

PHP8 の基礎となるカーネル ソース コードの解析 - 配列 (4)

今回は「PHP8の基盤となるカーネルソースコードの解析 - 配列(4)」を紹介します。一定の参考値があるので、困っている友達が参考になれば幸いです。
おすすめ関連記事: 「PHP8の基礎となるカーネルソースコードの解析 - 配列(1) 」 「PHP8の基礎となるカーネルソースコードの解析 - 配列(2) 」 " PHP8 の基礎となるカーネル ソース コードの解析 - 配列 (3) >>
Runningprocess では、コードが字句解析、構文解析、コンパイル、実行を経る必要があることがすでにわかっています。 4 つの主要なステップ
- PHP の基礎となる実行プロセスの詳細な分析>>
PHP 8 はコンパイル中に配列定数を作成しますフェーズ (AST 抽象構文ツリーがオペコードにコンパイルされるとき)。この配列定数は、数値定数や文字列定数と同様、コンパイル段階で決定され、メモリが割り当てられます。したがって、配列の初期化はコンパイル段階で行われます。
PHP の配列初期化コード部分は次のとおりです
//如果开启zend_debug
#if !ZEND_DEBUG && defined(HAVE_BUILTIN_CONSTANT_P)
# define zend_new_array(size) \
(__builtin_constant_p(size) ? \
((((uint32_t)(size)) <= HT_MIN_SIZE) ? \
_zend_new_array_0() \
//走 _zend_new_array_0
: \
_zend_new_array((size)) \
) \
: \
_zend_new_array((size)) \
)
#else
//没有开启 也就是一般模式 走 _zend_new_array
# define zend_new_array(size) \
_zend_new_array(size)
#endif
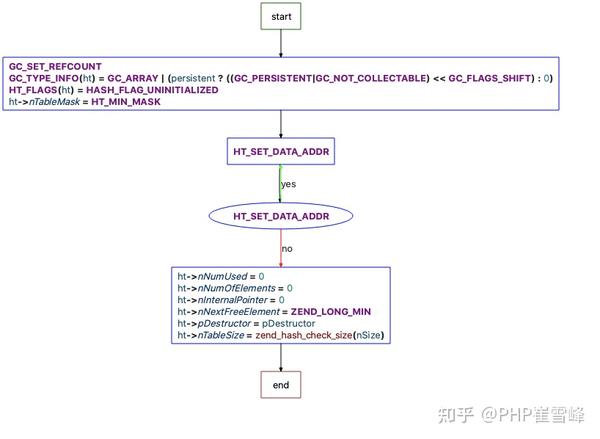
ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent)
{
_zend_hash_init_int(ht, nSize, pDestructor, persistent);
}
ZEND_API HashTable* ZEND_FASTCALL _zend_new_array_0(void)
{ //分配内存空间
HashTable *ht = emalloc(sizeof(HashTable));
//初始化
_zend_hash_init_int(ht, HT_MIN_SIZE, ZVAL_PTR_DTOR, 0);
return ht;
}
//初始化方法
static zend_always_inline void _zend_hash_init_int(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent)
{
GC_SET_REFCOUNT(ht, 1);
GC_TYPE_INFO(ht) = GC_ARRAY | (persistent ? ((GC_PERSISTENT|GC_NOT_COLLECTABLE) << GC_FLAGS_SHIFT) : 0);
HT_FLAGS(ht) = HASH_FLAG_UNINITIALIZED;
ht->nTableMask = HT_MIN_MASK;
HT_SET_DATA_ADDR(ht, &uninitialized_bucket);
ht->nNumUsed = 0;
ht->nNumOfElements = 0;
ht->nInternalPointer = 0;
ht->nNextFreeElement = ZEND_LONG_MIN;
ht->pDestructor = pDestructor;
ht->nTableSize = zend_hash_check_size(nSize);
}
//初始化 bucket 也就是 ardata
ZEND_API void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
{
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
//调用 zend_hash_real_init_ex方法
zend_hash_real_init_ex(ht, packed);
}
//zend_hash_real_init_ex方法
static zend_always_inline void zend_hash_real_init_ex(HashTable *ht, bool packed)
{
HT_ASSERT_RC1(ht);
ZEND_ASSERT(HT_FLAGS(ht) & HASH_FLAG_UNINITIALIZED);
if (packed) {
//如果是packed_array
zend_hash_real_init_packed_ex(ht);
} else {
//如果是 hash_array
zend_hash_real_init_mixed_ex(ht);
}
}
//paced_array 初始化bucket 的代码
static zend_always_inline void zend_hash_real_init_packed_ex(HashTable *ht)
{
void *data;
if (UNEXPECTED(GC_FLAGS(ht) & IS_ARRAY_PERSISTENT)) {
data = pemalloc(HT_SIZE_EX(ht->nTableSize, HT_MIN_MASK), 1);
} else if (EXPECTED(ht->nTableSize == HT_MIN_SIZE)) {
data = emalloc(HT_SIZE_EX(HT_MIN_SIZE, HT_MIN_MASK));
} else {
data = emalloc(HT_SIZE_EX(ht->nTableSize, HT_MIN_MASK));
}
HT_SET_DATA_ADDR(ht, data);
/* Don't overwrite iterator count. */
ht->u.v.flags = HASH_FLAG_PACKED | HASH_FLAG_STATIC_KEYS;
HT_HASH_RESET_PACKED(ht);
}
//hash_array 初始化bucket的代码
static zend_always_inline void zend_hash_real_init_mixed_ex(HashTable *ht)
{
void *data;
uint32_t nSize = ht->nTableSize;
if (UNEXPECTED(GC_FLAGS(ht) & IS_ARRAY_PERSISTENT)) {
data = pemalloc(HT_SIZE_EX(nSize, HT_SIZE_TO_MASK(nSize)), 1);
} else if (EXPECTED(nSize == HT_MIN_SIZE)) {
data = emalloc(HT_SIZE_EX(HT_MIN_SIZE, HT_SIZE_TO_MASK(HT_MIN_SIZE)));
ht->nTableMask = HT_SIZE_TO_MASK(HT_MIN_SIZE);
HT_SET_DATA_ADDR(ht, data);
/* Don't overwrite iterator count. */
ht->u.v.flags = HASH_FLAG_STATIC_KEYS;
#ifdef __SSE2__
do {
__m128i xmm0 = _mm_setzero_si128();
xmm0 = _mm_cmpeq_epi8(xmm0, xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 0), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 4), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 8), xmm0);
_mm_storeu_si128((__m128i*)&HT_HASH_EX(data, 12), xmm0);
} while (0);
#elif defined(__aarch64__)
do {
int32x4_t t = vdupq_n_s32(-1);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 0), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 4), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 8), t);
vst1q_s32((int32_t*)&HT_HASH_EX(data, 12), t);
} while (0);
#else
HT_HASH_EX(data, 0) = -1;
HT_HASH_EX(data, 1) = -1;
HT_HASH_EX(data, 2) = -1;
HT_HASH_EX(data, 3) = -1;
HT_HASH_EX(data, 4) = -1;
HT_HASH_EX(data, 5) = -1;
HT_HASH_EX(data, 6) = -1;
HT_HASH_EX(data, 7) = -1;
HT_HASH_EX(data, 8) = -1;
HT_HASH_EX(data, 9) = -1;
HT_HASH_EX(data, 10) = -1;
HT_HASH_EX(data, 11) = -1;
HT_HASH_EX(data, 12) = -1;
HT_HASH_EX(data, 13) = -1;
HT_HASH_EX(data, 14) = -1;
HT_HASH_EX(data, 15) = -1;
#endif
return;
} else {
data = emalloc(HT_SIZE_EX(nSize, HT_SIZE_TO_MASK(nSize)));
}
ht->nTableMask = HT_SIZE_TO_MASK(nSize);
HT_SET_DATA_ADDR(ht, data);
HT_FLAGS(ht) = HASH_FLAG_STATIC_KEYS;
HT_HASH_RESET(ht);
}
//数组赋值和更新值
static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag)
{
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if ((flag & HASH_ADD_NEXT) && h == ZEND_LONG_MIN) {
h = 0;
}
if (HT_FLAGS(ht) & HASH_FLAG_PACKED) {
if (h < ht->nNumUsed) {
p = ht->arData + h;
if (Z_TYPE(p->val) != IS_UNDEF) {
replace:
if (flag & HASH_ADD) {
return NULL;
}
if (ht->pDestructor) {
ht->pDestructor(&p->val);
}
ZVAL_COPY_VALUE(&p->val, pData);
return &p->val;
} else { /* we have to keep the order :( */
goto convert_to_hash;
}
} else if (EXPECTED(h < ht->nTableSize)) {
add_to_packed:
p = ht->arData + h;
/* incremental initialization of empty Buckets */
if ((flag & (HASH_ADD_NEW|HASH_ADD_NEXT)) != (HASH_ADD_NEW|HASH_ADD_NEXT)) {
if (h > ht->nNumUsed) {
Bucket *q = ht->arData + ht->nNumUsed;
while (q != p) {
ZVAL_UNDEF(&q->val);
q++;
}
}
}
ht->nNextFreeElement = ht->nNumUsed = h + 1;
goto add;
} else if ((h >> 1) < ht->nTableSize &&
(ht->nTableSize >> 1) < ht->nNumOfElements) {
zend_hash_packed_grow(ht);
goto add_to_packed;
} else {
if (ht->nNumUsed >= ht->nTableSize) {
ht->nTableSize += ht->nTableSize;
}
convert_to_hash:
zend_hash_packed_to_hash(ht);
}
} else if (HT_FLAGS(ht) & HASH_FLAG_UNINITIALIZED) {
if (h < ht->nTableSize) {
zend_hash_real_init_packed_ex(ht);
goto add_to_packed;
}
zend_hash_real_init_mixed(ht);
} else {
if ((flag & HASH_ADD_NEW) == 0 || ZEND_DEBUG) {
p = zend_hash_index_find_bucket(ht, h);
if (p) {
ZEND_ASSERT((flag & HASH_ADD_NEW) == 0);
goto replace;
}
}
ZEND_HASH_IF_FULL_DO_RESIZE(ht);/* If the Hash table is full, resize it */
}
idx = ht->nNumUsed++;
nIndex = h | ht->nTableMask;
p = ht->arData + idx;
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
if ((zend_long)h >= ht->nNextFreeElement) {
ht->nNextFreeElement = (zend_long)h < ZEND_LONG_MAX ? h + 1 : ZEND_LONG_MAX;
}
add:
ht->nNumOfElements++;
p->h = h;
p->key = NULL;
ZVAL_COPY_VALUE(&p->val, pData);
return &p->val;
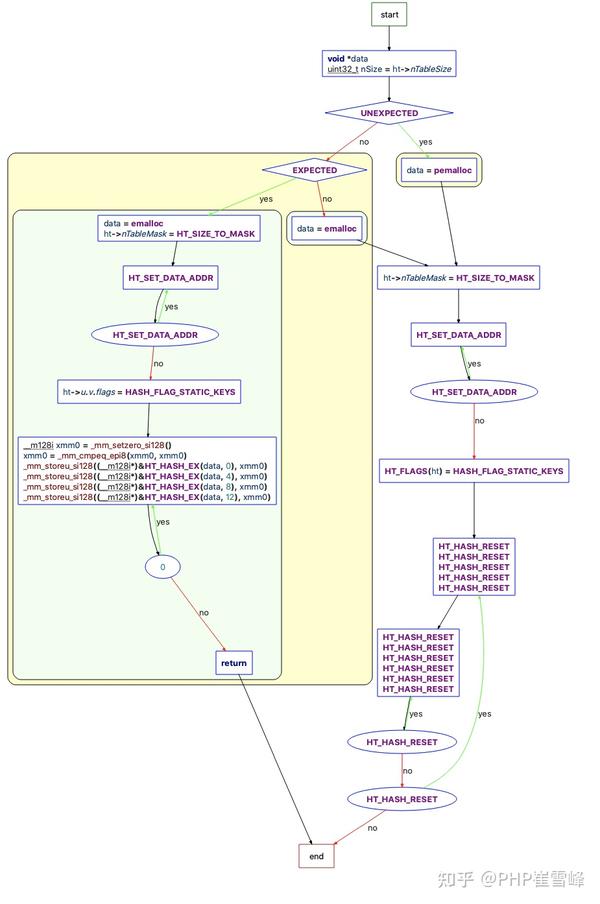
}_zend_hash_init_int フローチャートは次のとおりです

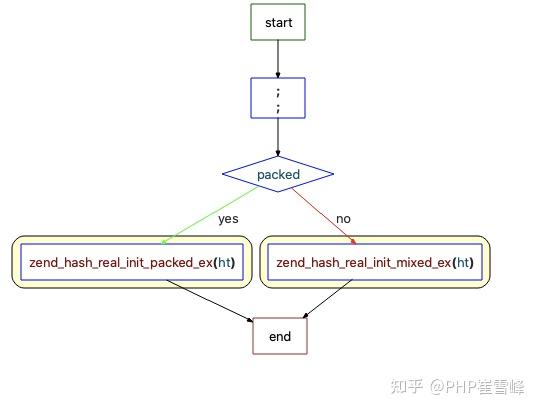
 ##zend_hash_real_init_ex メソッドのフローチャート (バケットの初期化)
##zend_hash_real_init_ex メソッドのフローチャート (バケットの初期化)

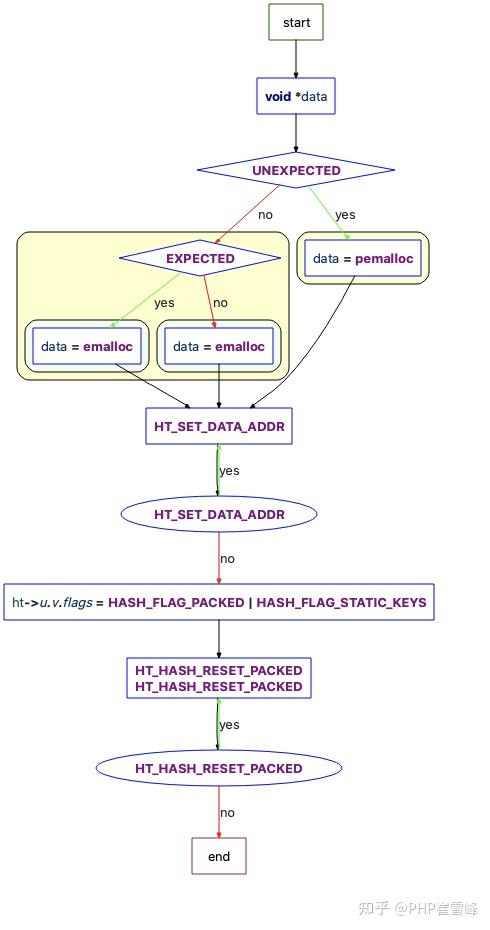 zend_hash_real_init_packed_ex( バケットの初期化フローPacked_array の場合のチャート)
zend_hash_real_init_packed_ex( バケットの初期化フローPacked_array の場合のチャート)

以上がPHP8 の基礎となるカーネル ソース コードの解析 - 配列 (4)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 foreach ループを使用して PHP 配列から重複要素を削除するにはどうすればよいですか?
Apr 27, 2024 am 11:33 AM
foreach ループを使用して PHP 配列から重複要素を削除するにはどうすればよいですか?
Apr 27, 2024 am 11:33 AM
foreach ループを使用して PHP 配列から重複要素を削除する方法は次のとおりです。配列を走査し、要素がすでに存在し、現在の位置が最初に出現しない場合は、要素を削除します。たとえば、データベース クエリの結果に重複レコードがある場合、このメソッドを使用してそれらを削除し、重複レコードのない結果を取得できます。
 PHP 配列キー値の反転: さまざまな方法のパフォーマンス比較分析
May 03, 2024 pm 09:03 PM
PHP 配列キー値の反転: さまざまな方法のパフォーマンス比較分析
May 03, 2024 pm 09:03 PM
PHP の配列キー値の反転メソッドのパフォーマンスを比較すると、array_flip() 関数は、大規模な配列 (100 万要素以上) では for ループよりもパフォーマンスが良く、所要時間が短いことがわかります。キー値を手動で反転する for ループ方式は、比較的長い時間がかかります。
 PHP 配列ディープ コピーの技術: さまざまな方法を使用して完璧なコピーを実現する
May 01, 2024 pm 12:30 PM
PHP 配列ディープ コピーの技術: さまざまな方法を使用して完璧なコピーを実現する
May 01, 2024 pm 12:30 PM
PHP で配列をディープ コピーする方法には、json_decode と json_encode を使用した JSON エンコードとデコードが含まれます。 array_map と clone を使用して、キーと値のディープ コピーを作成します。シリアル化と逆シリアル化には、serialize と unserialize を使用します。
 PHP 配列の多次元ソートの実践: 単純なシナリオから複雑なシナリオまで
Apr 29, 2024 pm 09:12 PM
PHP 配列の多次元ソートの実践: 単純なシナリオから複雑なシナリオまで
Apr 29, 2024 pm 09:12 PM
多次元配列のソートは、単一列のソートとネストされたソートに分類できます。単一列のソートでは、array_multisort() 関数を使用して列ごとにソートできますが、ネストされたソートでは、配列を走査してソートするための再帰関数が必要です。具体的な例としては、製品名による並べ替えや、売上数量や価格による化合物の並べ替えなどがあります。
 PHP 配列のディープ コピーのベスト プラクティス: 効率的な方法を発見する
Apr 30, 2024 pm 03:42 PM
PHP 配列のディープ コピーのベスト プラクティス: 効率的な方法を発見する
Apr 30, 2024 pm 03:42 PM
PHP で配列のディープ コピーを実行するためのベスト プラクティスは、 json_decode(json_encode($arr)) を使用して配列を JSON 文字列に変換し、それから配列に戻すことです。 unserialize(serialize($arr)) を使用して配列を文字列にシリアル化し、それを新しい配列に逆シリアル化します。 RecursiveIteratorIterator を使用して、多次元配列を再帰的に走査します。
 データソートにおけるPHP配列グループ化機能の応用
May 04, 2024 pm 01:03 PM
データソートにおけるPHP配列グループ化機能の応用
May 04, 2024 pm 01:03 PM
PHP の array_group_by 関数は、キーまたはクロージャ関数に基づいて配列内の要素をグループ化し、キーがグループ名、値がグループに属する要素の配列である連想配列を返すことができます。
 PHP 配列のマージおよび重複排除アルゴリズム: 並列ソリューション
Apr 18, 2024 pm 02:30 PM
PHP 配列のマージおよび重複排除アルゴリズム: 並列ソリューション
Apr 18, 2024 pm 02:30 PM
PHP 配列のマージおよび重複排除アルゴリズムは、元の配列を小さなブロックに分割して並列処理する並列ソリューションを提供し、メイン プロセスは重複排除するブロックの結果をマージします。アルゴリズムのステップ: 元の配列を均等に割り当てられた小さなブロックに分割します。重複排除のために各ブロックを並行して処理します。ブロックの結果をマージし、再度重複排除します。
 重複要素の検索における PHP 配列グループ化関数の役割
May 05, 2024 am 09:21 AM
重複要素の検索における PHP 配列グループ化関数の役割
May 05, 2024 am 09:21 AM
PHP の array_group() 関数を使用すると、指定したキーで配列をグループ化し、重複する要素を見つけることができます。この関数は次の手順で動作します。 key_callback を使用してグループ化キーを指定します。必要に応じて、value_callback を使用してグループ化値を決定します。グループ化された要素をカウントし、重複を特定します。したがって、array_group() 関数は、重複する要素を見つけて処理するのに非常に役立ちます。
