, name varchar(10) not null, dep_id int, foreign key(dep_id) references dep(id) on update cascade # 级联更新 on delete cascade); # 级联删除
上面外键的作用就是:
dep_id字段关联了dep表的id字段:
当dep表的id字段值修改后,该表的dep_id字段下面如果有和dep表id相同值的则会一起更改。
如果dep表删除了某一条记录,当emp表的dep_id与dep表删除记录的id值对上以后,emp表这条记录也会被随之删除。
注意:必须是外键已存在,所以需要先创建部门表,再创建员工表
部门表
create table dep( id int primary key auto_increment, name varchar(16) not null unique key, task varchar(16) not null);
emp表的dep_id字段设置的数据必须是dep表已存在的id
所以我们需要先向dep表插入记录
insert dep(name,task) values('IT','技术'),('HR','招聘'),('sale','销售');员工表插入记录
insert emp(name,dep_id) values
('jack',1),
('tom',2),
('jams',1),
('rouse',3),
('curry',2);
# ('go',4) 报错,在关联外键的id字段中找不到注意:如果我们emp表的dep_id字段插入的数据,在dep表中的id字段不存在该数据时,就会报错。
查询我们创建后的效果
这样就把这两个表关联起来了,目前我们先不了解多表查询,这个先了解的是,表之间的关联。
我们再来看一下同步更新以及删除,外键的改动被关联表会受到影响
update dep set id=33333 where id = 3;
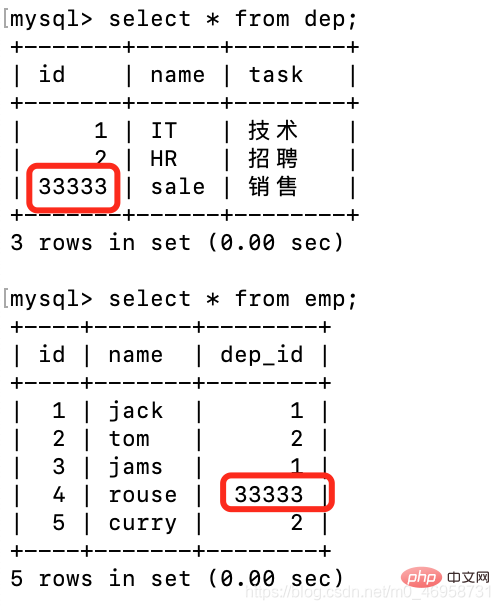
再来体验一下同步删除
delete from dep where id = 33333;

这就是外键带给我们的效果,有利也有弊:
- 优点:关联性强,只能设置已存在的内容,并且同步更新与删除
- 缺点:当删除外键表的某一条记录,关联表中有关联性的记录会被全部删除
多对多关联
多张表互相关联
如:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
这时使用外键会出现一个弊端,那就是先创建哪张表呢?它们都互相对应,是不是很矛盾呢?解决办法:第三张表,关联书的id与作者的id
book表
create table book( id int primary key auto_increment, name varchar(30));
author表
create table author( id int primary key auto_increment, name varchar(30));
中间表:负责将两张表进行关联
create table authorRbook( id int primary key auto_increment, author_id int, book_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, foreign key(author_id) references author(id) on update cascade on delete cascade);
多名作者关联一本书,或者一名作者关联多本书,书也要体现出谁关联了它
book表插入数据:
insert book(name) values
('斗破苍穹'),
('斗罗大陆'),
('武动乾坤');author表插入数据:
insert author(name) values
('jack'),
('tom'),
('jams'),
('rouse'),
('curry'),
('john');关联表插入数据:
insert authorRbook(author_id,book_id) values (1,1), (1,2), (1,3), (2,1), (2,3), (3,2), (4,1), (5,1), (5,3), (6,2);
目前的对应关系就是:
jack:斗破苍穹、斗罗大陆、武动乾坤
tom:斗破苍穹、武动乾坤
jams:斗罗大陆
rouse:斗破苍穹
curry:斗破苍穹、武动乾坤
jhon:斗罗大陆
一个作者可以产于多本书的编写,同时,每本书都会标明产于的作者
一对一关联
路人有可能变成某个学校的学生,即一对一关系。
在这之前,路人不属于学校。
原理就是:学校通过广告,或者通过电话邀请,将路人变成了学生。
路人表
create table passers_by(
id int primary key auto_increment,
name varchar(10),
age int);
insert passers_by(name,age) values
('jack',18),
('tom',19),
('jams',23);学校表
create table school(
id int primary key auto_increment,
class varchar(10),
student_id int unique key,
foreign key(student_id) references passers_by(id)
on update cascade
on delete cascade);insert school(class,student_id) values
('Mysql入门到放弃',1),
('Python入门到运维',3),
('Java从入门到音乐',2);数据存储的设计,需要提前设计好表的关联 关系,将关系全部设计好以后,剩下的只是往里存数据了,后续我们会了解到联表查询相关内容,将有关联性的内容,以虚拟表的形式查询出来,查询出来的数据可能来自多个表。
表的关联,建议使用以下方式
- 多对多 > 多对一 > 一对一
相关免费学习推荐:mysql数据库(视频)
以上がMySQL データベースとは何かを知ろう (3)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7663
7663
 15
1393
52
1205
24
91
11
15
1393
52
1205
24
91
11

 PHP 開発の実践: PHPMailer を使用して MySQL データベース内のユーザーに電子メールを送信する
Aug 05, 2023 pm 06:21 PM
PHP 開発の実践: PHPMailer を使用して MySQL データベース内のユーザーに電子メールを送信する
Aug 05, 2023 pm 06:21 PM
PHP 開発の実践: PHPMailer を使用して MySQL データベース内のユーザーに電子メールを送信する はじめに: 現代のインターネットの構築において、電子メールは重要なコミュニケーション ツールです。 ECにおけるユーザー登録やパスワードのリセット、注文確認など、メール送信は欠かせない機能です。この記事では、PHPMailer を使用してメールを送信し、メール情報を MySQL データベースのユーザー情報テーブルに保存する方法を紹介します。 1. PHPMailer ライブラリをインストールする PHPMailer は
 Go 言語と MySQL データベース: ホット データとコールド データを分離するには?
Jun 18, 2023 am 08:26 AM
Go 言語と MySQL データベース: ホット データとコールド データを分離するには?
Jun 18, 2023 am 08:26 AM
データ量が増加し続けるにつれて、データベースのパフォーマンスがますます重要な問題になっています。ホット データとコールド データの分離処理は、ホット データとコールド データを分離できる効果的なソリューションであり、それによってシステムのパフォーマンスと効率が向上します。この記事では、Go 言語と MySQL データベースを使用してホット データとコールド データを分離する方法を紹介します。 1. ホットデータとコールドデータの分離処理とは ホットデータとコールドデータの分離処理とは、ホットデータとコールドデータを分類する方法です。ホット データとは、アクセス頻度が高く、パフォーマンス要件が高いデータを指します。
 MySQL データベースのスキルをどの程度まで開発すれば、うまく活用できるでしょうか?
Sep 12, 2023 pm 06:42 PM
MySQL データベースのスキルをどの程度まで開発すれば、うまく活用できるでしょうか?
Sep 12, 2023 pm 06:42 PM
MySQL データベースのスキルをどの程度まで開発すれば、うまく活用できるでしょうか?情報化時代の急速な発展に伴い、データベース管理システムはあらゆる分野で不可欠かつ重要なコンポーネントになりました。一般的に使用されるリレーショナル データベース管理システムとして、MySQL には幅広い応用分野と雇用機会があります。では、MySQL データベースのスキルを適切に活用するには、どの程度まで開発する必要があるのでしょうか?まず、MySQL の基本原理と基礎知識を習得することが最も基本的な要件です。 MySQL はオープンソースのリレーショナル データベース管理です
 Go 言語を使用して MySQL データベースの増分データ バックアップを実行する方法
Jun 17, 2023 pm 02:28 PM
Go 言語を使用して MySQL データベースの増分データ バックアップを実行する方法
Jun 17, 2023 pm 02:28 PM
データ量が増加するにつれて、データベースのバックアップの重要性がますます高まります。 MySQL データベースの場合、Go 言語を使用して自動増分バックアップを実現できます。この記事では、Go 言語を使用して MySQL データベース データの増分バックアップを実行する方法を簡単に紹介します。 1. Go 言語環境をインストールする まず、Go 言語環境をローカルにインストールする必要があります。公式 Web サイトにアクセスして、対応するインストール パッケージをダウンロードしてインストールできます。 2. 対応するライブラリをインストールする Go 言語には、MySQL データベースにアクセスするための多くのサードパーティ ライブラリが用意されています。
 MySQL データベースを時系列分析に使用するにはどうすればよいですか?
Jul 12, 2023 am 08:39 AM
MySQL データベースを時系列分析に使用するにはどうすればよいですか?
Jul 12, 2023 am 08:39 AM
MySQL データベースを時系列分析に使用するにはどうすればよいですか?時系列データとは、時間的な連続性と相関性を持つ、時系列に並べられたデータの集合のことです。時系列分析は、将来の傾向の予測、周期的な変化の発見、外れ値の検出などに使用できる重要なデータ分析手法です。この記事では、MySQL データベースを使用して時系列分析を行う方法とコード例を紹介します。データ テーブルを作成する まず、時系列データを保存するデータ テーブルを作成する必要があります。数値を分析したいとします。
 画像処理に MySQL データベースを使用するにはどうすればよいですか?
Jul 14, 2023 pm 12:21 PM
画像処理に MySQL データベースを使用するにはどうすればよいですか?
Jul 14, 2023 pm 12:21 PM
画像処理に MySQL データベースを使用するにはどうすればよいですか? MySQL は強力なリレーショナル データベース管理システムであり、データの保存と管理に加えて、画像処理にも使用できます。この記事では、画像処理に MySQL データベースを使用する方法を紹介し、いくつかのコード例を示します。始める前に、MySQL データベースがインストールされており、基本的な SQL ステートメントに精通していることを確認してください。データベーステーブルの作成 まず、画像データを保存するための新しいデータベーステーブルを作成します。テーブルの構造は次のようになります。
 Go 言語を使用して信頼性の高い MySQL データベース接続を確立するにはどうすればよいですか?
Jun 17, 2023 pm 07:18 PM
Go 言語を使用して信頼性の高い MySQL データベース接続を確立するにはどうすればよいですか?
Jun 17, 2023 pm 07:18 PM
大量のデータの保存と処理が必要なため、MySQL はアプリケーション開発で最も一般的に使用されるリレーショナル データベースの 1 つになりました。 Go 言語は、効率的な同時実行処理と簡潔な構文により、開発者の間でますます人気が高まっています。この記事は、読者が Go 言語を介して信頼性の高い MySQL データベース接続を実装し、開発者がデータをより効率的にクエリおよび保存できるようにする方法を示します。 1. Go 言語で MySQL データベースに接続するためのいくつかの方法 Go 言語で MySQL データベースに接続するには、通常、次の 3 つの方法があります: 1. サードパーティ ライブラリ
 MySQL データベースと Go 言語: データ キャッシュを実行するにはどうすればよいですか?
Jun 17, 2023 am 10:05 AM
MySQL データベースと Go 言語: データ キャッシュを実行するにはどうすればよいですか?
Jun 17, 2023 am 10:05 AM
近年、Go 言語は開発者の間でますます人気が高まっており、高パフォーマンスの Web アプリケーションを開発するために推奨される言語の 1 つとなっています。 MySQL も広く使用されている人気のあるデータベースです。これら 2 つのテクノロジーを組み合わせるプロセスにおいて、キャッシュは非常に重要な部分です。 Go言語を使ってMySQLデータベースのキャッシュを扱う方法を紹介します。キャッシュの概念 Web アプリケーションにおいて、キャッシュはデータ アクセスを高速化するために作成された中間層です。主に、頻繁に要求されるデータを保存するために使用されます。
