

MySQLクエリ最適化の詳しい説明


1. 最適化の考え方と原則とは何ですか
1. 最適化が必要なクエリを最適化します
2. 最適化の位置付けオブジェクト パフォーマンスのボトルネック
3. 最適化目標を明確にする
4. Explain から始める
5. より多くのプロファイルを使用する
6. 常に小さな結果セットを使用して大きな結果セットを駆動する
7. インデックス作成を次のように使用します。可能な限り並べ替えを完了します
8. 必要なフィールド (列) のみを取り出します
9. 最も効果的なフィルタリング条件のみを使用します
10. 複雑な結合は可能な限り回避します
無料学習の推奨事項: #mysql ビデオ チュートリアル
1. 最適化が必要なクエリを最適化する
高同時実行性 (比較的) 低コストのクエリがシステム全体に及ぼす影響は、低同時実行性と高コストのクエリよりもはるかに大きくなります。2. 最適化オブジェクトのパフォーマンスのボトルネックを特定する
最適化が必要なクエリを取得した場合、まずクエリのボトルネックが次のとおりであるかどうかを判断する必要があります。 IO または CPU。消費量が多いのはデータベース アクセスですか、それともデータ操作 (グループ化や並べ替えなど) ですか?3. 明確な最適化目標
データベースの現在の全体的な状態を理解することで、データベースが耐えられる最大の圧力を知ることができます。最も悲観的な状況; クエリに関連するデータベース オブジェクトの情報を把握するには、最良の状態と最悪の状態でどれだけのリソースが消費されているかを知ることができます;
アプリケーション システムでのクエリの状態を知るには、クエリが占有できるリソースの量を分析でき、システム リソースの割合によって、クエリの効率が顧客エクスペリエンスにどの程度影響するかを知ることもできます。
4. Explain から開始
Explain では、このクエリがデータベースにどのような実行プランで実装されているかを知ることができます。まず目標が必要で、常に調整と試行を繰り返し、その結果がニーズを満たすかどうかを Explain を使用して検証することで、期待どおりの結果が得られます。5. 常に小さな結果セットを使用して大きな結果セットを駆動します
多くの人は、SQL を最適化するときに「小さなテーブルが大きなテーブルを駆動する##」を使用することを好みます # 」とありますが、この記述は厳密ではありません。 where 条件でフィルタリングされた後に大きなテーブルによって返される結果セットは、必ずしも小さなテーブルによって返される結果セットよりも大きいとは限らないため、この時点で大きなテーブルを使用して小さなテーブルを駆動すると、逆のパフォーマンス効果が発生します。得られる。 この結果も非常にわかりやすいのですが、MySQL には Join メソッドが Nested Loop の 1 つしかなく、MySQL の Join は入れ子ループによって実装されています。駆動される結果セットが大きくなるほど、より多くのループが必要となり、必然的に駆動テーブルへのアクセス数も多くなります。必要な論理 IO が非常に小さい場合でも、駆動テーブルにアクセスするたびに、ループの数が増加します。当然、総量はそれほど小さくなることはなく、各サイクルで必然的にCPUを消費するため、CPUの計算量も増加します。したがって、駆動テーブルを判断する基準としてテーブルのサイズのみを使用する場合、小さなテーブルをフィルタリングした後に残った結果セットが大きなテーブルの結果セットよりはるかに大きい場合、結果として必要なネストされたループでより多くのループが発生することになります。逆に、必要なサイクル数は少なくなり、IO および CPU 操作の総量も少なくなります。さらに、Oracle のハッシュ結合などの非ネスト ループ結合アルゴリズムの場合でも、小さな結果セットが大きな結果セットを駆動するのに最適な選択肢です。 したがって、結合クエリを最適化するときの最も基本的な原則は、「小さな結果セットが大きな結果セットを駆動する」ということです。この原則を通じて、ネストされたループ内のループ数を減らし、総 IO 量と IO の数を減らすことができます。 CPU の動作。可能な限りインデックス内の並べ替えを完了します
どのようなクエリでも、返されたデータは通過する必要がありますネットワークパケット クライアントに送信する際、取り出すカラム数が多ければ当然送信するデータ量も多くなり、ネットワーク帯域やネットワーク送信バッファの面で無駄が生じます。
7. 最も効果的なフィルタリング条件のみを使用しますたとえば、ユーザー テーブル user には id や nick_name などのフィールドがあり、インデックスは id と nike_name です。以下に 2 つのクエリ ステートメントを示します。
#1 select * from user where id = 1 and nick_name = 'zs'; #2 selet * from user where id = 1
2 つのクエリで得られる結果は同じですが、最初のステートメントで使用されるインデックスは 2 番目のステートメントよりも多くのスペースを占有します。より多くのスペースを占めるということは、より多くのデータを読み取る必要があることも意味します。つまり、2のクエリ文が最適なクエリです。
8. 複雑な結合クエリを避ける クエリに含まれるテーブルが増えるほど、ロックする必要があるリソースも増えます。つまり、Join ステートメントが複雑になるほど、より多くのリソースをロックする必要があり、より多くの他のスレッドをブロックする必要があります。逆に、より複雑なクエリ ステートメントを複数の単純なクエリ ステートメントに分割し、それらを段階的に実行すると、毎回ロックされるリソースが少なくなり、ブロックされる他のスレッドも少なくなります。 2. Explain と Profiling を使用する 1. Explain を使用する 各種情報表示 2、Profiling使用 该工具可以获取一条Query在整个执行过程中多种资源消耗情况,如CPU,IO,IPC,SWAP等,以及发生PAGE FAULTS, CONTEXT SWITCHE等等,同时还能得到该Query执行过程中MySQL所调用的各个函数在源文件中的位置。 1、开启profiling参数 1-开启,0-关闭 2、然后执行一条Query 三、合理利用索引 1、什么是索引 简单来说,在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或者多列的值进行排序的一种存储结构。就像书的目录,可以根据目录中的页码快速找到需要的内容。 2、索引的数据结构 一般来说,MySQL中的B-Tree索引的物理文件大多数都是以平衡树的结构来存储的,也就是所有实际需要存储的数据都存储于树的叶子节点,二到任何一个叶子节点的最短路径的长度都是完全相同的。MySQL中的存储引擎也会稍作改造,比如Innodb存储引擎的B-Tree索引实际上使用的存储结构是B+Tree,在每个叶子节点存储了索引键相关信息之外,还存储了指向相邻的叶子节点的指针信息,这是为了加快检索多个相邻的叶子节点的效率。 3、索引的利弊 优点: 提高数据的检索速度,降低数据库的IO成本; 4、如何判断是否需要建立索引 上面说了索引的利弊,我们知道索引并不是越多越好,索引也会带来副作用。那么我们该怎么判断是否需要建立索引呢? 5、单索引还是组合索引? 一般的なアプリケーション シナリオでは、フィルター フィールドの 1 つがほとんどのシナリオでデータの 90% 以上をフィルターでき、他のフィルター フィールドが頻繁に更新される限り、通常は結合インデックスを作成することを好みます。特にこれは同時実行性が高いシナリオでは特に当てはまります。同時実行性が増加すると、クエリごとに少量の IO 消費量が節約されたとしても、実行量が非常に大きいため、節約されるリソースの合計量は依然として非常に大きくなるからです。 6. インデックスの選択 1. 単一キー インデックスの場合は、現在のクエリに最適なインデックスをフィルターしてみてください。 7. MySQL インデックスの制限 1. MyISAM ストレージ エンジンのインデックス キーの長さの合計は 1000 バイトを超えることはできません; #8. 結合原則と最適化 結合原理: MySQL には、結合アルゴリズムが 1 つだけあります。それは有名な入れ子ループです。実際には、駆動テーブルの結果セットをループの基本データとして使用し、そのデータをループの基本データとして使用します。結果セットをフィルター条件として次のテーブルのデータを 1 つずつクエリし、その結果をマージします。最近の参加者がまだいる場合は、以前の最近の結果セットがサイクルの基本データとして使用され、サイクルが再度横断されます。 9. ORDER BY 最適化 MySQL では、ORDER BY 実装は次の 2 種類のみです: 2 , ストレージ エンジンに返されたデータを MySQL 並べ替えアルゴリズムを通じて並べ替え、並べ替えられたデータをクライアントに返します。 インデックス ソートを使用するのが最良の方法ですが、インデックス Lin Yong がない場合、MySQL は主に 2 つのアルゴリズムを実装します。 1. フィルタリング条件を満たすソートに使用されるフィールドを取り出します。行データを直接検索できる行ポインタ情報。ソートバッファ内で実際のソート操作を実行し、その後、ソートされたデータを使用して行ポインタ情報に従ってテーブルに戻り、クライアントが要求した他のフィールドのデータを取得します。 、クライアントに返します; 2. フィルタ条件に従って、並べ替えられたフィールドとクライアントが要求したその他すべてのフィールドのデータを一度に取得し、並べ替える必要のないフィールドを格納しますメモリ領域に格納され、ソート バッファ内のフィールドが並べ替えられます。 フィールドと行ポインタ情報が並べ替えられ、最後に並べ替えられた行ポインタを使用して、結果セットがメモリ領域に格納されている行ポインタ情報と照合され、マージされます。他のフィールドも含めて、順番にクライアントに返します。 最初のアルゴリズムと比較して、2 番目のアルゴリズムは主にデータの二次アクセスを削減します。ソート後はテーブルに戻ってデータを取得する必要がないため、IO 操作が節約されます。もちろん、2 番目のアルゴリズムはより多くのメモリを消費します。これは、空間と時間を交換する典型的な最適化方法です。 複数テーブルの結合ソートの場合、前の結合の結果セットは、まず一時テーブルを介して一時テーブルに格納され、次に一時テーブルのデータがソート バッファにフェッチされて操作されます。 非インデックス ソートの場合は、ソートに 2 番目のアルゴリズムを選択してください。方法は次のとおりです: 1. max_length_for_sort_data パラメータ設定を増やします: 2. 不要な戻りフィールドを減らす 3. sort_buffer_size パラメータ設定を増やします: 4. 最後に # チューニングは実際には非常に難しいものであり、チューニングは上記のクエリ チューニングに限定されません。テーブル設計の最適化、データベースパラメータのチューニング、アプリケーションのチューニング(データベースのループ操作の削減、バッチ追加、データベース接続プール、キャッシュなど)など。もちろん、実際にやってみないと分からないチューニングテクニックもたくさんあります。理論と事実に基づいて常に自己改善に努めることによってのみ、真のチューニングマスターになれるのです。 関連する無料学習の推奨事項: mysql データベース(ビデオ)
多くの人が疑問を持っているかもしれませんが、複雑な Join ステートメントを複数の単純なクエリ ステートメントに分割すると、ネットワーク インタラクションがさらに増えるのではないでしょうか?ネットワーク遅延に関する全体的な消費量は大きくなります。クエリ全体を完了するのにさらに時間がかかるのではありませんか?はい、その可能性はありますが、確実ではありません。再度分析してみましょう。複雑なクエリ文を実行すると、より多くのリソースをロックする必要があり、他のリソースによってブロックされる可能性が高くなります。単純なクエリの場合は、ロックする必要があるリソースが少ないため、ブロックされる可能性も大幅に低くなります。したがって、より複雑な接続クエリは実行前にブロックされ、より多くの時間が無駄になる可能性があります。さらに、データベースはこのクエリ リクエストだけでなく、他の多くのリクエストも処理します。同時実行性の高いシステムでは、全体の処理能力を向上させるために 1 つのクエリの短い応答時間を犠牲にすることは非常に価値があります。最適化自体はバランスとトレードオフの芸術であり、トレードオフを知り、全体のバランスをとることによってのみ、システムをより良くすることができます。
フィールド
説明
ID
実行時のクエリのシーケンス番号plan
##Select_type
クエリ タイプ: DEPENDENT SUBQUERY: サブクエリの内部層の最初の SELECT。外部クエリの結果セットに依存します。
DEPENDENT UNION : サブクエリ内の UNION の 2 番目の SELECT から始まる後続のすべての SELECT も、外部クエリ結果セットに依存します;
PRIMARY: 主キー クエリではなく、サブクエリ内の最も外側のクエリ;
SUBQUERY : 内部クエリの最初の SELECT をサブクエリし、結果は外部結果セットに依存しません;
UNCACHEABLE SUBQUERY: 結果セットをキャッシュできないサブクエリ;
UNION: 2 番目から始まる後続のすべての SELECT UNION ステートメントの SELECT、最初の SELECT は PRIMARY
UNION RESULT: UNION でのマージ結果
Table
アクセスされたデータベース内のテーブルの名前
TYPE
アクセス方法: ALL: フルテーブルスキャン
const: 定数、最大1件のみ一致 定数なので、実際に読み取る必要があるのは 1 回だけです
eq_ref: 一致する結果は最大 1 つだけであり、通常は主キーまたは一意のインデックスによってアクセスされます。
インデックス: フル インデックス スキャン
範囲: インデックス範囲スキャン
ref: jion ステートメント内のドリブン テーブル インデックスの参照クエリ
system: システム テーブル、テーブルには 1 行のデータのみあります
Possible_keys
使用される可能性のあるインデックス
Key
使用されるインデックス
Key_len
インデックスの長さ
行数
結果セット内の推定レコード数
追加 #追加情報
#开启profiling参数 1-开启,0-关闭set profiling=1;SHOW VARIABLES LIKE '%profiling%';
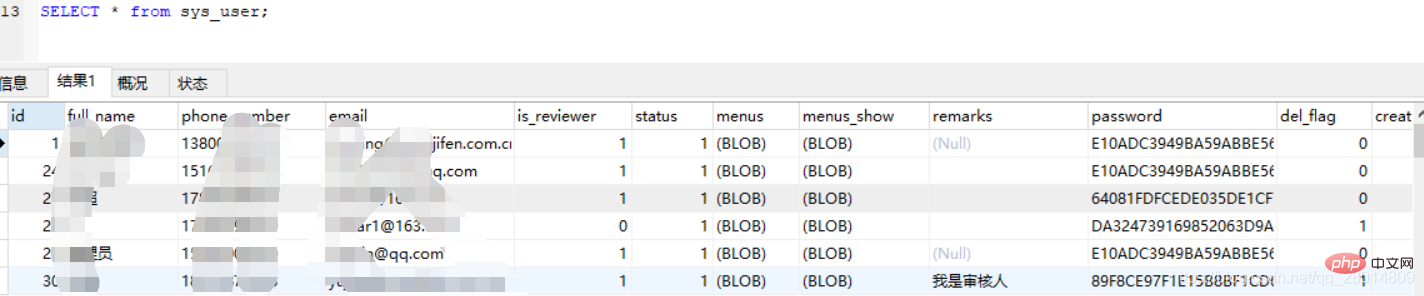
3、获取系统保存的profiling信息show PROFILES;
 4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)show profile cpu, block io for QUERY 7;
在MySQL中主要有四种类型索引,分别是:B-Tree索引,Hash索引,FullText索引,R-Tree索引,下面主要说一下我们常用的B-Tree索引,其他索引可以自行查找资料。
在Innodb中,存在两种形式的索引,一种是聚簇形式的主键索引,另外一种形式是和其他存储引擎(如MyISAM)存放形式基本相同的普通B-Tree索引,这种索引在Innodb存储引擎中被称作二级索引。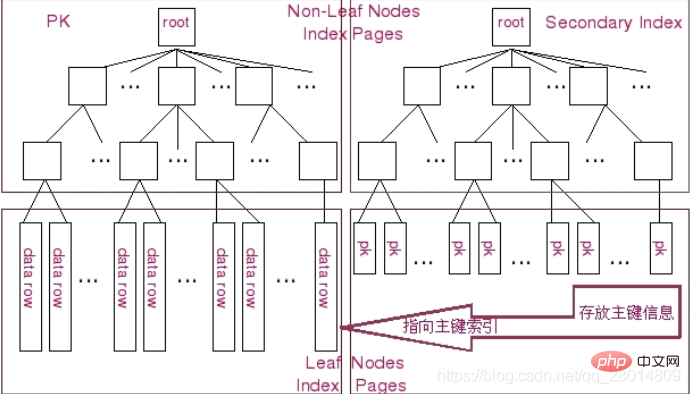
图示中左边为 Clustered 形式存放的 Primary Key,右侧则为普通的 B-Tree 索引。两种索引在根节点和 分支节点方面都还是完全一样的。而 叶子节点就出现差异了。在主键索引中,叶子结点存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据,整个数据以主键值有序的排列。而二级索引则和其他普通的 B-Tree 索引没有太大的差异,只是在叶子结点除了存放索引键的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过二级索引来访问数据的话,Innodb 首先通过二级索引的相关信息,通过相应的索引键检索到叶子节点之后,需要再通过叶子节点中存放的主键值再通过主键索引来获取相应的数据行。
MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的二级索引的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在叶子节点上面除了存放索引键信息之外,再存放能直接定位MyISAM 数据文件中相应的数据行的信息(如 Row Number),但并不会存放主键的键值信息。
缺点:查询需要更新索引信息带来额外的资源消耗,索引还会占用额外的存储空间
1、 较频繁的作为查询条件的字段应该创建索引;
2、更新频繁的字段不适合建立索引;
3、唯一性太差的不适合创建索引,如状态字段;
4、不出现在where中的字段不适合创建索引;
ただし、結合インデックスを作成する場合、クエリ条件のすべてのフィールドを 1 つのインデックスに配置する必要があるというわけではありません。1 つのインデックスを複数のクエリで使用できるようにし、インデックスの数を最小限に抑えてコストを削減する必要があります。アップデートとストレージのコスト。
MySQL は、インデックス自体の最適化を軽減する関数「Prefix Index」を提供します。つまり、フィールドのインデックスを作成するためのインデックス キーとしてフィールドの前の部分のみを使用できるため、インデックスが占有する領域が削減され、インデックスのアクセス効率が向上します。もちろん、プレフィックス インデックスは、プレフィックスが比較的ランダムで繰り返しがほとんどないフィールドにのみ適しています。
2. 結合されたインデックスを選択する場合インデックスを選択するときは、現在のクエリで最もフィルタリングしやすいフィールドをインデックス フィールドの順序で上位にランク付けする必要があります。
3. 結合インデックスを選択するときは、インデックスの where 句により多くのフィールドを含めることができるものを選択するようにしてください。現在のクエリ。インデックス;
4. 統計情報を分析し、クエリの記述方法を調整して、手動ヒントによるインデックス制御の選択肢を減らすことで、適切なインデックスを選択するようにしてください。これは、将来的に高いメンテナンスコストが発生するためです。
2. BLOB および TEXT タイプのフィールドプレフィックス インデックスの作成のみ可能;
3. MySQL は関数インデックスをサポートしていません;
4. != または を使用する場合、MySQL インデックスは使用できません;
5. 関数を使用してフィールドをフィルタリングした後操作、MySQL インデックスは使用できません;
6. jion ステートメントのニア フィールドの型が一致しない場合、MySQL インデックスは使用できません;
7. like を使用して前に一致させる場合 (例: '� a')、MySQL インデックスは使用できません;
8. 非同等のクエリを使用する場合、MySQL は HASH インデックスを使用できません;
9. 文字タイプが数値の場合は、='1' を使用する必要があります。 = 1 を直接使用することはできません;
10. or は使用しないでください。union all の代わりに in を使用してください。
最適化:
1. Join ステートメント内のループの合計数をできる限り減らします (前述した、小さな結果セットが大きな結果セットを駆動することに注意してください);
2.最適化を優先する 内部ループ;
3. Join ステートメントの駆動テーブルの結合条件フィールドにインデックスが作成されていることを確認します;
4. 駆動テーブルの結合条件フィールドにインデックスが作成されている保証がない場合メモリ リソースは十分にあるので、結合バッファ設定をケチらないでください (結合バッファは All、インデックス、範囲でのみ使用できます);
1. 順序付けされたインデックスを介して順序付けされたデータを直接取得することで、クライアントが必要とする順序付けされたデータを並べ替え操作なしで取得できます;
MySQL はパラメータ max_length_for_sort_data を通じて使用するアルゴリズムを決定します。 、返すフィールドの最大長がこのパラメータより小さい場合、MySQL は 2 番目のアルゴリズムを選択し、その逆も同様です。したがって、十分なメモリがある場合、このパラメータ値を増やすと、MySQL が 2 番目のアルゴリズムを選択できるようになります。
上記と同じ原理で、フィールドの数が少ない場合は、 max_length_for_sort_data パラメータより小さくなるようにしてください;
sort_buffer_size を増やすことは、MySQL がソート アルゴリズムの改善されたバージョンを選択できるようにするためではなく、MySQL がソート アルゴリズムの改善されたバージョンを選択できるようにするためです。ソート プロセスのステップ数 ソートする必要があるデータをセグメント化します (これにより、MySQL は交換ソートを実行するために一時テーブルを使用する必要が生じます)。
以上がMySQLクエリ最適化の詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7537
7537
 15
1380
52
82
11
21
86
15
1380
52
82
11
21
86

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
データベースから直接削除された行を直接回復することは、バックアップまたはトランザクションロールバックメカニズムがない限り、通常不可能です。キーポイント:トランザクションロールバック:トランザクションがデータの回復にコミットする前にロールバックを実行します。バックアップ:データベースの定期的なバックアップを使用して、データをすばやく復元できます。データベーススナップショット:データベースの読み取り専用コピーを作成し、データが誤って削除された後にデータを復元できます。削除ステートメントを使用して注意してください:誤って削除されないように条件を慎重に確認してください。 WHERE句を使用します:削除するデータを明示的に指定します。テスト環境を使用:削除操作を実行する前にテストします。
