

#1 レプリケーションの概要無料学習の推奨事項: mysql ビデオ チュートリアル
Mysql の組み込みレプリケーション機能は、大規模で高性能なアプリケーションを構築するための基盤です。 MySQL データを複数のシステムに分散する この分散メカニズムは、特定の MySQL ホストのデータを他のホスト (スレーブ) にコピーし、再度実行することで実現されます。レプリケーション中、1 つのサーバーがマスター サーバーとして機能し、1 つ以上の他のサーバーがスレーブ サーバーとして機能します。マスターサーバーはバイナリログファイルに更新を書き込み、ログローテーションを追跡するためにファイルのインデックスを維持します。これらのログは、スレーブ サーバーに送信された更新を記録します。スレーブはマスターに接続すると、スレーブがログから読み取った最後に成功した更新の場所をマスターに通知します。スレーブはそれ以降に発生した更新を受信し、ブロックしてマスターに新しい更新が通知されるのを待ちます。
レプリケートする場合、レプリケートされるテーブルに対するすべての更新はプライマリ サーバーで実行する必要があることに注意してください。それ以外の場合は、マスター サーバー上のテーブルに対するユーザー更新とスレーブ サーバー上のテーブルに対する更新の間の競合を避けるように注意する必要があります。
1.1 mysql でサポートされるレプリケーション タイプ:(1): ステートメントベースのレプリケーション: マスター サーバーで実行された SQL ステートメントはスレーブ サーバーで実行されます。 MySQL はデフォルトでステートメントベースのレプリケーションを使用します。これは比較的効率的です。
正確なコピーが実行できないことが判明すると、行ベースのコピーが自動的に選択されます。 (2): ロウベースレプリケーション: スレーブサーバー上でコマンドを実行する代わりに変更内容をコピー mysql5.0 からサポート
(3): 混合型レプリケーション: デフォルトで使用 ステートメントベースレプリケーション、ステートメントベースのレプリケーションが正確ではないことが判明すると、行ベースのレプリケーションが使用されます。
MySQL レプリケーション技術には次の特徴があります:
(1) データ分散 (2) 負荷分散
全体として、レプリケーションには 3 つの手順があります:
(1) マスターは変更をバイナリ ログに記録します (これらのレコードはバイナリ ログ イベントと呼ばれます);
(3) スレーブはリレー ログ内のイベントを再実行し、変更は自身のデータを反映します。
次の図はコピー プロセスを示しています: プロセスの最初の部分は、マスターがバイナリ ログを記録することです。各トランザクションがデータの更新を完了する前に、マスターはこれらの変更をセカンダリ ログに記録します。 MySQL は、トランザクション内のステートメントがインターリーブされている場合でも、トランザクションをバイナリ ログにシリアルに書き込みます。イベントがバイナリ ログに書き込まれた後、マスターはストレージ エンジンにトランザクションをコミットするように通知します。
次のステップは、スレーブがマスターのバイナリ ログを自身のリレー ログにコピーすることです。まず、スレーブはワーカー スレッド、つまり I/O スレッドを開始します。 I/O スレッドはマスター上で通常の接続を開き、バイナリ ログ ダンプ プロセスを開始します。バイナリ ダンプ プロセスは、マスターのバイナリ ログからイベントを読み取り、マスターに追いついた場合はスリープして、マスターが新しいイベントを生成するのを待ちます。 I/O スレッドは、これらのイベントをリレー ログに書き込みます。
SQL スレーブ スレッド (SQL スレーブ スレッド) は、プロセスの最後のステップを処理します。 SQL スレッドはリレー ログからイベントを読み取り、イベントを再生してスレーブのデータを更新し、マスター内のデータと一致するようにします。スレッドが I/O スレッドと一致している限り、リレー ログは通常 OS のキャッシュ内にあるため、リレー ログのオーバーヘッドは非常に小さくなります。
さらに、マスターにも作業スレッドがあります。他の MySQL 接続と同様、スレーブによってマスターで接続を開くと、マスターもスレッドを開始します。レプリケーション プロセスには重要な制限があります。レプリケーションはスレーブ上でシリアル化されます。つまり、マスター上の並列更新操作をスレーブ上で並行して実行することはできません。
2. マスター/スレーブ レプリケーション構成
MySQL データベース サーバーにはマスターとスレーブの 2 台があり、マスターはマスター サーバー、スレーブはスレーブ サーバーです。初期状態では、マスターとスレーブのデータ情報は同じですが、マスターのデータが変化すると、それに応じてスレーブも変化し、マスターとスレーブのデータ情報が同期され、目的を達成します。バックアップ。
重要なポイント:
マスター サーバーとスレーブ サーバーの間でさまざまな変更アクションを送信する媒体は、マスター サーバーのバイナリ変更ログです。このログには、スレーブに送信する必要があるさまざまな変更アクションが記録されます。サーバ。したがって、マスターサーバーはバイナリロギング機能を有効にする必要があります。スレーブ サーバーは、マスター サーバーに接続し、マスター サーバーにバイナリ変更ログの転送を要求するための十分な権限を持っている必要があります。
環境:
マスターとスレーブの MySQL データベース バージョンは両方とも 5.0.18
IP アドレス: 10.100.0.100
2.1。コピー アカウントの作成
1. マスターのデータベースにバックアップ アカウントを作成します: 各スレーブは、標準の MySQL ユーザー名とパスワードを使用してマスターに接続します。レプリケーション操作を実行するユーザーには、REPLICATION SLAVE 権限が付与されます。ユーザー名とパスワードはテキスト ファイル master.info に保存されます。
コマンドは次のとおりです:
mysql > GRANT REPLICATION SLAVE,RELOAD,SUPER ON *.* TO backup@’10.100.0.200’ IDENTIFIED BY ‘1234’;
アカウントのバックアップを作成し、からのアクセスのみを許可します。 10.100.0.200 アドレスにアクセスしてログインします。パスワードは 1234 です。
(mysql バージョンの新旧のパスワード アルゴリズムが異なる場合は、次のように設定できます: 'backup'@'10.100.0.200'=old_password('1234') のパスワードを設定します)
2.2, データのコピー
(mysql マスター/スレーブ サーバーを完全に新規にインストールする場合、この手順は必要ありません。新しくインストールされたマスターとスレーブは同じデータを持っているため)
マスターサーバーをシャットダウンし、マスターサーバーとスレーブサーバーのデータを同期するためにマスターサーバーのデータをBサーバーにコピーし、すべての設定操作が完了する前にマスターサーバーとスレーブサーバーで書き込み操作が禁止されていることを確認します。 2 つのデータベースのデータは同じでなければなりません。
2.3. マスターの設定
次に、バイナリ ログを開いて一意のサーバー ID を指定するなど、マスターを設定します。たとえば、構成ファイルに次の値を追加します:
server-id=1log-bin=mysql-binserver-id:为主服务器A的ID值log-bin:二进制变更日值
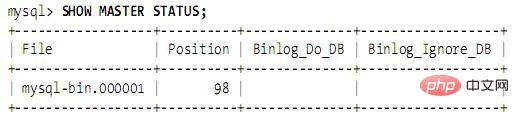
マスターを再起動し、SHOW MASTER STATUS を実行します。出力は次のようになります:
2.4. スレーブの設定
スレーブの設定はマスターと同様ですが、スレーブの MySQL も再起動する必要があります。次のように:
log_bin = mysql-binserver_id = 2relay_log = mysql-relay-binlog_slave_updates = 1read_only = 1
server_id: は必須であり、一意です。
log_bin: スレーブでバイナリ ログ bin_log を有効にする必要はありませんが、場合によっては設定する必要があります。たとえば、スレーブが別のスレーブのマスターである場合、bin_log を設定する必要があります。ここでは、バイナリ ログを有効にして名前を表示します (デフォルト名はホスト名ですが、ホスト名を変更すると問題が発生します)。
relay_log: リレー ログを設定します。log_slave_updates は、スレーブがレプリケーション イベントを独自のバイナリ ログに書き込むことを意味します (その使用法については後ほど説明します)。
スレーブ バイナリ ログを有効にしても、log_slave_updates を設定せずに、スレーブ データが変更されたかどうかを確認する人がいますが、これは間違った設定です。
read_only: データの変更を防ぐ read_only を使用してみてください (特殊なスレッドを除く)。ただし、特にスレーブ上にテーブルを作成する必要があるアプリケーションの場合、read_only はあまり実用的ではありません。
2.5. スレーブの開始
接下来就是让slave连接master,并开始重做master二进制日志中的事件。你不应该用配置文件进行该操作,而应该使用CHANGE MASTER TO语句,该语句可以完全取代对配置文件的修改,而且它可以为slave指定不同的master,而不需要停止服务器。如下:
mysql> CHANGE MASTER TO MASTER_HOST='server1', -> MASTER_USER='repl', -> MASTER_PASSWORD='p4ssword', -> MASTER_LOG_FILE='mysql-bin.000001', -> MASTER_LOG_POS=0;
MASTER_LOG_POS的值为0,因为它是日志的开始位置。
你可以用SHOW SLAVE STATUS语句查看slave的设置是否正确:
mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 4 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: No Slave_SQL_Running: No ...omitted... Seconds_Behind_Master: NULLSlave_IO_State, Slave_IO_Running, 和Slave_SQL_Running是No
表明slave还没有开始复制过程。日志的位置为4而不是0,这是因为0只是日志文件的开始位置,并不是日志位置。实际上,MySQL知道的第一个事件的位置是4。
为了开始复制,你可以运行:
mysql> START SLAVE;运行SHOW SLAVE STATUS查看输出结果:mysql> SHOW SLAVE STATUS\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: server1 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000001 Read_Master_Log_Pos: 164 Relay_Log_File: mysql-relay-bin.000001 Relay_Log_Pos: 164 Relay_Master_Log_File: mysql-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes ...omitted... Seconds_Behind_Master: 0
在这里主要是看:
Slave_IO_Running=Yes Slave_SQL_Running=Yes
slave的I/O和SQL线程都已经开始运行,而且Seconds_Behind_Master不再是NULL。日志的位置增加了,意味着一些事件被获取并执行了。如果你在master上进行修改,你可以在slave上看到各种日志文件的位置的变化,同样,你也可以看到数据库中数据的变化。
你可查看master和slave上线程的状态。在master上,你可以看到slave的I/O线程创建的连接:
在master上输入show processlist\G;
|
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: root Host: localhost:2096 db: test Command: Query Time: 0 State: NULL Info: show processlist *************************** 2. row *************************** Id: 2 User: repl Host: localhost:2144 db: NULL Command: Binlog Dump Time: 1838 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL 2 rows in set (0.00 sec) |
行2为处理slave的I/O线程的连接。
在slave服务器上运行该语句:
|
mysql> show processlist \G *************************** 1. row *************************** Id: 1 User: system user Host: db: NULL Command: Connect Time: 2291 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 2 User: system user Host: db: NULL Command: Connect Time: 1852 State: Has read all relay log; waiting for the slave I/O thread to update it Info: NULL *************************** 3. row *************************** Id: 5 User: root Host: localhost:2152 db: test Command: Query Time: 0 State: NULL Info: show processlist 3 rows in set (0.00 sec) |
行1为I/O线程状态,行2为SQL线程状态。
2.5、添加新slave服务器
假如master已经运行很久了,想对新安装的slave进行数据同步,甚至它没有master的数据。
此时,有几种方法可以使slave从另一个服务开始,例如,从master拷贝数据,从另一个slave克隆,从最近的备份开始一个slave。Slave与master同步时,需要三样东西:
(1)master的某个时刻的数据快照;
(2)master当前的日志文件、以及生成快照时的字节偏移。这两个值可以叫做日志文件坐标(log file coordinate),因为它们确定了一个二进制日志的位置,你可以用SHOW MASTER STATUS命令找到日志文件的坐标;
(3)master的二进制日志文件。
可以通过以下几中方法来克隆一个slave:
(1) 冷拷贝(cold copy)
停止master,将master的文件拷贝到slave;然后重启master。缺点很明显。
(2) 热拷贝(warm copy)
如果你仅使用MyISAM表,你可以使用mysqlhotcopy拷贝,即使服务器正在运行。
(3) 使用mysqldump
使用mysqldump来得到一个数据快照可分为以下几步:
锁表:如果你还没有锁表,你应该对表加锁,防止其它连接修改数据库,否则,你得到的数据可以是不一致的。如下:
mysql> FLUSH TABLES WITH READ LOCK;
在另一个连接用mysqldump创建一个你想进行复制的数据库的转储:
shell> mysqldump --all-databases --lock-all-tables >dbdump.db
对表释放锁。
mysql> UNLOCK TABLES;
3、深入了解复制
已经讨论了关于复制的一些基本东西,下面深入讨论一下复制。
3.1、基于语句的复制(Statement-Based Replication)
MySQL 5.0及之前的版本仅支持基于语句的复制(也叫做逻辑复制,logical replication),这在数据库并不常见。master记录下改变数据的查询,然后,slave从中继日志中读取事件,并执行它,这些SQL语句与master执行的语句一样。
这种方式的优点就是实现简单。此外,基于语句的复制的二进制日志可以很好的进行压缩,而且日志的数据量也较小,占用带宽少——例如,一个更新GB的数据的查询仅需要几十个字节的二进制日志。而mysqlbinlog对于基于语句的日志处理十分方便。
但是,基于语句的复制并不是像它看起来那么简单,因为一些查询语句依赖于master的特定条件,例如,master与slave可能有不同的时间。所以,MySQL的二进制日志的格式不仅仅是查询语句,还包括一些元数据信息,例如,当前的时间戳。即使如此,还是有一些语句,比如,CURRENT USER函数,不能正确的进行复制。此外,存储过程和触发器也是一个问题。
另外一个问题就是基于语句的复制必须是串行化的。这要求大量特殊的代码,配置,例如InnoDB的next-key锁等。并不是所有的存储引擎都支持基于语句的复制。
3.2、基于记录的复制(Row-Based Replication)
MySQL增加基于记录的复制,在二进制日志中记录下实际数据的改变,这与其它一些DBMS的实现方式类似。这种方式有优点,也有缺点。优点就是可以对任何语句都能正确工作,一些语句的效率更高。主要的缺点就是二进制日志可能会很大,而且不直观,所以,你不能使用mysqlbinlog来查看二进制日志。
对于一些语句,基于记录的复制能够更有效的工作,如:
mysql> INSERT INTO summary_table(col1, col2, sum_col3) -> SELECT col1, col2, sum(col3) -> FROM enormous_table -> GROUP BY col1, col2;
假设,只有三种唯一的col1和col2的组合,但是,该查询会扫描原表的许多行,却仅返回三条记录。此时,基于记录的复制效率更高。
另一方面,下面的语句,基于语句的复制更有效:
mysql> UPDATE enormous_table SET col1 = 0;
此时使用基于记录的复制代价会非常高。由于两种方式不能对所有情况都能很好的处理,所以,MySQL 5.1支持在基于语句的复制和基于记录的复制之前动态交换。你可以通过设置session变量binlog_format来进行控制。
3.3、复制相关的文件
除了二进制日志和中继日志文件外,还有其它一些与复制相关的文件。如下:
(1)mysql-bin.index
サーバーがバイナリ ログをオンにすると、2 番目のログ ファイルと同じ名前で末尾が .index のファイルが生成されます。これは、ディスク上にどのバイナリ ログ ファイルが存在するかを追跡するために使用されます。 MySQL はこれを使用してバイナリ ログ ファイルを見つけます。その内容は次のとおりです (私のマシン上): 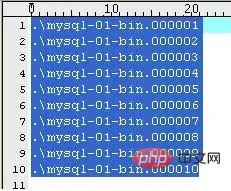
(2)mysql-relay-bin.index
このファイルの機能は mysql-bin と似ています。 .index ですが、これはバイナリ ログではなくリレー ログ用です。内容は次のとおりです。
.\mysql-02-relay-bin.000017
.\mysql-02-relay-bin.000018
(3)master.info
マスター関連の情報を保存します。削除しないでください。削除すると、再起動後にスレーブがマスターに接続できなくなります。内容は次のとおりです (私のマシン上): 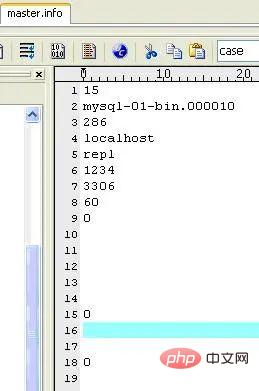
I/O スレッドは master.info ファイルを更新します。内容は次のとおりです (私のマシン上):
|
.\mysql-02-relay-bin.000019 254 mysql-01 -bin.000010 286 0 52813 |
(4)relay-log.info
スレーブ内の現在のバイナリ ログとリレー ログに関する情報が含まれます。
3.4. レプリケーション イベントを他のスレーブに送信する
log_slave_updates を設定すると、スレーブを他のスレーブのマスターとして機能させることができます。このとき、スレーブは SQL スレッドによって実行されたイベントを自身のバイナリ ログに書き込み、スレーブはこれらのイベントを取得して実行できます。 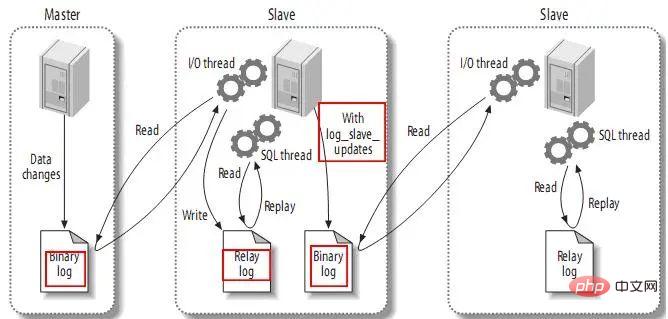
レプリケーション フィルターを使用すると、サーバー内のデータの一部のみをコピーできます。マスター バイナリ ログ内のイベントをフィルタリングし、スレーブ上のリレー ログ内のイベントをフィルタリングします。
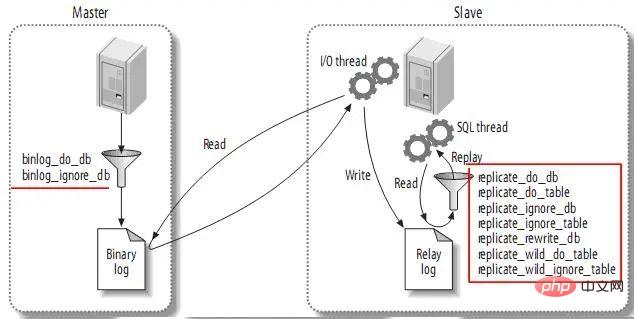
(1) 各スレーブはマスターを 1 つだけ持つことができます;
(2) 各スレーブは一意のサーバー ID を 1 つだけ持つことができます;
(3) 各マスターは複数のスレーブを持つことができます;
(4) log_slave_updates を設定すると、スレーブが他のスレーブのマスターになることができ、それによってマスターの更新を分散させることができます。
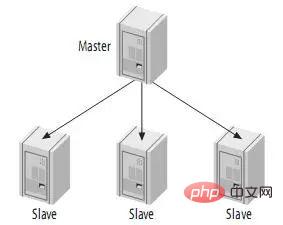 書き込み操作が少なく、読み取り操作が頻繁に行われる場合、この構造を採用できます。読み取り操作を他のスレーブに分散して、マスターへの負担を軽減できます。しかし、スレーブの数が一定数まで増加すると、マスターに対するスレーブの負荷とネットワーク帯域幅が深刻な問題になります。
書き込み操作が少なく、読み取り操作が頻繁に行われる場合、この構造を採用できます。読み取り操作を他のスレーブに分散して、マスターへの負担を軽減できます。しかし、スレーブの数が一定数まで増加すると、マスターに対するスレーブの負荷とネットワーク帯域幅が深刻な問題になります。
この構造は単純ですが、非常に柔軟で、ほとんどのアプリケーションのニーズを満たすのに十分です。いくつかの提案:
(1) 異なるスレーブは異なる役割を果たします (異なるインデックスや異なるストレージ エンジンの使用など);
(2) 1 つのスレーブをバックアップ マスターとして使用し、レプリケーションのみを実行します;
(3) ) 災害復旧にリモート スレーブを使用する;
可能有些读者朋友会有一个担心,这样搭建复制环境之后,难道不会造成两台MySQL之间的循环复制么?实际上MySQL自己早就想到了这一点,所以在MySQL的BinaryLog中记录了当前MySQL的server-id,而且这个参数也是我们搭建MySQLReplication的时候必须明确指定,而且Master和Slave的server-id参数值比需要不一致才能使MySQLReplication搭建成功。一旦有了server-id的值之后,MySQL就很容易判断某个变更是从哪一个MySQLServer最初产生的,所以就很容易避免出现循环复制的情况。而且,如果我们不打开记录Slave的BinaryLog的选项(--log-slave-update)的时候,MySQL根本就不会记录复制过程中的变更到BinaryLog中,就更不用担心可能会出现循环复制的情形了。
如图: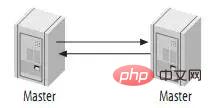
主动的Master-Master复制有一些特殊的用处。例如,地理上分布的两个部分都需要自己的可写的数据副本。这种结构最大的问题就是更新冲突。假设一个表只有一行(一列)的数据,其值为1,如果两个服务器分别同时执行如下语句:
在第一个服务器上执行:
mysql> UPDATE tbl SET col=col + 1;
在第二个服务器上执行:
mysql> UPDATE tbl SET col=col * 2;
那么结果是多少呢?一台服务器是4,另一个服务器是3,但是,这并不会产生错误。
实际上,MySQL并不支持其它一些DBMS支持的多主服务器复制(Multimaster Replication),这是MySQL的复制功能很大的一个限制(多主服务器的难点在于解决更新冲突),但是,如果你实在有这种需求,你可以采用MySQL Cluster,以及将Cluster和Replication结合起来,可以建立强大的高性能的数据库平台。但是,可以通过其它一些方式来模拟这种多主服务器的复制。
4.3、主动-被动模式的Master-Master(Master-Master in Active-Passive Mode)
这是master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中一个服务只能进行只读操作。如图: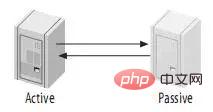
4.4 级联复制架构 Master –Slaves - Slaves
在有些应用场景中,可能读写压力差别比较大,读压力特别的大,一个Master可能需要上10台甚至更多的Slave才能够支撑注读的压力。这时候,Master就会比较吃力了,因为仅仅连上来的SlaveIO线程就比较多了,这样写的压力稍微大一点的时候,Master端因为复制就会消耗较多的资源,很容易造成复制的延时。
遇到这种情况如何解决呢?这时候我们就可以利用MySQL可以在Slave端记录复制所产生变更的BinaryLog信息的功能,也就是打开—log-slave-update选项。然后,通过二级(或者是更多级别)复制来减少Master端因为复制所带来的压力。也就是说,我们首先通过少数几台MySQL从Master来进行复制,这几台机器我们姑且称之为第一级Slave集群,然后其他的Slave再从第一级Slave集群来进行复制。从第一级Slave进行复制的Slave,我称之为第二级Slave集群。如果有需要,我们可以继续往下增加更多层次的复制。这样,我们很容易就控制了每一台MySQL上面所附属Slave的数量。这种架构我称之为Master-Slaves-Slaves架构
这种多层级联复制的架构,很容易就解决了Master端因为附属Slave太多而成为瓶颈的风险。下图展示了多层级联复制的Replication架构。
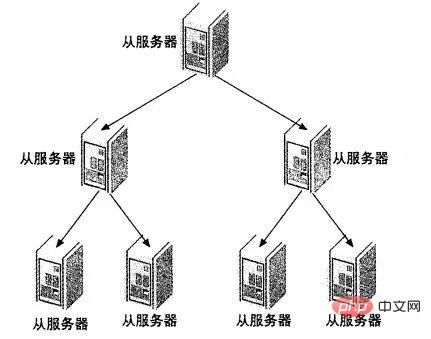
当然,如果条件允许,我更倾向于建议大家通过拆分成多个Replication集群来解决
上述瓶颈问题。毕竟Slave并没有减少写的量,所有Slave实际上仍然还是应用了所有的数据变更操作,没有减少任何写IO。相反,Slave越多,整个集群的写IO总量也就会越多,我们没有非常明显的感觉,仅仅只是因为分散到了多台机器上面,所以不是很容易表现出来。
此外,增加复制的级联层次,同一个变更传到最底层的Slave所需要经过的MySQL也会更多,同样可能造成延时较长的风险。
而如果我们通过分拆集群的方式来解决的话,可能就会要好很多了,当然,分拆集群也需要更复杂的技术和更复杂的应用系统架构。
4.5、带从服务器的Master-Master结构(Master-Master with Slaves)
这种结构的优点就是提供了冗余。在地理上分布的复制结构,它不存在单一节点故障问题,而且还可以将读密集型的请求放到slave上。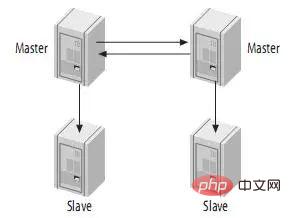
级联复制在一定程度上面确实解决了Master因为所附属的Slave过多而成为瓶颈的问题,但是他并不能解决人工维护和出现异常需要切换后可能存在重新搭建Replication的问题。这样就很自然的引申出了DualMaster与级联复制结合的Replication架构,我称之为Master-Master-Slaves架构
和Master-Slaves-Slaves架构相比,区别仅仅只是将第一级Slave集群换成了一台单独的Master,作为备用Master,然后再从这个备用的Master进行复制到一个Slave集群。
这种DualMaster与级联复制结合的架构,最大的好处就是既可以避免主Master的写入操作不会受到Slave集群的复制所带来的影响,同时主Master需要切换的时候也基本上不会出现重搭Replication的情况。但是,这个架构也有一个弊端,那就是备用的Master有可能成为瓶颈,因为如果后面的Slave集群比较大的话,备用Master可能会因为过多的SlaveIO线程请求而成为瓶颈。当然,该备用Master不提供任何的读服务的时候,瓶颈出现的可能性并不是特别高,如果出现瓶颈,也可以在备用Master后面再次进行级联复制,架设多层Slave集群。当然,级联复制的级别越多,Slave集群可能出现的数据延时也会更为明显,所以考虑使用多层级联复制之前,也需要评估数据延时对应用系统的影响。
5、复制的常见问题
错误一:change master导致的:
Last_IO_Error: error connecting to master 'repl1@IP:3306' - retry-time: 60 retries
错误二:在没有解锁的情况下停止slave进程:
mysql> stop slave;
ERROR 1192 (HY000): Can't execute the given command because you have active locked tables or an active transaction
错误三:在没有停止slave进程的情况下change master
mysql> change master to master_host=‘IP', master_user='USER', master_password='PASSWD', master_log_file='mysql-bin.000001',master_log_pos=106;
ERROR 1198 (HY000): This operation cannot be performed with a running slave; run STOP SLAVE first
错误四:A B的server-id相同:
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server ids;
these ids must be different for replication to work (or the --replicate-same-server-id option must be used on
slave but this does not always make sense; please check the manual before using it).
查看server-id
mysql> show variables like 'server_id';
手动修改server-id
mysql> set global server_id=2; #此处的数值和my.cnf里设置的一样就行
mysql> slave start;
错误五:change master之后,查看slave的状态,发现slave_IO_running 仍为NO
需要注意的是,上述几个错误做完操作之后要重启mysql进程,slave_IO_running 变为Yes
错误六:MySQL主从同步异常Client requested master to start replication from position > file size
字面理解:从库的读取binlog的位置大于主库当前binglog的值
这一般是主库重启导致的问题,主库从参数sync_binlog默认为1000,即主库的数据是先缓存到1000条后统一fsync到磁盘的binlog文件中。

当主库重启的时候,从库直接读取主库接着之前的位点重新拉binlog,但是主库由于没有fsync最后的binlog,所以会返回1236 的错误。
正常建议配置sync_binlog=1 也就是每个事务都立即写入到binlog文件中。
1、在从库检查slave状态:
偏移量为4063315
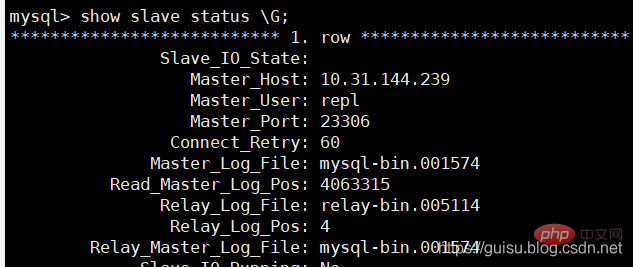
2、在主库检查mysql-bin.001574的偏移量位置
mysqlbinlog mysql-bin.001574 > ./mysql-bin.001574.bak
tail -10 ./mysql-bin.001574.bak
mysql-bin.001574文件最后几行 发现最后偏移量是4059237,从库偏移量的4063315远大主库的偏移量4059237,也就是参数sync_binlog=1000导致的。
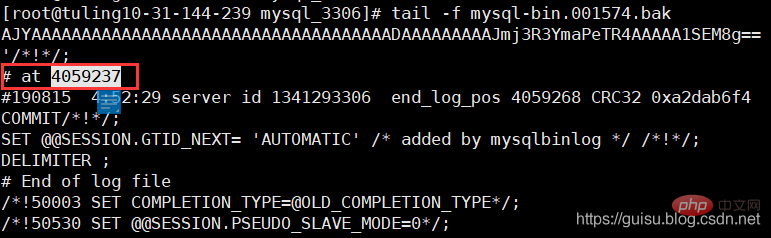
3、重新设置salve
mysql> stop slave;mysql> change master to master_log_file='mysql-bin.001574' ,master_log_pos=4059237;mysql> start slave;
错误8:数据同步异常情况
第一种:在master上删除一条记录,而slave上找不到。
Last_Error: Could not execute Delete_rows event on table market_edu.tl_player_task; Can't find record in 'tl_player_task', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.002094, end_log_pos 286434186
解决方法:由于master要删除一条记录,而slave上找不到故报错,这种情况主上都将其删除了,那么从机可以直接跳过。
可用命令:stop slave; set global sql_slave_skip_counter=1; start slave;
第二种:主键重复。在slave已经有该记录,又在master上插入了同一条记录。
Last_SQL_Error: Could not execute Write_rows event on table hcy.t1;
Duplicate entry '2' for key 'PRIMARY',
Error_code: 1062;
handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysql-bin.000006, end_log_pos 924
解决方法:在slave删除重复的主键
第三种:在master上更新一条记录,而slave上找不到,丢失了数据。
Last_SQL_Error: Could not execute Update_rows event on table hcy.t1;
Can't find record in 't1',
Error_code: 1032;
handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000010, end_log_pos 263
解决方法:把丢失的数据在slave上填补,然后跳过报错即可。
insert into t1 values (2,'BTV');
stop slave ;set global sql_slave_skip_counter=1;start slave;
相关免费学习推荐:mysql数据库(视频)
以上が高性能Mysqlマスタースレーブアーキテクチャのレプリケーション原理と構成を詳しく解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



