

ビッグデータの核心とは何か

ビッグデータの中核は予測です。ビッグデータの本質は問題を解決することであり、ビッグデータの中核となる価値は予測です。ビッグデータとは、大量のデータに数学的アルゴリズムを適用して、物事が起こる可能性を予測することです。ビッグデータ予測とは、ビッグデータに基づいて未来を予測することです予測モデル、何かが起こる確率。

このチュートリアルの動作環境: Windows 7 システム、Dell G3 コンピューター。
ビッグデータの中核は予測です。それは人工知能の一部、あるいはむしろ機械学習の一種であると考えられることがよくあります。しかし、この定義は誤解を招きます。ビッグデータは、機械に人間と同じように考えるように教えることではありません。
逆に、数学的アルゴリズムを大量のデータに適用して、何かが起こる可能性を予測します。電子メールがスパムとして除外される確率、入力された「て」が「あの」であるはずの確率、歩道橋を歩く人の軌跡と速度に基づいて人が時間内に道路を横断できる確率はすべて、ビッグデータが予測できる範囲内で。もちろん、人が時間内に道路を横断できれば、車はその人が歩道橋を歩くときにわずかに速度を落とすだけで済みます。これらの予測システムの成功の鍵は、大量のデータに基づいていることです。さらに、システムが受信するデータが増えるにつれて、最適な信号とパターンを自動的に検索してシステム自体を改善できるほど賢くなる可能性があります。
ビッグデータ予測 (ビッグデータ コア アプリケーション)
ビッグデータ予測は、従来の予測を組み合わせたビッグデータのコア アプリケーションです。 「ライブテスト」。ビッグ データ予測の利点は、非常に困難な予測問題を、従来の小さなデータ セットでは到底及ばない比較的単純な記述問題に変換できることです。予測の観点から見ると、ビッグデータ予測によって得られた結果は、実際のビジネスに対処するために使用される単純かつ客観的な結論だけでなく、ビジネス運営の意思決定にも使用できます。
1. 予測はビッグ データの中核的価値です
ビッグ データの本質は問題を解決することです。ビッグ データの中核的価値は予測にあり、事業運営の根幹も予測に基づいた正しい判断です。ビッグデータのアプリケーションについて話すとき、最も一般的なアプリケーション ケースは、「株式市場の予測」、「インフルエンザの予測」、「消費者行動の予測」などです。
ビッグデータ予測は、ビッグデータと予測モデルに基づいて、将来何かが起こる確率を予測します。ビッグデータと従来のデータ分析の最大の違いは、分析を「起こった過去と向き合う」から「これから起ころうとしている未来と向き合う」へとシフトすることです。
ビッグ データ予測の論理的基礎は、すべての非従来的な変化には事前に兆候があり、すべてに追跡すべき痕跡があるということです。兆候と変化の間のパターンが見つかれば、予測を進めることができます。ビッグ データの予測は、何かが確実に起こると判断することはできず、むしろ、イベントが起こる確率を与えることに重点を置いています。
継続的な実験の繰り返しとビッグデータの蓄積により、人間はさまざまなパターンを継続的に発見し、未来を予測できるようになりました。ビッグデータを使用して起こり得る災害を予測すること、ビッグデータを使用してがんの考えられる原因を分析し、治療法を見つけることはすべて、将来人類に利益をもたらす可能性のある取り組みです。
たとえば、ロサンゼルス市警察やカリフォルニア大学は犯罪の発生を予測するためにビッグデータを使用し、Google Flu Trendsは鳥インフルエンザの蔓延を予測するために検索キーワードを使用し、MITは携帯電話を使用しています。位置情報や交通情報などの都市計画を行い、気象庁は最近の気象状況と衛星雲画像を照合し、将来の気象状況をより正確に判断します。
2. ビッグデータ予測に関する考え方の変化
これまで、人々の意思決定は主に構造化データの 20% に依存していましたが、ビッグデータ予測では、さらに 80% の非構造化データは意思決定に使用されます。ビッグ データ予測では、より多くのデータ次元、より高速なデータ頻度、より広いデータ幅が実現されます。スモールデータの時代と比較して、ビッグデータ予測の考え方には、サンプリングではなく実際のサンプル、精度ではなく予測効率、因果関係ではなく相関関係という 3 つの大きな変化があります。
1) サンプリングではなく実際のサンプル
小規模データの時代、すべてのサンプルを入手する手段がなかったため、人々は「ランダム調査データ」という方法を発明しました。理論的には、サンプルがよりランダムに抽出されるほど、サンプルはサンプル全体をより代表するものになります。しかし、問題は、ランダムなサンプルを取得するのに非常に費用と時間がかかることです。人口調査はその代表的な例であり、無作為調査では時間と労力がかかりすぎるため、国が毎年人口調査を完了することは困難ですが、クラウドコンピューティングやビッグデータ技術の登場により、大量の人口調査を得ることが可能になりました。十分なサンプルデータ、さらには母集団全体さえあれば、データが可能になります。
2) 精度よりも効率
小規模データの時代では、サンプリング手法を使用するため、データ サンプルの特定の操作を非常に正確にする必要があります。そうしないと、 「わずかな違い、千マイルを逃した」たとえば、国勢調査で全サンプル1億人から無作為に1,000人を抽出した場合、1,000人で計算に誤りがあった場合、1億人に拡大するとその偏差は非常に大きくなります。しかし、完全なサンプルの場合、偏差はいくらでもあるので、それは増幅されません。
ビッグデータの時代では、厳密な正確性よりも、大まかな概要と開発コンテキストを迅速に取得することがはるかに重要です。場合によっては、大量の新しいタイプのデータがある場合でも、状況がどのように進んでいるかを把握できるため、精度はそれほど重要ではなくなります。ビッグデータに基づく単純なアルゴリズムは、小さなデータに基づく複雑なアルゴリズムよりも効果的です。データ分析の目的は単なるデータ分析ではなく意思決定であるため、タイムリーさも非常に重要です。
3) 因果関係ではなく相関関係
ビッグデータ研究は従来の論理的推論研究とは異なり、膨大な量のデータを統計的に検索、比較、クラスタリング、分類する必要があります。そしてデータの相関関係や相関関係に注意を払います。相関とは、2 つ以上の変数の値の間に何らかの規則性があることを意味します。相関関係には絶対的なものはなく、可能性があるだけです。ただし、相関関係が強い場合、相関関係が成功する確率は非常に高くなります。
相関関係は、現在を把握し、将来を予測するのに役立ちます。 A と B が同時に発生することが多い場合、A も発生することを予測するには B が発生することに注意するだけで済みます。
相関関係によれば、私たちの世界理解はもはや仮定に基づく必要はありませんが、この仮定とは、現象の生成メカニズムや内部メカニズムについて設定された仮定を指します。そのため、どの検索語がインフルエンザが流行している時期と場所を示しているか、航空会社が航空券の価格をどのように設定しているか、ウォルマートの顧客の料理の好みは何かなどについて推測する必要はありません。その代わりに、ビッグデータの相関分析を実行して、どの検索語がインフルエンザの蔓延を最もよく示しているか、航空券の価格が高騰するかどうか、ハリケーン中に家にいる人々が最も欲しがっている食べ物は何かなどを知ることができます。
ビッグデータのデータ駆動型相関分析は、仮定に基づいたエラーが発生しやすい手法を置き換えます。ビッグデータの相関分析手法は、より正確かつ高速で、バイアスの影響を受けにくくなっています。相関分析に基づく予測はビッグデータの中核です。
相関分析自体は非常に重要であり、因果関係を研究するための基礎にもなります。関連する可能性のあるものを特定することで、これに基づいてさらなる因果分析を行うことができます。因果関係がある場合は、さらに一歩進んでその理由を調べます。この便利なメカニズムにより、厳密な実験による因果分析のコストが削減されます。また、相関関係からいくつかの重要な変数を見つけることができ、因果関係を検証するための実験に使用できます。
3. ビッグデータ予測の代表的な応用分野
インターネットの普及によりビッグデータ予測アプリケーションの普及が促進され、国内外の事例をもとに以下のようなことが考えられます。 11 この分野はビッグデータ予測応用の中で最も有望な分野である。
1) 天気予報
天気予報は、ビッグデータ予測の代表的な応用分野です。天気予報の粒度は数日から数時間に短縮されており、適時性の要件が厳しくなっています。従来の膨大なデータをもとに計算を行っていれば、すでに明日が到来しており、結論が出た時点で予測は役に立たなくなりますが、ビッグデータ技術の発展により高速な計算能力が得られ、効率が大幅に向上しました。そして天気予報の正確さ。
2) スポーツイベントの予測
2014 年ワールドカップ期間中、Google、Baidu、Microsoft、Goldman Sachs などの企業が一斉に試合結果予測プラットフォームを立ち上げました。 Baidu の予測結果は最も注目を集めており、64 試合全体での予測精度は 67%、ノックアウト ラウンドに入った後の予測精度は 94% でした。これは、将来のスポーツイベントがビッグデータの予測によって制御されることを意味します。
Google ワールド カップの予測は、Opta Sports の膨大なイベント データに基づいて最終予測モデルを構築しています。 Baidu は過去 5 年間に世界中の 987 チーム (代表チームとクラブチームを含む) の 37,000 の試合データを検索し、
は中国の宝くじウェブサイト Lecai.com およびヨーロッパのベットフェア インデックス データ プロバイダーである Through とも協力しました。 SPdex社とのデータ連携により、ギャンブル市場から予測データをインポートし、199,972人のプレイヤーと1億1,200万件のデータを含む予測モデルを構築し、これに基づいて結果予測を行いました。
インターネット企業の成功体験から判断すると、スポーツイベントの過去のデータとインデックス会社との協力があれば、チャンピオンズリーグやNBAなどの他のイベントの予測も可能です。 。
3) 株式市場の予測
英国のワーウィック ビジネス スクールと米国のボストン大学物理学科が昨年実施した調査によると、Google でユーザーが検索する金融キーワードは、金融市場の方向性を予測できるようになり、それに応じて、投資戦略の収益率も 326% に達します。以前、一部の専門家はツイッターのブログ投稿のセンチメントから株式市場の変動を予測しようとした。
4) 市場価格予測
CPI は、発生した価格変動を特徴付けるために使用されますが、統計局のデータは信頼できるものではありません。ビッグデータは、人々が将来の価格動向を理解し、インフレや経済危機を事前に予測するのに役立つ可能性があります。最も典型的なケースは、ジャック・マー氏がアリババのB2Bビッグデータを通じてアジア金融危機を事前に知っていたケースだ。
特に航空券などの規格化された商品の場合、単一商品の価格を予測しやすくなります。「Qunar」が提供する「航空券カレンダー」は、おおよその価格がわかる価格予測機能です。数ヶ月以内に航空券が買える。
完全な競争市場では、商品の生産、チャネルコスト、およびおおよその粗利が比較的安定しているため、価格に関連する変数は比較的固定されており、商品の需要と供給の関係は電子メール上でリアルタイムに監視できます。 -コマースプラットフォームなので、価格を予測できます。予測結果に基づいて、購入時期の推奨事項を提供したり、利益を最大化するための動的な価格調整やマーケティング活動を実施するように販売者を誘導したりできます。
5) ユーザー行動予測
ユーザーの検索行動、閲覧行動、コメント履歴、個人情報などのデータに基づいて、インターネットビジネスは消費者の全体的なニーズを洞察し、対象商品の生産、改良、マーケティングを行います。 「ハウス・オブ・カード」は俳優とストーリーを選定し、百度はユーザーの好みに基づいて的確な広告とマーケティングを実施し、アリババは天猫ユーザーの特性に基づいて生産ライン向けにカスタマイズされた製品をパッケージ化し、アマゾンはユーザーのクリック行動を予測して商品を事前に出荷する。インターネット ユーザーの行動の予測から恩恵を受けることができます。図 1 に示すように。
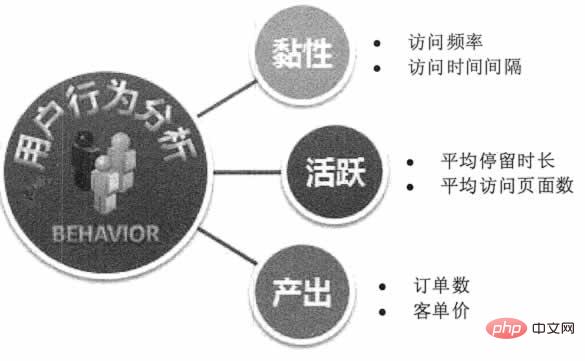
図 1 ユーザー行動の予測
センサー テクノロジーとモノのインターネットの開発の恩恵を受けて、オフラインのユーザー行動に関する洞察が生まれつつあります。無料の商用 Wi-Fi、iBeacon テクノロジー、カメラ画像モニタリング、屋内測位テクノロジー、NFC センサー ネットワーク、キューイング システムにより、ユーザーのオフライン移動、滞在、移動パターンなどのデータを検出し、正確なマーケティングや製品のカスタマイズを実行できます。
6) 人間の健康予測
伝統的な中国医学は、見て、嗅いで、尋ねたり聞いたりすることによって人体の隠れた慢性疾患を発見し、人がどのような症状を抱えているかを知ることさえできます。体質から未来を知る。体の物理的な兆候は特定の規則に従って変化し、慢性疾患が発生する前に人体にはすでにいくつかの持続的な異常が生じます。理論的には、ビッグデータがこのような異常を把握できれば、慢性疾患を予測できる可能性があります。
Nature News & Views は、人の血糖濃度が特定の食品によってどのような影響を受けるかという複雑な問題に関する Zeevi らの研究について報告しました。この研究は、腸内の微生物や生理学のその他の側面に基づいて個別化された食品の推奨を提供できる予測モデルを提案しており、現在の標準よりも正確に血糖反応を予測できます。写真2に示すように。
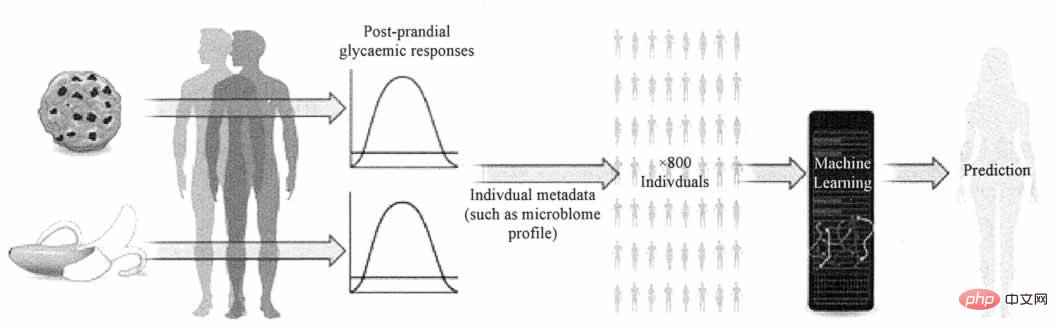
図 2 血糖濃度予測モデル
インテリジェントなハードウェアにより、慢性疾患のビッグデータ予測が可能になります。ウェアラブル デバイスとスマート ヘルス デバイスは、ネットワークが心拍数、体重、血中脂質、血糖、運動量、睡眠量などの人間の健康データを収集するのに役立ちます。これらのデータが正確かつ十分に包括的で、アルゴリズムを形成できる慢性疾患予測モデルがあれば、おそらく将来、これらのウェアラブル デバイスはユーザーに特定の慢性疾患に苦しむリスクを思い出させることになるでしょう。
7) 病気の流行予測
病気の流行予測とは、人々の検索条件や買い物行動などから大規模な疫病の発生の可能性を予測することをいい、最も古典的な「インフルエンザ予測」はこれに該当します。このカテゴリー。特定の地域から「インフルエンザ」と「イサティス ルート」の検索リクエストが増えている場合、そこでインフルエンザの傾向があると推測するのは自然です。
Baidu は疾病予測製品を発売しました。現在、国内のすべての省と、ほとんどの県レベルの市、区、郡の 4 つの疾病 (インフルエンザ、肝炎、結核、性感染症の状況を把握し、包括的なモニタリングを実施します。将来的には、百度疾病予測で監視される病気の種類は現在の 4 種類から 30 以上に拡大され、より一般的な病気や流行病がカバーされる予定です。ユーザーは、ローカルな予測結果に基づいて、的を絞った予防策を講じることができます。
8) 災害予測
気象予測は最も代表的な災害予測です。地震、洪水、高温、豪雨などの自然災害をビッグデータの力で事前に予測・情報化できれば、減災・予防・救援につながります。これまでのデータ収集方法は行き詰まりやコスト高などの問題がありましたが、IoT時代では安価なセンサーカメラや無線通信ネットワークを利用してリアルタイムにデータの監視・収集が可能となり、そして、ビッグデータ予測分析を使用して、自然災害のより正確な予測を実現します。
9) 環境変化予測
短期的なミクロな天気や災害の予測に加えて、長期的かつマクロ的な環境や生態系の変化の予測も行うことができます。森林や農地の面積の縮小、絶滅の危機に瀕した野生動物や植物、海岸線の上昇、温室効果は地球が直面している「慢性的な問題」です。地球の生態系や気象パターンの変化について人類が知るデータが増えれば増えるほど、将来の環境変化をモデル化し、悪い変化の発生を防ぐことが容易になります。ビッグデータは、人間がより多くの地球データを収集、保存、採掘するのに役立つと同時に、予測のためのツールも提供します。
10) 交通行動予測
交通行動予測とは、利用者や車両のLBS測位データに基づいて、走行する人や車両の個人や集団の特徴を分析し、交通行動を予測することを指します。運輸部門は、さまざまな時間帯のさまざまな道路の交通流を予測することで、インテリジェントな車両スケジュールを実行したり、潮汐レーンを適用したりすることができ、ユーザーは予測結果に基づいて渋滞確率が低い道路を選択できます。
Baidu の地図アプリケーションに基づく LBS 予測は、より広範囲をカバーします。春節期間中の人の移動傾向を予測して鉄道路線やルートの設定をガイドしたり、休暇中の景勝地の人の流れを予測して景勝地の選択をガイドしたり、百度ヒートマップを利用してユーザーに情報を提供したりすることもできる都市のビジネス街、動物園、その他の場所。人の流れは、ユーザーの旅行の選択やビジネスの場所の選択をガイドします。
11) エネルギー消費予測
リコウ州電力網運用センターは、カリフォルニア州の電力網の 80% 以上を管理し、毎年 2 億 8,900 万メガワットの電力を 3,500 万人のユーザーに供給しています。送電線の長さは 40,000 km。同センターでは、Space-Time Insightのインテリジェント管理ソフトウェアを活用し、気象、センサー、計測機器などのさまざまなデータソースからの膨大なデータを総合的に分析し、各地のエネルギー需要の変化を予測し、インテリジェントな電力配電を行い、電力供給のバランスをとります。ネットワーク全体のニーズやニーズを把握し、潜在的な危機に迅速に対応します。中国のスマートグリッド業界はすでに同様のビッグデータ予測アプリケーションを試している。
ビッグデータ予測は、上記11分野以外にも、不動産予測、雇用情勢予測、大学入試得点予測、選挙結果予測、オスカー賞予測、保険契約者のリスク評価、金融 借り手の返済能力評価などの分野において、人間は将来について定量的で説得力があり、検証可能な洞察を得る能力を備えており、ビッグデータ予測の魅力が解き放たれています。
関連知識の詳細については、FAQ 列をご覧ください。
以上がビッグデータの核心とは何かの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
PHPのビッグデータ構造処理スキル
May 08, 2024 am 10:24 AM
ビッグ データ構造の処理スキル: チャンキング: データ セットを分割してチャンクに処理し、メモリ消費を削減します。ジェネレーター: データ セット全体をロードせずにデータ項目を 1 つずつ生成します。無制限のデータ セットに適しています。ストリーミング: ファイルやクエリ結果を 1 行ずつ読み取ります。大きなファイルやリモート データに適しています。外部ストレージ: 非常に大規模なデータ セットの場合は、データをデータベースまたは NoSQL に保存します。
 2024 年の AEC/O 業界の 5 つの主要な開発トレンド
Apr 19, 2024 pm 02:50 PM
2024 年の AEC/O 業界の 5 つの主要な開発トレンド
Apr 19, 2024 pm 02:50 PM
AEC/O(Architecture, Engineering & Construction/Operation)とは、建設業界における建築設計、工学設計、建設、運営を提供する総合的なサービスを指します。 2024 年、AEC/O 業界は技術の進歩の中で変化する課題に直面しています。今年は先進技術の統合が見込まれ、設計、建設、運用におけるパラダイムシフトが到来すると予想されています。これらの変化に対応して、業界は急速に変化する世界のニーズに適応するために、作業プロセスを再定義し、優先順位を調整し、コラボレーションを強化しています。 AEC/O 業界の次の 5 つの主要なトレンドが 2024 年の主要テーマとなり、より統合され、応答性が高く、持続可能な未来に向けて進むことが推奨されます: 統合サプライ チェーン、スマート製造
 C++開発経験の共有:C++ビッグデータプログラミングの実践経験
Nov 22, 2023 am 09:14 AM
C++開発経験の共有:C++ビッグデータプログラミングの実践経験
Nov 22, 2023 am 09:14 AM
インターネット時代においてビッグデータは新たなリソースとなり、ビッグデータ分析技術の継続的な向上に伴い、ビッグデータプログラミングの需要がますます高まっています。広く使用されているプログラミング言語として、ビッグ データ プログラミングにおける C++ の独自の利点がますます顕著になってきています。以下では、C++ ビッグ データ プログラミングにおける私の実践的な経験を共有します。 1. 適切なデータ構造の選択 適切なデータ構造を選択することは、効率的なビッグ データ プログラムを作成する上で重要です。 C++ には、配列、リンク リスト、ツリー、ハッシュ テーブルなど、使用できるさまざまなデータ構造があります。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 Go言語にビッグデータフレームワークがない理由と解決策についてのディスカッション
Mar 29, 2024 pm 12:24 PM
Go言語にビッグデータフレームワークがない理由と解決策についてのディスカッション
Mar 29, 2024 pm 12:24 PM
今日のビッグデータ時代において、データの処理と分析はさまざまな産業の発展を支える重要な役割を果たしています。 Go言語は、開発効率が高くパフォーマンスに優れたプログラミング言語として、ビッグデータ分野で徐々に注目を集めています。しかし、Go 言語は Java や Python などの他の言語と比較してビッグ データ フレームワークのサポートが比較的不十分であり、一部の開発者に問題を引き起こしていました。この記事では、Go 言語にビッグ データ フレームワークが存在しない主な理由を調査し、対応する解決策を提案し、具体的なコード例で説明します。 1.Go言語
 AI、デジタルツイン、ビジュアライゼーション...2023 Yizhiwei 秋の製品発表会のハイライト!
Nov 14, 2023 pm 05:29 PM
AI、デジタルツイン、ビジュアライゼーション...2023 Yizhiwei 秋の製品発表会のハイライト!
Nov 14, 2023 pm 05:29 PM
Yizhiweiの2023年秋の新製品発表会は無事終了しました!カンファレンスのハイライトを一緒に振り返りましょう! 1. インテリジェントで包括的なオープン性がデジタルツインの生産性を高める Kangaroo Cloud の共同創設者で Yizhiwei の CEO である Ning Haiyuan 氏は開会の挨拶で次のように述べました: 「3 つのコア機能」「インテリジェントで包括的なオープン性」という 3 つのコアキーワードに焦点を当て、さらに「デジタルツインを生産力にする」という開発目標を提案しました。 2. EasyTwin: より使いやすい新しいデジタル ツイン エンジンを探索します。 1. 0.1 から 1.0 まで、デジタル ツイン フュージョン レンダリング エンジンを探索し続け、成熟した 3D 編集モード、便利なインタラクティブ ブループリント、大規模なモデル アセットを備えたより良いソリューションを実現します。
 入門ガイド: Go 言語を使用したビッグデータの処理
Feb 25, 2024 pm 09:51 PM
入門ガイド: Go 言語を使用したビッグデータの処理
Feb 25, 2024 pm 09:51 PM
オープンソースのプログラミング言語として、Go 言語は近年徐々に注目を集め、使用されるようになりました。そのシンプルさ、効率性、強力な同時処理機能によりプログラマーに好まれています。ビッグ データ処理の分野でも、Go 言語は大きな可能性を秘めており、大量のデータを処理し、パフォーマンスを最適化し、さまざまなビッグ データ処理ツールやフレームワークとうまく統合できます。この記事では、Go 言語によるビッグデータ処理の基本的な概念とテクニックをいくつか紹介し、具体的なコード例を通して Go 言語の使用方法を示します。
 C++ テクノロジーでのビッグ データ処理: インメモリ データベースを使用してビッグ データのパフォーマンスを最適化するには?
May 31, 2024 pm 07:34 PM
C++ テクノロジーでのビッグ データ処理: インメモリ データベースを使用してビッグ データのパフォーマンスを最適化するには?
May 31, 2024 pm 07:34 PM
ビッグ データ処理では、インメモリ データベース (Aerospike など) を使用すると、データがコンピュータ メモリに保存され、ディスク I/O ボトルネックが解消され、データ アクセス速度が大幅に向上するため、C++ アプリケーションのパフォーマンスが向上します。実際のケースでは、インメモリ データベースを使用した場合のクエリ速度が、ハードディスク データベースを使用した場合よりも数桁速いことが示されています。