

Divide&Conquer (pide&Conquer)、参考ビッグ データ アルゴリズム: 5 億データの並べ替え
これについては Total.txt 500000000行をソートし、ファイルサイズは4.6Gです。
10,000 行が読み取られるたびに、それらを並べ替えて新しいサブファイルに書き込みます (ここでは クイック ソート を使用します)。
#!/usr/bin/python2.7
import time
def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def quick_sort(lst):
if len(lst) < 2:
return lst
pivot = lst[0]
left = [ ele for ele in lst[1:] if ele < pivot ]
right = [ ele for ele in lst[1:] if ele >= pivot ]
return quick_sort(left) + [pivot,] + quick_sort(right)
def split_bfile(bfile):
count = 0
nums = []
for line in readline_by_yield(bfile):
num = int(line)
if num not in nums:
nums.append(num)
if 10000 == len(nums):
nums = quick_sort(nums)
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write('\n'.join([ str(i) for i in nums ]))
nums[:] = []
count += 1
print count
now = time.time()
split_bfile('total.txt')
run_t = time.time()-now
print 'Runtime : {}'.format(run_t)は 50,000 個の小さなファイルを生成します (各小さなファイルのサイズは約 96K)。
プログラムの実行中のメモリ使用量は約 5424kB

ファイル全体を分割するには 94146 秒かかります。
#!/usr/bin/python2.7
# -*- coding: utf-8 -*-
import os
import time
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行,即当前文件最小值
nums = []
tmp_nums = []
for fd in fds:
num = int(fd.readline())
tmp_nums.append(num)
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
count = 0
while 1:
val = min(tmp_nums)
nums.append(val)
idx = tmp_nums.index(val)
next = fds[idx].readline()
# 文件读完了
if not next:
del fds[idx]
del tmp_nums[idx]
else:
tmp_nums[idx] = int(next)
# 暂存区保存1000个数,一次性写入硬盘,然后清空继续读。
if 1000 == len(nums):
with open('final_sorted.txt','a') as wf:
wf.write('\n'.join([ str(i) for i in nums ]) + '\n')
nums[:] = []
if 499999999 == count:
break
count += 1
with open('runtime.txt','w') as wf:
wf.write('Runtime : {}'.format(time.time()-now))プログラムの実行中のメモリ使用量は約 240M
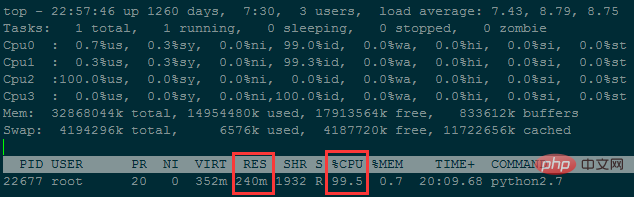

#5,000 万行未満のデータをマージするのに約 38 時間かかりました...
メモリ使用量は削減されましたが、時間は複雑になりました次数が高すぎます。ファイル数を減らす (各小さなファイルに格納される行数を増やす) ことで、メモリ使用量をさらに削減できます。
質問 2: ファイルには 1,000 億行のデータがあり、各行は IP アドレスであり、IP アドレスを並べ替える必要があります。 IP アドレスを数値に変換する# 方法一:手动计算
In [62]: ip
Out[62]: '10.3.81.150'
In [63]: ip.split('.')[::-1]
Out[63]: ['150', '81', '3', '10']
In [64]: [ '{}-{}'.format(idx,num) for idx,num in enumerate(ip.split('.')[::-1]) ]
Out[64]: ['0-150', '1-81', '2-3', '3-10']
In [65]: [256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])]
Out[65]: [150, 20736, 196608, 167772160]
In [66]: sum([256**idx*int(num) for idx,num in enumerate(ip.split('.')[::-1])])
Out[66]: 167989654
In [67]:
# 方法二:使用C扩展库来计算
In [71]: import socket,struct
In [72]: socket.inet_aton(ip)
Out[72]: b'\n\x03Q\x96'
In [73]: struct.unpack("!I", socket.inet_aton(ip))
# !表示使用网络字节顺序解析, 后面的I表示unsigned int, 对应Python里的integer or long
Out[73]: (167989654,)
In [74]: struct.unpack("!I", socket.inet_aton(ip))[0]
Out[74]: 167989654
In [75]: socket.inet_ntoa(struct.pack("!I", 167989654))
Out[75]: '10.3.81.150'
In [76]:基本的な考え方: 大きなファイルを繰り返し読み取り、大きなファイルを複数の小さなファイルに分割し、最後にこれらの小さなファイルをマージします。
分割ルール:
大きなファイルを繰り返し読み取り、メモリ内に辞書を維持します。キーは文字列で、値は文字列が出現する回数です。 ディクショナリによって維持される文字列タイプの数が 10,000 (カスタマイズ可能) に達すると、ディクショナリはキー によって小さいものから大きいものへと並べ替えられ、小さなファイルに書き込まれます。各行は次のようになります。 key\tvalue;
次に、辞書をクリアし、大きなファイルが終了するまで読み取りを続けます。マージ ルール :
まず、すべての個の小さなファイルのファイル記述子 を取得し、最初の行 (つまり、それぞれの小さなファイル) を読み出します。ファイルファイル文字列の最小の ASCII 値を持つ文字列)が比較されます。
最小の ASCII 値を持つ文字列を検索します。重複がある場合は、出現回数を合計し、現在の文字列と合計回数をメモリ内のリストに保存します。 次に、最小の文字列が位置するファイルの読み取りポインタを下に移動します。つまり、次の比較ラウンドのために、対応する小さなファイルから別の行を読み取ります。 メモリ内のリストの数が 10,000 に達すると、リストの内容が最終ファイルに一度に書き込まれ、ハードディスクに保存されます。同時に、後続の比較のためにリストをクリアします。 すべての小さなファイルが読み取られるまで、最後のファイルは、文字列 ASCII 値に従って昇順にソートされた大きなファイルです。各行の内容は、文字列\反復回数です ,
最後の反復では、最終ファイルを読み取り、最も繰り返しが多いファイルを見つけます。 1. 分割def readline_by_yield(bfile):
with open(bfile, 'r') as rf:
for line in rf:
yield line
def split_bfile(bfile):
count = 0
d = {}
for line in readline_by_yield(bfile):
line = line.strip()
if line not in d:
d[line] = 0
d[line] += 1
if 10000 == len(d):
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile{}.txt'.format(count+1),'w') as wf:
wf.write(text.strip())
d.clear()
count += 1
text = ''
for string in sorted(d):
text += '{}\t{}\n'.format(string,d[string])
with open('subfile/subfile_end.txt','w') as wf:
wf.write(text.strip())
split_bfile('bigfile.txt')import os
import json
import time
import traceback
testdir = '/ssd/subfile'
now = time.time()
# Step 1 : 获取全部文件描述符
fds = []
for f in os.listdir(testdir):
ff = os.path.join(testdir,f)
fds.append(open(ff,'r'))
# Step 2 : 每个文件获取第一行
tmp_strings = []
tmp_count = []
for fd in fds:
line = fd.readline()
string,count = line.strip().split('\t')
tmp_strings.append(string)
tmp_count.append(int(count))
# Step 3 : 获取当前最小值放入暂存区,并读取对应文件的下一行;循环遍历。
result = []
need2del = []
while True:
min_str = min(tmp_strings)
str_idx = [i for i,v in enumerate(tmp_strings) if v==min_str]
str_count = sum([ int(tmp_count[idx]) for idx in str_idx ])
result.append('{}\t{}\n'.format(min_str,str_count))
for idx in str_idx:
next = fds[idx].readline() # IndexError: list index out of range
# 文件读完了
if not next:
need2del.append(idx)
else:
next_string,next_count = next.strip().split('\t')
tmp_strings[idx] = next_string
tmp_count[idx] = next_count
# 暂存区保存10000个记录,一次性写入硬盘,然后清空继续读。
if 10000 == len(result):
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []
# 注意: 文件读完需要删除文件描述符的时候, 需要逆序删除
need2del.reverse()
for idx in need2del:
del fds[idx]
del tmp_strings[idx]
del tmp_count[idx]
need2del[:] = []
if 0 == len(fds):
break
with open('merged.txt','a') as wf:
wf.write(''.join(result))
result[:] = []| 分割中にメモリ内で維持される辞書のサイズ | 分割される小さなファイルの数 | マージ中に維持されるファイル記述子の数 | マージ中のメモリ使用量 | マージには時間がかかります | |
| 10000 | 9000 | 9000 ~ 0 | 200M | マージ速度が遅いため、完了時間がまだ計算されていません | |
| 100000 | 900 | 900 ~ 0 | 27M | マージ速度は速く、わずか 2572 秒です |
3.最も頻繁に出現する文字列とその時刻
import time
def read_line(filepath):
with open(filepath,'r') as rf:
for line in rf:
yield line
start_ts = time.time()
max_str = None
max_count = 0
for line in read_line('merged.txt'):
string,count = line.strip().split('\t')
if int(count) > max_count:
max_count = int(count)
max_str = string
print(max_str,max_count)
print('Runtime {}'.format(time.time()-start_ts))以上が大規模ファイルのソート/外部メモリのソートの問題を理解するための 1 つの記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



