

高度な MySQL データベース SQL ステートメントの紹介


無料学習の推奨事項: mysql チュートリアル(ビデオ)
1. 準備作業
1. MySQL データベースのインストール
シェルスクリプト「デプロイ - ソース コードのコンパイルと MySQL のインストール」をクリックします。
2. 実験の準備、データ テーブルの構成
mysql -uroot -p
show databases;
create database train_ticket;
use train_ticket;
create table REGION(region varchar(10),site varchar(20));
create table FARE(site varchar(20),money int(10),date varchar(15));
desc REGION;
desc FARE;
insert into REGION values ('south','changsha');
insert into REGION values ('south','nanchang');
insert into REGION values ('north','beijing');
insert into REGION values ('north','tianjin');
insert into FARE values ('changsha',1000,'2021-01-30');
insert into FARE values ('nanchang',700,'2021-01-30');
insert into FARE values ('beijing',1500,'2021-01-30');
insert into FARE values ('tianjin',1200,'2021-01-30');
insert into FARE values ('beijing',2200,'2021-02-05');
select * from REGION;
select * from FARE;

##2. MySQL Advanced (上級) SQL ステートメント
1. SELECT
1 つまたは複数のフィールドにすべてのデータを表示しますテーブル内 構文: SELECT フィールド FROM テーブル名
select region from REGION;
2, DISTINCT
重複データを表示しない (重複を削除) 構文: SELECT DISTINCT フィールド FROM テーブル名
select distinct region from REGION;
3, WHERE
条件付きクエリ 構文: SELECTフィールド FROM テーブル名 WHERE 条件
select site from FARE where money > 1000;
select site from FARE where money <p>4、AND、OR<strong></strong></p><p>and (and)、or (or) <strong></strong> 構文: SELECT フィールド FROM テーブル名 WHERE 条件 1 ([AND|OR] 条件 2); <br></p><pre class="brush:php;toolbar:false">select site from FARE where money > 1000 and (money = 700);
select site,money,date from FARE where money >= 500 and (date <p>5, IN<strong></strong></p><p>既知の値の情報を表示<strong></strong> 構文: SELECT フィールド FROM テーブル名 WHERE フィールド IN ('値 1', '値 2',...); <br></p><pre class="brush:php;toolbar:false">select site,money from FARE where money in (700,1000);6, BETWEEN
2 つの値の範囲内のデータを表示します 構文: SELECT フィールド FROM テーブル名 WHERE フィールド BETWEEN '値 1' と '値 2';
select * from FARE where money between 500 and 1000;
7、ワイルドカード, LIKE
通常、ワイルドカード文字は LIKE
% と一緒に使用されます。パーセント記号は、0、1 つ、または複数の文字を表します _ : アンダースコアは 1 文字を表します
LIKE: 情報を見つけるためにパターンを照合するために使用されます 構文: SELECT field FROM table name WHERE field LIKE 'pattern';
select * from FARE where site like 'be%'; select site,money from FARE where site like '%jin_';
8, ORDER BY
キーワードによる並べ替え 構文: SELECT フィールド FROM テーブル名 [WHERE 条件] ORDER BY フィールド [ASC,DESC];
# ASC: デフォルトの並べ替え方法である昇順で並べ替えます
#DESC: 降順で並べ替えます
select * from FARE order by money desc; select date,money from FARE order by money desc;
Function
1. 数学関数
| xx | の絶対値を返します。 |
|---|---|
| 0 から 1 までの乱数を返します | ##mod(x,y) |
| ##power(x,y) | #x の y 乗を返します|
| #round(x) | 最も近い整数を x |
| round(x,y) | x の小数点以下 y 桁を保持する四捨五入value |
| sqrt(x) | x |
| truncate(x,y) | #の平方根を返します。 ##数値 x の値を小数点以下 y 桁に切り捨てて返します|
| xx | 以上の最小の整数を返します#floor(x) |
| ##greatest(x1,x2…) | |
| least(x1,x2...) | |
select abs(-1),rand(),mod(5,3),power(2,3),round (1.579),round(1.734,2); ログイン後にコピー |
|

# #avg()
| 指定された列の平均値を返します-指定された列の NULL 値 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ## max() | 指定された列の最小値を返します最大値 | |||||||||||||||||||||||||||
| sum(x) | 指定された列のすべての値の合計を返します指定された列 | |||||||||||||||||||||||||||
| trim() | 返回去除指定格式的值 |
|---|---|
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
select trim(leading 'na' from 'nanchang');
select trim(trailing '--' from 'nanchang--');
select trim(both '--' from '--nanchang--');
select concat(region,site) from REGION where region = 'south';
select concat(region,' ',site) from REGION where region = 'south';
select substr(money,1,2) from FARE;
select length(site) from FARE;
select replace(site,'ji','--') from FARE;
select upper(site) from FARE;
select lower('HAHAHA');
select left(site,2) from FARE;
select right(site,3) from FARE;
select repeat(site,2) from FARE;
select space(2);
select strcmp(100,200);
select reverse(site) from FARE;4、| | 连接符
如果sql_mode开启开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
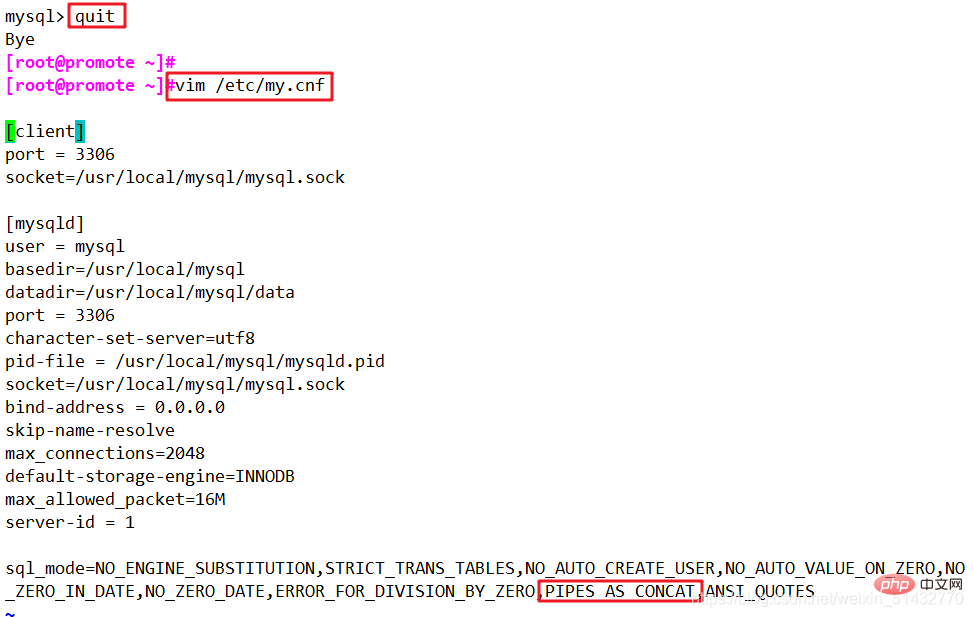
mysql -uroot -p use train_ticket; select region || ' ' || site from REGION where region = 'north'; select site || ' ' || money || ' ' || date from FARE;
5、GROUP BY
BY后面的栏位的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,就是 SELECT 后面的所有列中,没有使用聚合函数的列,必须出现在GROUP BY后面。
语法:SELECT 字段1,SUM(字段2) FROM 表名 GROUP BY 字段1;
select site,sum(money) from FARE group by site; select site,sum(money),date from FARE group by site order by money desc; select site,count(money),sum(money),date from FARE group by site order by money desc;
6、HAVING
用来过滤由GROUP BY语句返回的记录集,通常与GROUP BY语句联合使用。
HAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。如果被SELECT的只有函数栏,那就不需要GROUP BY子句。
语法:SELECT 字段1,SUM(字段2) FROM 表名 GROUP BY 字段1 HAVING(函数条件);
select site,count(money),sum(money),date from FARE group by site having sum(money) >=700;
7、别名
字段别名、表格别名
语法:SELECT “表格別名”.“字段1” [AS] “字段1別名” FROM “表格名” [AS] “表格別名”;
select RE.region AS reg, count(site) from REGION AS RE group by reg; select FA.site AS si,sum(money),count(money),date AS da from FARE AS FA group by si;
8、子查询
连接表格,在WHERE 子句或HAVING 子句中插入另一个SQL 语句
语法:SELECT 字段1 FROM 表格1 WHERE 字段2 [比较运算符] (SELECT 字段1 FROM 表格2 WHERE 条件)
可以是符号的运算符
例:=、>、=、
也可以是文字的运算符
例:LIKE、IN、BETWEEN
select A.site,region from REGION AS A where A.site in(select B.site from FARE AS B where money<blockquote><p><strong>相关免费推荐:<a href="https://www.php.cn/sql/" target="_blank">SQL教程</a></strong></p></blockquote>
以上が高度な MySQL データベース SQL ステートメントの紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 Oracleデータベースにリモート接続する方法
Apr 11, 2025 pm 02:27 PM
Oracleデータベースにリモート接続する方法
Apr 11, 2025 pm 02:27 PM
Oracleにリモートで接続するには、リスナー、サービス名、ネットワーク構成が必要です。 1.クライアント要求は、リスナーを介してデータベースインスタンスに転送されます。 2。インスタンスはIDを検証し、セッションを確立します。 3.ユーザー名/パスワード、ホスト名、ポート番号、およびサービス名を指定して、クライアントがサーバーにアクセスし、構成が一貫していることを確認する必要があります。接続が失敗したら、ネットワーク接続、ファイアウォール、リスナー、ユーザー名とパスワードを確認します。 ORA-12154エラーの場合は、リスナーとネットワークの構成を確認してください。 効率的な接続には、接続プーリング、SQLステートメントの最適化、適切なネットワーク環境の選択が必要です。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
 Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracle SQLステートメントのコアは、さまざまな条項の柔軟なアプリケーションと同様に、選択、挿入、更新、削除です。インデックスの最適化など、ステートメントの背後にある実行メカニズムを理解することが重要です。高度な使用法には、サブクエリ、接続クエリ、分析関数、およびPL/SQLが含まれます。一般的なエラーには、構文エラー、パフォーマンスの問題、およびデータの一貫性の問題が含まれます。パフォーマンス最適化のベストプラクティスには、適切なインデックスの使用、Select *の回避、条項の最適化、およびバインドされた変数の使用が含まれます。 Oracle SQLの習得には、コードライティング、デバッグ、思考、基礎となるメカニズムの理解など、練習が必要です。
