

例を使用して SQL を最適化する方法を説明します

最近ではハードウェアのコストが下がっていますが、ハードウェアをアップグレードしてシステムのパフォーマンスを向上させることも一般的な最適化方法です。リアルタイム性の高いシステムではやはりSQL面からの最適化が必要であり、今回はSQLの最適化方法を例に基づいて紹介します。
SQL の問題を判断する
SQL に問題があるかどうかを判断する場合、次の 2 つの現象によって判断できます。
-
システム レベルの現象
CPU 消費量が深刻です
IO 待機が深刻です
ページの応答時間が長すぎますlong
-
タイムアウトやその他のエラーがアプリケーション ログに表示される
sar コマンドと top コマンドを使用できます。現在のシステムステータスを表示します。 Prometheus や Grafana などの監視ツールを通じてシステムのステータスを観察することもできます。
- ##SQL ステートメントの外観
-
- 長さ
- 実行時間が長すぎます
- #フル テーブル スキャンからデータを取得しています
#実行プランの行とコストが非常に大きくなっています
- 長い SQL は理解しやすい SQL が長すぎると可読性が悪く、問題の発生頻度も確実に高くなります。 SQL の問題をさらに特定するには、以下に示すように、実行プランから始める必要があります。
 問題 SQL の取得
問題 SQL の取得
データベースごとに取得方法が異なります。以下は、現在主流のデータベース用のスロー クエリ SQL 取得ツールです。
MySQL
-
スロークエリログ
テストツールloadrunner
Perconaのptqueryおよびその他のツール
- Oracle
-
AWR レポート
テスト ツール ロードランナーなど
v$、$session_wait などの関連内部ビュー
GRID CONTROL 監視ツール
-
## Dameng データベース
#AWR レポート -
#テスト ツール ロードランナーなど
# Dameng パフォーマンス監視ツール (開発者)
v$、$session_wait などの関連内部ビュー
- SQL 記述スキル
SQL 記述には次の一般的なスキルがあります:
• インデックスの合理的な使用
• UNION
の代わりに UNION ALL を使用してください。最適化する場合SQL の実行 プロセッサは * を特定の列に変換する必要があり、各クエリはテーブルを返す必要があり、カバリング インデックスは使用できません。UNION ALL は UNION よりも実行効率が高くなります。UNION は実行時に重複排除する必要があります。UNION はデータを並べ替える必要があります
• select * の書き込みを避ける
• JOIN フィールドのインデックスを作成することをお勧めします一般に、JOIN フィールドには事前にインデックスが付けられます
• 複雑な SQL を避けるステートメント読みやすさを向上、クエリが遅くなる可能性を回避、複数の短いクエリに変換してビジネスエンドで処理可能
• データ列が複数回スキャンされる原因となる、rand() と同様の記述スタイルによる順序付けは避けてください。#• 1=1 の記述を避ける
RAND() によりデータ列が複数回スキャンされます。SQL 最適化
実行計画
SQL の最適化を完了する前に必ず実行計画を読んでください。実行計画には、効率が低い箇所と最適化が必要な箇所が示されます。 MYSQL を例として、実行計画がどのようなものかを見てみましょう。 (各データベースの実行計画は異なるため、自分で理解する必要があります)
| 説明 | |
|---|---|
| それぞれは独立して実行されます。操作識別子はオブジェクトを操作する順序を識別します。idの値が大きいほど最初に実行されます。同じ場合、実行順序は上から下です。 | |
| クエリ内 各 select 句のタイプ | |
| 操作対象のオブジェクトの名前。通常はテーブル名ですが、他の形式です | |
| 一致するパーティション情報 (パーティション化されていないテーブルの値は NULL) | |
| 結合操作の種類 | |
| 使用される可能性のあるインデックス | |
| オプティマイザによって実際に使用されるインデックス (最も重要な列) 最適な結合タイプから最悪の結合タイプまで、const、eq_reg、ref、range、index、および ALL です。 ALL が表示される場合は、現在の SQL に「悪臭」があることを意味します。 | |
| オプティマイザによって選択されたインデックス キーの長さ (バイト単位) | |
| はこの行の操作オブジェクトの参照オブジェクトを示します。参照オブジェクトは NULL | |
| ではありません | Query 実行によってスキャンされたタプルの数 (innodb の場合、この値は推定値です)|
| 条件式のタプル数のパーセンテージフィルタリングされたテーブル | |
| 実行計画の重要な補足情報。この列に「ファイルソートを使用」、「一時を使用」という言葉が表示されている場合は注意してください。 SQL ステートメントを最適化する必要があります |
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;

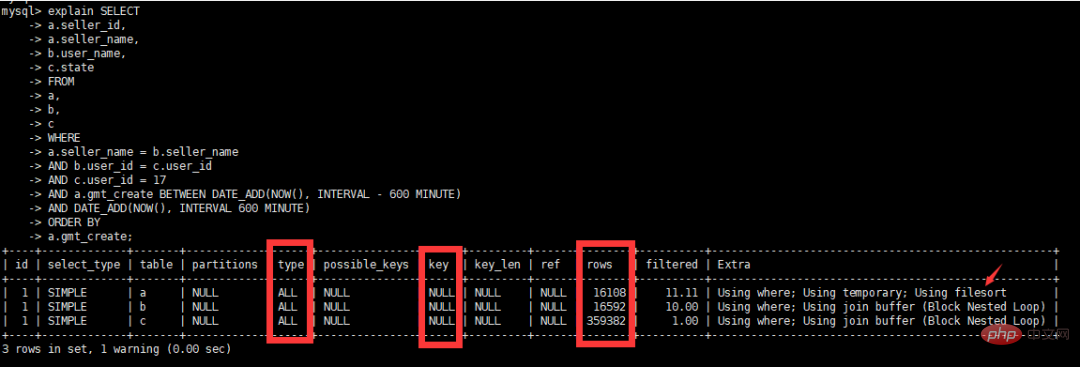 ##初期の最適化アイデア
##初期の最適化アイデア
- SQL の where 条件フィールドの型テーブルの user_id は、SQL で使用される実際の int 型である varchar(50) 型であり、暗黙的な変換が行われ、インデックスは追加されません。テーブル b とテーブル c の user_id フィールドを int 型に変更します。
- テーブル b とテーブル c の間に関連付けがあるため、テーブル b とテーブル c の user_id にインデックスを作成します。
- テーブル a とテーブル b の間の関連付けです。テーブル a と b の sell_name フィールドにインデックスを作成します。
- #複合インデックスを使用して一時テーブルを削除し、並べ替えます
- SQL の初期最適化
-
#SQL に関連するテーブル構造とインデックス情報を表示する - 実行計画に従って考えられる最適化ポイントを考える
- テーブルを実行する可能な最適化ポイントに応じて、構造の変更、インデックスの追加、SQL の書き換え、その他の操作
#最適化された実行時間と実行計画を表示します
- #最適化の効果は明らかではありません。4 番目のステップを繰り返します。
- 関連推奨: 「
mysql チュートリアル
」
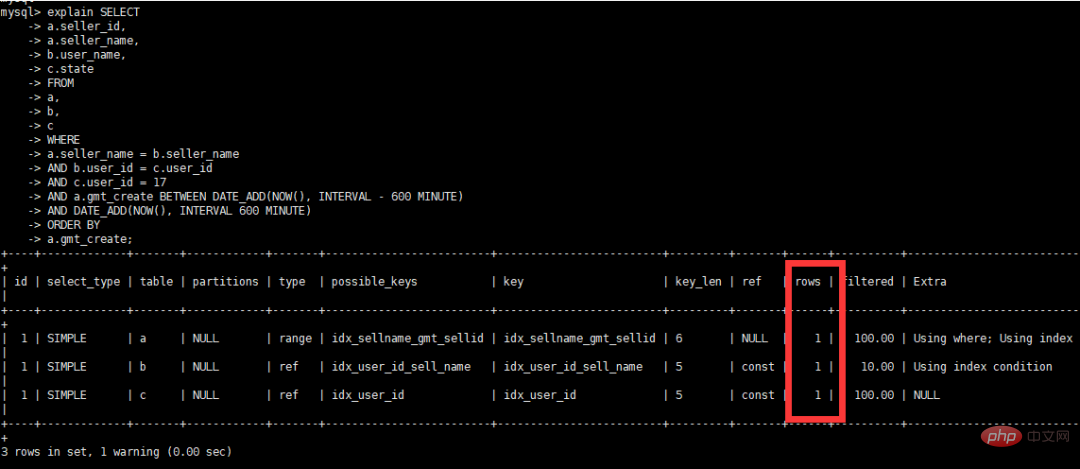
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);

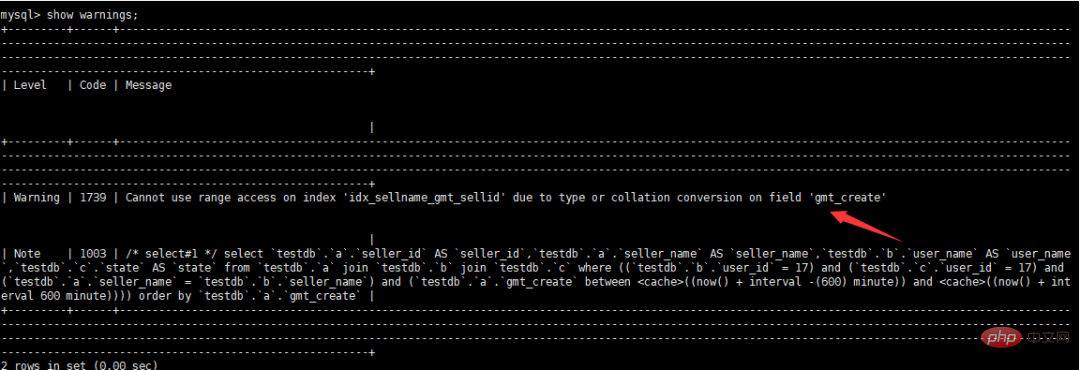
#警告情報の表示
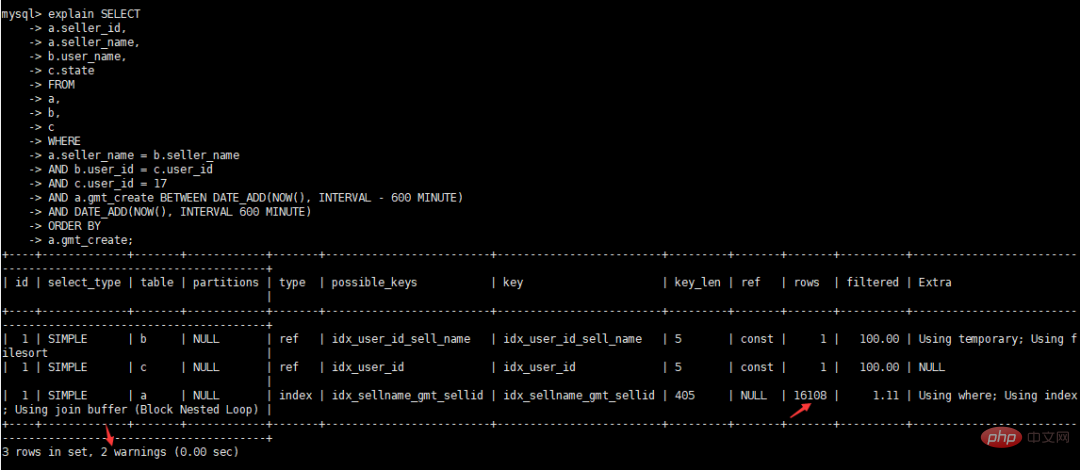
最適化を続行します。テーブルの変更、「gmt_create」の日時の変更 DEFAULT NULL;
 実行時間の表示
実行時間の表示
実行計画の表示

#概要
以上が例を使用して SQL を最適化する方法を説明しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29

 Discuz フォーラムのパフォーマンスを最適化するにはどうすればよいですか?
Mar 12, 2024 pm 06:48 PM
Discuz フォーラムのパフォーマンスを最適化するにはどうすればよいですか?
Mar 12, 2024 pm 06:48 PM
Discuz フォーラムのパフォーマンスを最適化するにはどうすればよいですか?はじめに: Discuz は一般的に使用されるフォーラム システムですが、使用中にパフォーマンスのボトルネックが発生する可能性があります。 Discuz フォーラムのパフォーマンスを向上させるために、データベースの最適化、キャッシュ設定、コードの調整など、さまざまな側面から最適化できます。以下では、具体的な操作とコード例を通して、Discuz フォーラムのパフォーマンスを最適化する方法を紹介します。 1. データベースの最適化: インデックスの最適化: 頻繁に使用されるクエリ フィールドにインデックスを作成すると、クエリの速度が大幅に向上します。例えば
 SQL Server と MySQL のパフォーマンスを最適化し、最高のパフォーマンスを発揮できるようにするにはどうすればよいでしょうか?
Sep 11, 2023 pm 01:40 PM
SQL Server と MySQL のパフォーマンスを最適化し、最高のパフォーマンスを発揮できるようにするにはどうすればよいでしょうか?
Sep 11, 2023 pm 01:40 PM
SQLServer と MySQL のパフォーマンスを最適化し、最高のパフォーマンスを発揮できるようにするにはどうすればよいでしょうか?要約: 今日のデータベース アプリケーションでは、SQLServer と MySQL が最も一般的で人気のある 2 つのリレーショナル データベース管理システム (RDBMS) です。データ量が増加し、ビジネス ニーズが変化し続けるにつれて、データベースのパフォーマンスの最適化が特に重要になってきています。この記事では、ユーザーが SQLServer と MySQL のパフォーマンスを最適化するための一般的な方法とテクニックをいくつか紹介します。
 Linuxのパフォーマンスチューニング~
Feb 12, 2024 pm 03:30 PM
Linuxのパフォーマンスチューニング~
Feb 12, 2024 pm 03:30 PM
Linux オペレーティング システムはオープン ソース製品であり、オープン ソース ソフトウェアの実践およびアプリケーション プラットフォームでもあります。このプラットフォームでは、Apache、Tomcat、mysql、php など、無数のオープン ソース ソフトウェアがサポートされています。オープンソース ソフトウェアの最大のコンセプトは、自由とオープンさです。したがって、オープン ソース プラットフォームとしての Linux の目標は、これらのオープン ソース ソフトウェアのサポートを通じて、最小限のコストで最適なアプリケーション パフォーマンスを実現することです。パフォーマンスの問題に関して言えば、主に Linux オペレーティング システムとアプリケーションの最適な組み合わせが達成されます。 1. パフォーマンスの問題の概要 システム パフォーマンスとは、タスクを完了する際のオペレーティング システムの効率、安定性、および応答速度を指します。 Linux システム管理者は、システムの不安定性や応答速度の遅さなどの問題に遭遇することがよくあります。
 Sybase と Oracle データベース管理システムの主な違い
Mar 08, 2024 pm 05:54 PM
Sybase と Oracle データベース管理システムの主な違い
Mar 08, 2024 pm 05:54 PM
Sybase と Oracle データベース管理システムの主な違いを理解するには、具体的なコード例が必要です。データベース管理システムは、現代の情報技術の分野で重要な役割を果たしています。Sybase と Oracle は、2 つのよく知られたリレーショナル データベース管理システムとして、重要な位置を占めています。データベース分野の重要なポジション。どちらもリレーショナル データベース管理システムですが、実際のアプリケーションではいくつかの重要な違いがあります。この記事では、アーキテクチャ、構文、パフォーマンスなどの複数の観点から Sybase と Oracle を比較します。
 SQLでanyは何を意味しますか
May 01, 2024 pm 11:03 PM
SQLでanyは何を意味しますか
May 01, 2024 pm 11:03 PM
SQL の ANY キーワードは、サブクエリが特定の条件を満たす行を返すかどうかを確認するために使用されます。 構文: ANY (サブクエリ) 使用法: 比較演算子とともに使用され、サブクエリが条件を満たす行を返す場合、ANY 式は次のように評価されます。 true 利点: クエリが簡素化され、効率が向上し、大量のデータの処理に適しています。 制限: 条件を満たす特定の行は提供されません。サブクエリが条件を満たす複数の行を返す場合、true のみが返されます。
 SQL Server と MySQL のパフォーマンス チューニング: ベスト プラクティスと重要なヒント。
Sep 11, 2023 pm 12:46 PM
SQL Server と MySQL のパフォーマンス チューニング: ベスト プラクティスと重要なヒント。
Sep 11, 2023 pm 12:46 PM
SQLServer と MySQL のパフォーマンス チューニング: ベスト プラクティスと重要なヒント 概要: この記事では、SQLServer と MySQL という 2 つの一般的なリレーショナル データベース システムのパフォーマンス チューニング方法を紹介し、開発者とデータベース管理者がパフォーマンスとパフォーマンスを向上させるのに役立ついくつかのベスト プラクティスと重要なヒントを提供します。データベースシステムの効率化。はじめに: 現代のアプリケーション開発において、データベース システムは不可欠な部分です。データ量が増加し、ユーザーの要求が増大するにつれて、データベースのパフォーマンスの最適化が特に重要になります。スクエア
 MySql SQL ステートメントの実行計画: MySQL クエリ プロセスを最適化する方法
Jun 16, 2023 am 09:15 AM
MySql SQL ステートメントの実行計画: MySQL クエリ プロセスを最適化する方法
Jun 16, 2023 am 09:15 AM
インターネットの急速な発展に伴い、データの保存と処理の重要性がますます高まっています。したがって、リレーショナル データベースは最新のソフトウェア プラットフォームに不可欠な部分です。 MySQL データベースは、使いやすく、展開と管理が簡単であるため、最も人気のあるリレーショナル データベースの 1 つになりました。ただし、大量のデータを処理する場合、MySQL データベースのパフォーマンスの問題が問題になることがよくあります。この記事では、MySQL の SQL ステートメントの実行プランを詳しく説明し、クエリ プロセスを最適化することで MySQL データを改善する方法を紹介します。
 データベース検索効果の最適化に関する Java スキル エクスペリエンスの共有と概要
Sep 18, 2023 am 09:25 AM
データベース検索効果の最適化に関する Java スキル エクスペリエンスの共有と概要
Sep 18, 2023 am 09:25 AM
データベース検索効果の最適化のための Java スキル エクスペリエンスの共有と要約 要約: データベース検索は、ほとんどのアプリケーションで一般的な操作の 1 つです。ただし、データの量が多い場合、検索操作が遅くなり、アプリケーションのパフォーマンスと応答時間に影響を与える可能性があります。この記事では、データベースの検索結果を最適化するのに役立つ Java のヒントをいくつか紹介し、具体的なコード例を示します。インデックスの使用 インデックス作成は、データベースの検索効率を向上させるための重要な部分です。検索操作を実行する前に、検索する必要がある列に適切なインデックスを作成していることを確認してください。例えば
