

Node.js マルチプロセス モデルで共有メモリを実装する方法に関する簡単な説明 (詳細なコードの説明)

この記事では、Node.jsworker_threads モジュールが提供するマルチコア方式、マルチスレッドモデルを利用して、Node.js で共有メモリを実現する方法を紹介します。マルチプロセスモデル。

Node.js シングルスレッド モデル設計のため、Node プロセス (メイン スレッド) は 1 つの CPU コアしか利用できませんが、今日のマシンは基本的にマルチコアです。 、これはパフォーマンスの重大な無駄を引き起こします。一般的に、複数のコアを利用したい場合は、次の方法があります。
Node 用の C プラグインを作成して、スレッド プールを拡張し、CPU 時間を委任する-JS コード内でのタスクの消費 他のスレッドの処理。
worker_threads モジュール (まだ実験段階) によって提供されるマルチスレッド モデルを使用します。
child_process または cluster モジュールによって提供されるマルチプロセス モデルを使用します。各プロセスは独立した Node.js プロセスです。
使いやすさ、コード侵入、安定性の観点から、通常はマルチプロセス モデルが最初の選択肢となります。 [推奨学習: "nodejs チュートリアル "]
Node.js クラスターのマルチプロセス モデルの問題
クラスター モジュールによって提供されるマルチプロセス モデルでは、各ノード プロセスは独立した完全なアプリケーション プロセスであり、他のプロセスからアクセスできない独自のメモリ空間を備えています。したがって、プロジェクトの開始時にはすべてのワーカー プロセスのステータスと動作が一貫していますが、その後の実行中にステータスが一貫しているという保証はありません。
たとえば、プロジェクトが開始されると、プロセス A とプロセス B の 2 つのワーカー プロセスが存在します。どちらのプロセスも変数 a=1 を宣言します。しかし、その後、プロジェクトがリクエストを受け取り、マスター プロセスがそのリクエストをプロセス A に割り当てて処理しました。このリクエストにより、a の値が 2 に変更されました。このとき、プロセス A のメモリ空間では a=2 でしたが、プロセス A では a=2 になりました。プロセス B のメモリ空間。まだ 1。このとき、aの値を読み出すリクエストがあった場合、MasterプロセスがプロセスAとプロセスBにリクエストをディスパッチした際に読み取った結果が不一致となり、整合性の問題が発生します。
クラスター モジュールは設計時に解決策を提供しませんでしたが、ワーカー プロセスがステートレスであることを要求しました。つまり、プログラマがコードを記述するときにリクエストを処理するときにメモリ内の値を変更することを許可されるべきではありませんでした。 . すべてのワーカー プロセスの一貫性を確保するため。ただし、実際には、ユーザーのログイン ステータスの記録など、メモリへの書き込みが必要なさまざまな状況が常にあります。多くの企業の実践では、通常、これらのステータス データはデータベース、Redis、メッセージ キュー、ファイル システムなど。 は、ステートフル リクエストが処理されるたびに、外部ストレージ領域の読み取りと書き込みを行います。
これは効果的なアプローチです。ただし、これには追加の外部ストレージ領域の導入が必要であり、同時に複数のプロセスによる同時アクセス下での一貫性の問題に対処し、寿命を維持する必要があります。 (ノードのプロセスと外部で維持されるデータは同期的に作成および破棄されないため)、同時アクセスが多い場合には IO パフォーマンスのボトルネックが発生します (メモリ以外の環境に保存されている場合)。データベースとして) 。実際、本質的には、複数のプロセスが共有してアクセスできるスペースが必要なだけです。永続ストレージは必要ありません。このスペースのライフ サイクルをノード プロセスに強力にバインドすることが最善です。使用に多くの時間を要し、手間が軽減されます。したがって、クロスプロセス共有メモリは、このシナリオでの使用に最適な方法となっています。
Node.js の共有メモリ
残念ながら、Node 自体は共有メモリの実装を提供していないため、以下を見てみましょう。 npm リポジトリ サードパーティ ライブラリの実装。これらのライブラリには、Node の機能を拡張する C プラグインを通じて実装されるものと、Node が提供する IPC メカニズムを通じて実装されるものがありますが、残念ながら、それらの実装は非常に単純で、相互排他的アクセス、オブジェクト監視、その他の機能は提供しません。作成者はこの共有メモリを注意深く維持する必要があります。そうしないと、タイミングの問題が発生します。 周りを見回しましたが、欲しいものが見つかりませんでした。 。 。忘れてください、自分で書きます。共有メモリの設計
まず、どのような共有メモリが必要なのかを明確にする必要があります。プロジェクトでは、プロセスをまたがってアクセスされる状態データを保存します)を考慮しつつ、汎用性を考慮するため、まず次の点を考慮します。JS オブジェクトを基本単位として使用する読み取りおよび書き込みアクセス。
#プロセス間で相互排他的なアクセスを提供できるため、あるプロセスがアクセスすると、他のプロセスはブロックされます。
共有メモリ内のオブジェクトを監視でき、オブジェクトが変更されたときに監視プロセスに通知できます。
#上記の条件を満たすことを前提として、実装方法は可能な限りシンプルである必要があります。
実際には、オペレーティング システム レベルで共有メモリは必要なく、複数のノード プロセスが同じオブジェクトにアクセスできるようにするだけで十分であることがわかります。その後、それ自体が提供するメカニズムに実装されたノードを使用できます。 マスター プロセスのメモリ空間を共有メモリ空間として使用できます。ワーカー プロセスは IPC を通じて読み取りおよび書き込みリクエストをマスター プロセスに委任し、マスター プロセスは読み取りと書き込みを行って結果をワーカーに返します。 IPCを介して処理します。
マスター プロセスとワーカー プロセスで共有メモリの使用を一貫して行うには、共有メモリの操作をインターフェイスに抽象化し、このインターフェイスをマスター プロセスとワーカー プロセスに実装します。それぞれワーカープロセス。クラス図は次のようになります。SharedMemory クラスを抽象インターフェイスとして使用し、server.js エントリ ファイルでオブジェクトを宣言します。これは、マスター プロセスでは Manager オブジェクトとして、ワーカー プロセスでは Worker オブジェクトとしてインスタンス化されます。 Manager オブジェクトは共有メモリを維持し、共有メモリへの読み取りおよび書き込みリクエストを処理します。一方、Worker オブジェクトは読み取りおよび書き込みリクエストをマスター プロセスに送信します。
")
Manager クラスの属性を共有メモリ オブジェクトとして使用できます。オブジェクトへのアクセス方法は、オブジェクトへのアクセス方法と同じです。通常の JS オブジェクトを作成してから、カプセル化のレイヤーを作成して、get、set、remove などの基本的な操作のみを公開して、プロパティが無効になるのを防ぎます。直接変更されました。
マスター プロセスはすべてのワーカー プロセスよりも前に作成されるため、マスター プロセスで共有メモリ領域を宣言した後にワーカー プロセスを作成して、各ワーカー プロセスが宣言直後に共有メモリにアクセスできるようにすることができます。作成した。 。
使用を簡単にするために、SharedMemory をシングルトンとして設計して、各プロセスにインスタンスが 1 つだけ存在するようにし、それを import にすることができます。 SharedMemory の直後に使用します。
コードの実装
読み取り/書き込み制御と IPC 通信
最初に外部インターフェイスを実装しますSharedMemory クラスですが、ここでは Manager と Worker に SharedMemory を継承させる方法を使用せず、SharedMemory## に継承させます。 # インスタンス化される Manager または Worker のインスタンスを返すときに、サブクラスを自動的に選択できます。
ノード 16 では、isPrimary
が isMasterに置き換わります。ここでは、互換性のために 2 つの記述方法が使用されています。// shared-memory.js class SharedMemory { constructor() { if (cluster.isMaster || cluster.isPrimary) { return new Manager(); } else { return new Worker(); } } }ログイン後にコピー
Manager は共有メモリ空間の管理を担当します。__sharedMemory__ 属性を Manager オブジェクトに直接追加します。また、JS オブジェクトは JS のガベージコレクション管理に含まれるため、メモリクリーニングやデータ移行などの操作が不要となり、実装が非常に簡単になります。次に、set、get、remove などの標準操作を __sharedMemory__ に定義して、アクセス メソッドを提供します。
cluster.on('online', callback) を通じてワーカー プロセスの作成イベントをリッスンし、すぐに worker.on('message', callback ) を使用します。 ワーカー プロセスからの IPC 通信を監視し、通信メッセージを handle 関数に渡して処理します。
handle 関数は、ワーカー プロセスが実行したい操作の種類を区別し、操作のパラメーターを取り出して、対応する set## に委託する責任があります。 #, get, remove 関数 (## の set, get, remove ではないことに注意してください) #__sharedMemory__) を処理し、処理結果をワーカー プロセスに返します。
// manager.js
const cluster = require('cluster');
class Manager {
constructor() {
this.__sharedMemory__ = {
set(key, value) {
this.memory[key] = value;
},
get(key) {
return this.memory[key];
},
remove(key) {
delete this.memory[key];
},
memory: {},
};
// Listen the messages from worker processes.
cluster.on('online', (worker) => {
worker.on('message', (data) => {
this.handle(data, worker);
return false;
});
});
}
handle(data, target) {
const args = data.value ? [data.key, data.value] : [data.key];
this[data.method](...args).then((value) => {
const msg = {
id: data.id, // workerId
uuid: data.uuid, // communicationID
value,
};
target.send(msg);
});
}
set(key, value) {
return new Promise((resolve) => {
this.__sharedMemory__.set(key, value);
resolve('OK');
});
}
get(key) {
return new Promise((resolve) => {
resolve(this.__sharedMemory__.get(key));
});
}
remove(key) {
return new Promise((resolve) => {
this.__sharedMemory__.remove(key);
resolve('OK');
});
}
}process.on を使用します (結局のところ、メッセージを待つことはできません)監視する前に送信すると手遅れになります)。 __getCallbacks__ オブジェクトの役割については、後ほど説明します。この時点で、Worker オブジェクトが作成されます。 その後、プロジェクトがどこかで実行されるときに、共有メモリにアクセスしたい場合は、Worker
set、get,# が実行されます。 ##remove 関数が呼び出されると、handle 関数が呼び出され、process.send を通じてマスター プロセスにメッセージが送信されます。戻り結果が得られたときに実行される処理は、__getCallbacks__ に記録されます。結果が返されると、process.on の前の関数によって監視され、対応するコールバック関数が __getCallbacks__ から取得されて実行されます。 <blockquote><p>因为访问共享内存的过程中会经过IPC,所以必定是异步操作,所以需要记录回调函数,不能实现成同步的方式,不然会阻塞原本的任务。</p></blockquote><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>// worker.js
const cluster = require(&#39;cluster&#39;);
const { v4: uuid4 } = require(&#39;uuid&#39;);
class Worker {
constructor() {
this.__getCallbacks__ = {};
process.on(&#39;message&#39;, (data) => {
const callback = this.__getCallbacks__[data.uuid];
if (callback && typeof callback === &#39;function&#39;) {
callback(data.value);
}
delete this.__getCallbacks__[data.uuid];
});
}
set(key, value) {
return new Promise((resolve) => {
this.handle(&#39;set&#39;, key, value, () => {
resolve();
});
});
}
get(key) {
return new Promise((resolve) => {
this.handle(&#39;get&#39;, key, null, (value) => {
resolve(value);
});
});
}
remove(key) {
return new Promise((resolve) => {
this.handle(&#39;remove&#39;, key, null, () => {
resolve();
});
});
}
handle(method, key, value, callback) {
const uuid = uuid4(); // 每次通信的uuid
process.send({
id: cluster.worker.id,
method,
uuid,
key,
value,
});
this.__getCallbacks__[uuid] = callback;
}
}</pre><div class="contentsignin">ログイン後にコピー</div></div><p>一次共享内存访问的完整流程是:调用<code>Worker的set/get/remove函数 -> 调用Worker的handle函数,向master进程通信并将回调函数记录在__getCallbacks__ -> master进程监听到来自worker进程的消息 -> 调用Manager的handle函数 -> 调用Manager的set/get/remove函数 -> 调用__sharedMemory__的set/get/remove函数 -> 操作完成返回Manager的set/get/remove函数 -> 操作完成返回handle函数 -> 向worker进程发送通信消息 -> worker进程监听到来自master进程的消息 -> 从__getCallbacks__中取出回调函数并执行。
互斥访问
到目前为止,我们已经实现了读写共享内存,但还没有结束,目前的共享内存是存在严重安全问题的。因为这个共享内存是可以所有进程同时访问的,然而我们并没有考虑并发访问时的时序问题。我们来看下面这个例子:
| 时间 | 进程A | 进程B | 共享内存中变量x的值 |
|---|---|---|---|
| t0 | 0 | ||
| t1 | 读取x(x=0) | 0 | |
| t2 | x1=x+1(x1=1) | 读取x(x=0) | 0 |
| t3 | 将x1的值写回x | x2=x+1(x2=1) | 1 |
| t4 | 将x2的值写回x | 1 |
进程A和进程B的目的都是将x的值加1,理想情况下最后x的值应该是2,可是最后的结果却是1。这是因为进程B在t3时刻给x的值加1的时候,使用的是t2时刻读取出来的x的值,但此时从全局角度来看,这个值已经过期了,因为t3时刻x最新的值已经被进程A写为了1,可是进程B无法知道进程外部的变化,所以导致了t4时刻最后写回的值又覆盖掉了进程A写回的值,等于是进程A的行为被覆盖掉了。
在多线程、多进程和分布式中并发情况下的数据一致性问题是老大难问题了,这里不再展开讨论。
为了解决上述问题,我们必须实现进程间互斥访问某个对象,来避免同时操作一个对象,从而使进程可以进行原子操作,所谓原子操作就是不可被打断的一小段连续操作,为此需要引入锁的概念。由于读写均以对象为基本单位,因此锁的粒度设置为对象级别。在某一个进程(的某一任务)获取了某个对象的锁之后,其它要获取锁的进程(的任务)会被阻塞,直到锁被归还。而要进行写操作,则必须要先获取对象的锁。这样在获取到锁直到锁被释放的这段时间里,该对象在共享内存中的值不会被其它进程修改,从而导致错误。
在Manager的__sharedMemory__中加入locks属性,用来记录哪个对象的锁被拿走了,lockRequestQueues属性用来记录被阻塞的任务(正在等待锁的任务)。并增加getLock函数和releaseLock函数,用来申请和归还锁,以及handleLockRequest函数,用来使被阻塞的任务获得锁。在申请锁时,会先将回调函数记录到lockRequestQueues队尾(因为此时该对象的锁可能已被拿走),然后再调用handleLockRequest检查当前锁是否被拿走,若锁还在,则让队首的任务获得锁。归还锁时,先将__sharedMemory__.locks中对应的记录删掉,然后再调用handleLockRequest让队首的任务获得锁。
// manager.js
const { v4: uuid4 } = require('uuid');
class Manager {
constructor() {
this.__sharedMemory__ = {
...
locks: {},
lockRequestQueues: {},
};
}
getLock(key) {
return new Promise((resolve) => {
this.__sharedMemory__.lockRequestQueues[key] =
this.__sharedMemory__.lockRequestQueues[key] ?? [];
this.__sharedMemory__.lockRequestQueues[key].push(resolve);
this.handleLockRequest(key);
});
}
releaseLock(key, lockId) {
return new Promise((resolve) => {
if (lockId === this.__sharedMemory__.locks[key]) {
delete this.__sharedMemory__.locks[key];
this.handleLockRequest(key);
}
resolve('OK');
});
}
handleLockRequest(key) {
return new Promise((resolve) => {
if (
!this.__sharedMemory__.locks[key] &&
this.__sharedMemory__.lockRequestQueues[key]?.length > 0
) {
const callback = this.__sharedMemory__.lockRequestQueues[key].shift();
const lockId = uuid4();
this.__sharedMemory__.locks[key] = lockId;
callback(lockId);
}
resolve();
});
}
...
}在Worker中,则是增加getLock和releaseLock两个函数,行为与get、set类似,都是调用handle函数。
// worker.js
class Worker {
getLock(key) {
return new Promise((resolve) => {
this.handle('getLock', key, null, (value) => {
resolve(value);
});
});
}
releaseLock(key, lockId) {
return new Promise((resolve) => {
this.handle('releaseLock', key, lockId, (value) => {
resolve(value);
});
});
}
...
}监听对象
有时候我们需要监听某个对象值的变化,在单进程Node应用中这很容易做到,只需要重写对象的set属性就可以了,然而在多进程共享内存中,对象和监听者都不在一个进程中,这只能依赖Manager的实现。这里,我们选择了经典的观察者模式来实现监听共享内存中的对象。
为此,我们先在__sharedMemory__中加入listeners属性,用来记录在对象值发生变化时监听者注册的回调函数。然后增加listen函数,其将监听回调函数记录到__sharedMemory__.listeners中,这个监听回调函数会将变化的值发送给对应的worker进程。最后,在set和remove函数返回前调用notifyListener,将所有记录在__sharedMemory__.listeners中监听该对象的所有函数取出并调用。
// manager.js
class Manager {
constructor() {
this.__sharedMemory__ = {
...
listeners: {},
};
}
handle(data, target) {
if (data.method === 'listen') {
this.listen(data.key, (value) => {
const msg = {
isNotified: true,
id: data.id,
uuid: data.uuid,
value,
};
target.send(msg);
});
} else {
...
}
}
notifyListener(key) {
const listeners = this.__sharedMemory__.listeners[key];
if (listeners?.length > 0) {
Promise.all(
listeners.map(
(callback) =>
new Promise((resolve) => {
callback(this.__sharedMemory__.get(key));
resolve();
})
)
);
}
}
set(key, value) {
return new Promise((resolve) => {
this.__sharedMemory__.set(key, value);
this.notifyListener(key);
resolve('OK');
});
}
remove(key) {
return new Promise((resolve) => {
this.__sharedMemory__.remove(key);
this.notifyListener(key);
resolve('OK');
});
}
listen(key, callback) {
if (typeof callback === 'function') {
this.__sharedMemory__.listeners[key] =
this.__sharedMemory__.listeners[key] ?? [];
this.__sharedMemory__.listeners[key].push(callback);
} else {
throw new Error('a listener must have a callback.');
}
}
...
}在Worker中由于监听操作与其它操作不一样,它是一次注册监听回调函数之后对象的值每次变化都会被通知,因此需要在增加一个__getListenerCallbacks__属性用来记录监听操作的回调函数,与__getCallbacks__不同,它里面的函数在收到master的回信之后不会删除。
// worker.js
class Worker {
constructor() {
...
this.__getListenerCallbacks__ = {};
process.on('message', (data) => {
if (data.isNotified) {
const callback = this.__getListenerCallbacks__[data.uuid];
if (callback && typeof callback === 'function') {
callback(data.value);
}
} else {
...
}
});
}
handle(method, key, value, callback) {
...
if (method === 'listen') {
this.__getListenerCallbacks__[uuid] = callback;
} else {
this.__getCallbacks__[uuid] = callback;
}
}
listen(key, callback) {
if (typeof callback === 'function') {
this.handle('listen', key, null, callback);
} else {
throw new Error('a listener must have a callback.');
}
}
...
}LRU缓存
有时候我们需要用用内存作为缓存,但多进程中各进程的内存空间独立,不能共享,因此也需要用到共享内存。但是如果用共享内存中的一个对象作为缓存的话,由于每次IPC都需要传输整个缓存对象,会导致缓存对象不能太大(否则序列化和反序列化耗时太长),而且由于写缓存对象的操作需要加锁,进一步影响了性能,而原本我们使用缓存就是为了加快访问速度。其实在使用缓存的时候通常不会做复杂操作,大多数时候也不需要保障一致性,因此我们可以在Manager再增加一个共享内存__sharedLRUMemory__,其为一个lru-cache实例,并增加getLRU、setLRU、removeLRU函数,与set、get、remove函数类似。
// manager.js
const LRU = require('lru-cache');
class Manager {
constructor() {
...
this.defaultLRUOptions = { max: 10000, maxAge: 1000 * 60 * 5 };
this.__sharedLRUMemory__ = new LRU(this.defaultLRUOptions);
}
getLRU(key) {
return new Promise((resolve) => {
resolve(this.__sharedLRUMemory__.get(key));
});
}
setLRU(key, value) {
return new Promise((resolve) => {
this.__sharedLRUMemory__.set(key, value);
resolve('OK');
});
}
removeLRU(key) {
return new Promise((resolve) => {
this.__sharedLRUMemory__.del(key);
resolve('OK');
});
}
...
}Worker中也增加getLRU、setLRU、removeLRU函数。
// worker.js
class Worker {
getLRU(key) {
return new Promise((resolve) => {
this.handle('getLRU', key, null, (value) => {
resolve(value);
});
});
}
setLRU(key, value) {
return new Promise((resolve) => {
this.handle('setLRU', key, value, () => {
resolve();
});
});
}
removeLRU(key) {
return new Promise((resolve) => {
this.handle('removeLRU', key, null, () => {
resolve();
});
});
}
...
}共享内存的使用方式
目前共享内存的实现已发到npm仓库(文档和源代码在Github仓库,欢迎pull request和报bug),可以直接通过npm安装:
npm i cluster-shared-memory
下面的示例包含了基本使用方法:
const cluster = require('cluster');
// 引入模块时会根据当前进程 master 进程还是 worker 进程自动创建对应的 SharedMemory 对象
require('cluster-shared-memory');
if (cluster.isMaster) {
// 在 master 进程中 fork 子进程
for (let i = 0; i < 2; i++) {
cluster.fork();
}
} else {
const sharedMemoryController = require('./src/shared-memory');
const obj = {
name: 'Tom',
age: 10,
};
// 写对象
await sharedMemoryController.set('myObj', obj);
// 读对象
const myObj = await sharedMemoryController.get('myObj');
// 互斥访问对象,首先获得对象的锁
const lockId = await sharedMemoryController.getLock('myObj');
const newObj = await sharedMemoryController.get('myObj');
newObj.age = newObj.age + 1;
await sharedMemoryController.set('myObj', newObj);
// 操作完之后释放锁
await sharedMemoryController.releaseLock('requestTimes', lockId);
// 或者使用 mutex 函数自动获取和释放锁
await sharedMemoryController.mutex('myObj', async () => {
const newObjM = await sharedMemoryController.get('myObj');
newObjM.age = newObjM.age + 1;
await sharedMemoryController.set('myObj', newObjM);
});
// 监听对象
sharedMemoryController.listen('myObj', (value) => {
console.log(`myObj: ${value}`);
});
//写LRU缓存
await sharedMemoryController.setLRU('cacheItem', {user: 'Tom'});
// 读对象
const cacheItem = await sharedMemoryController.getLRU('cacheItem');
}缺点
这种实现目前尚有几个缺点:
不能使用PM2的自动创建worker进程的功能。
由于PM2会使用自己的
cluster模块的master进程的实现,而我们的共享内存模块需要在master进程维护一个内存空间,则不能使用PM2的实现,因此不能使用PM2的自动创建worker进程的功能。
传输的对象必须可序列化,且不能太大。
如果使用者在获取锁之后忘记释放,会导致其它进程一直被阻塞,这要求程序员有良好的代码习惯。
原文地址:https://juejin.cn/post/6992091006220894215
作者:FinalZJY
更多编程相关知识,请访问:编程视频!!
以上がNode.js マルチプロセス モデルで共有メモリを実装する方法に関する簡単な説明 (詳細なコードの説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7400
7400
 15
1630
14
1358
52
1268
25
1217
29
15
1630
14
1358
52
1268
25
1217
29

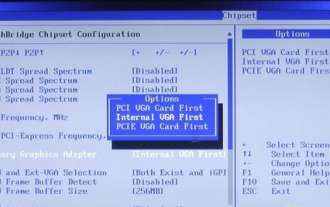 win10gpu共有メモリをオフにする方法
Jan 12, 2024 am 09:45 AM
win10gpu共有メモリをオフにする方法
Jan 12, 2024 am 09:45 AM
コンピューターにある程度詳しい友人なら、GPU には共有メモリがあることを知っているはずですが、多くの友人は、共有メモリによってメモリの数が減り、コンピューターに影響が出るのではないかと心配して、GPU をオフにしたいと考えています。見る。 win10gpu 共有メモリをオフにする: 注: GPU の共有メモリをオフにすることはできませんが、その値を最小値に設定することはできます。 1. 起動時に DEL を押して BIOS に入ります。一部のマザーボードでは、F2/F9/F12 を押して入る必要があります。BIOS インターフェイスの上部には、「メイン」、「詳細」、その他の設定を含む多くのタブがあります。「チップセット」を見つけます。 " オプション。以下のインターフェイスで SouthBridge 設定オプションを見つけ、Enter をクリックして入力します。
 Nodeのメモリ制御に関する記事
Apr 26, 2023 pm 05:37 PM
Nodeのメモリ制御に関する記事
Apr 26, 2023 pm 05:37 PM
ノンブロッキングおよびイベント駆動に基づいて構築されたノード サービスには、メモリ消費量が少ないという利点があり、大量のネットワーク リクエストの処理に非常に適しています。大量のリクエストを前提として、「メモリ制御」に関する問題を考慮する必要があります。 1. V8 のガベージ コレクション メカニズムとメモリ制限 Js はガベージ コレクション マシンによって制御されます
 Node V8 エンジンのメモリと GC の詳細な図による説明
Mar 29, 2023 pm 06:02 PM
Node V8 エンジンのメモリと GC の詳細な図による説明
Mar 29, 2023 pm 06:02 PM
この記事では、NodeJS V8 エンジンのメモリとガベージ コレクター (GC) について詳しく説明します。
 Node.js 19 が正式リリースされました。その 6 つの主要な機能についてお話しましょう。
Nov 16, 2022 pm 08:34 PM
Node.js 19 が正式リリースされました。その 6 つの主要な機能についてお話しましょう。
Nov 16, 2022 pm 08:34 PM
Node 19 が正式リリースされましたので、この記事では Node.js 19 の 6 つの主要な機能について詳しく説明します。
 Node の File モジュールについて詳しく説明しましょう
Apr 24, 2023 pm 05:49 PM
Node の File モジュールについて詳しく説明しましょう
Apr 24, 2023 pm 05:49 PM
ファイル モジュールは、ファイルの読み取り/書き込み/開く/閉じる/削除の追加など、基礎となるファイル操作をカプセル化したものです。ファイル モジュールの最大の特徴は、すべてのメソッドが **同期** と ** の 2 つのバージョンを提供することです。 asynchronous**、sync サフィックスが付いているメソッドはすべて同期メソッドであり、持たないメソッドはすべて異種メソッドです。
 最適な Node.js Docker イメージを選択する方法について話しましょう。
Dec 13, 2022 pm 08:00 PM
最適な Node.js Docker イメージを選択する方法について話しましょう。
Dec 13, 2022 pm 08:00 PM
ノード用の Docker イメージの選択は些細なことのように思えるかもしれませんが、イメージのサイズと潜在的な脆弱性は、CI/CD プロセスとセキュリティに大きな影響を与える可能性があります。では、最適な Node.js Docker イメージを選択するにはどうすればよいでしょうか?
 Golang関数における複数プロセス間の共有メモリの適用方法
May 17, 2023 pm 12:52 PM
Golang関数における複数プロセス間の共有メモリの適用方法
May 17, 2023 pm 12:52 PM
同時実行性の高いプログラミング言語である Golang の組み込みコルーチン メカニズムとマルチスレッド操作により、軽量のマルチタスクが可能になります。ただし、マルチプロセス処理シナリオでは、異なるプロセス間の通信と共有メモリがプログラム開発の重要な問題になります。この記事では、Golangで複数プロセス間で共有メモリを実現する応用方法を紹介します。 1. Golang でマルチプロセスを実装する方法 Golang では、fork、os.Process、
 Node.js の GC (ガベージ コレクション) メカニズムについて話しましょう
Nov 29, 2022 pm 08:44 PM
Node.js の GC (ガベージ コレクション) メカニズムについて話しましょう
Nov 29, 2022 pm 08:44 PM
Node.js はどのように GC (ガベージ コレクション) を行うのでしょうか?次の記事で詳しく説明します。
