

Redisのデータ構造とデータ操作の詳細な分析


推奨 (無料): redis
Redis がデータ操作を完了する速度は、マイクロ秒レベルに達することがあります。 Redis がこのような卓越したパフォーマンスを実現できる主な理由は 2 つあります:
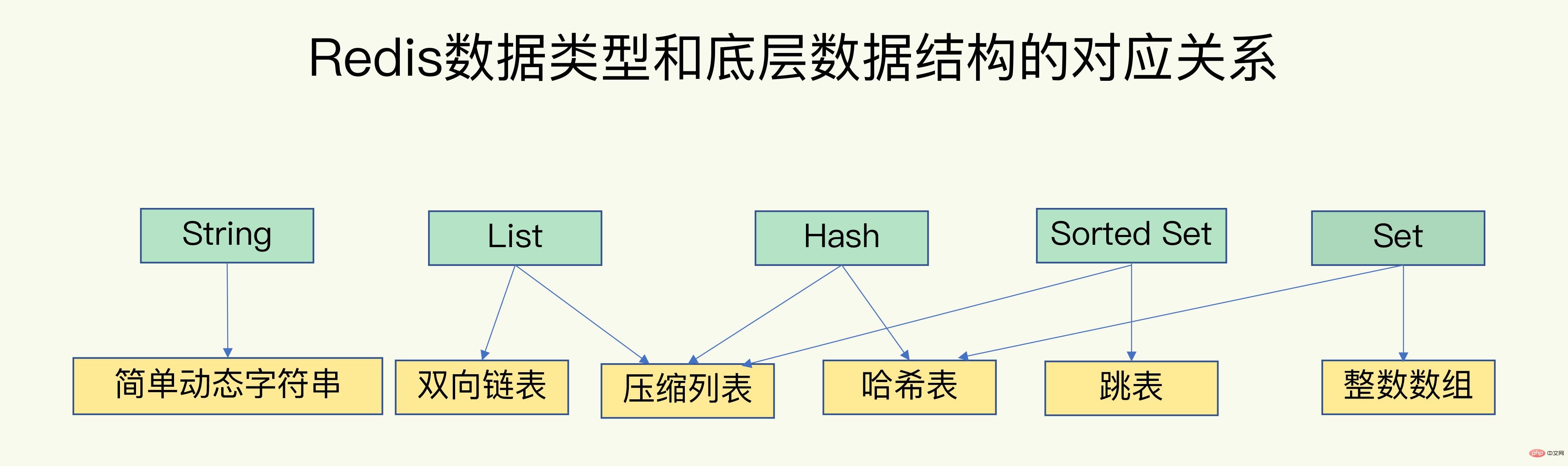
- Redis はインメモリ データベースであり、すべての操作がメモリ内で完了し、メモリ アクセス速度自体が非常に高速です。 ##Redis 効率的なデータ型とデータ構造を持っています。
 キーから値への高速アクセスを実現するために、Redis はハッシュ テーブルを使用してキーと値のペアを保存します。ハッシュ バケット内のエントリは、実際のキーと値へのポインターを保存します。値が であっても、値ポインタを通じてコレクションを見つけることもできます。
キーから値への高速アクセスを実現するために、Redis はハッシュ テーブルを使用してキーと値のペアを保存します。ハッシュ バケット内のエントリは、実際のキーと値へのポインターを保存します。値が であっても、値ポインタを通じてコレクションを見つけることもできます。
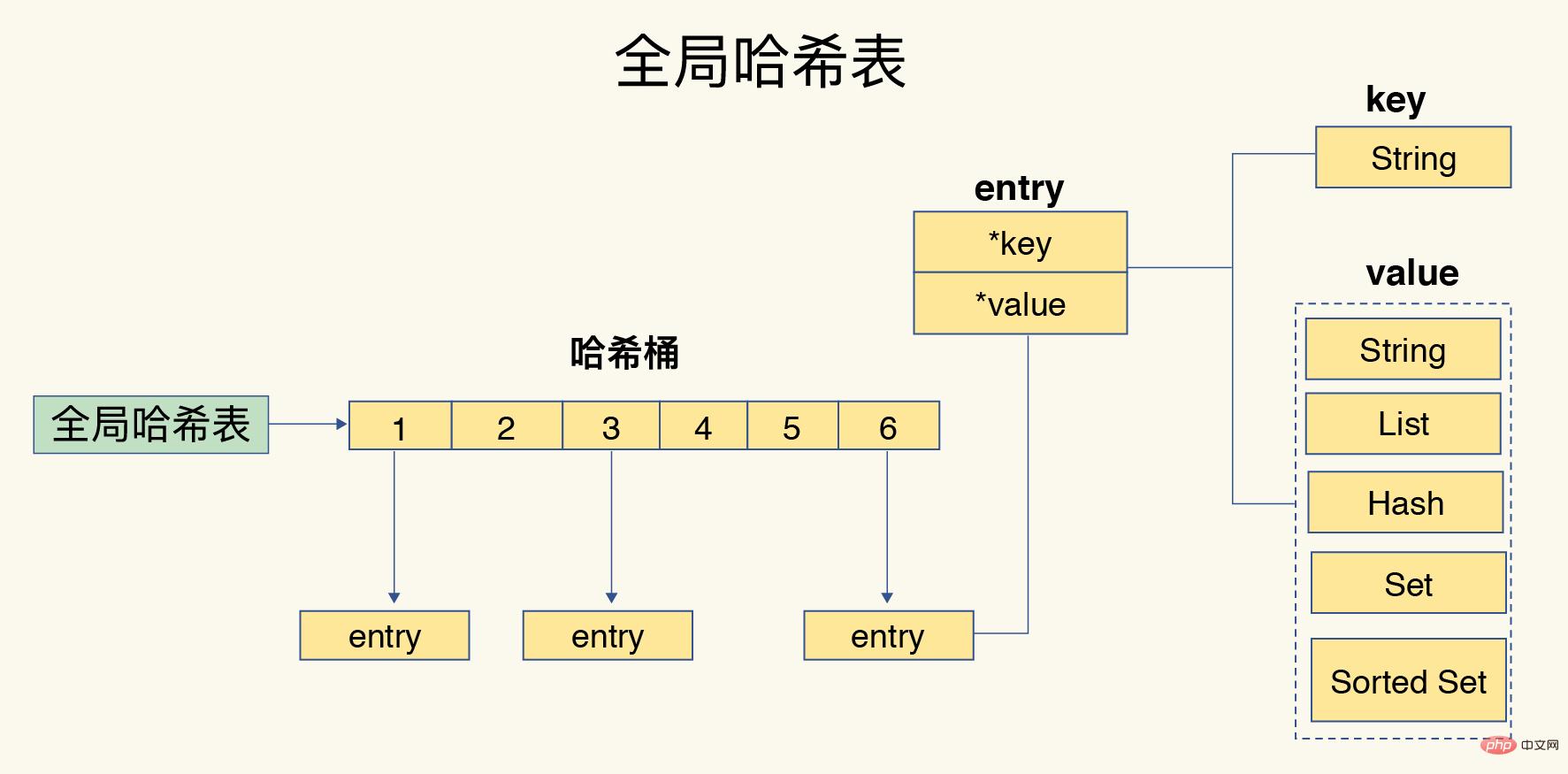 ハッシュ テーブル内のデータが増えると、ハッシュの競合が発生します。つまり、複数のキーのハッシュ値が同じハッシュ バケットに対応する可能性があります。 Redis は、連鎖ハッシュを使用してハッシュの競合を解決します。つまり、同じハッシュ バケット内の複数の要素がリンクされたリストに格納され、要素がポインターによって順番にリンクされます。
ハッシュ テーブル内のデータが増えると、ハッシュの競合が発生します。つまり、複数のキーのハッシュ値が同じハッシュ バケットに対応する可能性があります。 Redis は、連鎖ハッシュを使用してハッシュの競合を解決します。つまり、同じハッシュ バケット内の複数の要素がリンクされたリストに格納され、要素がポインターによって順番にリンクされます。
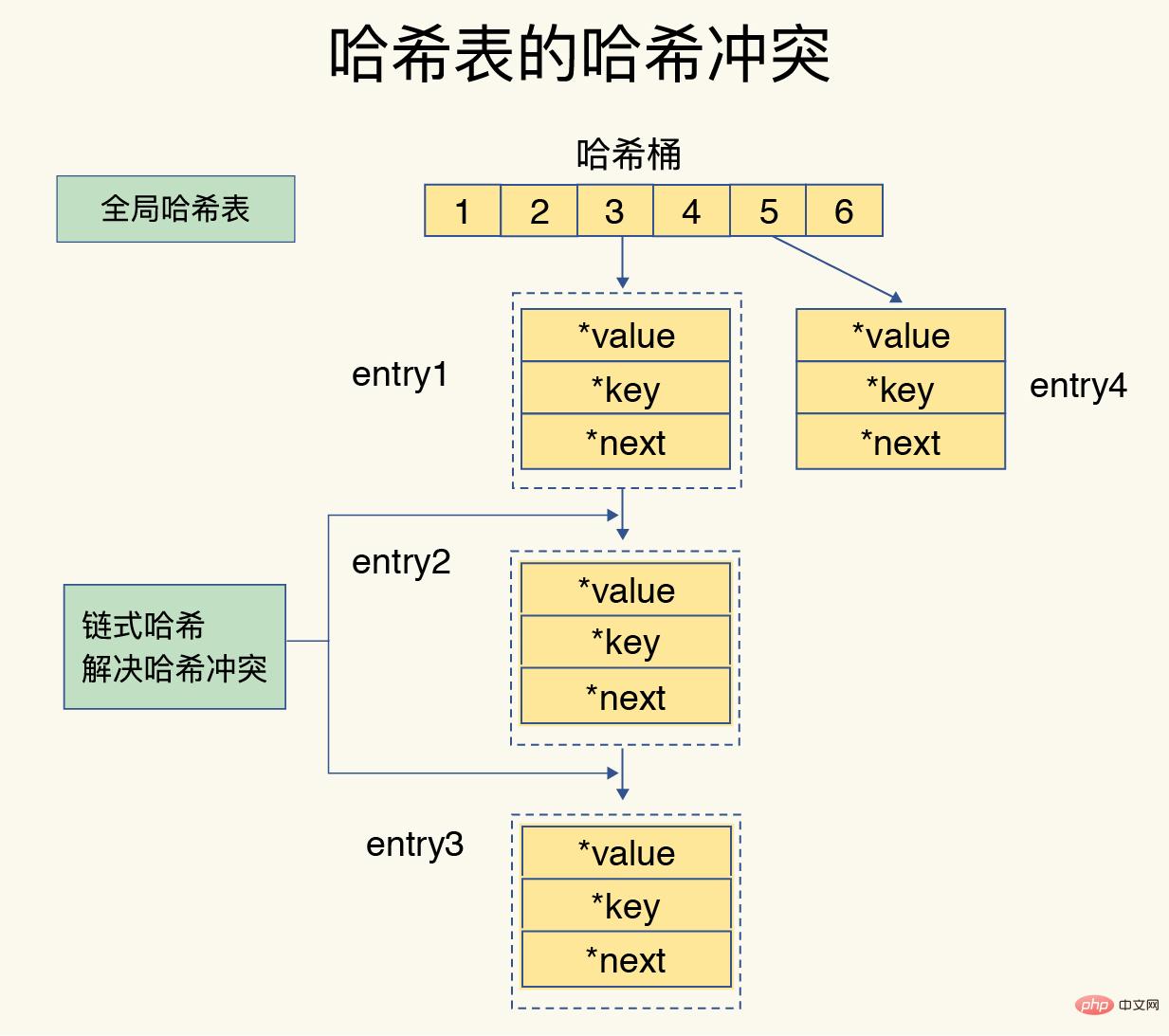 ハッシュの競合が増えると、ハッシュの競合チェーンが長くなり、要素の検索に時間がかかり、効率が低下します。この問題を解決するために、Redis はハッシュ テーブルに対して再ハッシュ操作を実行して複数のエントリ要素を分散して格納し、単一のハッシュ バケット内の要素の数を減らし、それによって単一のバケット内の競合を減らします。
ハッシュの競合が増えると、ハッシュの競合チェーンが長くなり、要素の検索に時間がかかり、効率が低下します。この問題を解決するために、Redis はハッシュ テーブルに対して再ハッシュ操作を実行して複数のエントリ要素を分散して格納し、単一のハッシュ バケット内の要素の数を減らし、それによって単一のバケット内の競合を減らします。
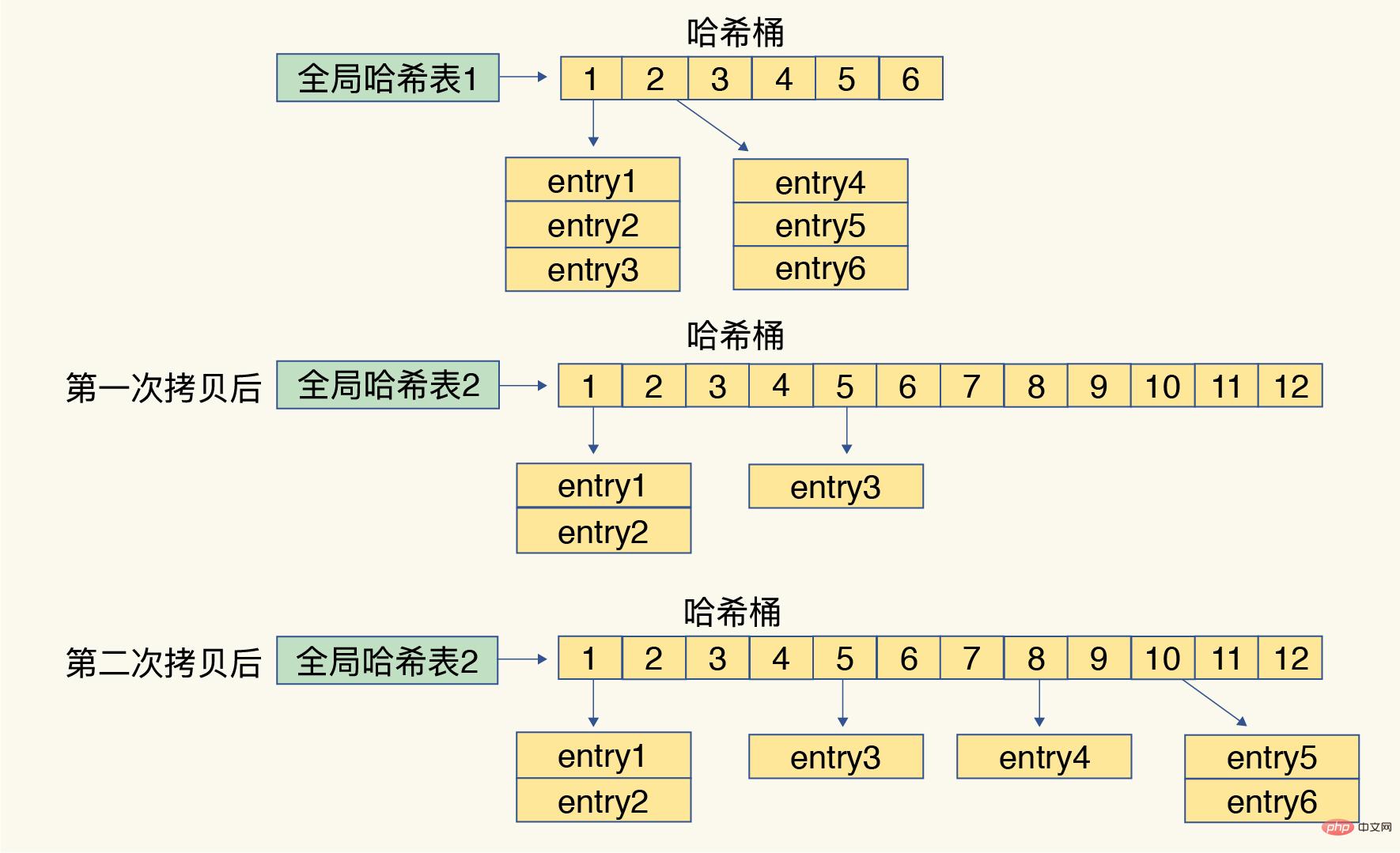
Redis は、効率的な再ハッシュのために、デフォルトで 2 つのグローバル ハッシュ テーブルを使用します。最初はハッシュ テーブル 1 がデフォルトで使用され、ハッシュ テーブル 2 はスペースを割り当てません。データが増加し続けると、redis は、次の手順:
ハッシュ テーブル 2 にさらにスペースを割り当てます。- ハッシュ テーブル 1 のデータをハッシュ テーブル 2 にコピーします。
- ハッシュ テーブル 1 を解放します。スペースは予約されています。次の再ハッシュ拡張のために
- ただし、手順 2 で一度に大量のデータがコピーされると、Redis スレッドがブロックされ、他のリクエストを処理できなくなる可能性があるため、Redis はリハッシュとは、リクエストが処理されるたびに、このインデックス位置にあるすべてのエントリがコピーされることを意味します。
 文字列型の値の場合は、ハッシュ バケットを見つけた後、直接 CRUD 操作を実行できます。セットの場合は、グローバル ハッシュ テーブルから対応するハッシュ バケットを見つけた後、セット内で CRUD を実行します。コレクションの操作効率は、基礎となるデータ構造と操作の複雑さに関係します。
文字列型の値の場合は、ハッシュ バケットを見つけた後、直接 CRUD 操作を実行できます。セットの場合は、グローバル ハッシュ テーブルから対応するハッシュ バケットを見つけた後、セット内で CRUD を実行します。コレクションの操作効率は、基礎となるデータ構造と操作の複雑さに関係します。
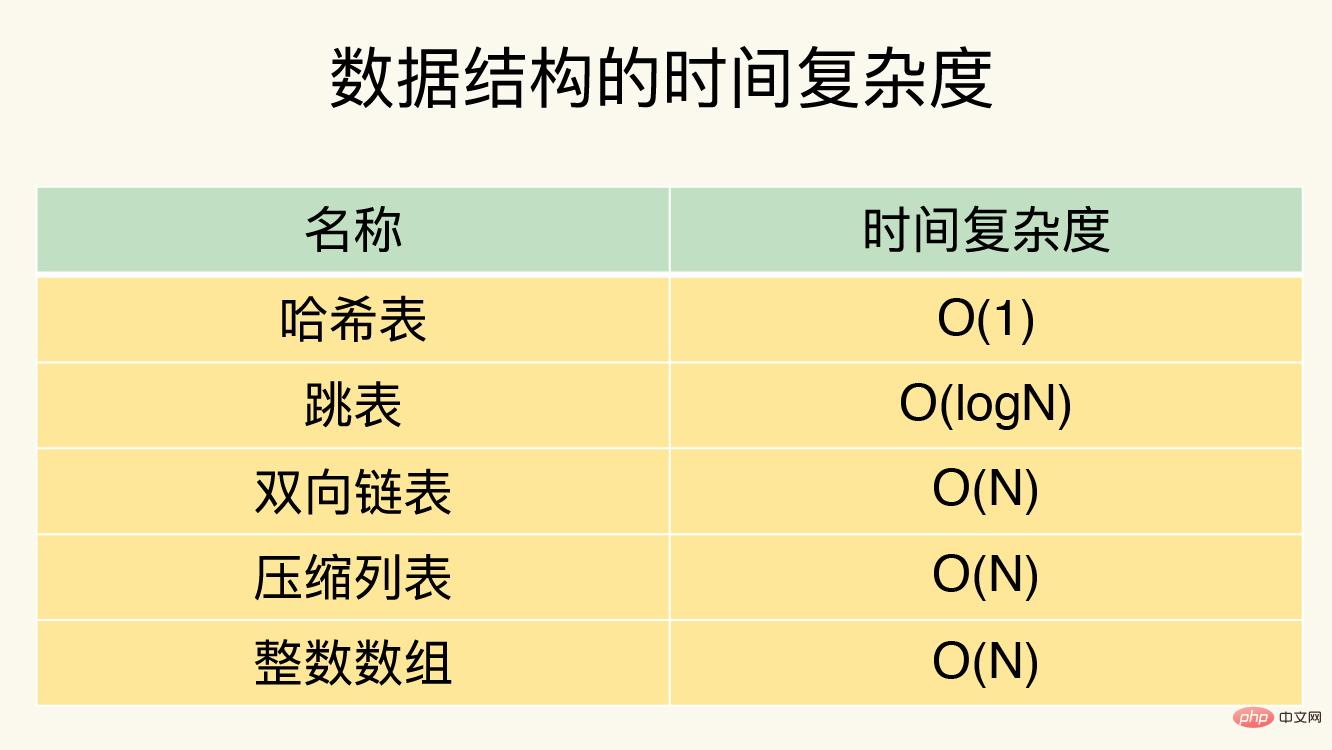 #単一要素の演算が基本であり、演算の複雑さは O(1);
#単一要素の演算が基本であり、演算の複雑さは O(1);
- ハッシュ: HGET、HSET、HDEL;
-
- タイプ SADD、SREM、SRANDMEMBER などを設定します。
- 範囲操作は非常に時間がかかり、操作の複雑さは O(N) です。
ハッシュ:HGETALL; - セット:SMEMBERS;
- リスト:LRANGE
- Zセット:ZRANGE
- 通常、統計演算は効率的であり、演算の複雑さは O(1) です。
例外はわずかで、演算の複雑さは O(1) です。 - リスト: LPOP、RPOP、LPUSH、RPUSH
以上がRedisのデータ構造とデータ操作の詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
1. [スタート]メニューを起動し、[cmd]と入力し、[コマンドプロンプト]を右クリックし、[管理者として実行]を選択します。 2. 次のコマンドを順番に入力します (注意してコピーして貼り付けてください): SCconfigwuauservstart=auto、Enter キーを押す SCconfigbitsstart=auto、Enter キーを押す SCconfigcryptsvcstart=auto、Enter キーを押す SCconfigtrustedinstallerstart=auto、Enter キーを押す SCconfigwuauservtype=share、Enter キーを押す netstopwuauserv 、enter netstopcryptS を押す
 PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発では、キャッシュ メカニズムにより、頻繁にアクセスされるデータがメモリまたはディスクに一時的に保存され、データベース アクセスの数が削減され、パフォーマンスが向上します。キャッシュの種類には主にメモリ、ファイル、データベース キャッシュが含まれます。キャッシュは、組み込み関数またはサードパーティのライブラリ (cache_get() や Memcache など) を使用して PHP に実装できます。一般的な実用的なアプリケーションには、データベース クエリ結果をキャッシュしてクエリ パフォーマンスを最適化したり、ページ出力をキャッシュしてレンダリングを高速化したりすることが含まれます。キャッシュ メカニズムにより、Web サイトの応答速度が効果的に向上し、ユーザー エクスペリエンスが向上し、サーバーの負荷が軽減されます。
 Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
まず、システム言語を簡体字中国語表示に設定して再起動する必要があります。もちろん、以前に表示言語を簡体字中国語に変更したことがある場合は、この手順をスキップできます。次に、レジストリ regedit.exe の操作を開始し、左側のナビゲーション バーまたは上部のアドレス バーで HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage に直接移動し、InstallLanguage キーの値と Default キーの値を 0804 に変更します (英語に変更する場合)。まずシステムの表示言語を en-us に設定し、システムを再起動してから、すべてを 0409 に変更します) この時点でシステムを再起動する必要があります。
 Javaのデータ構造とアルゴリズム: 詳細な説明
May 08, 2024 pm 10:12 PM
Javaのデータ構造とアルゴリズム: 詳細な説明
May 08, 2024 pm 10:12 PM
データ構造とアルゴリズムは Java 開発の基礎です。この記事では、Java の主要なデータ構造 (配列、リンク リスト、ツリーなど) とアルゴリズム (並べ替え、検索、グラフ アルゴリズムなど) について詳しく説明します。これらの構造は、スコアを保存するための配列、買い物リストを管理するためのリンク リスト、再帰を実装するためのスタック、スレッドを同期するためのキュー、高速検索と認証のためのツリーとハッシュ テーブルの使用など、実際の例を通じて説明されています。これらの概念を理解すると、効率的で保守しやすい Java コードを作成できるようになります。
 PHP データ構造: AVL ツリーのバランス、効率的で秩序あるデータ構造の維持
Jun 03, 2024 am 09:58 AM
PHP データ構造: AVL ツリーのバランス、効率的で秩序あるデータ構造の維持
Jun 03, 2024 am 09:58 AM
AVL ツリーは、高速かつ効率的なデータ操作を保証するバランスのとれた二分探索ツリーです。バランスを達成するために、左回転と右回転の操作を実行し、バランスに反するサブツリーを調整します。 AVL ツリーは高さバランシングを利用して、ツリーの高さがノード数に対して常に小さくなるようにすることで、対数時間計算量 (O(logn)) の検索操作を実現し、大規模なデータ セットでもデータ構造の効率を維持します。
 Win11でダウンロードしたアップデートファイルの探し方_Win11でダウンロードしたアップデートファイルの場所を共有する
May 08, 2024 am 10:34 AM
Win11でダウンロードしたアップデートファイルの探し方_Win11でダウンロードしたアップデートファイルの場所を共有する
May 08, 2024 am 10:34 AM
1. まず、デスクトップ上の[このPC]アイコンをダブルクリックして開きます。 2. 次に、マウスの左ボタンをダブルクリックして [C ドライブ] に入ります。システム ファイルは通常、自動的に C ドライブに保存されます。 3. 次に、C ドライブで [windows] フォルダーを見つけ、ダブルクリックしてに入ります。 4. [windows]フォルダーに入ったら、[SoftwareDistribution]フォルダーを見つけます。 5. 入力後、win11 のダウンロード ファイルとアップデート ファイルがすべて含まれている [ダウンロード] フォルダーを見つけます。 6. これらのファイルを削除したい場合は、このフォルダー内で直接削除してください。
 Docker環境にPECLを使用して拡張機能をインストールするときにエラーが発生するのはなぜですか?それを解決する方法は?
Apr 01, 2025 pm 03:06 PM
Docker環境にPECLを使用して拡張機能をインストールするときにエラーが発生するのはなぜですか?それを解決する方法は?
Apr 01, 2025 pm 03:06 PM
エラーの原因とソリューションPECLを使用してDocker環境に拡張機能をインストールする場合、Docker環境を使用するときに、いくつかの頭痛に遭遇します...
 Apple M1チップMACでのRedisのコンパイルとインストールは失敗しました。 PHP7.3コンピレーションエラーのトラブルシューティング方法は?
Mar 31, 2025 pm 11:39 PM
Apple M1チップMACでのRedisのコンパイルとインストールは失敗しました。 PHP7.3コンピレーションエラーのトラブルシューティング方法は?
Mar 31, 2025 pm 11:39 PM
Apple M1 Chip MacにRedisをコンパイルおよびインストールする際に遭遇する問題とソリューション、多くのユーザーは...
