

K8s での Redis クラスターのデプロイメントの紹介


# 1. はじめに アーキテクチャの原則: 各マスターは複数のスレーブを持つことができます。マスターがオフラインになると、Redis クラスターは代替として複数のスレーブから新しいマスターを選出し、オンラインに戻ると古いマスターが新しいマスターのスレーブになります。
2. 準備作業 このデプロイメントは主にこれに基づいていますプロジェクト :
https://github.com/zuxqoj/kubernetes-redis-cluster
Service&Deployment
3. StatefulSet の概要 RC、Deployment、および DaemonSet はすべてステートレス サービスであり、管理する Pod の IP、名前、開始および停止のシーケンスはすべてランダムです。ステートフルセットとは何ですか?名前が示すように、ステートフル コレクションは、MySQL、MongoDB クラスターなどのすべてのステートフル サービスを管理します。
StatefulSet は本質的に Deployment のバリアントです。v1.9 で GA バージョンになりました。ステートフル サービスの問題を解決するために、管理する Pod には固定の Pod 名、開始および停止シーケンスがあります。StatefulSet では、ポッド名はネットワーク識別子 (ホスト名) と呼ばれ、共有ストレージも使用する必要があります。
Deployment では、対応するサービスは service であり、StatefulSet では、ヘッドレス サービス、ヘッドレス サービス、つまりヘッドレス サービスに対応しますが、service との違いは、クラスター IP を持たないことです。その名前は、ヘッドレス サービスに対応するすべてのポッドのエンドポイント リストに返されます。 さらに、StatefulSet は、ヘッドレス サービスに基づいて、StatefulSet によって制御される各 Pod コピーの DNS ドメイン名を作成します。このドメイン名の形式は次のとおりです:
$(podname).(headless server name) FQDN: $(podname).(headless server name).namespace.svc.cluster.local
StatefulSet は、ヘッドレス サービス (つまり、クラスター IP のないサービス) に基づいて、ポッドの安定したネットワーク フラグ (ポッドのホスト名と DNS レコードを含む) を実装します。これは、ポッドが再スケジュールされた後も変更されません。同時に、StatefulSet を PV/PVC と組み合わせることで、安定した永続ストレージを実現でき、Pod が再スケジュールされた後でも、元の永続データに引き続きアクセスできます。
以下は、StatefulSet を使用して Redis をデプロイするアーキテクチャです。マスターであってもスレーブであっても、これは StatefulSet のコピーであり、データは PV を通じて永続化され、クライアントのリクエストを受け入れるサービスとして公開されます。
4. デプロイメントプロセス この記事では、リファレンス プロジェクトの README で、StatefulSet に基づいて Redis を作成する手順を簡単に紹介しています:
2. PV の作成
3. PVC の作成
4. Configmap の作成
5. ヘッドレス サービスの作成
6. Redis StatefulSet の作成
7. Redis クラスターの初期化
1. NFS ストレージの作成 NFS ストレージの作成は、主に K8S の安定したバックエンド ストレージを提供することです。 Redis: Redis ポッドを再起動または移行しても、元のデータを引き続き取得できます。ここでは、最初に NFS を作成し、次に PV を使用して Redis のリモート NFS パスをマウントします。
NFS をインストールします
yum -y install nfs-utils(主包提供文件系统) yum -y install rpcbind(提供rpc协议)
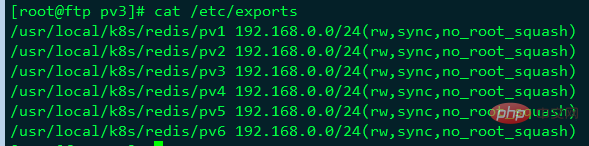
[root@ftp pv3]# cat /etc/exports /usr/local/k8s/redis/pv1 192.168.0.0/24(rw,sync,no_root_squash) /usr/local/k8s/redis/pv2 192.168.0.0/24(rw,sync,no_root_squash) /usr/local/k8s/redis/pv3 192.168.0.0/24(rw,sync,no_root_squash) /usr/local/k8s/redis/pv4 192.168.0.0/24(rw,sync,no_root_squash) /usr/local/k8s/redis/pv5 192.168.0.0/24(rw,sync,no_root_squash) /usr/local/k8s/redis/pv6 192.168.0.0/24(rw,sync,no_root_squash)
 対応するディレクトリを作成します
対応するディレクトリを作成します
[root@ftp quizii]# mkdir -p /usr/local/k8s/redis/pv{1..6}systemctl restart rpcbind systemctl restart nfs systemctl enable nfs
[root@ftp pv3]# exportfs -v /usr/local/k8s/redis/pv1 192.168.0.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash) /usr/local/k8s/redis/pv2 192.168.0.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash) /usr/local/k8s/redis/pv3 192.168.0.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash) /usr/local/k8s/redis/pv4 192.168.0.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash) /usr/local/k8s/redis/pv5 192.168.0.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash) /usr/local/k8s/redis/pv6 192.168.0.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
yum -y install nfs-utils
[root@node2 ~]# showmount -e 192.168.0.222 Export list for 192.168.0.222: /usr/local/k8s/redis/pv6 192.168.0.0/24 /usr/local/k8s/redis/pv5 192.168.0.0/24 /usr/local/k8s/redis/pv4 192.168.0.0/24 /usr/local/k8s/redis/pv3 192.168.0.0/24 /usr/local/k8s/redis/pv2 192.168.0.0/24 /usr/local/k8s/redis/pv1 192.168.0.0/24
各 Redis ポッドには独自のデータを保存する独立した PV が必要なので、6 つの PV を含む pv.yaml ファイルを作成できます:
[root@master redis]# cat pv.yaml apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv1 spec: capacity: storage: 200M accessModes: - ReadWriteMany nfs: server: 192.168.0.222 path: "/usr/local/k8s/redis/pv1" --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-vp2 spec: capacity: storage: 200M accessModes: - ReadWriteMany nfs: server: 192.168.0.222 path: "/usr/local/k8s/redis/pv2" --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv3 spec: capacity: storage: 200M accessModes: - ReadWriteMany nfs: server: 192.168.0.222 path: "/usr/local/k8s/redis/pv3" --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv4 spec: capacity: storage: 200M accessModes: - ReadWriteMany nfs: server: 192.168.0.222 path: "/usr/local/k8s/redis/pv4" --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv5 spec: capacity: storage: 200M accessModes: - ReadWriteMany nfs: server: 192.168.0.222 path: "/usr/local/k8s/redis/pv5" --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv6 spec: capacity: storage: 200M accessModes: - ReadWriteMany nfs: server: 192.168.0.222 path: "/usr/local/k8s/redis/pv6"
[root@master redis]#kubectl create -f pv.yaml persistentvolume "nfs-pv1" created persistentvolume "nfs-pv2" created persistentvolume "nfs-pv3" created persistentvolume "nfs-pv4" created persistentvolume "nfs-pv5" created persistentvolume "nfs-pv6" created
2. Configmap の作成 ここでは、Redis 構成ファイルを Configmap に直接変換でき、これは構成を読み取るためのより便利な方法です。 。構成ファイル redis.conf は次のとおりです。
[root@master redis]# cat redis.conf appendonly yes cluster-enabled yes cluster-config-file /var/lib/redis/nodes.conf cluster-node-timeout 5000 dir /var/lib/redis port 6379
kubectl create configmap redis-conf --from-file=redis.conf
[root@master redis]# kubectl describe cm redis-conf Name: redis-conf Namespace: default Labels: <none> Annotations: <none> Data ==== redis.conf: ---- appendonly yes cluster-enabled yes cluster-config-file /var/lib/redis/nodes.conf cluster-node-timeout 5000 dir /var/lib/redis port 6379 Events: <none></none></none></none>
3. ヘッドレス サービスの作成 ヘッドレス サービスは、StatefulSet が安定したネットワーク識別を実現するための基盤であり、事前に作成する必要があります。次のようにファイル headless-service.yml を準備します:
[root@master redis]# cat headless-service.yaml apiVersion: v1 kind: Service metadata: name: redis-service labels: app: redis spec: ports: - name: redis-port port: 6379 clusterIP: None selector: app: redis appCluster: redis-cluster
kubectl create -f headless-service.yml
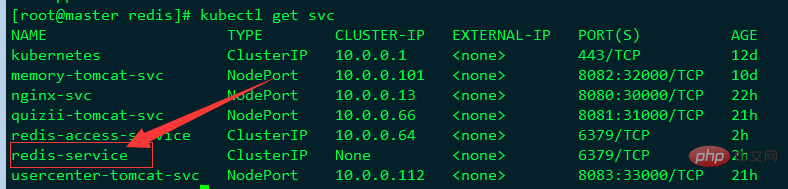 サービス名が redis-service であることがわかります。およびそのクラスター - IP は None であり、これが「ヘッドレス」サービスであることを示します。
サービス名が redis-service であることがわかります。およびそのクラスター - IP は None であり、これが「ヘッドレス」サービスであることを示します。
4.创建Redis 集群节点
创建好Headless service后,就可以利用StatefulSet创建Redis 集群节点,这也是本文的核心内容。我们先创建redis.yml文件:
[root@master redis]# cat redis.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: redis-app spec: serviceName: "redis-service" replicas: 6 template: metadata: labels: app: redis appCluster: redis-cluster spec: terminationGracePeriodSeconds: 20 affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - redis topologyKey: kubernetes.io/hostname containers: - name: redis image: redis command: - "redis-server" args: - "/etc/redis/redis.conf" - "--protected-mode" - "no" resources: requests: cpu: "100m" memory: "100Mi" ports: - name: redis containerPort: 6379 protocol: "TCP" - name: cluster containerPort: 16379 protocol: "TCP" volumeMounts: - name: "redis-conf" mountPath: "/etc/redis" - name: "redis-data" mountPath: "/var/lib/redis" volumes: - name: "redis-conf" configMap: name: "redis-conf" items: - key: "redis.conf" path: "redis.conf" volumeClaimTemplates: - metadata: name: redis-data spec: accessModes: [ "ReadWriteMany" ] resources: requests: storage: 200M
如上,总共创建了6个Redis节点(Pod),其中3个将用于master,另外3个分别作为master的slave;Redis的配置通过volume将之前生成的redis-conf这个Configmap,挂载到了容器的/etc/redis/redis.conf;Redis的数据存储路径使用volumeClaimTemplates声明(也就是PVC),其会绑定到我们先前创建的PV上。
这里有一个关键概念——Affinity,请参考官方文档详细了解。其中,podAntiAffinity表示反亲和性,其决定了某个pod不可以和哪些Pod部署在同一拓扑域,可以用于将一个服务的POD分散在不同的主机或者拓扑域中,提高服务本身的稳定性。
而PreferredDuringSchedulingIgnoredDuringExecution 则表示,在调度期间尽量满足亲和性或者反亲和性规则,如果不能满足规则,POD也有可能被调度到对应的主机上。在之后的运行过程中,系统不会再检查这些规则是否满足。
在这里,matchExpressions规定了Redis Pod要尽量不要调度到包含app为redis的Node上,也即是说已经存在Redis的Node上尽量不要再分配Redis Pod了。但是,由于我们只有三个Node,而副本有6个,因此根据PreferredDuringSchedulingIgnoredDuringExecution,这些豌豆不得不得挤一挤,挤挤更健康~
另外,根据StatefulSet的规则,我们生成的Redis的6个Pod的hostname会被依次命名为 $(statefulset名称)-$(序号) 如下图所示:
[root@master redis]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE redis-app-0 1/1 Running 0 2h 172.17.24.3 192.168.0.144 <none> redis-app-1 1/1 Running 0 2h 172.17.63.8 192.168.0.148 <none> redis-app-2 1/1 Running 0 2h 172.17.24.8 192.168.0.144 <none> redis-app-3 1/1 Running 0 2h 172.17.63.9 192.168.0.148 <none> redis-app-4 1/1 Running 0 2h 172.17.24.9 192.168.0.144 <none> redis-app-5 1/1 Running 0 2h 172.17.63.10 192.168.0.148 <none></none></none></none></none></none></none>
如上,可以看到这些Pods在部署时是以{0…N-1}的顺序依次创建的。注意,直到redis-app-0状态启动后达到Running状态之后,redis-app-1 才开始启动。
同时,每个Pod都会得到集群内的一个DNS域名,格式为$(podname).$(service name).$(namespace).svc.cluster.local ,也即是:
redis-app-0.redis-service.default.svc.cluster.local redis-app-1.redis-service.default.svc.cluster.local ...以此类推...
在K8S集群内部,这些Pod就可以利用该域名互相通信。我们可以使用busybox镜像的nslookup检验这些域名:
[root@master redis]# kubectl exec -ti busybox -- nslookup redis-app-0.redis-service Server: 10.0.0.2 Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local Name: redis-app-0.redis-service Address 1: 172.17.24.3
可以看到, redis-app-0的IP为172.17.24.3。当然,若Redis Pod迁移或是重启(我们可以手动删除掉一个Redis Pod来测试),IP是会改变的,但是Pod的域名、SRV records、A record都不会改变。
另外可以发现,我们之前创建的pv都被成功绑定了:
[root@master redis]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE nfs-pv1 200M RWX Retain Bound default/redis-data-redis-app-2 3h nfs-pv3 200M RWX Retain Bound default/redis-data-redis-app-4 3h nfs-pv4 200M RWX Retain Bound default/redis-data-redis-app-5 3h nfs-pv5 200M RWX Retain Bound default/redis-data-redis-app-1 3h nfs-pv6 200M RWX Retain Bound default/redis-data-redis-app-0 3h nfs-vp2 200M RWX Retain Bound default/redis-data-redis-app-3 3h
5.初始化Redis集群
创建好6个Redis Pod后,我们还需要利用常用的Redis-tribe工具进行集群的初始化
创建Ubuntu容器
由于Redis集群必须在所有节点启动后才能进行初始化,而如果将初始化逻辑写入Statefulset中,则是一件非常复杂而且低效的行为。这里,本人不得不称赞一下原项目作者的思路,值得学习。也就是说,我们可以在K8S上创建一个额外的容器,专门用于进行K8S集群内部某些服务的管理控制。
这里,我们专门启动一个Ubuntu的容器,可以在该容器中安装Redis-tribe,进而初始化Redis集群,执行:
kubectl run -it ubuntu --image=ubuntu --restart=Never /bin/bash
我们使用阿里云的Ubuntu源,执行:
root@ubuntu:/# cat > /etc/apt/sources.list EOF
成功后,原项目要求执行如下命令安装基本的软件环境:
apt-get update apt-get install -y vim wget python2.7 python-pip redis-tools dnsutils
初始化集群
首先,我们需要安装redis-trib:
pip install redis-trib==0.5.1
然后,创建只有Master节点的集群:
redis-trib.py create \ `dig +short redis-app-0.redis-service.default.svc.cluster.local`:6379 \ `dig +short redis-app-1.redis-service.default.svc.cluster.local`:6379 \ `dig +short redis-app-2.redis-service.default.svc.cluster.local`:6379
其次,为每个Master添加Slave
redis-trib.py replicate \ --master-addr `dig +short redis-app-0.redis-service.default.svc.cluster.local`:6379 \ --slave-addr `dig +short redis-app-3.redis-service.default.svc.cluster.local`:6379 redis-trib.py replicate \ --master-addr `dig +short redis-app-1.redis-service.default.svc.cluster.local`:6379 \ --slave-addr `dig +short redis-app-4.redis-service.default.svc.cluster.local`:6379 redis-trib.py replicate \ --master-addr `dig +short redis-app-2.redis-service.default.svc.cluster.local`:6379 \ --slave-addr `dig +short redis-app-5.redis-service.default.svc.cluster.local`:6379
至此,我们的Redis集群就真正创建完毕了,连到任意一个Redis Pod中检验一下:
[root@master redis]# kubectl exec -it redis-app-2 /bin/bash root@redis-app-2:/data# /usr/local/bin/redis-cli -c 127.0.0.1:6379> cluster nodes 5d3e77f6131c6f272576530b23d1cd7592942eec 172.17.24.3:6379@16379 master - 0 1559628533000 1 connected 0-5461 a4b529c40a920da314c6c93d17dc603625d6412c 172.17.63.10:6379@16379 master - 0 1559628531670 6 connected 10923-16383 368971dc8916611a86577a8726e4f1f3a69c5eb7 172.17.24.9:6379@16379 slave 0025e6140f85cb243c60c214467b7e77bf819ae3 0 1559628533672 4 connected 0025e6140f85cb243c60c214467b7e77bf819ae3 172.17.63.8:6379@16379 master - 0 1559628533000 2 connected 5462-10922 6d5ee94b78b279e7d3c77a55437695662e8c039e 172.17.24.8:6379@16379 myself,slave a4b529c40a920da314c6c93d17dc603625d6412c 0 1559628532000 5 connected 2eb3e06ce914e0e285d6284c4df32573e318bc01 172.17.63.9:6379@16379 slave 5d3e77f6131c6f272576530b23d1cd7592942eec 0 1559628533000 3 connected 127.0.0.1:6379> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:6 cluster_stats_messages_ping_sent:14910 cluster_stats_messages_pong_sent:15139 cluster_stats_messages_sent:30049 cluster_stats_messages_ping_received:15139 cluster_stats_messages_pong_received:14910 cluster_stats_messages_received:30049 127.0.0.1:6379>
另外,还可以在NFS上查看Redis挂载的数据:
[root@ftp pv3]# ll /usr/local/k8s/redis/pv3 total 12 -rw-r--r-- 1 root root 92 Jun 4 11:36 appendonly.aof -rw-r--r-- 1 root root 175 Jun 4 11:36 dump.rdb -rw-r--r-- 1 root root 794 Jun 4 11:49 nodes.conf
6.创建用于访问Service
前面我们创建了用于实现StatefulSet的Headless Service,但该Service没有Cluster Ip,因此不能用于外界访问。所以,我们还需要创建一个Service,专用于为Redis集群提供访问和负载均衡:
[root@master redis]# cat redis-access-service.yaml apiVersion: v1 kind: Service metadata: name: redis-access-service labels: app: redis spec: ports: - name: redis-port protocol: "TCP" port: 6379 targetPort: 6379 selector: app: redis appCluster: redis-cluster
如上,该Service名称为 redis-access-service,在K8S集群中暴露6379端口,并且会对labels name为app: redis或appCluster: redis-cluster的pod进行负载均衡。
创建后查看:
[root@master redis]# kubectl get svc redis-access-service -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR redis-access-service ClusterIP 10.0.0.64 <none> 6379/TCP 2h app=redis,appCluster=redis-cluster</none>
如上,在K8S集群中,所有应用都可以通过10.0.0.64 :6379来访问Redis集群。当然,为了方便测试,我们也可以为Service添加一个NodePort映射到物理机上,这里不再详细介绍。
五、测试主从切换
在K8S上搭建完好Redis集群后,我们最关心的就是其原有的高可用机制是否正常。这里,我们可以任意挑选一个Master的Pod来测试集群的主从切换机制,如redis-app-0:
[root@master redis]# kubectl get pods redis-app-0 -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE redis-app-1 1/1 Running 0 3h 172.17.24.3 192.168.0.144 <none></none>
进入redis-app-0查看:
[root@master redis]# kubectl exec -it redis-app-0 /bin/bash root@redis-app-0:/data# /usr/local/bin/redis-cli -c 127.0.0.1:6379> role 1) "master" 2) (integer) 13370 3) 1) 1) "172.17.63.9" 2) "6379" 3) "13370" 127.0.0.1:6379>
如上可以看到,app-0为master,slave为172.17.63.9即redis-app-3。
接着,我们手动删除redis-app-0:
[root@master redis]# kubectl delete pod redis-app-0 pod "redis-app-0" deleted [root@master redis]# kubectl get pod redis-app-0 -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE redis-app-0 1/1 Running 0 4m 172.17.24.3 192.168.0.144 <none></none>
我们再进入redis-app-0内部查看:
[root@master redis]# kubectl exec -it redis-app-0 /bin/bash root@redis-app-0:/data# /usr/local/bin/redis-cli -c 127.0.0.1:6379> role 1) "slave" 2) "172.17.63.9" 3) (integer) 6379 4) "connected" 5) (integer) 13958
如上,redis-app-0变成了slave,从属于它之前的从节点172.17.63.9即redis-app-3。
六、疑问
至此,大家可能会疑惑,那为什么没有使用稳定的标志,Redis Pod也能正常进行故障转移呢?这涉及了Redis本身的机制。因为,Redis集群中每个节点都有自己的NodeId(保存在自动生成的nodes.conf中),并且该NodeId不会随着IP的变化和变化,这其实也是一种固定的网络标志。也就是说,就算某个Redis Pod重启了,该Pod依然会加载保存的NodeId来维持自己的身份。我们可以在NFS上查看redis-app-1的nodes.conf文件:
[root@k8s-node2 ~]# cat /usr/local/k8s/redis/pv1/nodes.conf 96689f2018089173e528d3a71c4ef10af68ee462 192.168.169.209:6379@16379 slave d884c4971de9748f99b10d14678d864187a9e5d3 0 1526460952651 4 connected237d46046d9b75a6822f02523ab894928e2300e6 192.168.169.200:6379@16379 slave c15f378a604ee5b200f06cc23e9371cbc04f4559 0 1526460952651 1 connected
c15f378a604ee5b200f06cc23e9371cbc04f4559 192.168.169.197:6379@16379 master - 0 1526460952651 1 connected 10923-16383d884c4971de9748f99b10d14678d864187a9e5d3 192.168.169.205:6379@16379 master - 0 1526460952651 4 connected 5462-10922c3b4ae23c80ffe31b7b34ef29dd6f8d73beaf85f 192.168.169.198:6379@16379 myself,slave c8a8f70b4c29333de6039c47b2f3453ed11fb5c2 0 1526460952565 3 connected
c8a8f70b4c29333de6039c47b2f3453ed11fb5c2 192.168.169.201:6379@16379 master - 0 1526460952651 6 connected 0-5461vars currentEpoch 6 lastVoteEpoch 4
如上,第一列为NodeId,稳定不变;第二列为IP和端口信息,可能会改变。
这里,我们介绍NodeId的两种使用场景:
当某个Slave Pod断线重连后IP改变,但是Master发现其NodeId依旧, 就认为该Slave还是之前的Slave。
当某个Master Pod下线后,集群在其Slave中选举重新的Master。待旧Master上线后,集群发现其NodeId依旧,会让旧Master变成新Master的slave。
对于这两种场景,大家有兴趣的话还可以自行测试,注意要观察Redis的日志。
以上がK8s での Redis クラスターのデプロイメントの紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1658
1658
 14
1415
52
1309
25
1257
29
1231
24
14
1415
52
1309
25
1257
29
1231
24

 k8s サービス springboot プロジェクト アプリケーションをアップグレードする際の 502 エラーを解決する方法
May 11, 2023 pm 10:28 PM
k8s サービス springboot プロジェクト アプリケーションをアップグレードする際の 502 エラーを解決する方法
May 11, 2023 pm 10:28 PM
小さなステップと迅速な反復の開発モデルがますます多くのインターネット企業で認識され、採用されるにつれて、アプリケーションの変更とアップグレードの頻度はますます高くなっています。さまざまなアップグレード ニーズに対応し、アップグレード プロセスがスムーズに進むようにするために、一連の導入およびリリース モデルが誕生しました。シャットダウン リリース - アプリケーション インスタンスの古いバージョンを完全に停止してから、新しいバージョンをリリースします。このリリース モデルは主に、新バージョンと旧バージョンの非互換性と共存できない問題を解決することを目的としていますが、一定期間サービスが完全に利用できなくなるという欠点があります。ブルーグリーン リリース - 同数の新しいバージョンと古いバージョンのアプリケーション インスタンスを同時にオンラインでデプロイします。新しいバージョンがテストに合格すると、トラフィックはすぐに新しいサービス インスタンスに切り替えられます。この公開モデルは、ダウンタイム公開時にサービスが完全に利用できないという問題を解決しますが、比較的大規模な問題が発生します。
 ThinkPHP6 を使用した Redis クラスターの実装
Jun 20, 2023 am 08:36 AM
ThinkPHP6 を使用した Redis クラスターの実装
Jun 20, 2023 am 08:36 AM
インターネットの急速な発展に伴い、高い同時実行性の問題がますます顕著になってきました。この問題に対応するために、Redis の登場が重要な解決策となっており、従来のリレーショナル データベースにおけるメモリの読み書きによる過剰な読み書きの負荷の問題を解決します。ただし、単一ノード Redis は、同時実行性が高い状況では依然としてパフォーマンスのボトルネックがあるため、Redis クラスターを使用する必要があります。この記事では、ThinkPHP6 を使用して Redis クラスターを実装する方法について説明します。 1. Redis Cluster の概要 Redis Cluster は、Redis が提供する公式クラスターです。

 k8s に Redis クラスターをデプロイする方法
May 31, 2023 pm 05:25 PM
k8s に Redis クラスターをデプロイする方法
May 31, 2023 pm 05:25 PM
redis クラスターの構築 1.1 redis-cli を使用してクラスターを作成します #redis ポッドに対応する ipkubectlgetpod-njxbp-owide を表示します>NAMEREADYSTATUSRESARTSAGEIPNODENOMINATEDNODEREADINESSGATESredis-01/1Running018h10.168.235.196k8s-masterredis-11/1Running018h10.168。 235.225k 8s-masterredis-21 /1実行中018h10.168 。
 Redis を介して PHP データ キャッシュのクラスター デプロイメントを実装するにはどうすればよいですか?
Aug 10, 2023 am 08:13 AM
Redis を介して PHP データ キャッシュのクラスター デプロイメントを実装するにはどうすればよいですか?
Aug 10, 2023 am 08:13 AM
Redis を介して PHP データ キャッシュのクラスター デプロイメントを実装するにはどうすればよいですか?はじめに: PHP アプリケーションが高い同時実行性と大規模なトラフィックに直面すると、データベースのパフォーマンスのボトルネックが発生することがよくありますが、このとき、キャッシュ テクノロジを使用すると、システムのパフォーマンスと同時実行性を大幅に向上させることができます。 Redis は、高性能のメモリ内キー/値データベースとして、キャッシュ ソリューションの実装に広く使用されています。この記事では、パフォーマンスとスケーラビリティをさらに向上させるために、Redis を介して PHP データ キャッシュのクラスター デプロイメントを実装する方法を紹介します。 1. Redis Cluster Redis の概要
 Springboot プロジェクトを k8s にデプロイする方法
May 15, 2023 am 10:04 AM
Springboot プロジェクトを k8s にデプロイする方法
May 15, 2023 am 10:04 AM
Springboot を k8s にデプロイする手順 Springboot プロジェクトはイメージをパッケージ化し、イメージ ウェアハウスにデプロイします。プライベート イメージ ウェアハウスにログインします。イメージをプルします。デプロイメントを作成します。サービス アクセス ポートを公開します。シークレットを作成します。プライベート イメージ ウェアハウスにログインします。シークレットを作成し、docker レジストリの認証情報を保存する必要があります。シークレットを作成します~$kubectlcreatesecretdocker-registryfdf-docker. -secret--docker-server=registry.cn-chengdu.aliyuncs.com--docker-ユーザー名=176
 Javaプロジェクトをk8sにデプロイする方法
May 15, 2023 pm 06:07 PM
Javaプロジェクトをk8sにデプロイする方法
May 15, 2023 pm 06:07 PM
はじめに Java プロジェクトでは、開発およびデバッグのプロセス中にさまざまな環境にインストールおよびデプロイする必要があります。これまで、仮想マシンのデプロイメントを使用するときは、マシン上でコマンドを実行するか、Jenkins スクリプトを構成することによってデプロイメントを自動化していました。ただし、コンテナ環境での高可用性プロジェクトのインストールと展開には、コンテナ化テクノロジと k8s のスケジューリングと実行を使用する必要があります。一般に、正式な環境では、コンテナ化されたデプロイメントを形成するために次の部分が必要になります: コンテナ環境 dockerContainerdk8s クラスター k8s 管理システム KubeSoheredashboard (k8s 独自の管理システム) ミラー ウェアハウス Dockerhub registryharbor コード ウェアハウス githubgitlab
 Redis および Node.js クラスター ソリューション: 高可用性を実現する方法
Jul 29, 2023 pm 05:42 PM
Redis および Node.js クラスター ソリューション: 高可用性を実現する方法
Jul 29, 2023 pm 05:42 PM
Redis および Node.js のクラスター ソリューション: 高可用性を実現する方法 はじめに: インターネットの急速な発展に伴い、データ処理はますます大規模かつ複雑になってきました。システムの高可用性とスケーラビリティを確保するには、分散クラスター アーキテクチャを使用して、大量のデータの保存と処理のニーズに対処する必要があります。高性能のインメモリ データベースとしての Redis を、バックエンド プログラミング言語としての Node.js と組み合わせることで、可用性の高い分散クラスター ソリューションを構築できます。この記事ではRedisとNode.jsを使って実装する方法を紹介します。
