

MySQL エッセンス 1: DQL データ クエリ ステートメント

#ディレクトリ無料学習の推奨事項: mysql ビデオ チュートリアル
##1. 基本クエリ
##2. 条件付きクエリ- ##3. 並べ替えクエリ
- # #4 . 共通機能 ##5. グループクエリ
- ##6. 接続クエリ ##7. サブクエリ
- ##8. ページングクエリ 9. 結合クエリ
- サンプルデータの準備
- DQLクエリ文の実験を行う前に、まずクエリ利用のサンプルとして対応するデータを準備します。
- SQL スクリプトを SQLyog にインポートすると、準備されたサンプル テーブルが表示されます。
このサンプルは、多国籍企業の従業員管理用です。 enterprise 4 つのテーブルがあります。次の図は、各テーブルのフィールドを示しています:
1. 基本クエリ
構文: 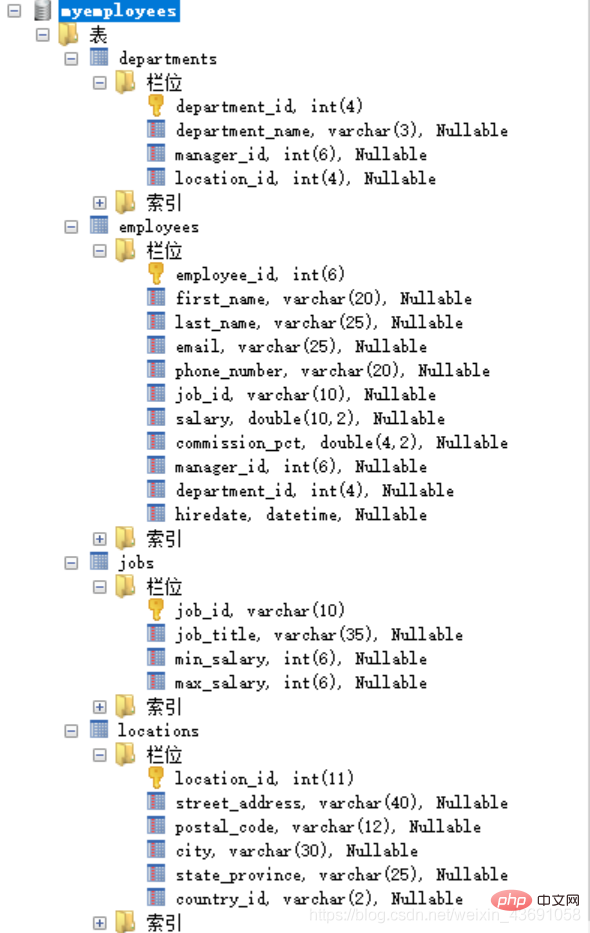 selectテーブル名からのクエリ リスト;
selectテーブル名からのクエリ リスト;
機能: クエリ リストには、テーブル内のフィールド、定数値、式、関数を指定できます。
クエリ リストには、テーブル内のフィールド、定数値、式、関数を指定できます。
実行順序: from > select (最初にテーブルを見つけてからクエリを開始します)
注意:`是着重号,当某张表中的字段与关键字冲突时,可以在该字段两边加上着重号,以标明其是一个字段,而不是关键字(如`name`)。
【基础查询】# 选中样本库USER myemployees;# 1.查询表中的单个字段SELECT last_name FROM employees;# 2.查询表中的多个字段SELECT last_name,salary,email FROM employees;# 3.查询表中所有的字段SELECT * FROM employees;# 4. 查询常量值SELECT 'Tom';# 5.查询表达式SELECT 7%6;# 6. 查询函数SELECT VERSION();# 7.起别名(mysql中建议将起别名使用双引号引起来"别名")/* 优点:便于理解;连接查询时,如果要查询的字段有重名情况,可以使用起别名来区分 */# 方式一,使用asSELECT 7%6 AS 结果;SELECT last_name AS 姓,first_name AS 名 FROM employees;# 方式二,使用空格SELECT 7%6 结果;SELECT last_name 姓,first_name 名 FROM employees;# 查询员工号为176的员工的姓名、部门、nianxinSELECT last_name,department_id,salary*12*(1+IFNULL(commission_pct,0)) AS 年薪 FROM employees; # 8.去重SELECT DISTINCT department_id FROM employees;# 9.+号的作用/* select 13+21; 两个操作数都是数值型,自动做加法运算 其中一个为字符型,则将字符型转换为数值型 select '13'+1; 转换成功,做加法运算 select 'hello'+1; 转换失败,将字符型转换为0 select null+10; 只要其中一方为null,结果就为null 补充ifnull函数:SELECT IFNULL(commission_pct,0) AS 奖金率,commission_pct FROM employees; mysql中用来拼接的不是+号,而是concat函数 */SELECT CONCAT(last_name,first_name) AS "姓名" FROM employees;
基本的なクエリの概要
手順
| フィールドを選択します1 from table ; | |
|---|---|
| 2.テーブル内の複数のフィールドをクエリします | フィールド 1、フィールド 2、を選択します。 .. テーブルのフィールド n; |
| 3. テーブル内のすべてのフィールドをクエリします | select * from table; |
| 4. 定数値のクエリ | ##select 'Constant value;' |
| 5. クエリ式 | select value 1 式の値 2; |
| #select f(); | |
| as | |
| #distinct | |
| concat(last_name,first_name) |
|
| 答え: | 1.正解
| 2 .###正しい
(1) 条件演算子によるフィルタリング4.
DESC 部門;;
SELECT * FROM 部門;
5.SELECT CONCAT(first_name,',',last_name,',',IFNULL(email,0)) AS "out_put" FROM 従業員;
#2. 条件付きクエリ
構文:フィルター条件があるテーブル名からクエリ リストを選択;実行順序:
from > where > select (最初にテーブルを見つけ、次にフィルタリングを開始し、最後にクエリを実行します)Category:
 ;
;条件运算符有: > = )
支持&& || !,但推荐使用and or not 逻辑表达式作用:用于连接条件表达式 &&或and: 两个都为true,结果为true,反之为false ||或or : 只要有一个条件为true,结果即为true,反之为false !或not : 取反
模糊查关键字:like、between and、in、is null (1)like关键字 可以判断字符型或数值型 like一般和通配符搭配使用,通配符有 %:代表任意多个字符,包含0个 _:代表任意单个字符 (2)between...and关键字 可以提高语句简洁度 包含临界值 两个临界值不能调换顺序 (3)in关键字 可以提高语句简洁度 in列表的值类型必须一致 (4)is null 取反是 is not null
【条件查询】(1)按条件运算符筛选# 1.查询工资>12000的员工SELECT * FROM employees WHERE salary > 12000 ;# 2.查询部门编号不等于90的员工名和部门编号SELECT department_name, department_id FROM departments WHERE department_id90;---------------------------------------------------------------------------------------------------------------------(2)按逻辑表达式筛选# 1.查询工资在10000到20000之间的员工名、工资以及奖金率SELECT last_name,salary,commission_pct FROM employees WHERE salary>=10000 AND salary=90 AND department_id15000;---------------------------------------------------------------------------------------------------------------------(3)模糊查询# (1)like关键字# 1.查询员工名中包含字符a的员工的信息SELECT * FROM employees WHERE last_name LIKE '%a%';# 2.查询员工名中第三个字符为n,第五个字符为l的员工名和工资SELECT last_name,salary FROM employees WHERE last_name LIKE '__n_l%';# 3.查询员工名中第二个字符为_的员工名(转义)SELECT last_name FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$';# (2)between...and关键字# 1.查询员工编号在100到120的员工信息SELECT * FROM employees WHERE employee_id BETWEEN 100 AND 120;# (3)in关键字# 1.查询员工的工种编号是IT_PROG、AD_VP、AD_PRES中的员工名和工种编号SELECT last_name,job_id FROM employees WHERE job_id IN('IT_PROG','AD_VP','AD_PRES');# (4)is null# 1.查询没有奖金的员工名和奖金率SELECT last_name,commission_pct FROM employees WHERE commission_pct IS NULL;# is null仅仅可以用来判断null值;安全等于既可以用来判断null值,又可以用来判断普通值# is null的可读性高于,建议使用is nullSELECT last_name,commission_pct FROM employees WHERE commission_pct NULL;条件付きクエリの概要説明
(3) ファジー クエリ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| 排序查询总结 | 说明 |
|---|---|
| 升序 | order by asc |
| 降序 | order by desc |
4. 共通関数
呼び出し構文: テーブルから関数名(実際のパラメータリスト)を選択;
概念: Javaに似ていますこのメソッドは、一連の論理ステートメントをメソッド本体にカプセル化し、インターフェイスを外部に公開します。
利点:
1. 実装の詳細を非表示にします
2. コードの再利用性を向上します
分類: 単一行関数とグループ化された関数に分割されます。このうち、単一行関数は、文字関数、数学関数、日付関数、システム関数、プロセス制御関数に分類されます。 ;グループ関数は、統計関数、集計関数、グループ関数とも呼ばれる統計関数に使用されます。
| 説明 | |
|---|---|
| (1)文字関数 | パラメータの型は文字型です |
select length('string') |
|
concat(フィールド 1, フィールド 2) |
|
上位、下位 |
|
| substr(index, end ) | |
| instr(main string, substring) | |
| trim(a from'aaaa string 1aa') | |
| lpad( '文字列 1', 左のパディング番号 n, パディング文字 'a') | , lpad('文字列 1', 右のパディング番号 n, パディング文字 'a')
| #Replace
| replace('文字列 1','置換された文字列','新しい文字列') | |
| ##パラメータの型は数値です | #四捨五入 |
Interception |
|
切り上げ |
|
切り捨て方向 | |
remainder |
|
乱数 |
|
|
|
| パラメータは日付です | 現在の値を返します完全な日付 |
現在の年、月、日を返します | |
現在の時、分、秒を返します |
|
指定された部分をインターセプト | #年として YEAR(now())、月として MONTH(now())、日として DAY(now()) を選択します。|
文字列→日付 | STR_TO_DATE('2020-7-7','%Y-%m-%d')|
日付→文字列 | DATE_FORMAT(NOW(),'%Y年 %m月 %d日')|
2 つの日付間の差の日数を返します | datediff(date1,date2)|
(4 ) システムfunction |
|
| 現在のバージョンを表示 | select version() ;|
現在のデータベースを表示 | select database();|
View現在のユーザー | select user();|
自動暗号化 | password('character');または md5( 'Character');|
(5) プロセス制御関数 |
|
| if | if(ボーナス IS NULL,'ボーナスなし','ボーナスあり')|
|
|
 |
 |
| ##sum | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
avg |
||||||||||||
max |
||||||||||||
| #min | | 最小値|||||||||||
| count | | 数値を計算する|||||||||||
##【单行函数】# (1)字符函数-[参数类型为字符型]# 1.length 获取参数值的字节个数SELECT LENGTH('john');SELECT LENGTH('张三丰');SHOW VARIABLES LIKE '%char%' # 查看字符集# 2.concat拼接字符串SELECT CONCAT(last_name,'_',first_name) 姓名 from employees;# 3.upper、lower 大小写转换SELECT UPPER('tom');SELECT LOWER('TOM')# 将姓变大写,名变小写,然后拼接SELECT CONCAT(UPPER(last_name),LOWER(first_name))姓名 FROM employees;# 4.substr 拼接函数# mysql中的索引从1开始SELECT SUBSTR('若负平生意,何名作莫愁',7) AS out_put;SELECT SUBSTR('若负平生意,何名作莫愁',1,3) AS out_put;# 案例:姓名中首字符大写,其他字符小写,用_拼接并显示出来SELECT CONCAT(UPPER(SUBSTR(last_name,1,1)),'_',LOWER(SUBSTR(last_name,2))) oup_put FROM employees; # 5.instr 字符查找函数# 返回子串在主串中的起始索引,没有返回零SELECT INSTR('凡尘阿凉','阿凉') AS out_put;# 6.trim 清除空格函数# 将字符两边的空格移除SELECT LENGTH(TRIM(' 凡尘 ')) AS out_put;SELECT TRIM('a' FROM 'aaaaaa凡aaa尘aaaa') AS out_put;# 7.lpad 左填充函数# 用指定的字符实现左填充指定长度SELECT LPAD('凡尘',10,'*') AS out_put;# 8.rpad 右填充函数# 用指定的字符实现右填充指定长度SELECT RPAD('凡尘',10,'*') AS out_put;# 9.replace 替换函数SELECT REPLACE('我的偶像是鲁迅','鲁迅','周冬雨') AS oup_put;---------------------------------------------------------------------------------------------------------# (2)数学函数-[参数类型为数值]# 1.round 四舍五入函数SELECT ROUND(1.65);SELECT ROUND(1.567,2);# 2.ceil 向上取整函数# 返回>=该参数的最小整数SELECT CEIL(1.00);# 3.floor 向下取整函数# 返回5,'大于','小于');SELECT last_name,commission_pct, IF(commission_pct IS NULL,'没奖金','有奖金') AS out_put FROM employees;# 2.MySQL エッセンス 1: DQL データ クエリ ステートメント函数/*
方式一:类似于Java中的switch-MySQL エッセンス 1: DQL データ クエリ ステートメント:
案例:查询员工工资,要求
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示的工资为原工资
*/SELECT salary 原始工资,department_id,CASE department_idWHEN 30 THEN salary*1.1WHEN 40 THEN salary*1.2WHEN 50 THEN salary*1.3ELSE salaryEND AS 新工资FROM employees;/*
方式二:类似于Java中的多重if:
案例:查询员工的工资情况
工资>20000,显示A级别
工资>15000,显示B级别
工资>10000,显示C级别
否则,显示D级别
*/SELECT salary,CASEWHEN salary>20000 THEN 'A'WHEN salary>15000 THEN 'B'WHEN salary>10000 THEN 'C'ELSE 'D'END AS 工资级别FROM employees;ログイン後にコピー 【分组函数】/* SUM 求和 AVG 平均值 MAX 最大值 MIN 最小值 COUNT 计算个数 */# 综合使用SELECT SUM(salary) "和",AVG(salary) "平均数",MAX(salary) "最大值",MIN(salary) "最小值",COUNT(salary) "总个数" FROM employees;/* 分组函数的特点: 1.sum、avg一般用于处理数值型;max、min、count可以处理任何类型 2.分组函数都忽略null值,都可以和distinct搭配去重 3.和分组函数一同查询的字段要求是group by后的字段 4.count函数经常用来统计行数,使用count(*)或count(1)或count(常量) 效率问题: MYISAM存储引擎下,count(*)效率高 INNODB存储引擎下,count(*)和count(1)效率差不多,但比count(字段)要高 */ ログイン後にコピー
五、分组查询 语法: 执行顺序:
注意: # 1.查询每个工种的最高工资SELECT MAX(salary) "最高工资",job_id "工种" FROM employees GROUP BY job_id;# 2.查询每个位置上的部门个数SELECT COUNT(*) "部门个数",location_id "位置id" FROM departments GROUP BY location_id;# 3.查询邮箱中包含a字符的,每个部门的平均工资SELECT AVG(salary) "平均工资",department_id "部门id" FROM employees WHERE email LIKE '%a%' GROUP BY department_id;# 4.查询每个领导手下的有奖金的员工的最高工资SELECT MAX(salary) "最高工资",manager_id "领导编号" FROM employees WHERE NOT ISNULL(commission_pct) GROUP BY manager_id;# 5.查询哪个部门的员工个数>2# 思路:查询每个部门的个数,再根据结果哪个部门的员工个数>2SELECT COUNT(*),department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2;# 6.查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资SELECT MAX(salary) "最高工资",job_id "工种" FROM employees WHERE NOT ISNULL(commission_pct) GROUP BY job_id HAVING MAX(salary)>12000;# 7.查询领导编号>102的每个领导手下员工的最低工资>5000的领导编号是哪个,以及其最低工资SELECT MIN(salary) "最低工资",manager_id "领导编号" FROM employees WHERE manager_id>102 GROUP BY manager_id HAVING MIN(salary)>5000;# 8.按员工姓名的长度分组,查询每一组的员工个数,筛选员工个数>5的有哪些SELECT COUNT(*) "员工个数",LENGTH(last_name) "姓名长度" FROM employees GROUP BY LENGTH (last_name) HAVING COUNT(*)>5;# 9.查询每个部门每个工种的员工的平均工资SELECT AVG(salary) "平均工资",department_id "部门",job_id "工种" FROM employees GROUP BY department_id,job_id; # 10.查询每个部门每个工种的员工的平均工资,并按平均工资的高低显示SELECT AVG(salary) "平均工资",department_id "部门",job_id "工种" FROM employees GROUP BY department_id,job_id ORDER BY AVG(salary) DESC; ログイン後にコピー
六、连接查询 概念: 分类:安装年代可以分为 注意: 连接查询分为下面三类:
(2)外连接
(3)交叉连接 【sql92标准】# 1.等值连接# 查询女神名和对应的男朋友名# SELECT NAME,boyName FROM boys,beauty WHERE beauty.boyfriend_id=boys.id;# 1.查询员工名和对应的部门名SELECT last_name "员工名",department_name "部门名" FROM employees,departments
WHERE employees.department_id=departments.department_id;# 2.查询员工名、工种号、工种名SELECT last_name,e.job_id,job_title FROM employees e,jobs j WHERE e.`job_id`=j.`job_id`;# 3.查询有奖金的员工名、部门名SELECT last_name,department_name,commission_pct FROM employees e,departments d
WHERE e.`department_id`=d.`department_id` AND e.`commission_pct` IS NOT NULL;# 等值连接+筛选# 4.查询城市中第二个字符为o的部门名和城市名SELECT department_name "部门名",city "城市名" FROM departments d,locations l
WHERE d.`location_id`=l.`location_id` AND city LIKE '_o%'; # 等值连接+分组# 5.查询每个城市的部门个数SELECT COUNT(*) "部门个数",city "城市" FROM departments d,locations l
WHERE d.`location_id`=l.`location_id` GROUP BY city;# 6.查询有奖金的每个部门的部门名、部门的领导编号、该部门最低工资SELECT department_name,d.manager_id,MIN(salary) FROM departments d,employees e
WHERE d.`department_id`=e.`department_id` AND commission_pct IS NOT NULL GROUP BY department_name,d.manager_id;# 7.查询每个工种的工种名、员工的个数并按员工的个数降序SELECT job_title,COUNT(*) FROM employees e,jobs j WHERE e.`job_id`=j.`job_id` GOUP BY job_title ORDER BY COUNT(*) DESC;# 8.支持三表连接# 查询员工名、部门名、所在的城市SELECT last_name,department_name,city FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id` AND d.`location_id`=l.`location_id`;# (2)非等值连接/*
先执行下面的语句,在myemployees数据库中创建新的job_grades表。
CREATE TABLE job_grades
(grade_level VARCHAR(3),
lowest_sal INT,
highest_sal INT);
INSERT INTO job_grades
VALUES ('A', 1000, 2999);
INSERT INTO job_grades
VALUES ('B', 3000, 5999);
INSERT INTO job_grades
VALUES('C', 6000, 9999);
INSERT INTO job_grades
VALUES('D', 10000, 14999);
INSERT INTO job_grades
VALUES('E', 15000, 24999);
INSERT INTO job_grades
VALUES('F', 25000, 40000);
*/# 1.查询员工的工资和工资级别SELECT salary,grade_level FROM employees e,job_grades j WHERE salary BETWEEN j.`lowest_sal` AND j.`highest_sal`;# (3)自连接# 1.查询员工名和其上级的名称.SELECT e.employee_id "员工id",e.last_name "员工姓名",m.employee_id "经理id",m.last_name "经理姓名" FROM employees e,employees m WHERE e.`manager_id`=m.`employee_id`;ログイン後にコピー
【sql99标准】# (1)等值连接# 1.查询员工名,部门名SELECT last_name,department_name FROM employees eINNER JOIN departments dON e.department_id=d.department_id;# 2.查询名字中包含e的员工名和工种名(添加筛选)SELECT last_name,job_titleFROM employees eINNER JOIN jobs jON e.job_id=j.job_idWHERE last_name LIKE '%e%' OR job_title LIKE '%e%';# 3.查询部门个数>3的城市名和部门个数(分组+筛选)SELECT city,COUNT(*) "部门个数"FROM departments dINNER JOIN locations lON d.location_id=l.location_idGROUP BY cityHAVING COUNT(*)>3;# 4.查询哪个部门的部门员工个数>3的部门名和员工个数,并按个数降序(排序)SELECT department_name "部门名",COUNT(*) "员工个数"FROM departments dINNER JOIN employees eON d.department_id=e.department_idGROUP BY department_nameHAVING COUNT(*)>3ORDER BY COUNT(*) DESC;# 5.查询员工名、部门名、工种名、并按部门名排序SELECT last_name "员工名",department_name "部门名",job_title "工种名"FROM employees eINNER JOIN departments d ON d.department_id=e.department_idINNER JOIN jobs j ON e.job_id=j.job_idORDER BY department_name ;# (2)非等值连接# 查询员工工资级别SELECT salary,grade_levelFROM employees eJOIN job_grades j ON e.`salary` BETWEEN j.lowest_sal AND j.highest_sal;# 查询每个工资级别的个数>20的个数,并且按照工资级别降序排列SELECT COUNT(*),grade_levelFROM employees eJOIN job_grades j ON e.`salary` BETWEEN j.lowest_sal AND j.highest_salGROUP BY grade_levelHAVING COUNT(*)>20ORDER BY grade_level DESC;# (3)自连接# 查询员工的名字、上级的名字SELECT e1.last_name "员工名",e2.last_name "上级名"FROM employees e1JOIN employees e2 ON e1.manager_id=e2.employee_id;--------------------------------------------------------------------------------------------------------------# 二、外连接# 1.查询男朋友不在男神表的女神名# 左外连接SELECT NAME FROM beauty LEFT OUTER JOIN boys ON beauty.boyfriend_id=boys.idWHERE boys.id IS NULL;# 右外连接SELECT NAMEFROM boys RIGHT OUTER JOIN beauty ON beauty.boyfriend_id=boys.idWHERE boys.id IS NULL;# 2.查询没有员工的部门SELECT d.department_name,e.employee_idFROM departments d LEFT JOIN employees e ON d.department_id=e.department_idWHERE e.manager_id IS NULL;SELECT * FROM employees WHERE employee_id=100;# 3.全外连接(不支持)# 全外连接就是就并集USE girls;SELECT b.*,bo.*FROM beauty bFULL JOIN boys boON b.boyfriend_id=bo.id;# 三.交叉连接# 使用99标准实现的笛卡尔乘积,使用cross代替了92中的,SELECT b.*,bo.*FROM beauty bCROSS JOIN boys bo ログイン後にコピー
七、子查询 含义:出现在其他语句中的select语句,称为子查询或内查询;外部的查询语句,称为主查询或外查询。 按
按
【where和having后的子查询】(支持标量、行、列子查询)# 1.单个标量子查询# 查询工资比Abel工资高的员工名SELECT last_name,salary FROM employees WHERE salary>(SELECT salary FROM employees WHERE last_name='Abel');# 2。多个标量子查询# 返回job_id与141号相同,salary比143号员工多的员工的姓名、job_id、工资。SELECT last_name,job_id,salary FROM employeesWHERE job_id=( SELECT job_id FROM employees WHERE employee_id=141) AND salary>(SELECT salary FROM employees WHERE employee_id=143);# 3。标量子查询+分组函数# 返回工资最少的员工的last_name、job_id和salarySELECT last_name,job_id,salary FROM employees WHERE salary=(SELECT MIN(salary) FROM employees);# 4。标量子查询+having子句# 查询最低工资 >50号部门最低工资的 部门id和其最低工资SELECT department_id,MIN(salary) FROM employees GROUP BY department_idHAVING MIN(salary)>(SELECT MIN(salary) FROM employees WHERE department_id=50); # 5.列子查询(多行子查询)# 返回location_id是1400或1700的部门中的所有员工姓名.SELECT last_name FROM employees WHERE department_id IN ( SELECT DISTINCT department_id FROM departments WHERE location_id IN(1400,1700));# 返回其它工种中比job_id为'IT_PROG'工种中任一工资低的员工的工号、姓名、job_id、以及salarySELECT employee_id,last_name,job_id,salary FROM employeesWHERE salary<any>'IT_PROG';# 返回其它工种中比job_id为'IT_PROG'工种中所有工资低的员工的工号、姓名、job_id、以及salarySELECT employee_id,last_name,job_id,salary FROM employeesWHERE salary<all>'IT_PROG';# 6.行子查询(一行多列或多列多行子查询)# 查询出员工编号最小并且工资最高的员工信息# 方式一SELECT * FROM employees WHERE (employee_id,salary)=(SELECT MIN(employee_id),MAX(salary) FROM employees);# 方式二SELECT * FROM employees WHERE employee_id=(SELECT MIN(employee_id) FROM employees)AND salary=(SELECT MAX(salary) FROM employees)</all></any> ログイン後にコピー 【select后的子查询】:(仅支持标量子查询)# 1.查询每个部门的员工个数SELECT d.*,(SELECT COUNT(*) FROM employees e WHERE e.department_id=d.department_id) "员工个数"FROM departments d;# 2.查询员工号=102的部门名SELECT ( SELECT department_name FROM departments d INNER JOIN employees e ON d.department_id=e.department_id WHERE e.employee_id=102) 部门名; ログイン後にコピー 【from后面的子查询】(支持表子查询)# 1.查询每个部门的平均工资的工资等级,即将子查询后的结果充当一张表,要求必须起别名SELECT a.*,g.grade_level "工资等级"FROM ( SELECT AVG(salary) ag,department_id FROM employees GROUP BY department_id) aINNER JOIN job_grades gON a.ag BETWEEN lowest_sal AND highest_sal; ログイン後にコピー 【existts后面的子查询】(又叫相关子查询,可以用in代替)# exists结果只会是1或0 :SELECT EXISTS(SELECT * FROM employees);# 1.查询有员工名的部门名SELECT department_nameFROM departments dWHERE EXISTS(SELECT * FROM employees e WHERE d.department_id=e.department_id); ログイン後にコピー
八、分页查询 应用场景:当要显示的数据一页显示不全,需要分页提交sql请求。 语法:
执行顺序: limit分页公式:
# 1.查询前五条员工信息SELECT * FROM employees LIMIT 5;# 2.查询第11条到第25条SELECT * FROM employees LIMIT 10,15# 3.有奖金的员工信息,并且显示出工资较高的前10名SELECT * FROM employeesWHERE commission_pct IS NOT NULLORDER BY salaryLIMIT 10; ログイン後にコピー 九、联合查询 定义:将多条查询语句的结果合并成一个结果。 语法: 应用场景:当要查询的结果来自多个没有连接关系的表,但查询的信息一致时,最适合使用union。 注意事项:
# 1.查询部门编号>90或邮箱包含a的员工信息SELECT * FROM employees WHERE department_id>90 OR email LIKE '%a%';SELECT * FROM employees WHERE department_id>90 UNION SELECT * FROM employees WHERE email LIKE '%a%'; ログイン後にコピー
|







以上がMySQL エッセンス 1: DQL データ クエリ ステートメントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7364
7364
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
ビッグ データ構造の処理スキル: チャンキング: データ セットを分割してチャンクに処理し、メモリ消費を削減します。ジェネレーター: データ セット全体をロードせずにデータ項目を 1 つずつ生成します。無制限のデータ セットに適しています。ストリーミング: ファイルやクエリ結果を 1 行ずつ読み取ります。大きなファイルやリモート データに適しています。外部ストレージ: 非常に大規模なデータ セットの場合は、データをデータベースまたは NoSQL に保存します。
 PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
PHP で MySQL クエリのパフォーマンスを最適化するにはどうすればよいですか?
Jun 03, 2024 pm 08:11 PM
MySQL クエリのパフォーマンスは、検索時間を線形の複雑さから対数の複雑さまで短縮するインデックスを構築することで最適化できます。 PreparedStatement を使用して SQL インジェクションを防止し、クエリのパフォーマンスを向上させます。クエリ結果を制限し、サーバーによって処理されるデータ量を削減します。適切な結合タイプの使用、インデックスの作成、サブクエリの使用の検討など、結合クエリを最適化します。クエリを分析してボトルネックを特定し、キャッシュを使用してデータベースの負荷を軽減し、オーバーヘッドを最小限に抑えます。
 PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL のバックアップと復元を使用するにはどうすればよいですか?
Jun 03, 2024 pm 12:19 PM
PHP で MySQL データベースをバックアップおよび復元するには、次の手順を実行します。 データベースをバックアップします。 mysqldump コマンドを使用して、データベースを SQL ファイルにダンプします。データベースの復元: mysql コマンドを使用して、SQL ファイルからデータベースを復元します。
 PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
PHP を使用して MySQL テーブルにデータを挿入するにはどうすればよいですか?
Jun 02, 2024 pm 02:26 PM
MySQLテーブルにデータを挿入するにはどうすればよいですか?データベースに接続する: mysqli を使用してデータベースへの接続を確立します。 SQL クエリを準備します。挿入する列と値を指定する INSERT ステートメントを作成します。クエリの実行: query() メソッドを使用して挿入クエリを実行します。成功すると、確認メッセージが出力されます。
 MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 で mysql_native_password がロードされていないエラーを修正する方法
Dec 09, 2024 am 11:42 AM
MySQL 8.4 (2024 年時点の最新の LTS リリース) で導入された主な変更の 1 つは、「MySQL Native Password」プラグインがデフォルトで有効ではなくなったことです。さらに、MySQL 9.0 ではこのプラグインが完全に削除されています。 この変更は PHP および他のアプリに影響します
 PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するにはどうすればよいですか?
Jun 02, 2024 pm 02:13 PM
PHP で MySQL ストアド プロシージャを使用するには: PDO または MySQLi 拡張機能を使用して、MySQL データベースに接続します。ストアド プロシージャを呼び出すステートメントを準備します。ストアド プロシージャを実行します。結果セットを処理します (ストアド プロシージャが結果を返す場合)。データベース接続を閉じます。
 PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するにはどうすればよいですか?
Jun 04, 2024 pm 01:57 PM
PHP を使用して MySQL テーブルを作成するには、次の手順が必要です。 データベースに接続します。データベースが存在しない場合は作成します。データベースを選択します。テーブルを作成します。クエリを実行します。接続を閉じます。
 Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracleデータベースとmysqlの違い
May 10, 2024 am 01:54 AM
Oracle データベースと MySQL はどちらもリレーショナル モデルに基づいたデータベースですが、Oracle は互換性、スケーラビリティ、データ型、セキュリティの点で優れており、MySQL は速度と柔軟性に重点を置いており、小規模から中規模のデータ セットに適しています。 ① Oracle は幅広いデータ型を提供し、② 高度なセキュリティ機能を提供し、③ エンタープライズレベルのアプリケーションに適しています。① MySQL は NoSQL データ型をサポートし、② セキュリティ対策が少なく、③ 小規模から中規模のアプリケーションに適しています。
