この記事では、SQL 更新ステートメントを実行するプロセスを紹介します。一定の参考値があるので、困っている友達が参考になれば幸いです。

1. はじめに
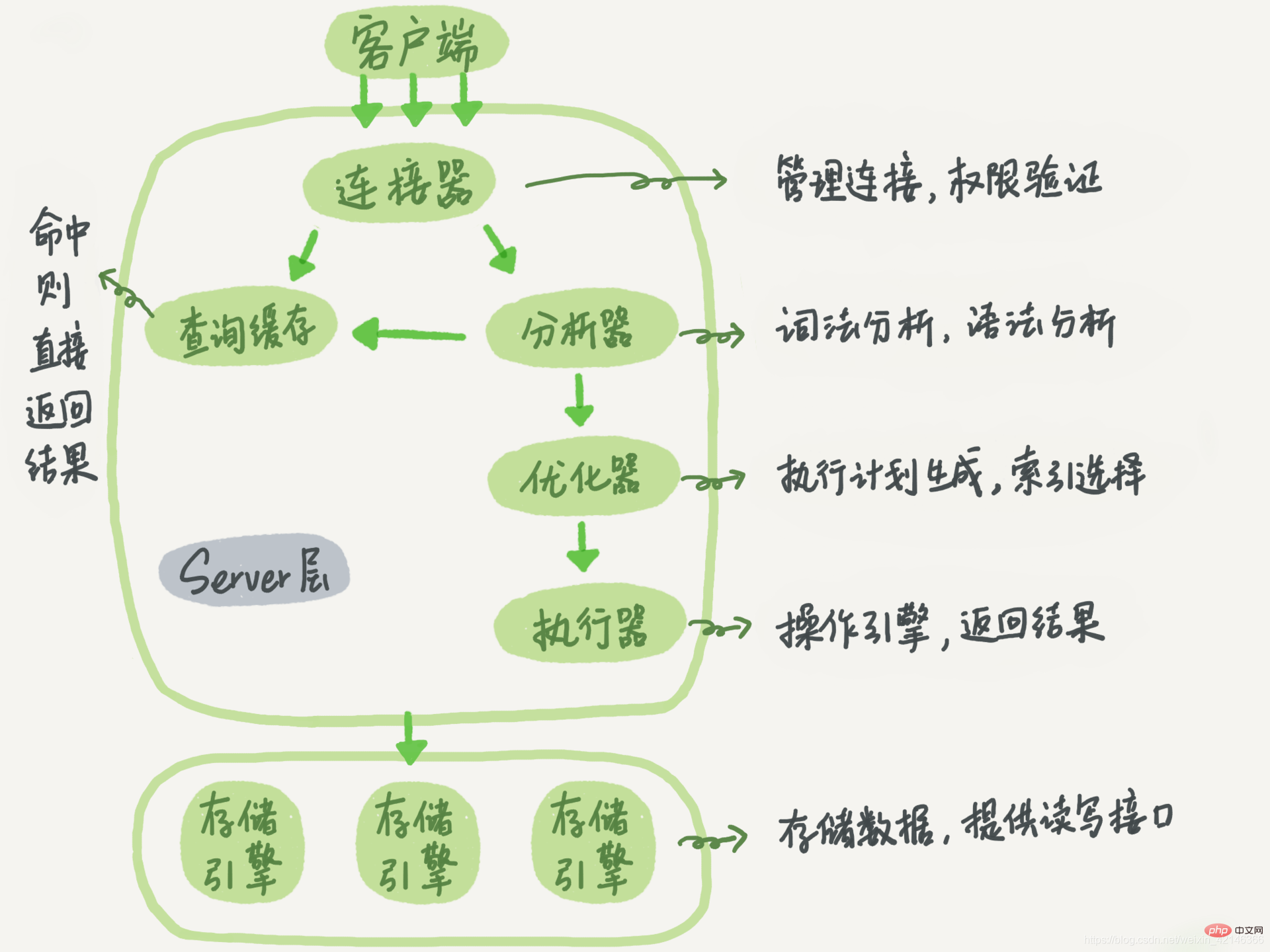
これまで、クエリ ステートメントの実行プロセスを体系的に理解し、実行プロセスに関与する処理モジュールを紹介しました。クエリ ステートメントの実行プロセスは、通常、コネクタ、アナライザー、オプティマイザー、エグゼキューターなどの機能モジュールを経由して、最終的にストレージ エンジンに到達することをまだ覚えていると思います。
それでは、更新ステートメントの実行フローはどのようなものでしょうか?
以前、DBA の同僚から、MySQL は半月以内でいつでも元の状態に復元できるという話をよく聞いたことがあるかもしれません。驚くと同時に、これがどのように行われるのかについても興味があるかもしれません。
2. ステートメント分析
テーブルの更新ステートメントから始めましょう。次はこのテーブルの作成ステートメントです。このテーブルには主キー ID と整数フィールド c:# があります。 ##
mysql> create table T(ID int primary key, c int);
ログイン後にコピー
行 ID=2 の値に 1 を加算する場合、SQL ステートメントは次のように記述します。
mysql> update T set c=c+1 where ID=2;
ログイン後にコピー
SQL の基本的な実行リンクを紹介しました。この写真をもう一度見て、確認することもできます。まず、クエリ ステートメントと更新ステートメントについても同じ一連のプロセスが実行されることは確実に言えます。
#ステートメントを実行する前にデータベースに接続する必要があります。これはコネクタの役割です。
テーブルに更新があると、このテーブルに関連するクエリ キャッシュが無効になると前に述べたので、このステートメントはテーブル T のキャッシュされた結果をすべてクリアします。このため、通常はクエリ キャッシュの使用を推奨しません。
次に、アナライザーは字句解析と構文解析を通じて、これが更新ステートメントであることを認識します。オプティマイザはインデックス ID を使用することを決定します。その後、エグゼキュータは実際にこの行を実行し、検索し、更新する責任を負います。
クエリ プロセスとは異なり、更新プロセスには、今日説明する主役である REDO ログ (REDO ログ) と binlog (アーカイブ ログ) という 2 つの重要なログ モジュールも含まれます。 MySQL に触れる場合、この 2 つの単語は絶対に避けて通ることはできません。以下のコンテンツでも引き続きこの 2 つの単語を強調していきます。ただし、そうは言っても、REDO ログと binlog の設計には興味深い側面が数多くあり、これらの設計アイデアは独自のプログラムでも使用できます。
重要なログ モジュール: やり直しログ
記事「Kong Yiji」をまだ覚えているかどうかはわかりません。ホテルの支配人は、ゲストの信用記録を記録するために特別に使用されるピンクのボードを持っています。 。クレジットで支払う人が少ない場合は、顧客の名前と口座をボードに書くことができます。しかし、クレジットアカウントを持つ人が多すぎると、ファンボードがそれらを追跡できない場合が常に発生するため、店主はクレジットアカウントを記録するための専用の台帳を持っている必要があります。
誰かが信用を作りたい、または借金を返済したい場合、店主には通常 2 つの方法があります。
1 つの方法は、家計簿を直接取り出して信用口座を追加することです。差し引いてください;- もう一つの方法は、最初にピンクのボードに口座を書き、閉店後に家計簿を取り出すことです。
-
ビジネスが好調でカウンターが非常に混雑している場合、店主は間違いなく後者を選択します。前者は操作が面倒だからです。まず、この人の信用口座の合計記録を見つけなければなりません。考えてみれば、何十ページもびっしりと詰まっており、店主は老眼鏡をかけてゆっくりと名前を探し、見つけたらそろばんを取り出して計算し、最後にその結果を帳簿に書き込むのです。台帳。
このプロセス全体を考えるのは面倒です。逆に、最初にピンクのボードに書き出すと簡単です。考えてみてください、店主はピンクのボードの助けがなければ、会計を記録するたびに台帳をひっくり返さなければならず、効率が非常に低くなりませんか?
同様に、この問題は MySQL にも存在します。すべての更新操作をディスクに書き込む必要があり、ディスクが対応するレコードを見つけて更新する必要がある場合、全体の IO コストと検索コストが発生します。プロセスは非常に高くなります。この問題を解決するために、MySQL の設計者は、ホテルの店主のピンクのボードに似たアイデアを使用して更新効率を向上させました。
ピンクのボードと台帳の連携プロセス全体は、実際には MySQL でよく言及される WAL テクノロジーです。WAL の正式名は、Write-Ahead Logging です。その重要な点は、最初にログを書き込み、最初にピンクのボードに書き込み、それから忙しくないときに家計簿を書きます。
具体的には、レコードを更新する必要がある場合、InnoDB エンジンはまずレコードを REDO ログ (ピンク色のボード) に書き込み、メモリを更新し、この時点で更新が完了します。同時に、InnoDB エンジンは適切なタイミングで操作記録をディスクに更新します。この更新は、店主が閉店後に行うのと同じように、システムが比較的アイドル状態のときに行われることがよくあります。
今日のクレジット口座がそれほど多くない場合、店主は閉店後まで待って整理することができます。しかし、ある日にたくさんのクレジット口座があり、ピンクのボードがいっぱいになった場合はどうすればよいでしょうか?このとき、店主は作業を中止し、ピンクのボード上の信用記録の一部を台帳に更新し、新しい口座を作成するためのスペースを確保するためにピンクのボードからこれらの記録を消去する必要がありました。
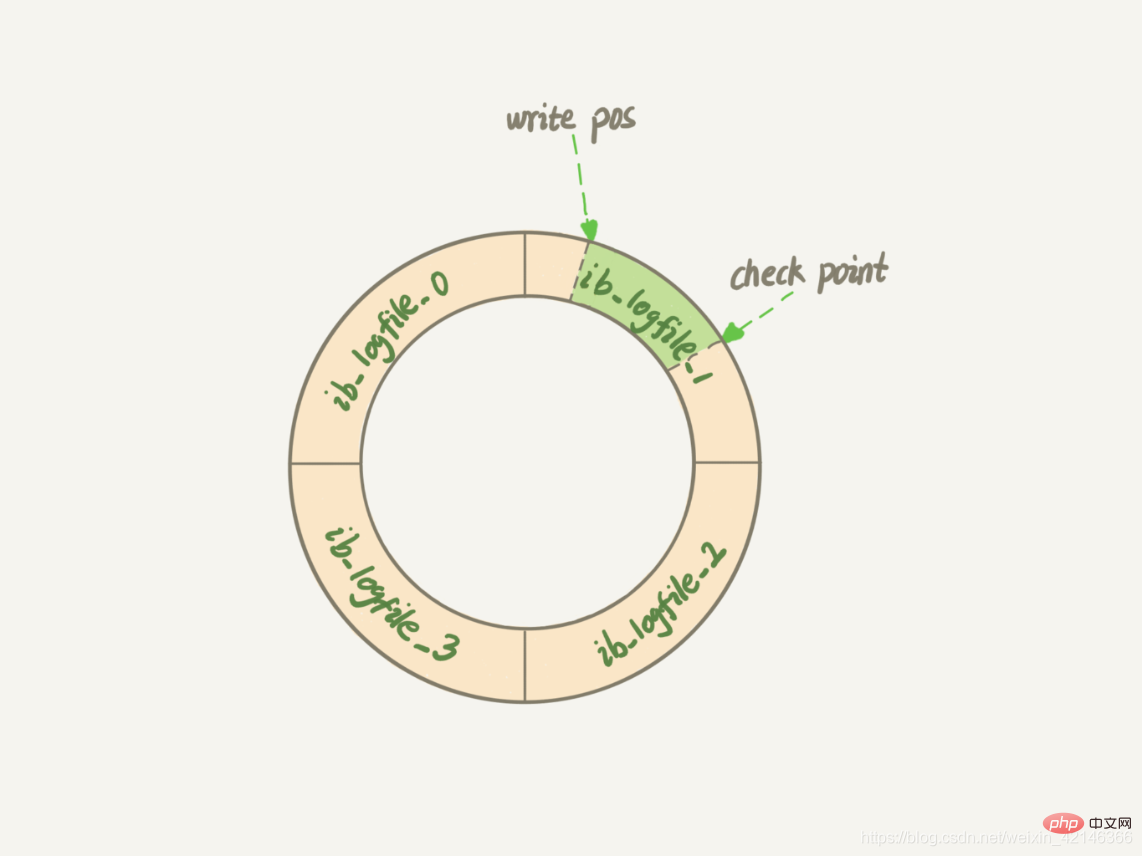
これと同様に、InnoDB の REDO ログはサイズが固定されています。たとえば、各ファイルのサイズが 1 GB の 4 つのファイルのセットとして構成できます。この場合、この「ピンクのボード」には合計 4 GB の操作を記録できます。以下の図のように、最初から書き始めて、最初に戻ってループして書きます。
write pos はカレントレコードの位置です書き込み中は逆方向(時計回り)に移動しますファイルNo.3の最後まで書き込んだ後先頭に戻りますファイルNo.0のチェックポイントは消去する現在位置であり、前方に移動してループします。レコードを消去する前に、レコードをデータ ファイルに更新する必要があります。
書き込み pos とチェックポイントの間のスペースは、新しい操作を記録するために使用できる「ピンクのボード」の空の部分です。書き込み pos がチェックポイントに追いついた場合、「ピンクのボード」がいっぱいであることを意味します。現時点では、新しい更新は実行できません。チェックポイントを進めるには、まず停止していくつかのレコードを消去する必要があります。
REDO ログを使用すると、InnoDB はデータベースが異常に再起動した場合でも、以前に送信されたレコードが失われないことを保証できます。この機能はクラッシュ セーフと呼ばれます。
クラッシュセーフの概念を理解するには、以前の信用記録の例を思い浮かべてください。信用記録がピンクのボードに記録されているか台帳に記載されていれば、店主が数日間突然営業を停止するなど、後で忘れてしまったとしても、台帳のデータから信用口座を明らかにすることができ、営業再開後のピンクボード。
重要なログ モジュール: binlog
前に述べたように、MySQL 全体には実際には 2 つの部分があります。1 つはサーバー層で、主に MySQL の機能レベルで処理を行います。エンジン層もあり、ストレージに関連する特定の問題を担当します。上で説明したピンクのボードの REDO ログは InnoDB エンジンに固有のログであり、サーバー層にも binlog (アーカイブ ログ) と呼ばれる独自のログがあります。
なぜログが 2 つあるのかと疑問に思われると思います。
MySQL には最初から InnoDB エンジンがなかったからです。 MySQL 独自のエンジンは MyISAM ですが、MyISAM にはクラッシュセーフ機能がなく、binlog ログはアーカイブにのみ使用できます。 InnoDB は、他社によってプラグインの形で MySQL に導入されましたが、binlog のみに依存するとクラッシュ セーフ機能がないため、InnoDB は別のログ システム、つまり REDO ログを使用してクラッシュ セーフ機能を実現します。
2 つのログには次の 3 つの違いがあります。
- redo ログは InnoDB エンジンに固有であり、binlog は MySQL のサーバー層によって実装され、すべてのエンジンで使用できます。
- redo ログは、「特定のデータ ページにどのような変更が加えられたか」を記録する物理ログであり、binlog は、「行 ID= を指定する」など、このステートメントの元のロジックを記録する論理ログです。 2" c フィールドに 1 を追加します。
- REDO ログはループで書き込まれ、スペースは常に使い果たされますが、binlog は追加で書き込むことができます。 「追加書き込み」とは、binlog ファイルが特定のサイズに達した後、次のファイルに切り替わり、前のログを上書きしないことを意味します。
これら 2 つのログの概念を理解した上で、この単純な更新ステートメントを実行するときのエグゼキューターと InnoDB エンジンの内部プロセスを見てみましょう。
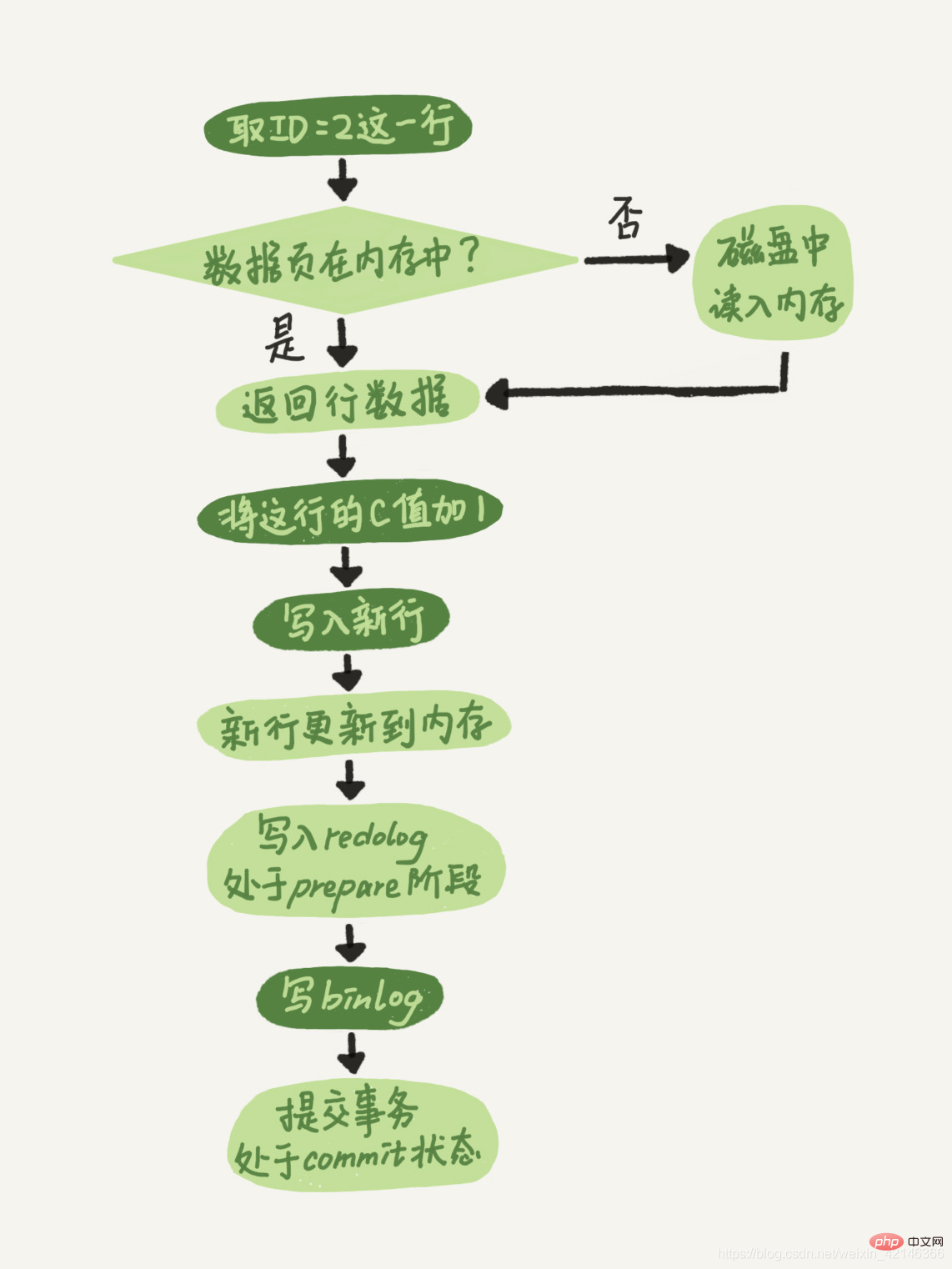
- エグゼキュータは、まずエンジンを検索して行 ID=2 を取得します。 ID が主キーであり、エンジンはツリー検索を直接使用してこの行を見つけます。 ID=2 行が配置されているデータ ページがすでにメモリ内にある場合は、そのデータ ページが直接エグゼキュータに返されます。それ以外の場合は、ディスクからメモリに読み取ってから返す必要があります。
- エグゼキューターは、エンジンによって指定された行データを取得し、この値に 1 を加算します。たとえば、以前は N でしたが、現在は N 1 になり、新しいデータ行を取得して、エンジン インターフェイスを使用して、この新しいデータ行を書き込みます。
- エンジンは、この新しいデータ行をメモリに更新し、更新操作を REDO ログに記録します。この時点で、REDO ログは準備状態になります。次に、実行が完了し、いつでもトランザクションを送信できることを実行者に通知します。
- エグゼキュータは、この操作のバイナリログを生成し、バイナリログをディスクに書き込みます。
- エグゼキューターはエンジンのコミット トランザクション インターフェイスを呼び出し、エンジンは書き込まれたばかりの REDO ログをコミット状態に変更し、更新が完了します。
この update ステートメントの実行フローチャートを示しますが、図中の明るいボックスは InnoDB 内で実行されることを示し、暗いボックスはエグゼキューターで実行されることを示します。
最後の 3 つのステップが少し「循環」しているように見えることに気づいたかもしれません。REDO ログの書き込みは、準備とコミットの 2 つのステップに分かれています。これは「2 つ」です。 -フェーズコミット」。
2 段階の提出
なぜ「2 段階の提出」が必要なのでしょうか?これは、2 つのログ間のロジックを一貫させるためです。この問題を説明するには、この記事の冒頭の質問から始める必要があります。「データベースを半月以内に任意の秒の状態に復元するにはどうすればよいですか?」
前に述べたように、binlog はすべての論理操作を記録し、「追記書き込み」の形式を採用します。 DBA が半月以内に復元できると約束した場合、バックアップ システムは確実に過去半月のすべてのバイナリ ログを保存し、データベース全体を定期的にバックアップします。ここでの「定期的」とは、システムの重要性に応じて、1 日に 1 回または週に 1 回にすることができます。
指定した秒に復元する必要がある場合、たとえば、ある日の午後 2 時にテーブルが正午に誤って削除されたことに気づき、データを取得する必要があるとします。
- まず、最新の完全バックアップを見つけます。運が良ければ、それは昨夜のバックアップである可能性があり、このバックアップから一時ライブラリに復元します。
- 次に、バックアップ時点から開始して復元します。バックアップ バイナリログが 1 つずつ取得され、正午にテーブルが誤って削除される前の時点まで再生されます。
このようにすると、一時データベースは誤って削除される前のオンライン データベースと同じになります。その後、必要に応じて一時データベースからテーブル データを取り出し、オンライン データベースに復元できます。 。
さて、データ回復プロセスについての説明は終わりましたので、戻ってログに「2 段階の送信」が必要な理由について話しましょう。ここでは、矛盾による証明を使って説明することもできます。
引き続き、前の update ステートメントを例として使用します。 ID=2 の現在の行でフィールド c の値が 0 であると仮定し、更新ステートメントの実行中、最初のログが書き込まれた後、2 番目のログが書き込まれる前にクラッシュが発生したと仮定します。 ?
- 最初に REDO ログを書き込み、次に binlog を書き込みます。 REDO ログが書き込まれたとき、バイナリログが書き込まれる前に、MySQL プロセスが異常に再起動したとします。前に述べたように、REDO ログが書き込まれた後は、システムがクラッシュしてもデータを回復できるため、回復後のこの行の c の値は 1 になります。ただし、バイナリログが終了する前にクラッシュしたため、この時点ではこのステートメントはバイナリログに記録されませんでした。したがって、後でログをバックアップするときに、このステートメントは保存されたバイナリログには含まれません。次に、このバイナリ ログを使用して一時ライブラリを復元する必要がある場合、このステートメントのバイナリ ログが失われているため、今回は一時ライブラリは更新されないことがわかります。復元された行の c の値は 0 です。元のライブラリの値と同じですが、異なります。
- 最初に binlog を書き込み、次に redo ログを書き込みます。 binlog の書き込み後にクラッシュが発生した場合、REDO ログはまだ書き込まれていないため、クラッシュ回復後のトランザクションは無効になるため、この行の c の値は 0 になります。ただし、binlog には「c を 0 から 1 に変更する」というログが記録されています。そのため、後で binlog を使用して復元すると、トランザクションが 1 つ増えてしまい、復元された行の c の値は 1 となり、元のデータベースの値とは異なります。
「2 フェーズ コミット」が使用されていない場合、データベースの状態が、ログを使用して復元されたライブラリの状態と一致しない可能性があることがわかります。
「この可能性は非常に低いのでしょうか? 一時ライブラリをいつでも復元する必要がある状況はないのでしょうか?」と思われるかもしれません。
実はいいえ、このプロセスは誤操作後にデータを回復するためだけに必要なわけではありません。容量を拡張する必要がある場合、つまり、システムの読み取り容量を増やすためにさらにバックアップ データベースを構築する必要がある場合、現在の一般的な方法は、完全バックアップを使用し、binlog を適用してこれを実現することです。オンラインのマスター データベースとスレーブ データベース間の不一致です。
簡単に言えば、REDO ログと binlog の両方を使用してトランザクションのコミット ステータスを表すことができ、2 フェーズ コミットは 2 つの状態の論理的な一貫性を保つことです。
関連する推奨事項: 「mysql チュートリアル 」
以上がSQL更新ステートメントを実行するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



